Prepare Source Data
This page shows you the basic requirements for the source data you need to observe when performing an import on Zilliz Cloud.
Map source data to collection
The target collection requires mapping the source data to its schema. The diagram below shows how acceptable source data is mapped to the schema of a target collection.
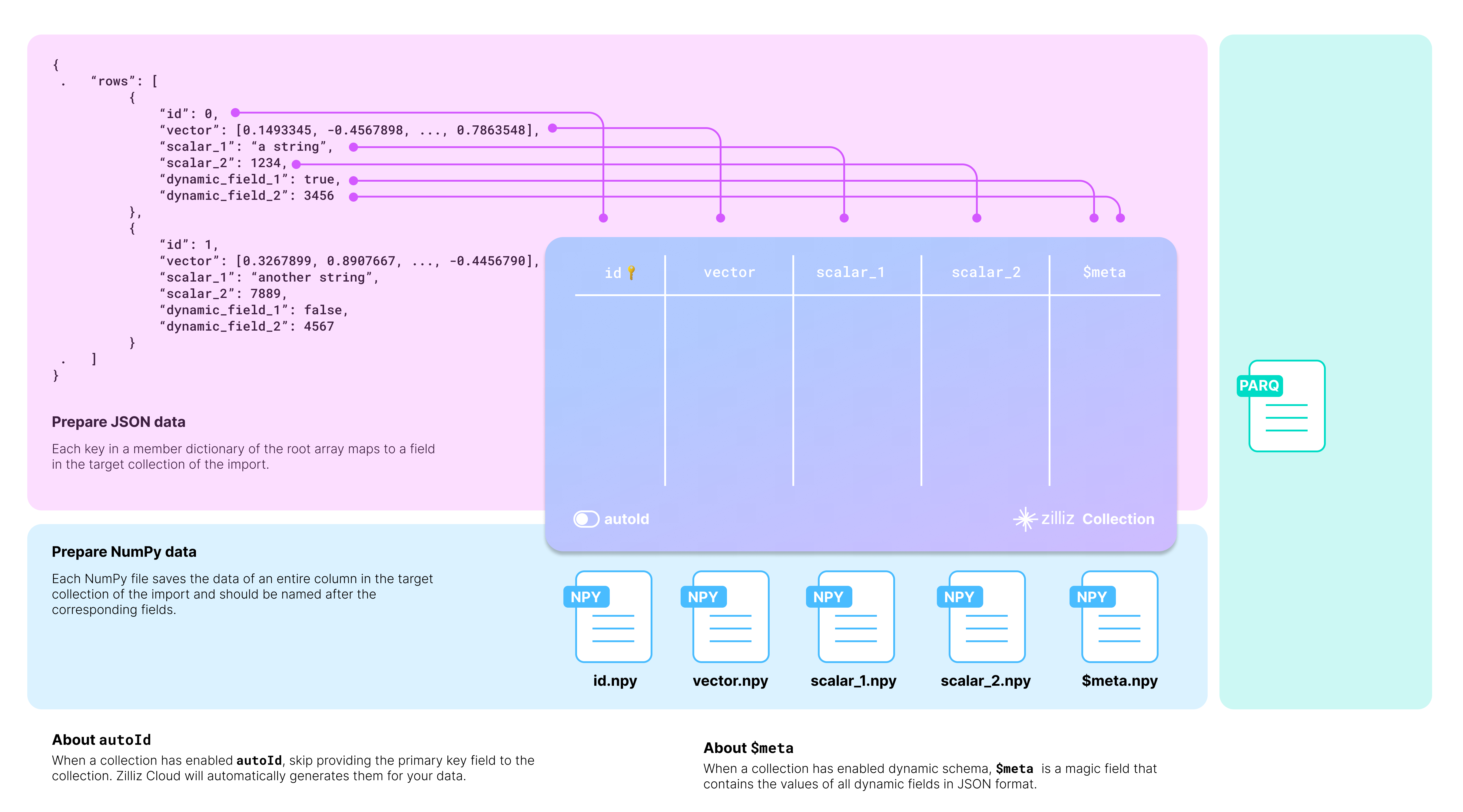
You should carefully examine your data and design the schema of the target collection accordingly.
Taking the JSON data in the above diagram as an example, there are two entities in the rows list, each row having six fields. The collection selectively includes four: id, vector, scalar_1, and scalar_2.
There are two more things to consider when designing the schema:
-
Whether to enable AutoID
The id field serves as the primary field of the collection. To make the primary field automatically increment, you can enable AutoID in the schema. In this case, you should exclude the id field from each row in the source data.
