Weighted Ranker
Weighted Ranker intelligently combines and prioritizes results from multiple search paths by assigning different importance weights to each. Similar to how a skilled chef balances multiple ingredients to create the perfect dish, Weighted Ranker balances different search results to deliver the most relevant combined outcomes. This approach is ideal when searching across multiple vector fields or modalities where certain fields should contribute more significantly to the final ranking than others.
When to use Weighted Ranker
Weighted Ranker is specifically designed for hybrid search scenarios where you need to combine results from multiple vector search paths. It's particularly effective for:
Use Case | Example | Why Weighted Ranker Works Well |
|---|---|---|
E-commerce search | Product search combining image similarity and text description | Allows retailers to prioritize visual similarity for fashion items while emphasizing text descriptions for technical products |
Media content search | Video retrieval using both visual features and audio transcripts | Balances the importance of visual content versus spoken dialogue based on query intent |
Document retrieval | Enterprise document search with multiple embeddings for different sections | Gives higher weight to title and abstract embeddings while still considering full-text embeddings |
If your hybrid search application requires combining multiple search paths while controlling their relative importance, Weighted Ranker is your ideal choice.
Mechanism of Weighted Ranker
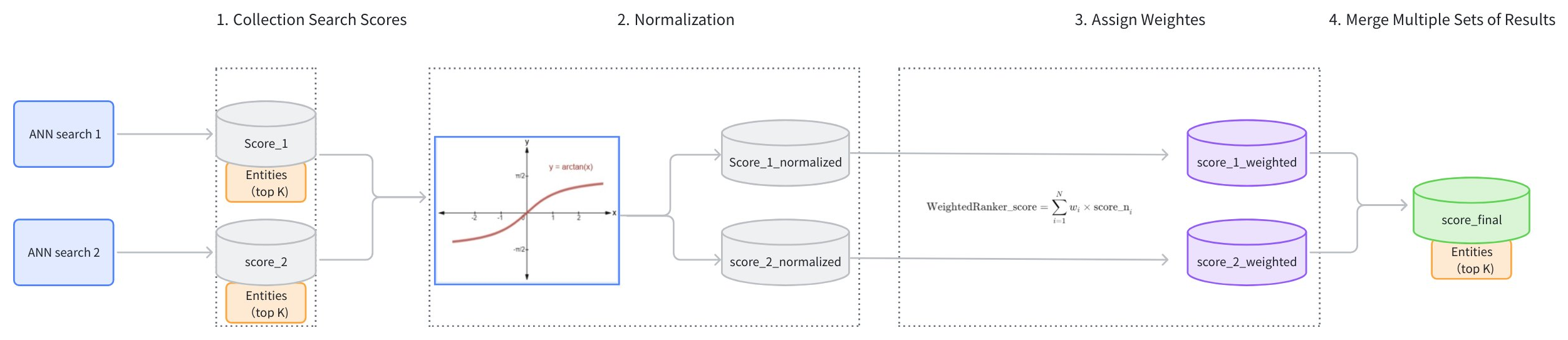
The main workflow of the WeightedRanker strategy is as follows:
-
Collect Search Scores: Gather the results and scores from each path of vector search (score_1, score_2).
-
Score Normalization: Each search may use different similarity metrics, resulting in varied score distributions. For instance, using Inner Product (IP) as a similarity type could result in scores ranging from [−∞,+∞], while using Euclidean distance (L2) results in scores ranging from [0,+∞]. Because the score ranges from different searches vary and cannot be directly compared, it is necessary to normalize the scores from each path of search. Typically,
arctanfunction is applied to transform the scores into a range between [0, 1] (score_1_normalized, score_2_normalized). Scores closer to 1 indicate higher similarity. -
Assign Weights: Based on the importance assigned to different vector fields, weights (wi) are allocated to the normalized scores (score_1_normalized, score_2_normalized). The weights of each path should range between [0,1]. The resulting weighted scores are score_1_weighted and score_2_weighted.
-
Merge Scores: The weighted scores (score_1_weighted, score_2_weighted) are ranked from highest to lowest to produce a final set of scores (score_final).
Example of Weighted Ranker
This example demonstrates a multimodal Hybrid Search (topK=5) involving images and text and illustrates how the WeightedRanker strategy reranks the results from two ANN searches.
-
Results of ANN search on images (topK=5):
ID
Score (image)
101
0.92
203
0.88
150
0.85
198
0.83
175
0.8
-
Results of ANN search on texts (topK=5):
ID
Score (text)
198
0.91
101
0.87
110
0.85
175
0.82
250
0.78
-
Use WeightedRanker assign weights to image and text search results. Suppose the weight for the image ANN search is 0.6 and the weight for the text search is 0.4.
ID
Score (image)
Score (text)
Weighted Score
101
0.92
0.87
0.6×0.92+0.4×0.87=0.90
203
0.88
N/A
0.6×0.88+0.4×0=0.528
150
0.85
N/A
0.6×0.85+0.4×0=0.51
198
0.83
0.91
0.6×0.83+0.4×0.91=0.86
175
0.80
0.82
0.6×0.80+0.4×0.82=0.81
110
Not in Image
0.85
0.6×0+0.4×0.85=0.34
250
Not in Image
0.78
0.6×0+0.4×0.78=0.312
-
The final results after reranking(topK=5):
Rank
ID
Final Score
1
101
0.90
2
198
0.86
3
175
0.81
4
203
0.528
5
150
0.51
Usage of Weighted Ranker
When using the WeightedRanker strategy, it is necessary to input weight values. The number of weight values to input should correspond to the number of basic ANN search requests in the Hybrid Search. The input weight values should fall in the range of [0,1], with values closer to 1 indicating greater importance.
