Upsert Entities
The upsert operation provides a convenient way to insert or update entities in a collection.
Overview
You can use upsert to either insert a new entity or update an existing one, depending on whether the primary key provided in the upsert request exists in the collection. If the primary key is not found, an insert operation occurs. Otherwise, an update operation will be performed.
An upsert request combines an insert and a delete. When an upsert request for an existing entity is received, Zilliz Cloud inserts the data carried in the request payload and deletes the existing entity with the original primary key specified in the data at the same time.
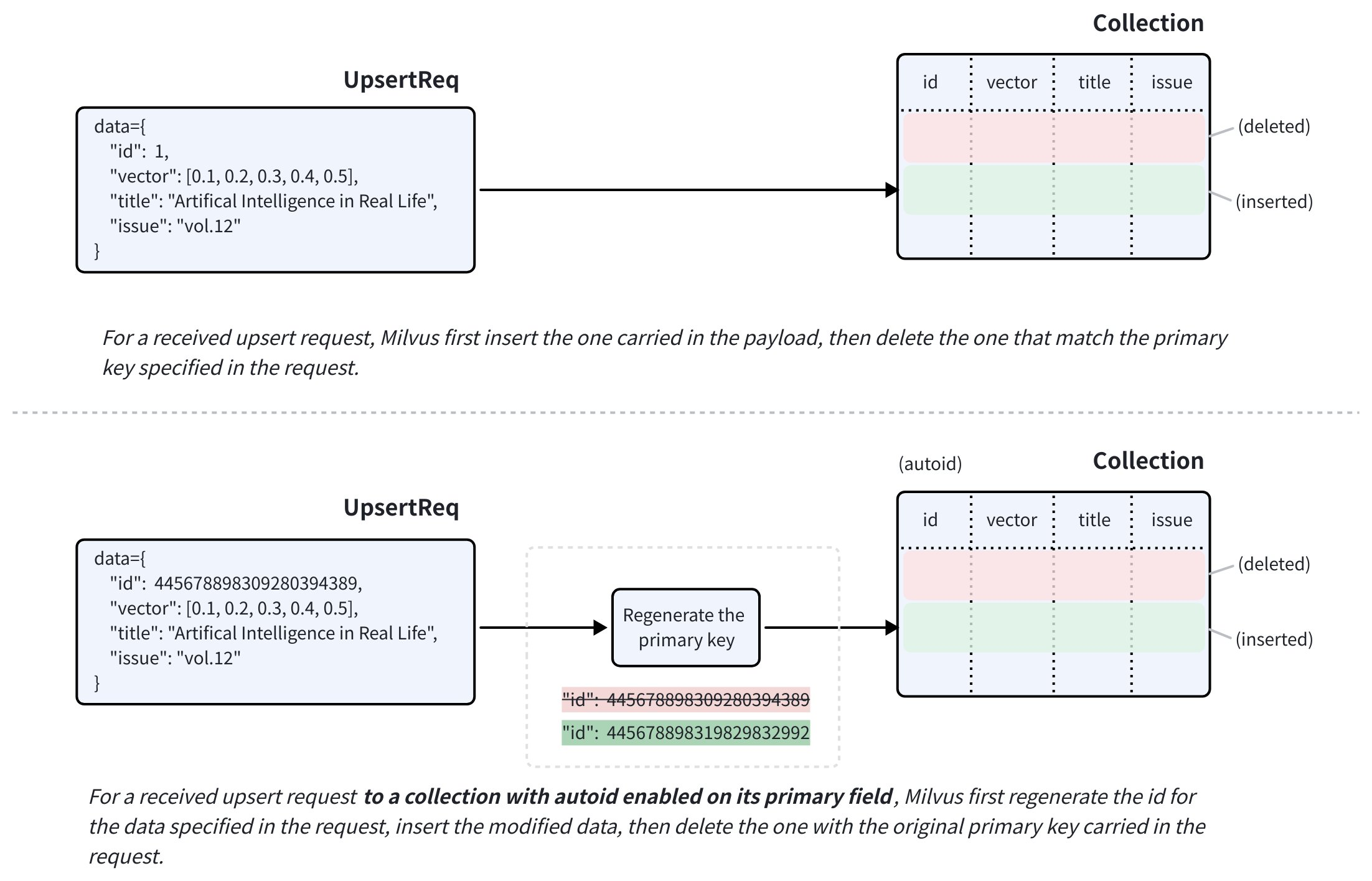
If the target collection has autoid enabled on its primary field, Zilliz Cloud will generate a new primary key for the data carried in the request payload before inserting it.
For fields with nullable enabled, you can omit them in the upsert request if they do not require any updates.
Upsert in merge mode
You can also use the partial_update flag to make an upsert request work in merge mode. This allows you to include only the fields that need updating in the request payload.