-
Whether to enable dynamic fields
The target collection can also store fields not included in its pre-defined schema if the schema enables dynamic fields. The $meta field is a reserved JSON field to hold dynamic fields and their values in key-value pairs. In the above diagram, the fields dynamic_field_1 and dynamic_field_2 and the values will be saved as key-value pairs in $meta.
The following code shows how to set up the schema for the collection in the above diagram.
- Python
- Java
from pymilvus import MilvusClient, DataType
# You need to work out a collection schema out of your dataset.
schema = MilvusClient.create_schema(
auto_id=False,
enable_dynamic_field=True
)
schema.add_field(field_name="id", datatype=DataType.INT64, is_primary=True)
schema.add_field(field_name="vector", datatype=DataType.FLOAT_VECTOR, dim=768)
schema.add_field(field_name="scalar_1", datatype=DataType.VARCHAR, max_length=512)
schema.add_field(field_name="scalar_2", datatype=DataType.INT64)
schema.verify()
import io.milvus.param.collection.CollectionSchemaParam;
import io.milvus.param.collection.FieldType;
import io.milvus.grpc.DataType;
// Define schema for the target collection
FieldType id = FieldType.newBuilder()
.withName("id")
.withDataType(DataType.Int64)
.withPrimaryKey(true)
.withAutoID(false)
.build();
FieldType vector = FieldType.newBuilder()
.withName("vector")
.withDataType(DataType.FloatVector)
.withDimension(768)
.build();
FieldType scalar1 = FieldType.newBuilder()
.withName("scalar_1")
.withDataType(DataType.VarChar)
.withMaxLength(512)
.build();
FieldType scalar2 = FieldType.newBuilder()
.withName("scalar_2")
.withDataType(DataType.Int64)
.build();
CollectionSchemaParam schema = CollectionSchemaParam.newBuilder()
.withEnableDynamicField(true)
.addFieldType(id)
.addFieldType(vector)
.addFieldType(scalar1)
.addFieldType(scalar2)
.build();
Source data requirements
Zilliz Cloud supports data imports from files in JSON, Parquet, and NumPy formats. If your data is in these formats but fails to import to Zilliz Cloud collections, check whether your data meets the following requirements. If your data is in a different format, convert it using the BulkWriter tool.
