Choose the Right Analyzer for Your Use Case
This guide helps you select and configure the most suitable analyzer for your text content in Zilliz Cloud.
It focuses on practical decision-making: what analyzer to use, when to customize one, and how to verify your configuration. For background on analyzer components and parameters, see Analyzer Overview.
Quick concept: How analyzers work
An analyzer processes textual data so that it becomes searchable for features like full text search (BM25-based), phrase match, or text match. It transforms your raw text into discrete searchable tokens through a two-stage pipeline.
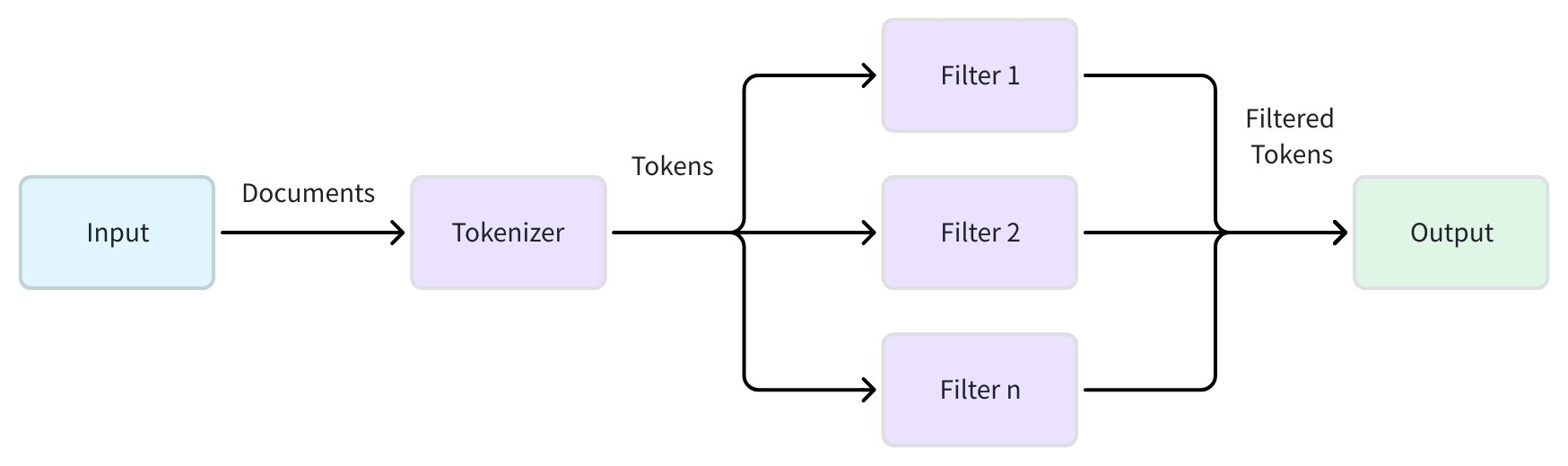
-
Tokenization (required): This initial stage applies a tokenizer to break a continuous string of text into discrete, meaningful units called tokens. The tokenization method can vary significantly depending on the language and content type.
-
Token filtering (optional): After tokenization, filters are applied to modify, remove, or refine the tokens. These operations can include converting all tokens to lowercase, removing common meaningless words (such as stopwords), or reducing words to their root form (stemming).
Example:
Input: "Hello World!"
1. Tokenization → ["Hello", "World", "!"]
2. Lowercase & Punctuation Filtering → ["hello", "world"]
Why the choice of analyzer matters
The analyzer you choose directly affects search quality and relevance.
An inappropriate analyzer can cause either under- or over-tokenization, missing terms, or irrelevant results.
Problem | Symptom | Example (Input & Output) | Cause (Bad Analyzer) | Solution (Good Analyzer) |
|---|---|---|---|---|
Over-tokenization | Technical terms, identifiers, or URLs split incorrectly |
|
| Use a |
Under-tokenization | Multi-word phrases treated as single token |
| Analyzer with a | Use a |
Language Mismatches | Foreign-language results meaningless | Chinese text: |
| Use a language-specific analyzer, such as |
Step 1: Do you need to choose an analyzer?
If you’re using text retrieval features (e.g., full text search, phrase match, or text match) but don’t explicitly specify an analyzer,
Zilliz Cloud automatically applies the standard analyzer.
Standard analyzer behavior:
-
Splits text on spaces and punctuation
-
Converts all tokens to lowercase
Example transformation:
Input: "The Milvus vector database is built for scale!"
Output: ['the', 'milvus', 'vector', 'database', 'is', 'built', 'for', 'scale']
Step 2: Check if the standard analyzer meets your needs
Use this table to quickly determine if the default standard analyzer meets your needs. If it doesn't, you'll need to choose a different path.