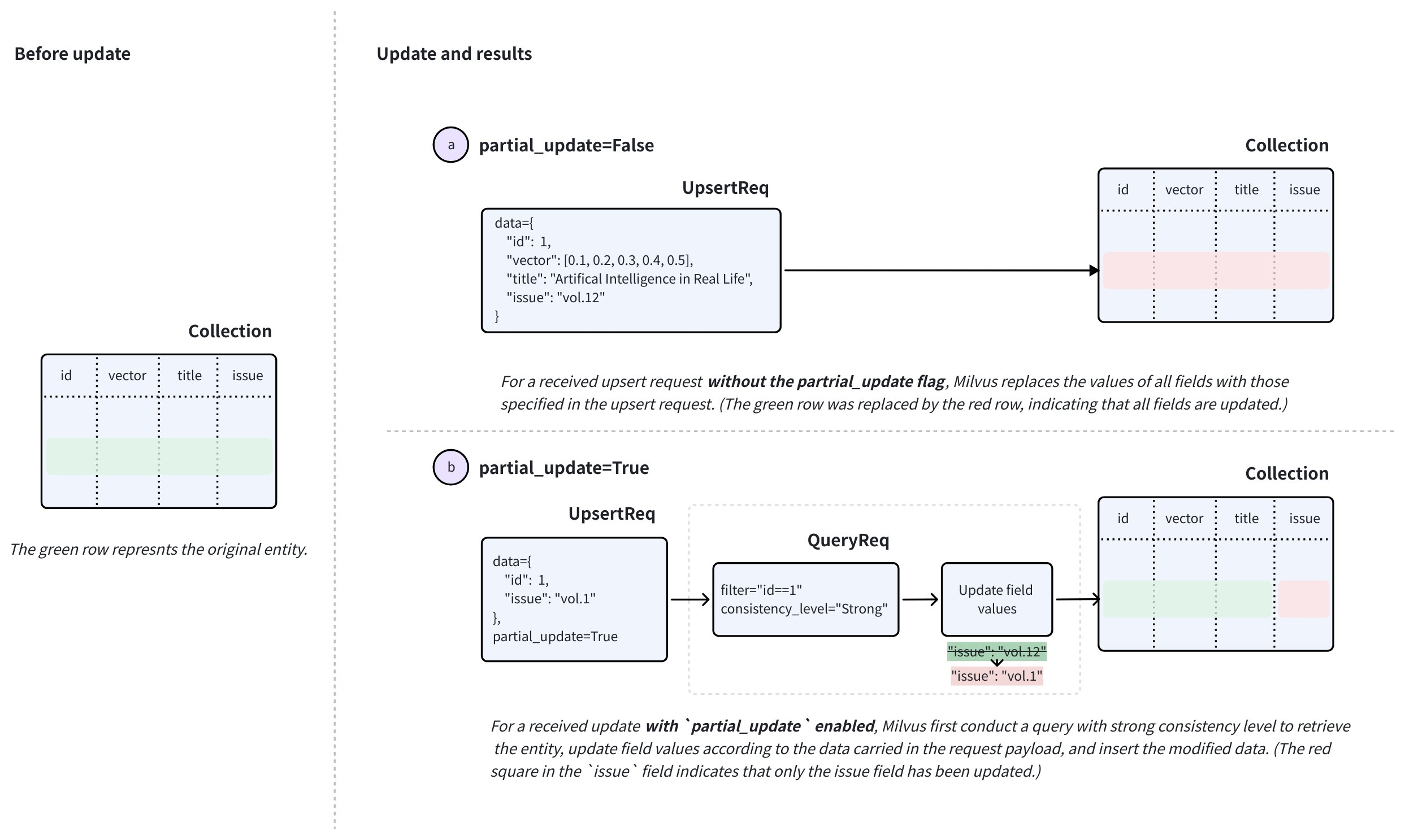
To perform a merge, set partial_update to True in the upsert request along with the primary key and the fields to update with their new values.
Upon receiving such a request, Zilliz Cloud performs a query with strong consistency to retrieve the entity, updates the field values based on the data in the request, inserts the modified data, and then deletes the existing entity with the original primary key carried in the request.
For ARRAY fields, merge mode supports two operators: ARRAY_APPEND and ARRAY_REMOVE. These operators let you append elements to or remove matching elements from an existing ARRAY field, without first querying the entity to retrieve its current value. For details, see Upsert ARRAY fields with partial-update operators.
Update field values
To update the field values of an existing entity, use upsert in merge mode. In this mode, only the fields included in the request are updated — all other fields retain their existing values.
Upsert behaviors: special notes
There are several special notes you should consider before using the merge feature. The following cases assume that you have a collection with two scalar fields named title and issue, along with a primary key id and a vector field called vector.