JSON file
A valid JSON file has a root key named rows, the corresponding value of which is a list of dictionaries, each representing an entity that matches the schema of the target collection.
Item | Description |
|---|---|
Multiple files per import | Yes |
Maximum file size per import | Free cluster: 512 MB in total Serverless and Dedicated cluster:
|
Applicable data file locations | Local and remote files |
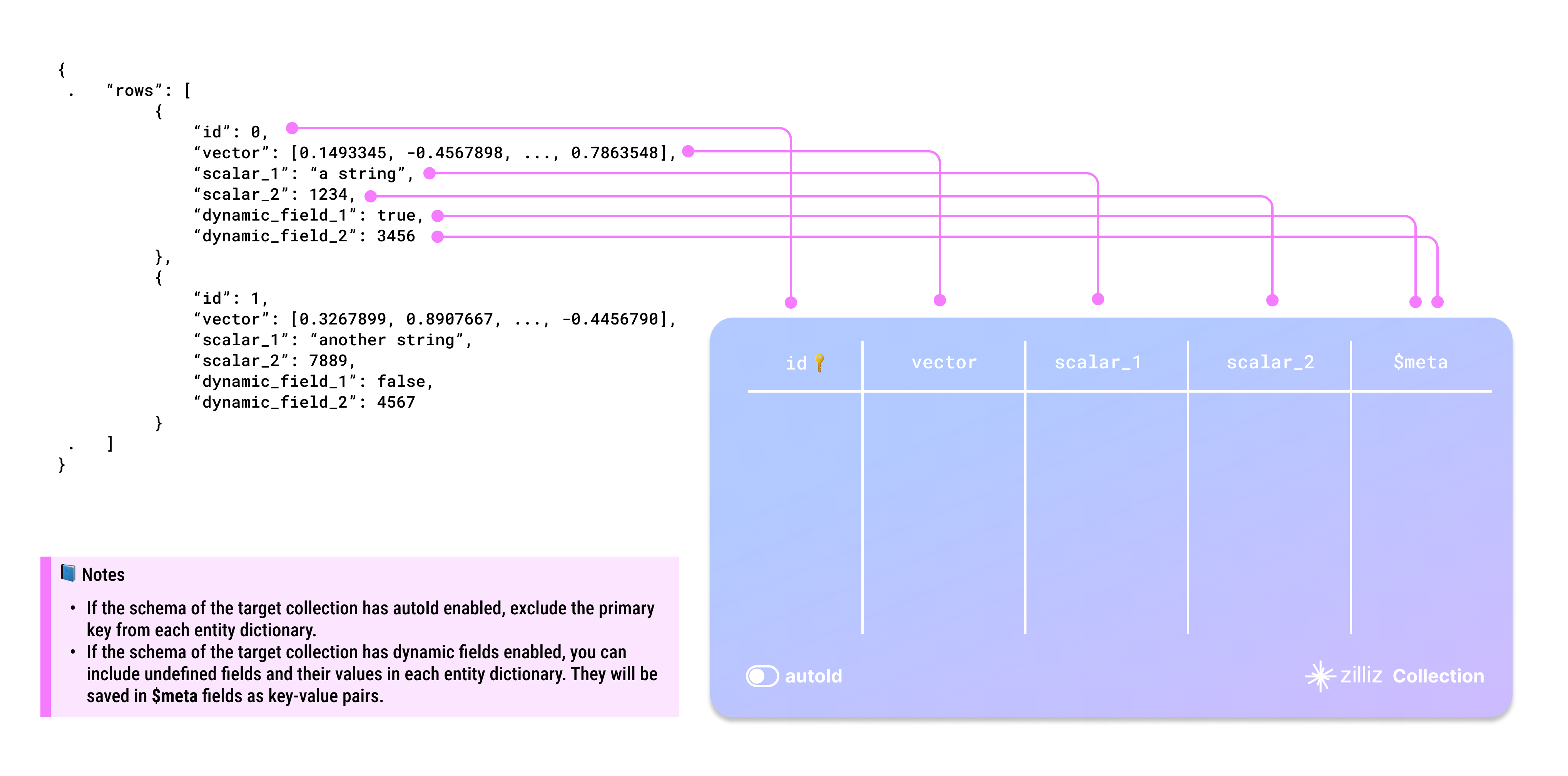
Exclude the primary key in each entity dictionary if the target collection has AutoId enabled in its schema.
You can include any undefined fields and their values in each entity dictionary as dynamic fields if the target collection has enabled dynamic fields.
Dictionary keys and collection field names are case-sensitive. Ensure that the dictionary keys in your data exactly match the field names in the target collection. If there is a field named id in the target collection, each entity dictionary should have a key named id. Using ID or Id results in errors.
You can either rebuild your data on your own by referring to Prepare the data file or use the BulkWriter tool to generate the source data file. Click here to download the prepared sample data based on the schema in the above diagram.
Parquet file
Item | Description |
|---|---|
Multiple files per import | Yes |
Maximum file size per import | Free cluster: 512 MB in total Serverless & Dedicated cluster
|
Applicable data file locations | Remote files only |
You are advised to use the BulkWriter tool to prepare your raw data into parquet files. Click here to download the prepared sample data based on the schema in the above diagram.
This file type is available for clusters compatible with Milvus 2.3.x.
NumPy files
A valid set of NumPy files should be named after the fields in the schema of the target collection, and the data in them should match the corresponding field definitions.