Your Content | Standard Analyzer OK? | Why | What You Need |
|---|---|---|---|
English blog posts | ✅ Yes | Default behavior is sufficient. | Use the default (no configuration needed). |
Chinese documents | ❌ No | Chinese words have no spaces and will be treated as one token. | Use a built-in |
Technical documentation | ❌ No | Punctuation is stripped from terms like | Create a custom analyzer with a |
Space-separated languages such as French/Spanish text | ⚠️ Maybe | Accented characters ( | A custom analyzer with the |
Multilingual or unknown languages | ❌ No | The | Use a custom analyzer with the Alternatively, consider configuring multi-language analyzers or a language identifier for more precise handling of multilingual content. |
Step 3: Choose your path
If the default standard analyzer is insufficient, select one of two paths:
-
Path A – Use a built-in analyzer (ready-to-use, language-specific)
-
Path B – Create a custom analyzer (manually define tokenizer + a set of filters)
Path A: Use built-in analyzers
Built-in analyzers are pre-configured solutions for common languages. They are the easiest way to get started when the default standard analyzer isn't a perfect fit.
Available built-in analyzers
Analyzer | Language Support | Components | Notes |
|---|---|---|---|
Most space-separated languages (English, French, German, Spanish, etc.) |
| General-purpose analyzer for initial text processing. For monolingual scenarios, language-specific analyzers (like | |
Dedicated to English, which applies stemming and stop word removal for better English semantic matching |
| Recommended for English-only content over | |
Chinese |
| Currently uses Simplified Chinese dictionary by default. |
Implementation example
To use a built-in analyzer, simply specify its type in the analyzer_params when defining your field schema.
# Using built-in English analyzer
analyzer_params = {
"type": "english"
}
# Applying analyzer config to target VARCHAR field in your collection schema
schema.add_field(
field_name='text',
datatype=DataType.VARCHAR,
max_length=200,
enable_analyzer=True,
analyzer_params=analyzer_params,
)
For detailed usage, refer to Full Text Search, Text Match, or Phrase Match.
Path B: Create a custom analyzer
When built-in options don't meet your needs, you can create a custom analyzer by combining a tokenizer with a set of filters. This gives you full control over the text processing pipeline.
Step 1: Select the tokenizer based on language
Choose your tokenizer based on your content's primary language:
Western languages
For space-separated languages, you have these options:
Tokenizer | How It Works | Best For | Examples |
|---|---|---|---|
Splits text based on spaces and punctuation marks | General text, mixed punctuation |
| |
Splits only on whitespace characters | Pre-processed content, user-formatted text |
|
East Asian languages
Dictionary-based languages require specialized tokenizers for proper word segmentation:
Chinese
Tokenizer | How It Works | Best For | Examples |
|---|---|---|---|
Chinese dictionary-based segmentation with intelligent algorithm | Recommended for Chinese content - combines dictionary with intelligent algorithms, specifically designed for Chinese |
| |
Pure dictionary-based morphological analysis with Chinese dictionary (cc-cedict) | Compared to |
|
Japanese and Korean
Language | Tokenizer | Dictionary Options | Best For | Examples |
|---|---|---|---|---|
Japanese | ipadic (general-purpose), ipadic-neologd (modern terms), unidic (academic) | Morphological analysis with proper noun handling |
| |
Korean | Korean morphological analysis |
|
Multilingual or unknown languages
For content where languages are unpredictable or mixed within documents:
Tokenizer | How It Works | Best For | Examples |
|---|---|---|---|
Unicode-aware tokenization (International Components for Unicode) | Mixed scripts, unknown languages, or when simple tokenization is sufficient |
|
When to use icu:
-
Mixed languages where language identification is impractical.
-
You don't want the overhead of multi-language analyzers or the language identifier.
-
Content has a primary language with occasional foreign words that contribute little to the overall meaning (e.g., English text with sporadic brand names or technical terms in Japanese or French).
Alternative approaches: For more precise handling of multilingual content, consider using multi-language analyzers or the language identifier. For details, refer to Multi-language Analyzers or Language Identifier.
Step 2: Add filters for precision
After selecting your tokenizer, apply filters based on your specific search requirements and content characteristics.
Commonly used filters
These filters are essential for most space-separated language configurations (English, French, German, Spanish, etc.) and significantly improve search quality:
Filter | How It Works | When to Use | Examples |
|---|---|---|---|
Convert all tokens to lowercase | Universal - applies to all languages with case distinctions |
| |
Reduce words to their root form | Languages with word inflections (English, French, German, etc.) | For English:
| |
Remove common meaningless words | Most languages - particularly effective for space-separated languages |
|
For East Asian languages (Chinese, Japanese, Korean, etc.), focus on language-specific filters instead. These languages typically use different approaches for text processing and may not benefit significantly from stemming.
Text normalization filters
These filters standardize text variations to improve matching consistency:
Filter | How It Works | When to Use | Examples |
|---|---|---|---|
Convert accented characters to ASCII equivalents | International content, user-generated content |
|
Token filtering
Control which tokens are preserved based on character content or length:
Filter | How It Works | When to Use | Examples |
|---|---|---|---|
Remove standalone punctuation tokens | Clean output from |
| |
Keep only letters and numbers | Technical content, clean text processing |
| |
Remove tokens outside specified length range | Filter noise (exccessively long tokens) |
| |
Custom pattern-based filtering | Domain-specific token requirements |
|
Language-specific filters
These filters handle specific language characteristics:
Filter | Language | How It Works | Examples |
|---|---|---|---|
German | Splits compound words into searchable components |
| |
Chinese | Keeps Chinese characters + alphanumeric |
| |
Chinese | Keeps only Chinese characters |
|
Step 3: Combine and implement
To create your custom analyzer, you define the tokenizer and a list of filters in the analyzer_params dictionary. The filters are applied in the order they are listed.