-
Upsert fields with
nullableenabled.Suppose that the
issuefield can be null. When you upsert these fields, note that:-
If you omit the
issuefield in theupsertrequest and disablepartial_update, theissuefield will be updated tonullinstead of retaining its original value. -
To preserve the original value of the
issuefield, you need either to enablepartial_updateand omit theissuefield or include theissuefield with its original value in theupsertrequest.
-
-
Upsert keys in the dynamic field.
Suppose that you have enabled the dynamic key in the example collection, and the key-value pairs in the dynamic field of an entity are similar to
{"author": "John", "year": 2020, "tags": ["fiction"]}.When you upsert the entity with keys, such as
author,year, ortags, or add other keys, note that:-
If you upsert with
partial_updatedisabled, the default behavior is to override. It means that the value of the dynamic field will be overridden by all non-schema-defined fields included in the request and their values.For example, if the data included in the request is
{"author": "Jane", "genre": "fantasy"}, the key-value pairs in the dynamic field of the target entity will be updated to that. -
If you upsert with
partial_updateenabled, the default behavior is to merge. It means that the value of the dynamic field will merge with all non-schema-defined fields included in the request and their values.For example, if the data included in the request is
{"author": "John", "year": 2020, "tags": ["fiction"]}, the key-value pairs in the dynamic field of the target entity will become{"author": "John", "year": 2020, "tags": ["fiction"], "genre": "fantasy"}after the upsert.
-
-
Upsert a JSON field.
Suppose that the example collection has a schema-defined JSON field named
extras, and the key-value pairs in this JSON field of an entity are similar to{"author": "John", "year": 2020, "tags": ["fiction"]}.When you upsert the
extrasfield of an entity with modified JSON data, note that the JSON field is treated as a whole, and you cannot update individual keys selectively. In other words, the JSON field DOES NOT support upsert in merge mode. -
Upsert an
ARRAYfield.By default, an
ARRAYfield in merge mode follows REPLACE semantics: the value carried in the request overwrites the existing array. For finer-grained updates, Zilliz Cloud also supports two operators:-
ARRAY_APPENDappends the elements in the request payload to the existing array. -
ARRAY_REMOVEremoves every element from the existing array that matches a value in the request payload.
For operator syntax, supported element types, and other constraints, see Upsert array fields with partial-update operators.
-
Limits & Restrictions
Based on the above content, there are several limits and restrictions to follow:
-
The
upsertrequest must always include the primary keys of the target entities. -
The target collection must be loaded and available for queries.
-
All fields specified in the request must exist in the schema of the target collection.
-
The values of all fields specified in the request must match the data types defined in the schema.
-
For any field derived from another using functions, Zilliz Cloud will remove the derived field during the upsert to allow recalculation.
Upsert entities in a collection
In this section, we will upsert entities into a collection named my_collection. This collection has only two fields, named id, vector, title, and issue. The id field is the primary field, while the title and issue fields are scalar fields.
The three entities, if exists in the collection, will be overridden by those included the upsert request.
- Python
- Java
- NodeJS
- Go
- cURL
from pymilvus import MilvusClient
client = MilvusClient(
uri="YOUR_CLUSTER_ENDPOINT",
token="YOUR_CLUSTER_TOKEN"
)
data=[
{
"id": 0,
"vector": [-0.619954382375778, 0.4479436794798608, -0.17493894838751745, -0.4248030059917294, -0.8648452746018911],
"title": "Artificial Intelligence in Real Life",
"issue": "vol.12"
}, {
"id": 1,
"vector": [0.4762662251462588, -0.6942502138717026, -0.4490002642657902, -0.628696575798281, 0.9660395877041965],
"title": "Hollow Man",
"issue": "vol.19"
}, {
"id": 2,
"vector": [-0.8864122635045097, 0.9260170474445351, 0.801326976181461, 0.6383943392381306, 0.7563037341572827],
"title": "Treasure Hunt in Missouri",
"issue": "vol.12"
}
]
res = client.upsert(
collection_name='my_collection',
data=data
)
print(res)
# Output
# {'upsert_count': 3}
import com.google.gson.Gson;
import com.google.gson.JsonObject;
import io.milvus.v2.client.ConnectConfig;
