Use mmap
Memory mapping (Mmap) enables direct memory access to large files on disk, allowing Zilliz Cloud to store indexes and data in both memory and hard drives. This approach helps optimize data placement policy based on access frequency, expanding storage capacity for collections without impacting search performance. This page helps you understand how Zilliz Cloud uses mmap to enable fast and efficient data storage and retrieval.
When migrating or restoring data between source and target clusters that have different plans, the mmap settings of the source collection will not be migrated to the target cluster. Please manually reconfigure the mmap settings on the target cluster.
Zilliz Cloud supports configuring mmap settings programmatically or via the web console. This page focuses on how to set mmap programmatically. For details about operations on the web console, refer to Manage Collections (Console).
Overview
Zilliz Cloud uses collections to organize vector embeddings and their metadata, and each row in the collection represents an entity. As shown in the left figure below, the vector field stores vector embeddings, and the scalar fields store their metadata. When you have created indexes on certain fields and loaded the collection, Zilliz Cloud loads the created indexes and raw data from all fields into memory.
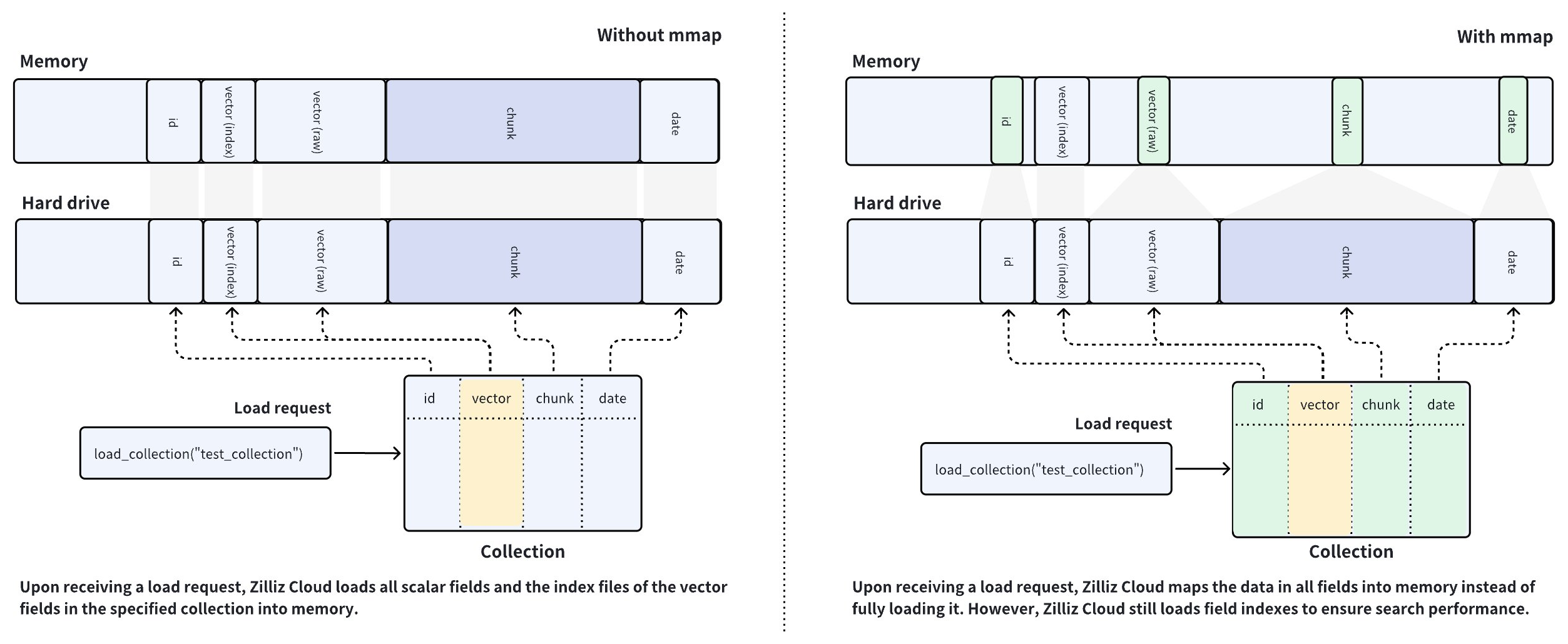
Zilliz Cloud clusters are memory-intensive database systems, and the memory size available determines the capacity of a collection. Loading fields containing a large volume of data into memory is impossible if the data size exceeds the memory capacity, which is the usual case for AI-driven applications.
