JSON Shredding
JSON shredding accelerates JSON queries by converting traditional row-based storage into optimized columnar storage. While maintaining JSON's flexibility for data modeling, Zilliz Cloud performs behind-the-scenes columnar optimization that dramatically improves access and query efficiency.
JSON shredding is effective for most JSON query scenarios. The performance benefits become more pronounced with:
-
Larger, more complex JSON documents - Greater performance gains as document size increases
-
Read-heavy workloads - Frequent filtering, sorting, or searching on JSON keys
-
Mixed query patterns - Queries across different JSON keys benefit from the hybrid storage approach
How it works
The JSON shredding process happens in three distinct phases to optimize data for fast retrieval.
Phase 1: Ingestion & key classification
As new JSON documents are written, Zilliz Cloud continuously samples and analyzes them to build statistics for each JSON key. This analysis includes the key's occurrence ratio and type stability (whether its data type is consistent across documents).
Based on these statistics, JSON keys are categorized into the following for optimal storage.
Categories of JSON keys
Key Type | Description |
|---|---|
Typed keys | Keys that exist in most documents and always have the same data type (e.g., all integers or all strings). |
Dynamic keys | Keys that appear frequently but have a mixed data type (e.g., sometimes a string, sometimes an integer). |
Shared keys | Infrequently appearing or nested keys that fall below a configurable frequency threshold. |
Example classification
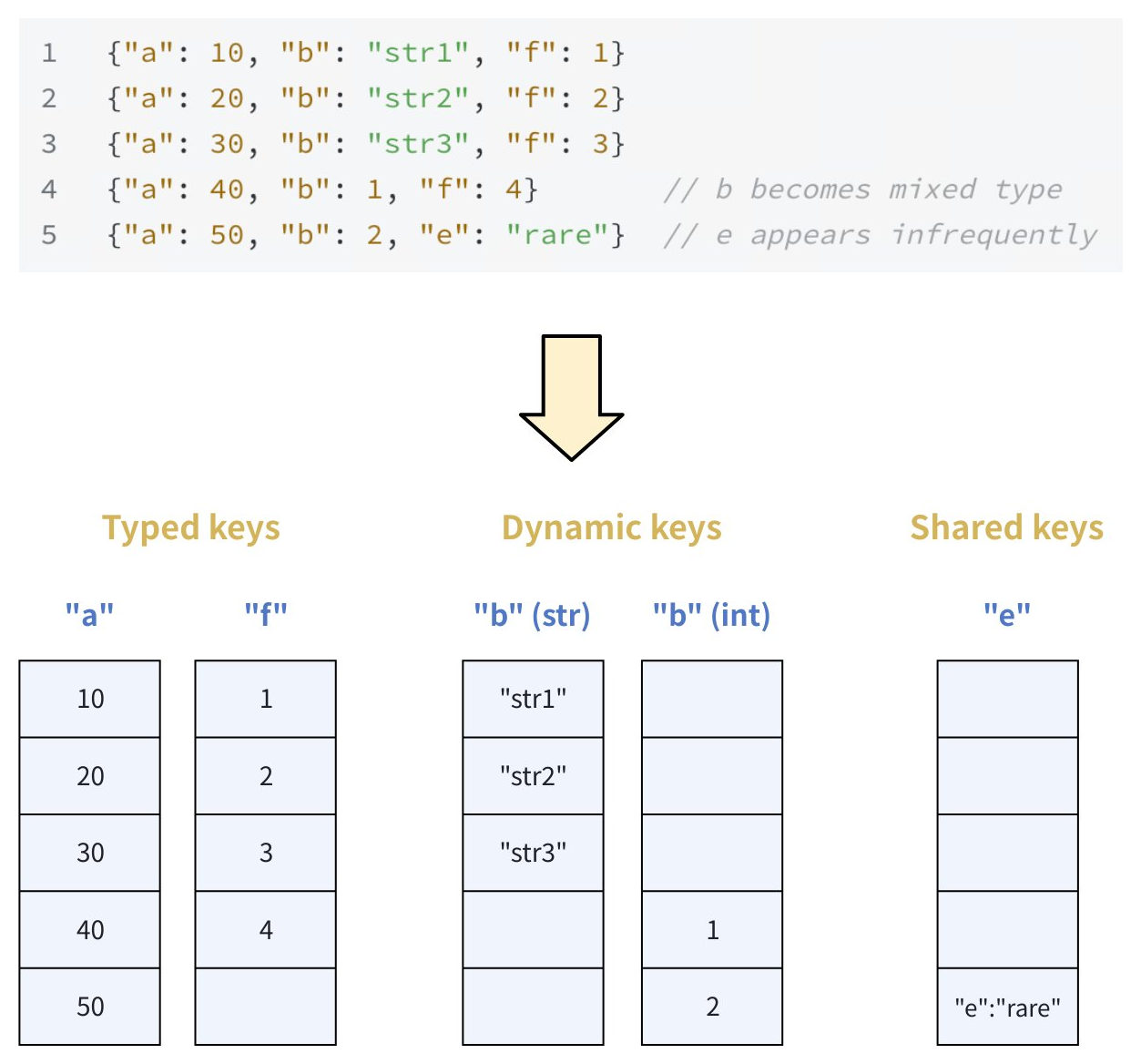
Consider the sample JSON data containing the following JSON keys:
{"a": 10, "b": "str1", "f": 1}
{"a": 20, "b": "str2", "f": 2}
{"a": 30, "b": "str3", "f": 3}
{"a": 40, "b": 1, "f": 4} // b becomes mixed type
{"a": 50, "b": 2, "e": "rare"} // e appears infrequently
Based on this data, the keys would be classified as follows:
-
Typed keys:
aandf(always an integer) -
Dynamic keys:
b(mixed string/integer) -
Shared keys:
e(infrequently appearing key)
Phase 2: Storage optimization
The classification from Phase 1 dictates the storage layout. Zilliz Cloud uses a columnar format optimized for queries.
-
Shredded columns: For typed and dynamic keys, data is written to dedicated columns. This columnar storage allows for fast, direct scans during queries, as Zilliz Cloud can read only the required data for a given key without processing the entire document.
-