import io.milvus.v2.client.MilvusClientV2;
import io.milvus.v2.service.vector.request.UpsertReq;
import io.milvus.v2.service.vector.response.UpsertResp;
import java.util.*;
MilvusClientV2 client = new MilvusClientV2(ConnectConfig.builder()
.uri("YOUR_CLUSTER_ENDPOINT")
.token("YOUR_CLUSTER_TOKEN")
.build());
Gson gson = new Gson();
List<JsonObject> data = Arrays.asList(
gson.fromJson("{\"id\": 0, \"vector\": [-0.619954382375778, 0.4479436794798608, -0.17493894838751745, -0.4248030059917294, -0.8648452746018911], \"title\": \"Artificial Intelligence in Real Life\", \"issue\": \"\vol.12\"}", JsonObject.class),
gson.fromJson("{\"id\": 1, \"vector\": [0.4762662251462588, -0.6942502138717026, -0.4490002642657902, -0.628696575798281, 0.9660395877041965], \"title\": \"Hollow Man\", \"issue\": \"vol.19\"}", JsonObject.class),
gson.fromJson("{\"id\": 2, \"vector\": [-0.8864122635045097, 0.9260170474445351, 0.801326976181461, 0.6383943392381306, 0.7563037341572827], \"title\": \"Treasure Hunt in Missouri\", \"issue\": \"vol.12\"}", JsonObject.class),
);
UpsertReq upsertReq = UpsertReq.builder()
.collectionName("my_collection")
.data(data)
.build();
UpsertResp upsertResp = client.upsert(upsertReq);
System.out.println(upsertResp);
// Output:
//
// UpsertResp(upsertCnt=3)
const { MilvusClient, DataType } = require("@zilliz/milvus2-sdk-node")
const address = "YOUR_CLUSTER_ENDPOINT";
const token = "YOUR_CLUSTER_TOKEN";
const client = new MilvusClient({address, token});
data = [
{id: 0, vector: [-0.619954382375778, 0.4479436794798608, -0.17493894838751745, -0.4248030059917294, -0.8648452746018911], title: "Artificial Intelligence in Real Life", issue: "vol.12"},
{id: 1, vector: [0.4762662251462588, -0.6942502138717026, -0.4490002642657902, -0.628696575798281, 0.9660395877041965], title: "Hollow Man", issue: "vol.19"},
{id: 2, vector: [-0.8864122635045097, 0.9260170474445351, 0.801326976181461, 0.6383943392381306, 0.7563037341572827], title: "Treasure Hunt in Missouri", issue: "vol.12"},
]
res = await client.upsert({
collection_name: "my_collection",
data: data,
})
console.log(res.upsert_cnt)
// Output
//
// 3
//
import (
"context"
"fmt"
"github.com/milvus-io/milvus/client/v2/column"
"github.com/milvus-io/milvus/client/v2/milvusclient"
)
ctx, cancel := context.WithCancel(context.Background())
defer cancel()
milvusAddr := "YOUR_CLUSTER_ENDPOINT"
client, err := milvusclient.New(ctx, &milvusclient.ClientConfig{
Address: milvusAddr,
})
if err != nil {
fmt.Println(err.Error())
// handle error
}
defer client.Close(ctx)
titleColumn := column.NewColumnString("title", []string{
"Artificial Intelligence in Real Life", "Hollow Man", "Treasure Hunt in Missouri",
})
issueColumn := column.NewColumnString("issue", []string{
"vol.12", "vol.19", "vol.12"
})
_, err = client.Upsert(ctx, milvusclient.NewColumnBasedInsertOption("my_collection").
WithInt64Column("id", []int64{0, 1, 2, 3, 4, 5, 6, 7, 8, 9}).
WithFloatVectorColumn("vector", 5, [][]float32{
{0.3580376395471989, -0.6023495712049978, 0.18414012509913835, -0.26286205330961354, 0.9029438446296592},
{0.19886812562848388, 0.06023560599112088, 0.6976963061752597, 0.2614474506242501, 0.838729485096104},
{0.43742130801983836, -0.5597502546264526, 0.6457887650909682, 0.7894058910881185, 0.20785793220625592},
}).
WithColumns(titleColumn, issueColumn),
)
if err != nil {
fmt.Println(err.Error())
// handle err
}
export CLUSTER_ENDPOINT="YOUR_CLUSTER_ENDPOINT"
export TOKEN="YOUR_CLUSTER_TOKEN"
curl --request POST \
--url "${CLUSTER_ENDPOINT}/v2/vectordb/entities/upsert" \
--header "Authorization: Bearer ${TOKEN}" \
--header "Content-Type: application/json" \
--header "Request-Timeout: 10" \
-d '{
"data": [
{"id": 0, "vector": [0.3580376395471989, -0.6023495712049978, 0.18414012509913835, -0.26286205330961354, 0.9029438446296592], "title": "Artificial Intelligence in Real Life", "issue": "vol.12"},
{"id": 1, "vector": [0.19886812562848388, 0.06023560599112088, 0.6976963061752597, 0.2614474506242501, 0.838729485096104], "title": "Hollow Man", "issue": "vol.19"},
{"id": 2, "vector": [0.43742130801983836, -0.5597502546264526, 0.6457887650909682, 0.7894058910881185, 0.20785793220625592], "title": "Treasure Hunt in Missouri", "issue": "vol.12"},
],
"collectionName": "my_collection"
}'
# {
# "code": 0,
# "data": {
# "upsertCount": 3,
# "upsertIds": [
# 0,
# 1,
# 2,
# ]
# }
# }
Upsert entities in a partition
You can also upsert entities into a specified partition. The following code snippets assume that you have a partition named PartitionA in your collection.