To resolve such issues, Zilliz Cloud introduces mmap to balance the loading of hot and cold data in collections. As shown in the right figure above, Zilliz Cloud loads only the vector indexes into memory and memory-maps the raw data of all fields and scalar indexes when you load a collection if you are using a Zilliz Cloud cluster with capacity-optimized CUs.
By comparing the data placement procedures in the left and right figures, you can figure out that the memory usage is much higher in the left figure than in the right one. With mmap enabled, the data that should have been loaded into memory is offloaded into the hard drive and cached in the page cache of the operating system, reducing memory footprint. However, cache hit failures may result in performance degradation. For details, refer to this article.
Global mmap strategy
The following table lists the global mmap strategy for clusters from different tiers.
Mmap Target | Dedicated Clusters | Free Clusters Serverless Clusters | ||
|---|---|---|---|---|
Performance-optimized | Capacity-optimized | Tiered-storage | ||
Scalar field raw data | Disabled & Changeable | Enabled & Changeable | Enabled & Unchangeable | |
Scalar field index | Disabled & Changeable | Enabled & Changeable | Enabled & Unchangeable | |
Vector field raw data | Enabled & Changeable | Enabled & Changeable | Enabled & Unchangeable | |
Vector field index | Disabled & Unchangeable | Disabled & Unchangeable | Enabled & Unchangeable | |
In dedicated clusters using the Performance-optimized CUs, Zilliz Cloud enables mmap only for the raw data in vector fields and loads the raw data in scalar fields and all field indexes into memory. You are advised to keep the global settings to ensure the performance of metadata filtering and retrieval during searches and queries. However, you can still enable mmap for those fields that are not involved in metadata filtering or used as output fields.
In dedicated clusters using the Capacity-optimized CUs, Zilliz Cloud disables mmap for the vector field indexes for the sake of auto-indexing and memory-maps the indexes of scalar fields and all field raw data, ensuring the maximum storage capacity. If the raw data of some fields used in metadata filtering conditions or listed in the output fields is too large and leaving them on the hard drive causes slow response or network jitters, you can consider disabling mmap for these fields to improve search performance.
In Free and Serverless clusters and the dedicated clusters using Extended-capacity CUs, Zilliz Cloud enables mmap for the raw data and indexes of all fields to fully utilize the system cache, improve the performance of hot data, and reduce the cost of cold data.
Collection-specific mmap settings
You need to release a collection to make changes to the mmap settings and load it again to make the changes to the mmap settings take effect. You can configure mmap for a specific field, a field index, or a collection.
Exercise with caution when changing mmap settings. Improper mmap settings may cause the following issues:
For performance-optimized dedicated clusters, the raw data of all scalar fields and the vector indexes are loaded into memory by default to ensure fast retrieval of scalar fields during searches and queries. Changing the default mmap settings may cause performance degradation.
For capacity-optimized dedicated clusters, only the vector indexes are loaded into memory by default to ensure maximum storage capacity. Changing the default mmap settings may cause load failures due to out-of-memory (OOM) issues.
Configure mmap for specific fields
If you are using a dedicated cluster with small performance-optimized CUs and the raw data of a field in your dataset is large, consider adding the field to a collection with mmap enabled.
The following example assumes connecting to a performance-optimized dedicated cluster and demonstrates how to enable mmap on a VarChar field named doc_chunk while adding the field.