# Example: A custom analyzer for technical content
analyzer_params = {
"tokenizer": "whitespace",
"filter": ["lowercase", "alphanumonly"]
}
# Applying analyzer config to target VARCHAR field in your collection schema
schema.add_field(
field_name='text',
datatype=DataType.VARCHAR,
max_length=200,
enable_analyzer=True,
analyzer_params=analyzer_params,
)
Final: Test with run_analyzer
Always validate your configuration before applying to a collection:
# Sample text to analyze
sample_text = "The Milvus vector database is built for scale!"
# Run analyzer with the defined configuration
result = client.run_analyzer(sample_text, analyzer_params)
print("Analyzer output:", result)
Common issues to check:
-
Over-tokenization: Technical terms being split incorrectly
-
Under-tokenization: Phrases not being separated properly
-
Missing tokens: Important terms being filtered out
For detailed usage, refer to run_analyzer.
Quick recipes by use case
This section provides recommended tokenizer and filter configurations for common use cases when working with analyzers in Zilliz Cloud. Choose the combination that best matches your content type and search requirements.
Before applying an analyzer to your collection, we recommend you use run_analyzer to test and validate text analysis performance.
English
analyzer_params = {
"tokenizer": "standard",
"filter": [
"lowercase",
{
"type": "stemmer",
"language": "english"
},
{
"type": "stop",
"stop_words": [
"_english_"
]
}
]
}
Chinese
{
"tokenizer": "jieba",
"filter": ["cnalphanumonly"]
}
Arabic
{
"tokenizer": "standard",
"filter": [
"lowercase",
{
"type": "stemmer",
"language": "arabic"
}
]
}
Bengali
{
"tokenizer": "icu",
"filter": ["lowercase", {
"type": "stop",
"stop_words": [<put stop words list here>]
}]
}
French
{
"tokenizer": "standard",
"filter": [
"lowercase",
{
"type": "stemmer",
"language": "french"
},
{
"type": "stop",
"stop_words": [
"_french_"
]
}
]
}
German
{
"tokenizer": {
"type": "lindera",
"dict_kind": "ipadic"
},
"filter": [
"removepunct"
]
}
Hindi
{
"tokenizer": "icu",
"filter": ["lowercase", {
"type": "stop",
"stop_words": [<put stop words list here>]
}]
}
Korean
{
"tokenizer": {
"type": "lindera",
"dict_kind": "ko-dic",
"filter": [
{
"kind": "korean_stop_tags",
"tags": ["SP", "SSC", "SSO", "SC", "SE", "SF", "JKS", "JKC", "JKG", "JKO", "JKB", "JKV", "JKQ", "JX", "JC", "UNK", "EP", "ETM"]
}
]
}
}
Japanese
{
"tokenizer": {
"type": "lindera",
"dict_kind": "ipadic"
},
"filter": [
"removepunct"
]
}
Portuguese
{
"tokenizer": "standard",
"filter": [
"lowercase",
{
"type": "stemmer",
"language": "portuguese"
},
{
"type": "stop",
"stop_words": [
"_portuguese_"
]
}
]
}
Russian
{
"tokenizer": "standard",
"filter": [
"lowercase",
{
"type": "stemmer",
"language": "russian"
},
{
"type": "stop",
"stop_words": [
"_russian_"
]
}
]
}
Spanish
{
"tokenizer": "standard",
"filter": [
"lowercase",
{
"type": "stemmer",
"language": "spanish"
},
{
"type": "stop",
"stop_words": [
"_spanish_"
]
}
]
}
Swahili
{
"tokenizer": "standard",
"filter": ["lowercase", {
"type": "stop",
"stop_words": [<put stop words list here>]
}]
}
Turkish
{
"tokenizer": "standard",
"filter": [
"lowercase",
{
"type": "stemmer",
"language": "turkish"
}
]
}
Urdu
{
"tokenizer": "icu",
"filter": ["lowercase", {
"type": "stop",
"stop_words": [<put stop words list here>]
}]
}
Mixed or multilingual content
When working with content that spans multiple languages or uses scripts unpredictably, start with the icu analyzer. This Unicode-aware analyzer handles mixed scripts and symbols effectively.
Basic multilingual configuration (no stemming):
analyzer_params = {
"tokenizer": "icu",
"filter": ["lowercase", "asciifolding"]
}
Advanced multilingual processing:
For better control over token behavior across different languages:
-
Use a multi-language analyzer configuration. For details, refer to Multi-language Analyzers.
-
Implement a language identifier on your content. For details, refer to Language Identifier.
Configure and preview analyzers in Zilliz Cloud
In Zilliz Cloud, you can configure and test text analyzers directly from the Zilliz Cloud console, without writing code.