Item | Description |
|---|---|
Multiple files per import | Yes |
Data import from first-level subfolders | Yes |
Maximum number of first-level subfolders | 100 |
Maximum file size per import | Free cluster: 512 MB in total Serverless & Dedicated cluster:
|
Applicable data file locations | Remote files only |
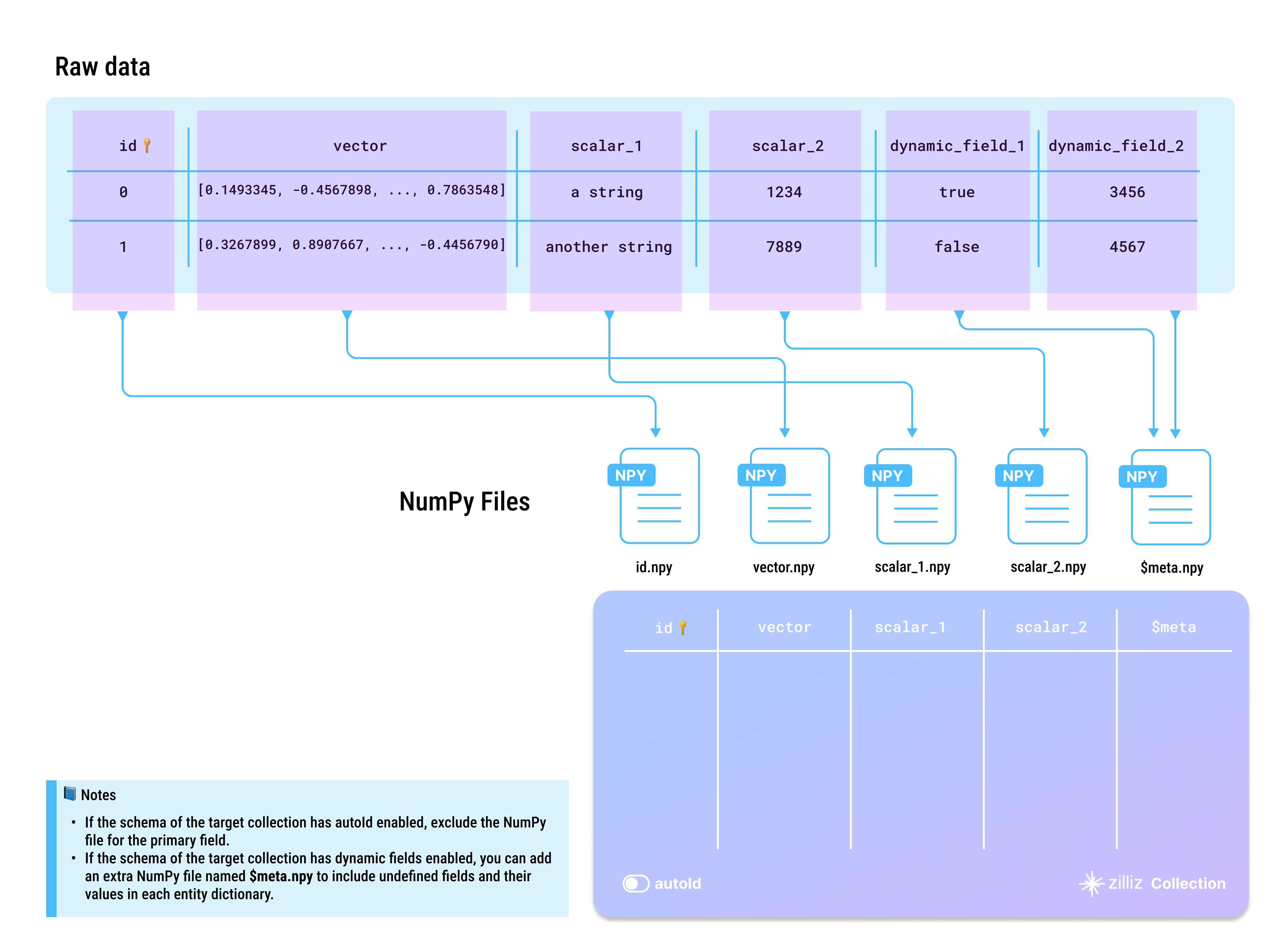
Exclude the NumPy file for the primary field if the target collection has AutoID enabled in its schema.
You can include any undefined fields and their values as key-value pairs in a separate NumPy file named $meta.npy if the target collection has enabled dynamic fields.
NumPy file names and collection field names are case-sensitive. Ensure that all NumPy files are named after the field names in the target collection. If there is a field named id in the target collection, you should prepare a NumPy file and name it id.npy. Naming the file ID.npy or Id.npy results in errors.
You can either rebuild your data on your own by referring to Prepare the data file or use the BulkWriter tool to generate the source data file. Click here to download the prepared sample data based on the schema in the above diagram.
Tips on import paths
Zilliz Cloud supports data import through the Zilliz Cloud console as well as via RESTful APIs and SDKs. To import the prepared data, you should provide a valid import path to the data.
From local folders
Zilliz Cloud supports data import from a JSON file in a local folder on the Zilliz Cloud console. You can drag the local file and drop it into the Import Data dialog box or click upload a file and select the prepared file. Then click Import to import the file to the target collection.