- Python
- Java
- NodeJS
- Go
- cURL
from pymilvus import MilvusClient, DataType
CLUSTER_ENDPOINT="YOUR_CLUSTER_ENDPOINT"
TOKEN="YOUR_CLUSTER_TOKEN"
client = MilvusClient(
uri=CLUSTER_ENDPOINT,
token=TOKEN
)
schema = MilvusClient.create_schema()
schema.add_field("id", DataType.INT64, is_primary=True, auto_id=False)
schema.add_field("vector", DataType.FLOAT_VECTOR, dim=5)
# Disable mmap on a field upon creating the schema for a collection
schema.add_field(
field_name="doc_chunk",
datatype=DataType.INT64,
max_length=512,
mmap_enabled=False,
)
client.create_collection(collection_name="my_collection", schema=schema)
# Disable mmap on an existing field
# The following assumes that you have a collection named \`my_collection\`
client.alter_collection_field(
collection_name="my_collection",
field_name="doc_chunk",
field_params={"mmap.enabled": True}
)
import io.milvus.param.Constant;
import io.milvus.v2.client.ConnectConfig;
import io.milvus.v2.client.MilvusClientV2;
import io.milvus.v2.common.DataType;
import io.milvus.v2.service.collection.request.*;
import java.util.*;
String CLUSTER_ENDPOINT = "YOUR_CLUSTER_ENDPOINT";
String TOKEN = "YOUR_CLUSTER_TOKEN";
client = new MilvusClientV2(ConnectConfig.builder()
.uri(CLUSTER_ENDPOINT)
.token(TOKEN)
.build());
CreateCollectionReq.CollectionSchema schema = client.createSchema();
schema.addField(AddFieldReq.builder()
.fieldName("id")
.dataType(DataType.Int64)
.isPrimaryKey(true)
.autoID(false)
.build());
schema.addField(AddFieldReq.builder()
.fieldName("vector")
.dataType(DataType.FloatVector)
.dimension(5)
.build());
Map<String, String> typeParams = new HashMap<String, String>() {{
put(Constant.MMAP_ENABLED, "false");
}};
schema.addField(AddFieldReq.builder()
.fieldName("doc_chunk")
.dataType(DataType.VarChar)
.maxLength(512)
.typeParams(typeParams)
.build());
CreateCollectionReq req = CreateCollectionReq.builder()
.collectionName("my_collection")
.collectionSchema(schema)
.build();
client.createCollection(req);
client.alterCollectionField(AlterCollectionFieldReq.builder()
.collectionName("my_collection")
.fieldName("doc_chunk")
.property(Constant.MMAP_ENABLED, "true")
.build());
import { MilvusClient, DataType } from '@zilliz/milvus2-sdk-node';
const CLUSTER_ENDPOINT="YOUR_CLUSTER_ENDPOINT";
const TOKEN="YOUR_TOKEN";
const client = await MilvusClient({
address: CLUSTER_ENDPOINT,
token: TOKEN
});
const schema = [
{
name: 'vector',
data_type: DataType.FloatVector
},
{
name: "doc_chunk",
data_type: DataType.VarChar,
max_length: 512,
'mmap.enabled': false,
}
];
await client.createCollection({
collection_name: "my_collection",
schema: schema
});
await client.alterCollectionFieldProperties({
collection_name: "my_collection",
field_name: "doc_chunk",
properties: {"mmap_enable": true}
});
import (
"context"
"fmt"
"github.com/milvus-io/milvus/client/v2/column"
"github.com/milvus-io/milvus/client/v2/entity"
"github.com/milvus-io/milvus/client/v2/milvusclient"
)
ctx, cancel := context.WithCancel(context.Background())
defer cancel()
milvusAddr := "YOUR_CLUSTER_ENDPOINT"
client, err := milvusclient.New(ctx, &milvusclient.ClientConfig{
Address: milvusAddr,
})
if err != nil {
fmt.Println(err.Error())
// handle error
}
defer client.Close(ctx)
schema := entity.NewSchema().WithDynamicFieldEnabled(false)
schema.WithField(entity.NewField().
WithName("id").
WithDataType(entity.FieldTypeInt64).
WithIsPrimaryKey(true),
).WithField(entity.NewField().
WithName("vector").
WithDataType(entity.FieldTypeFloatVector).
WithDim(5),
).WithField(entity.NewField().
WithName("doc_chunk").
WithDataType(entity.FieldTypeVarChar).
WithMaxLength(512).
WithTypeParams(common.MmapEnabledKey, "false"),
)
err = client.CreateCollection(ctx,
milvusclient.NewCreateCollectionOption("my_collection", schema))
if err != nil {
fmt.Println(err.Error())
// handle error
}
err = client.AlterCollectionFieldProperty(ctx, milvusclient.NewAlterCollectionFieldPropertiesOption("my_collection", "doc_chunk").