Shared column: All shared keys are stored together in a single, compact binary JSON column. A shared-key inverted index is built on this column. This index is crucial for accelerating queries on low-frequency keys by allowing Zilliz Cloud to quickly prune the data, effectively narrowing down the search space to only those rows that contain the specified key.
Phase 3: Query execution
The final phase leverages the optimized storage layout to intelligently select the fastest path for each query predicate.
-
Fast path: Queries on typed/dynamic keys (e.g.,
json['a'] < 100) access dedicated columns directly -
Optimized path: Queries on shared keys (e.g.,
json['e'] = 'rare') use inverted index to quickly locate relevant documents
Performance benchmarks
Our testing demonstrates significant performance improvements across different JSON key types and query patterns.
Test environment and methodology
-
Hardware: 1 core/8GB cluster
-
Dataset: 1 million documents from JSONBench
-
Average document size: 478.89 bytes
-
Test duration: 100 seconds measuring QPS and latency
Results: typed keys
This test measured performance when querying a key present in most documents.
Query Expression | Key Value Type | QPS (without shredding) | QPS (with shredding) | Performance Boost |
|---|---|---|---|---|
| Integer | 8.69 | 287.50 | 33x |
| String | 8.42 | 126.1 | 14.9x |
Results: shared keys
This test focused on querying sparse, nested keys that fall into the "shared" category.
Query Expression | Key Value Type | QPS (without shredding) | QPS (with shredding) | Performance Boost |
|---|---|---|---|---|
| Nested Integer | 4.33 | 385 | 88.9x |
| Nested String | 7.6 | 352 | 46.3x |
Key insights
-
Shared key queries show the most dramatic improvements (up to 89x faster)
-
Typed key queries provide consistent 15-30x performance gains
-
All query types benefit from JSON Shredding with no performance regressions
FAQ
-
How do I select between JSON shredding and JSON indexing?
-
JSON shredding is ideal for keys that appear frequently in your documents, especially for complex JSON structures. It combines the benefits of columnar storage and inverted indexing, making it well-suited for read-heavy scenarios where you query many different keys. However, it is not recommended for very small JSON documents as the performance gain is minimal. The smaller the proportion of the key's value to the total size of the JSON document, the better the performance optimization from shredding.
-
JSON indexing is better for targeted optimization of specific key-based queries and has lower storage overhead. It's suitable for simpler JSON structures. Note that JSON shredding does not cover queries on keys inside arrays, so you need a JSON index to accelerate those.
For details, refer to JSON Field Overview.
-