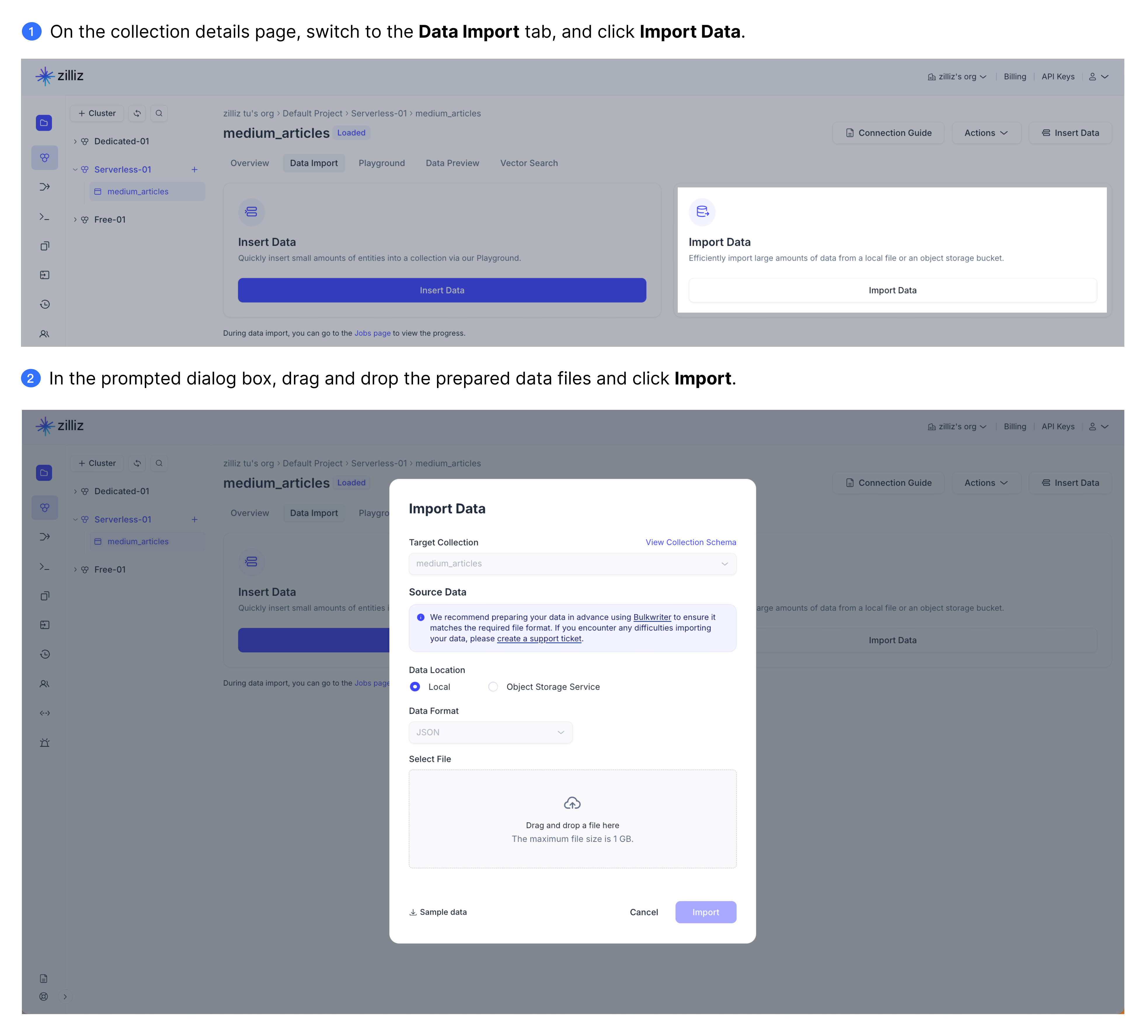
For a free cluster, you can upload files of no greater than 512 MB at a time. And this figure is 1 GB for a serverless or dedicated cluster.
From remote buckets
Zilliz Cloud also supports data import from a bucket on AWS S3, Google GCS, and Azure Blob through the console, RESTful API, and SDKs.
-
Object access URIs
URI Style
URI Format
AWS S3 URI
s3://bucket-name/object-nameAWS Object URL, virtual-hosted–style
https://bucket-name.s3.region-code.amazonaws.com/object-nameAWS Object URL, path-style
https://s3.region-code.amazonaws.com/bucket-name/object-nameFor more details, see Methods for accessing a bucket.
-
Quick examples
File Type
Quick Examples
JSON
s3://bucket-name/json-folder/s3://bucket-name/json-folder/data.jsonNumPy
s3://bucket-name/numpy_folder/s3://bucket-name/folder/*.npyParquet
s3://bucket-name/parquet-folder/s3://bucket-name/parquet-folder/data.parquet -
Required permissions
-
s3:GetObject -
s3:ListBucket -
s3:GetBucketLocation
-