Create a Weighted Ranker
For example, suppose there are two basic ANN search requests in a Hybrid Search: text search and image search. If the text search is considered more important, it should be assigned a greater weight.
- Python
- Java
- NodeJS
- Go
- cURL
from pymilvus import Function, FunctionType
rerank = Function(
name="weight",
input_field_names=[], # Must be an empty list
function_type=FunctionType.RERANK,
params={
"reranker": "weighted",
"weights": [0.1, 0.9],
"norm_score": True # Optional
}
)
import io.milvus.common.clientenum.FunctionType;
import io.milvus.v2.service.collection.request.CreateCollectionReq;
CreateCollectionReq.Function rerank = CreateCollectionReq.Function.builder()
.name("weight")
.functionType(FunctionType.RERANK)
.param("reranker", "weighted")
.param("weights", "[0.1, 0.9]")
.param("norm_score", "true")
.build();
import { FunctionType } from '@zilliz/milvus2-sdk-node';
const rerank = {
name: "weight",
input_field_names: [],
function_type: FunctionType.RERANK,
params: {
reranker: "weighted",
weights: [0.1, 0.9],
norm_score: true
}
};
// Go
# Restful
Parameter | Required? | Description | Value/Example |
|---|---|---|---|
| Yes | Unique identifier for this Function |
|
| Yes | List of vector fields to apply the function to (must be empty for Weighted Ranker) | [] |
| Yes | The type of Function to invoke; use |
|
| Yes | Specifies the reranking method to use. Must be set to |
|
| Yes | Array of weights corresponding to each search path; values ∈ [0,1]. For details, refer to Mechanism of Weighted Ranker. |
|
| No | Whether to normalize raw scores (using arctan) before weighting. For details, refer to Mechanism of Weighted Ranker. |
|
Apply to hybrid search
Weighted Ranker is designed specifically for hybrid search operations that combine multiple vector fields. When performing hybrid search, you must specify the weights for each search path:
- Python
- Java
- NodeJS
- Go
- cURL
from pymilvus import MilvusClient, AnnSearchRequest
# Connect to Milvus server
milvus_client = MilvusClient(
uri="YOUR_CLUSTER_ENDPOINT",
token="YOUR_CLUSTER_TOKEN"
)
# Assume you have a collection setup
# Define text vector search request
text_search = AnnSearchRequest(
data=["modern dining table"],
anns_field="text_vector",
param={},
limit=10
)
# Define image vector search request
image_search = AnnSearchRequest(
data=[image_embedding], # Image embedding vector
anns_field="image_vector",
param={},
limit=10
)
# Apply Weighted Ranker to product hybrid search
# Text search has 0.8 weight, image search has 0.3 weight
hybrid_results = milvus_client.hybrid_search(
collection_name,
[text_search, image_search], # Multiple search requests
ranker=rerank, # Apply the weighted ranker
limit=10,
output_fields=["product_name", "price", "category"]
)
import io.milvus.v2.client.ConnectConfig;
import io.milvus.v2.client.MilvusClientV2;
import io.milvus.v2.service.vector.request.AnnSearchReq;
import io.milvus.v2.service.vector.request.HybridSearchReq;
import io.milvus.v2.service.vector.response.SearchResp;
import io.milvus.v2.service.vector.request.data.EmbeddedText;
import io.milvus.v2.service.vector.request.data.FloatVec;
MilvusClientV2 client = new MilvusClientV2(ConnectConfig.builder()
.uri("YOUR_CLUSTER_ENDPOINT")
.token("YOUR_CLUSTER_TOKEN")
.build());
List<AnnSearchReq> searchRequests = new ArrayList<>();
searchRequests.add(AnnSearchReq.builder()
.vectorFieldName("text_vector")
.vectors(Collections.singletonList(new EmbeddedText("\"modern dining table\"")))
.limit(10)
.build());
searchRequests.add(AnnSearchReq.builder()
.vectorFieldName("image_vector")
.vectors(Collections.singletonList(new FloatVec(imageEmbedding)))
.limit(10)
.build());
HybridSearchReq hybridSearchReq = HybridSearchReq.builder()
.collectionName(COLLECTION_NAME)
.searchRequests(searchRequests)
.ranker(ranker)
.limit(10)
.outputFields(Arrays.asList("product_name", "price", "category"))
.build();
SearchResp searchResp = client.hybridSearch(hybridSearchReq);
import { MilvusClient, FunctionType } from "@zilliz/milvus2-sdk-node";
const milvusClient = new MilvusClient({
address: "YOUR_CLUSTER_ENDPOINT",
token: "YOUR_CLUSTER_TOKEN"
});
const text_search = {
data: ["modern dining table"],
anns_field: "text_vector",
param: {},
limit: 10,
};
const image_search = {
data: [image_embedding],
anns_field: "image_vector",
param: {},
limit: 10,
};
const search = await milvusClient.search({
collection_name: collection_name,
limit: 10,
data: [text_search, image_search],
rerank: rerank,
output_fields = ["product_name", "price", "category"],
});
// go
# restful
For more information on hybrid search, refer to Multi-Vector Hybrid Search.