The three entities, if exists in the partition, will be overridden by those included in the request.
- Python
- Java
- NodeJS
- Go
- cURL
data=[
{
"id": 10,
"vector": [0.06998888224297328, 0.8582816610326578, -0.9657938677934292, 0.6527905683627726, -0.8668460657158576],
"title": "Layour Design Reference",
"issue": "vol.34"
},
{
"id": 11,
"vector": [0.6060703043917468, -0.3765080534566074, -0.7710758854987239, 0.36993888322346136, 0.5507513364206531],
"title": "Doraemon and His Friends",
"issue": "vol.2"
},
{
"id": 12,
"vector": [-0.9041813104515337, -0.9610546012461163, 0.20033003106083358, 0.11842506351635174, 0.8327356724591011],
"title": "Pikkachu and Pokemon",
"issue": "vol.12"
},
]
res = client.upsert(
collection_name="my_collection",
data=data,
partition_name="partitionA"
)
print(res)
# Output
# {'upsert_count': 3}
import io.milvus.v2.service.vector.request.UpsertReq;
import io.milvus.v2.service.vector.response.UpsertResp;
Gson gson = new Gson();
List<JsonObject> data = Arrays.asList(
gson.fromJson("{\"id\": 10, \"vector\": [0.06998888224297328, 0.8582816610326578, -0.9657938677934292, 0.6527905683627726, -0.8668460657158576], \"title\": \"Layour Design Reference\", \"issue\": \"vol.34\"}", JsonObject.class),
gson.fromJson("{\"id\": 11, \"vector\": [0.6060703043917468, -0.3765080534566074, -0.7710758854987239, 0.36993888322346136, 0.5507513364206531], \"title\": \"Doraemon and His Friends\", \"issue\": \"vol.2\"}", JsonObject.class),
gson.fromJson("{\"id\": 12, \"vector\": [-0.9041813104515337, -0.9610546012461163, 0.20033003106083358, 0.11842506351635174, 0.8327356724591011], \"title\": \"Pikkachu and Pokemon\", \"issue\": \"vol.12\"}", JsonObject.class),
);
UpsertReq upsertReq = UpsertReq.builder()
.collectionName("my_collection")
.partitionName("partitionA")
.data(data)
.build();
UpsertResp upsertResp = client.upsert(upsertReq);
System.out.println(upsertResp);
// Output:
//
// UpsertResp(upsertCnt=3)
const { MilvusClient, DataType } = require("@zilliz/milvus2-sdk-node")
// 6. Upsert data in partitions
data = [
{id: 10, vector: [0.06998888224297328, 0.8582816610326578, -0.9657938677934292, 0.6527905683627726, -0.8668460657158576], title: "Layour Design Reference", issue: "vol.34"},
{id: 11, vector: [0.6060703043917468, -0.3765080534566074, -0.7710758854987239, 0.36993888322346136, 0.5507513364206531], title: "Doraemon and His Friends", issue: "vol.2"},
{id: 12, vector: [-0.9041813104515337, -0.9610546012461163, 0.20033003106083358, 0.11842506351635174, 0.8327356724591011], title: "Pikkachu and Pokemon", issue: "vol.12"},
]
res = await client.upsert({
collection_name: "my_collection",
data: data,
partition_name: "partitionA"
})
console.log(res.upsert_cnt)
// Output
//
// 3
//
titleColumn = column.NewColumnString("title", []string{
"Layour Design Reference", "Doraemon and His Friends", "Pikkachu and Pokemon",
})
issueColumn = column.NewColumnString("issue", []string{
"vol.34", "vol.2", "vol.12",
})
_, err = client.Upsert(ctx, milvusclient.NewColumnBasedInsertOption("my_collection").
WithPartition("partitionA").
WithInt64Column("id", []int64{10, 11, 12, 13, 14, 15, 16, 17, 18, 19}).
WithFloatVectorColumn("vector", 5, [][]float32{
{0.3580376395471989, -0.6023495712049978, 0.18414012509913835, -0.26286205330961354, 0.9029438446296592},
{0.19886812562848388, 0.06023560599112088, 0.6976963061752597, 0.2614474506242501, 0.838729485096104},
{0.43742130801983836, -0.5597502546264526, 0.6457887650909682, 0.7894058910881185, 0.20785793220625592},
}).