WithProperty(common.MmapEnabledKey, "true"))
if err != nil {
fmt.Println(err.Error())
// handle error
}
#restful
export TOKEN="YOUR_CLUSTER_TOKEN"
export CLUSTER_ENDPOINT="YOUR_CLUSTER_ENDPOINT"
export idField='{
"fieldName": "id",
"dataType": "Int64",
"isPrimary": true,
"auto_id": false
}'
export vectorField='{
"fieldName": "vector",
"dataType": "FloatVector",
"elementTypeParams": {
"dim": 5
}
}'
export docChunkField='{
"fieldName": "doc_chunk",
"dataType": "Varchar",
"elementTypeParams": {
"max_length": 512,
"mmap.enabled": false
}
}'
export schema="{
\"autoID\": false,
\"fields\": [
$idField,
$docChunkField,
$vectorField
]
}"
curl --request POST \
--url "${CLUSTER_ENDPOINT}/v2/vectordb/collections/create" \
--header "Authorization: Bearer ${TOKEN}" \
--header "Content-Type: application/json" \
--header "Request-Timeout: 10" \
--data "{
\"collectionName\": \"my_collection\",
\"schema\": $schema
}"
curl --request POST \
--url "${CLUSTER_ENDPOINT}/v2/vectordb/collections/fields/alter_properties" \
--header "Authorization: Bearer ${TOKEN}" \
--header "Content-Type: application/json" \
--header "Request-Timeout: 10" \
-d '{
"collectionName": "my_collection",
"fieldName": "doc_chunk",
"fieldParams":{
"mmap.enabled": true
}
}'
When loading the collection created using the above schema, Zilliz Cloud memory-maps the raw data of the doc_chunk field. Note that you need to release the collection to make changes to the mmap settings of a field and load the collection again after the change.
Configure mmap for scalar indexes
For scalar fields involved in metadata filtering or used as output fields, consider loading them into memory while keeping other scalar fields on the hard drive.
The following example assumes connecting to a capacity-optimized dedicated cluster and demonstrates how to disable mmap on the index of a VarChar field named title for quick retrieval.
- Python
- Java
- NodeJS
- Go
- cURL
# Add a varchar field
schema.add_field(
field_name="title",
datatype=DataType.VARCHAR,
max_length=512
)
index_params = MilvusClient.prepare_index_params()
# Create index on the varchar field with mmap settings
index_params.add_index(
field_name="title",
index_type="AUTOINDEX",
params={ "mmap.enabled": "false" }
)
# Change mmap settings for an index
# The following assumes that you have a collection named \`my_collection\`
client.alter_index_properties(
collection_name="my_collection",
index_name="title",
properties={"mmap.enabled": True}
)
schema.addField(AddFieldReq.builder()
.fieldName("title")
.dataType(DataType.VarChar)
.maxLength(512)
.build());
List<IndexParam> indexParams = new ArrayList<>();
Map<String, Object> extraParams = new HashMap<String, Object>() {{
put(Constant.MMAP_ENABLED, false);
}};
indexParams.add(IndexParam.builder()
.fieldName("title")
.indexType(IndexParam.IndexType.AUTOINDEX)
.extraParams(extraParams)
.build());
client.alterIndexProperties(AlterIndexPropertiesReq.builder()
.collectionName("my_collection")
.indexName("title")
.property(Constant.MMAP_ENABLED, "true")
.build());
// Create index on the varchar field with mmap settings
await client.createIndex({
collection_name: "my_collection",
field_name: "title",
params: { "mmap.enabled": false }
});
// Change mmap settings for an index
// The following assumes that you have a collection named \`my_collection\`
await client.alterIndexProperties({
collection_name: "my_collection",
index_name: "title",
properties:{"mmap.enabled": true}
});
schema.WithField(entity.NewField().
WithName("title").
WithDataType(entity.FieldTypeVarChar).
WithMaxLength(512),
)
indexOption := milvusclient.NewCreateIndexOption("my_collection", "title",
index.NewInvertedIndex())
indexOption.WithExtraParam(common.MmapEnabledKey, "false")
err = client.AlterIndexProperties(ctx, milvusclient.NewAlterIndexPropertiesOption("my_collection", "title").
WithProperty(common.MmapEnabledKey, "true"))
if err != nil {
fmt.Println(err.Error())
// handle error
}
# restful
export TOKEN="YOUR_CLUSTER_TOKEN"
curl --request POST \
--url "${CLUSTER_ENDPOINT}/v2/vectordb/indexes/create" \
--header "Authorization: Bearer ${TOKEN}" \
--header "Content-Type: application/json" \
--header "Request-Timeout: 10" \
-d '{
"collectionName": "my_collection",
"indexParams": [
{
"fieldName": "title",
"params": {
"index_type": "AUTOINDEX",
"mmap.enabled": false
}
}
]
}'
curl --request POST \
--url "${CLUSTER_ENDPOINT}/v2/vectordb/indexes/alter_properties" \
--header "Authorization: Bearer ${TOKEN}" \
--header "Content-Type: application/json" \
--header "Request-Timeout: 10" \
-d '{
"collectionName": "my_collection",
"indexName": "title",
"properties": {
"mmap.enabled": true
}
}'
When loading the collection created using the above index parameters, Zilliz Cloud loads the index of the title field into memory. Note that you need to release the collection to make changes to the mmap settings of a field and load the collection again after the change.