WithColumns(titleColumn, issueColumn),
)
if err != nil {
fmt.Println(err.Error())
// handle err
}
export CLUSTER_ENDPOINT="YOUR_CLUSTER_ENDPOINT"
export TOKEN="YOUR_CLUSTER_TOKEN"
curl --request POST \
--url "${CLUSTER_ENDPOINT}/v2/vectordb/entities/upsert" \
--header "Authorization: Bearer ${TOKEN}" \
--header "Content-Type: application/json" \
--header "Request-Timeout: 10" \
-d '{
"data": [
{"id": 10, "vector": [0.06998888224297328, 0.8582816610326578, -0.9657938677934292, 0.6527905683627726, -0.8668460657158576], "title": "Layour Design Reference", "issue": "vol.34"},
{"id": 11, "vector": [0.6060703043917468, -0.3765080534566074, -0.7710758854987239, 0.36993888322346136, 0.5507513364206531], "title": "Doraemon and His Friends", "issue": "vol.2"},
{"id": 12, "vector": [-0.9041813104515337, -0.9610546012461163, 0.20033003106083358, 0.11842506351635174, 0.8327356724591011], "title": "Pikkachu and Pokemon", "issue": "vol.12"},
],
"collectionName": "my_collection",
"partitionName": "partitionA"
}'
# {
# "code": 0,
# "data": {
# "upsertCount": 3,
# "upsertIds": [
# 10,
# 11,
# 12,
# ]
# }
# }
Upsert entities in merge mode
The following code example demonstrates how to upsert entities with partial updates. Provide only the fields needing updates and their new values, along with the explicit partial update flag.
In the following example, the issue field of the entities specified in the upsert request will be updated to the values included in the request.
When performing an upsert in merge mode, ensure that the entities involved in the request have the same set of fields. Suppose there are two or more entities to be upserted, as shown in the following code snippet, it is important that they include identical fields to prevent errors and maintain data integrity.
- Python
- Java
- Go
- NodeJS
- cURL
data=[
{
"id": 1,
"issue": "vol.14"
},
{
"id": 2,
"issue": "vol.7"
}
]
res = client.upsert(
collection_name="my_collection",
data=data,
partial_update=True
)
print(res)
# Output
# {'upsert_count': 2}
JsonObject row1 = new JsonObject();
row1.addProperty("id", 1);
row1.addProperty("issue", "vol.14");
JsonObject row2 = new JsonObject();
row2.addProperty("id", 2);
row2.addProperty("issue", "vol.7");
UpsertReq upsertReq = UpsertReq.builder()
.collectionName("my_collection")
.data(Arrays.asList(row1, row2))
.partialUpdate(true)
.build();
UpsertResp upsertResp = client.upsert(upsertReq);
System.out.println(upsertResp);
// Output:
//
// UpsertResp(upsertCnt=2)
pkColumn := column.NewColumnInt64("id", []int64{1, 2})
issueColumn = column.NewColumnString("issue", []string{
"vol.17", "vol.7",
})
_, err = client.Upsert(ctx, milvusclient.NewColumnBasedInsertOption("my_collection").
WithColumns(pkColumn, issueColumn).
WithPartialUpdate(true),
)
if err != nil {
fmt.Println(err.Error())
// handle err
}
const data=[
{
"id": 1,
"issue": "vol.14"
},
{
"id": 2,
"issue": "vol.7"
}
];
const res = await client.upsert({
collection_name: "my_collection",
data,
partial_update: true
});
console.log(res)
// Output
//
// 2
//
export CLUSTER_ENDPOINT="YOUR_CLUSTER_ENDPOINT"
export TOKEN="YOUR_CLUSTER_TOKEN"
export COLLECTION_NAME="my_collection"
export UPSERT_DATA='[
{
"id": 1,
"issue": "vol.14"
},
{
"id": 2,
"issue": "vol.7"
}
]'
curl -X POST "YOUR_CLUSTER_ENDPOINT/v2/vectordb/entities/upsert" \
-H "Content-Type: application/json" \
-H "Authorization: Bearer ${TOKEN}" \
-H "Request-Timeout: 10" \
-d "{
\"collectionName\": \"${COLLECTION_NAME}\",
\"data\": ${UPSERT_DATA},
\"partialUpdate\": true
}"
# {
# "code": 0,
# "data": {
# "upsertCount": 2,
# "upsertIds": [
# 3,
# 12,
# ]
# }
# }
Upsert ARRAY fields with partial-update operators
Before introducing partial-update operators (ARRAY_APPEND and ARRAY_REMOVE), updating part of an ARRAY field required a client-side read-modify-write flow: query the existing array, change it in application code, and upsert the full replacement value. Partial-update operators let you send only the elements to append or remove, which reduces client-side logic and avoids the extra read before the upsert.
Suppose the entity with primary key 1 already has tags = ["new", "trial"]. Before partial-update operators, adding element "premium" to an array required upserting the full replacement array:
- Python
- Java
- NodeJS
- Go
- cURL
client.upsert(
collection_name="users",
data=[{"pk": 1, "tags": ["new", "trial", "premium"]}],
partial_update=True,
)
List<JsonObject> replacementData = Collections.singletonList(
gson.fromJson("{\"pk\": 1, \"tags\": [\"new\", \"trial\", \"premium\"]}", JsonObject.class)
);
client.upsert(UpsertReq.builder()
.collectionName("users")
.partialUpdate(true)
.data(replacementData)
.build());
// nodejs
// go
# restful
With ARRAY_APPEND, send only the element to add:
- Python
- Java
- NodeJS
- Go
- cURL
client.upsert(
collection_name="users",
data=[{"pk": 1, "tags": ["premium"]}],
field_ops={"tags": FieldOp.array_append()},
)
List<JsonObject> appendData = Collections.singletonList(
gson.fromJson("{\"pk\": 1, \"tags\": [\"premium\"]}", JsonObject.class)
);
UpsertReq.FieldPartialUpdateOp appendTags = UpsertReq.FieldPartialUpdateOp.builder()
.fieldName("tags")
.opType(UpsertReq.FieldPartialUpdateOp.OpType.ARRAY_APPEND)
.build();
client.upsert(UpsertReq.builder()
.collectionName("users")
.partialUpdate(true)
.data(appendData)
.fieldOps(Collections.singletonList(appendTags))
.build());
// nodejs
// go
# restful
Attaching either operator to a field via field_ops implicitly enables partial-update semantics. Therefore, you do not need to pass partial_update=True alongside field_ops.
Limits
-
The payload values must match the
element_typeof the targetARRAYfield. For example, if the target field isARRAY<VARCHAR>, the payload must contain string values. -
For this release,
ARRAY_APPENDandARRAY_REMOVEsupportARRAYfields whoseelement_typeisBOOL,INT8,INT16,INT32,INT64,FLOAT,DOUBLE, orVARCHAR. -
After an
ARRAY_APPENDoperation, the resulting array length must not exceed the field'smax_capacity. -
Concurrent upserts to the same entity are not atomic across requests. If two requests update the same
ARRAYfield at the same time, the later write can overwrite the earlier one. Use application-level coordination if you need to preserve all concurrent changes.
Example
The following example uses a small users collection with a primary key pk, a tags field of type ARRAY<VARCHAR>, and an embedding vector field. It first inserts two entities with initial tags values, then uses ARRAY_APPEND and ARRAY_REMOVE to show how each operator changes the stored array.
- Python
- Java
- NodeJS
- Go
- cURL
from pymilvus import DataType, FieldOp, MilvusClient
client = MilvusClient(
uri="YOUR_CLUSTER_ENDPOINT",
token="YOUR_CLUSTER_TOKEN"
)
# 1. Create a collection with an ARRAY<VARCHAR> field
schema = client.create_schema(enable_dynamic_field=False)
schema.add_field("pk", DataType.INT64, is_primary=True)
schema.add_field("embedding", DataType.FLOAT_VECTOR, dim=5)
schema.add_field(
"tags",
DataType.ARRAY,
element_type=DataType.VARCHAR,
max_capacity=8,
max_length=32,
)
index_params = client.prepare_index_params()
index_params.add_index(
field_name="embedding",
index_type="AUTOINDEX",
metric_type="L2",
)
client.create_collection(
collection_name="users",
schema=schema,
index_params=index_params
)
# 2. Seed two entities
client.insert(
collection_name="users",
data=[
{"pk": 1, "embedding": [0.1, 0.2, 0.3, 0.4, 0.5], "tags": ["new"]},
{"pk": 2, "embedding": [0.6, 0.7, 0.8, 0.9, 1.0], "tags": ["new", "trial"]},
],
)
# 3. Append tags without reading the existing ARRAY values
client.upsert(
collection_name="users",
data=[
{"pk": 1, "tags": ["premium", "vip"]},
{"pk": 2, "tags": ["premium"]},
],
field_ops={"tags": FieldOp.array_append()},
)
res = client.query(
collection_name="users",
filter="pk in [1, 2]",
output_fields=["pk", "tags"],
)
print(res)
# Example output:
# data: [
# "{'pk': 1, 'tags': ['new', 'premium', 'vip']}",
# "{'pk': 2, 'tags': ['new', 'trial', 'premium']}"
# ]
# 4. Remove matching tags without replacing the full ARRAY field
client.upsert(
collection_name="users",
data=[
{"pk": 1, "tags": ["new"]},
{"pk": 2, "tags": ["trial"]},
],
field_ops={"tags": FieldOp.array_remove()},
)
res = client.query(
collection_name="users",
filter="pk in [1, 2]",