Configure mmap in collection
You can disable mmap settings in a collection so that Zilliz Cloud fully loads the raw data of all fields into memory.
The following example assumes connecting to a performance-optimized dedicated cluster and demonstrates how to disable mmap when you create a collection.
- Python
- Java
- NodeJS
- Go
- cURL
# Enable mmap when creating a collection
client.create_collection(
collection_name="my_collection",
schema=schema,
properties={ "mmap.enabled": "false" }
)
CreateCollectionReq req = CreateCollectionReq.builder()
.collectionName("my_collection")
.collectionSchema(schema)
.property(Constant.MMAP_ENABLED, "false")
.build();
client.createCollection(req);
await client.createCollection({
collection_name: "my_collection",
scheme: schema,
properties: { "mmap.enabled": false }
});
err = client.CreateCollection(ctx,
milvusclient.NewCreateCollectionOption("my_collection", schema).
WithProperty(common.MmapEnabledKey, "false"))
if err != nil {
fmt.Println(err.Error())
// handle error
}
curl --request POST \
--url "${CLUSTER_ENDPOINT}/v2/vectordb/collections/create" \
--header "Authorization: Bearer ${TOKEN}" \
--header "Content-Type: application/json" \
--header "Request-Timeout: 10" \
--data "{
\"collectionName\": \"my_collection\",
\"schema\": $schema,
\"params\": {
\"mmap.enabled\": \"false\"
}
}"
You can also change the mmap settings of an existing collection as follows.
- Python
- Java
- NodeJS
- Go
- cURL
# Release collection before change mmap settings
client.release_collection("my_collection")
# Ensure that the collection has already been released
# and run the following
client.alter_collection_properties(
collection_name="my_collection",
properties={
"mmap.enabled": false
}
)
# Load the collection to make the above change take effect
client.load_collection("my_collection")
client.releaseCollection(ReleaseCollectionReq.builder()
.collectionName("my_collection")
.build());
client.alterCollectionProperties(AlterCollectionPropertiesReq.builder()
.collectionName("my_collection")
.property(Constant.MMAP_ENABLED, "false")
.build());
client.loadCollection(LoadCollectionReq.builder()
.collectionName("my_collection")
.build());
// Release collection before change mmap settings
await client.releaseCollection({
collection_name: "my_collection"
});
// Ensure that the collection has already been released
// and run the following
await client.alterCollectionProperties({
collection_name: "my_collection",
properties: {
"mmap.enabled": false
}
});
// Load the collection to make the above change take effect
await client.loadCollection({
collection_name: "my_collection"
});
err = client.ReleaseCollection(ctx, milvusclient.NewReleaseCollectionOption("my_collection"))
if err != nil {
fmt.Println(err.Error())
// handle error
}
err = client.AlterCollectionProperties(ctx, milvusclient.NewAlterCollectionPropertiesOption("my_collection").
WithProperty(common.MmapEnabledKey, "false"))
if err != nil {
fmt.Println(err.Error())
// handle error
}
_, err := client.LoadCollection(ctx, milvusclient.NewLoadCollectionOption("my_collection"))
if err != nil {
fmt.Println(err.Error())
// handle err
}
# restful
export CLUSTER_ENDPOINT="YOUR_CLUSTER_ENDPOINT"
export TOKEN="YOUR_CLUSTER_TOKEN"
curl --request POST \
--url "${CLUSTER_ENDPOINT}/v2/vectordb/collections/release" \
--header "Authorization: Bearer ${TOKEN}" \
--header "Content-Type: application/json" \
--header "Request-Timeout: 10" \
-d '{
"collectionName": "my_collection"
}'
curl --request POST \
--url "${CLUSTER_ENDPOINT}/v2/vectordb/collections/alter_properties" \
--header "Authorization: Bearer ${TOKEN}" \
--header "Content-Type: application/json" \
--header "Request-Timeout: 10" \
-d '{
"collectionName": "my_collection",
"properties": {
"mmmap.enabled": false
}
}'
curl --request POST \
--url "${CLUSTER_ENDPOINT}/v2/vectordb/collections/load" \
--header "Authorization: Bearer ${TOKEN}" \
--header "Content-Type: application/json" \
--header "Request-Timeout: 10" \
-d '{
"collectionName": "my_collection"
}'
You need to release the collection to make changes to its properties and reload the collection to make the changes take effect.