output_fields=["pk", "tags"],
)
print(res)
# Example output:
# data: [
# "{'pk': 1, 'tags': ['premium', 'vip']}",
# "{'pk': 2, 'tags': ['new', 'premium']}"
# ]
import com.google.gson.Gson;
import com.google.gson.JsonObject;
import io.milvus.v2.client.ConnectConfig;
import io.milvus.v2.client.MilvusClientV2;
import io.milvus.v2.common.ConsistencyLevel;
import io.milvus.v2.common.DataType;
import io.milvus.v2.common.IndexParam;
import io.milvus.v2.service.collection.request.AddFieldReq;
import io.milvus.v2.service.collection.request.CreateCollectionReq;
import io.milvus.v2.service.vector.request.InsertReq;
import io.milvus.v2.service.vector.request.QueryReq;
import io.milvus.v2.service.vector.request.UpsertReq;
import io.milvus.v2.service.vector.response.QueryResp;
import java.util.Arrays;
import java.util.Collections;
import java.util.List;
MilvusClientV2 client = new MilvusClientV2(ConnectConfig.builder()
.uri("YOUR_CLUSTER_ENDPOINT")
.token("YOUR_CLUSTER_TOKEN")
.build());
Gson gson = new Gson();
// 1. Create a collection with an ARRAY<VARCHAR> field
CreateCollectionReq.CollectionSchema schema = CreateCollectionReq.CollectionSchema.builder()
.enableDynamicField(false)
.build();
schema.addField(AddFieldReq.builder()
.fieldName("pk")
.dataType(DataType.Int64)
.isPrimaryKey(true)
.build());
schema.addField(AddFieldReq.builder()
.fieldName("embedding")
.dataType(DataType.FloatVector)
.dimension(5)
.build());
schema.addField(AddFieldReq.builder()
.fieldName("tags")
.dataType(DataType.Array)
.elementType(DataType.VarChar)
.maxCapacity(8)
.maxLength(32)
.build());
List<IndexParam> indexParams = Collections.singletonList(IndexParam.builder()
.fieldName("embedding")
.indexType(IndexParam.IndexType.AUTOINDEX)
.metricType(IndexParam.MetricType.L2)
.build());
client.createCollection(CreateCollectionReq.builder()
.collectionName("users")
.collectionSchema(schema)
.indexParams(indexParams)
.consistencyLevel(ConsistencyLevel.STRONG)
.build());
// 2. Seed two entities
List<JsonObject> data = Arrays.asList(
gson.fromJson("{\"pk\": 1, \"embedding\": [0.1, 0.2, 0.3, 0.4, 0.5], \"tags\": [\"new\"]}", JsonObject.class),
gson.fromJson("{\"pk\": 2, \"embedding\": [0.6, 0.7, 0.8, 0.9, 1.0], \"tags\": [\"new\", \"trial\"]}", JsonObject.class)
);
client.insert(InsertReq.builder()
.collectionName("users")
.data(data)
.build());
// 3. Append tags without reading the existing ARRAY values
List<JsonObject> appendData = Arrays.asList(
gson.fromJson("{\"pk\": 1, \"tags\": [\"premium\", \"vip\"]}", JsonObject.class),
gson.fromJson("{\"pk\": 2, \"tags\": [\"premium\"]}", JsonObject.class)
);
UpsertReq.FieldPartialUpdateOp appendTags = UpsertReq.FieldPartialUpdateOp.builder()
.fieldName("tags")
.opType(UpsertReq.FieldPartialUpdateOp.OpType.ARRAY_APPEND)
.build();
client.upsert(UpsertReq.builder()
.collectionName("users")
.partialUpdate(true)
.data(appendData)
.fieldOps(Collections.singletonList(appendTags))
.build());
QueryResp res = client.query(QueryReq.builder()
.collectionName("users")
.filter("pk in [1, 2]")
.outputFields(Arrays.asList("pk", "tags"))
.consistencyLevel(ConsistencyLevel.STRONG)
.build());
System.out.println(res);
// Example output:
// [
// {"pk": 1, "tags": ["new", "premium", "vip"]},
// {"pk": 2, "tags": ["new", "trial", "premium"]}
// ]
// 4. Remove matching tags without replacing the full ARRAY field
List<JsonObject> removeData = Arrays.asList(
gson.fromJson("{\"pk\": 1, \"tags\": [\"new\"]}", JsonObject.class),
gson.fromJson("{\"pk\": 2, \"tags\": [\"trial\"]}", JsonObject.class)
);
UpsertReq.FieldPartialUpdateOp removeTags = UpsertReq.FieldPartialUpdateOp.builder()
.fieldName("tags")
.opType(UpsertReq.FieldPartialUpdateOp.OpType.ARRAY_REMOVE)
.build();
client.upsert(UpsertReq.builder()
.collectionName("users")
.partialUpdate(true)
.data(removeData)
.fieldOps(Collections.singletonList(removeTags))
.build());
res = client.query(QueryReq.builder()
.collectionName("users")
.filter("pk in [1, 2]")
.outputFields(Arrays.asList("pk", "tags"))
.consistencyLevel(ConsistencyLevel.STRONG)
.build());
System.out.println(res);
// Example output:
// [
// {"pk": 1, "tags": ["premium", "vip"]},
// {"pk": 2, "tags": ["new", "premium"]}
// ]
// nodejs
// go
# restful