Boost Ranker
ベクトル間距離に基づいて計算されたセマンティック類似性のみに依存するのではなく、Boost Ranker を使用することで、検索結果に意味のある影響を与えることができます。メタデータフィルタリングを使用して検索結果を迅速に調整するのに最適です。
検索リクエストに Boost Ranker 関数が含まれる場合、Milvus は関数内のオプションのフィルタリング条件を使用して、検索結果候補の中から一致するものを見つけ、指定された重みを適用してそれらの一致のスコアをブーストし、最終結果における一致したエンティティのランキングの昇格または降格を支援します。
Boost Ranker を使用するタイミング
クロスエンコーダーモデルやフュージョンアルゴリズムに依存する他のランカーとは異なり、Boost Ranker はオプションのメタデータ駆動型ルールをランキングプロセスに直接注入するため、以下のシナリオにより適しています。
ユースケース | 例 | Boost Ranker が効果的な理由 |
|---|---|---|
ビジネス主導のコンテンツ優先順位付け |
| インデックスの再構築やベクトル埋め込みモデルの変更など、時間のかかる操作を行う必要なく、リアルタイムでオプションのメタデータフィルタを適用することで、検索結果内の特定のアイテムを即座に昇格または降格できます。このメカニズムにより、進化するビジネス要件に容易に適応できる柔軟で動的な検索ランキングが可能になります。 |
戦略的なコンテンツのランク低下 |
|
複数の Boost Ranker を組み合わせて、より動的で堅牢な重みベースのランキング戦略を実装することもできます。
Boost Ranker のメカニズム
以下の図は、Boost Ranker の主なワークフローを示しています。
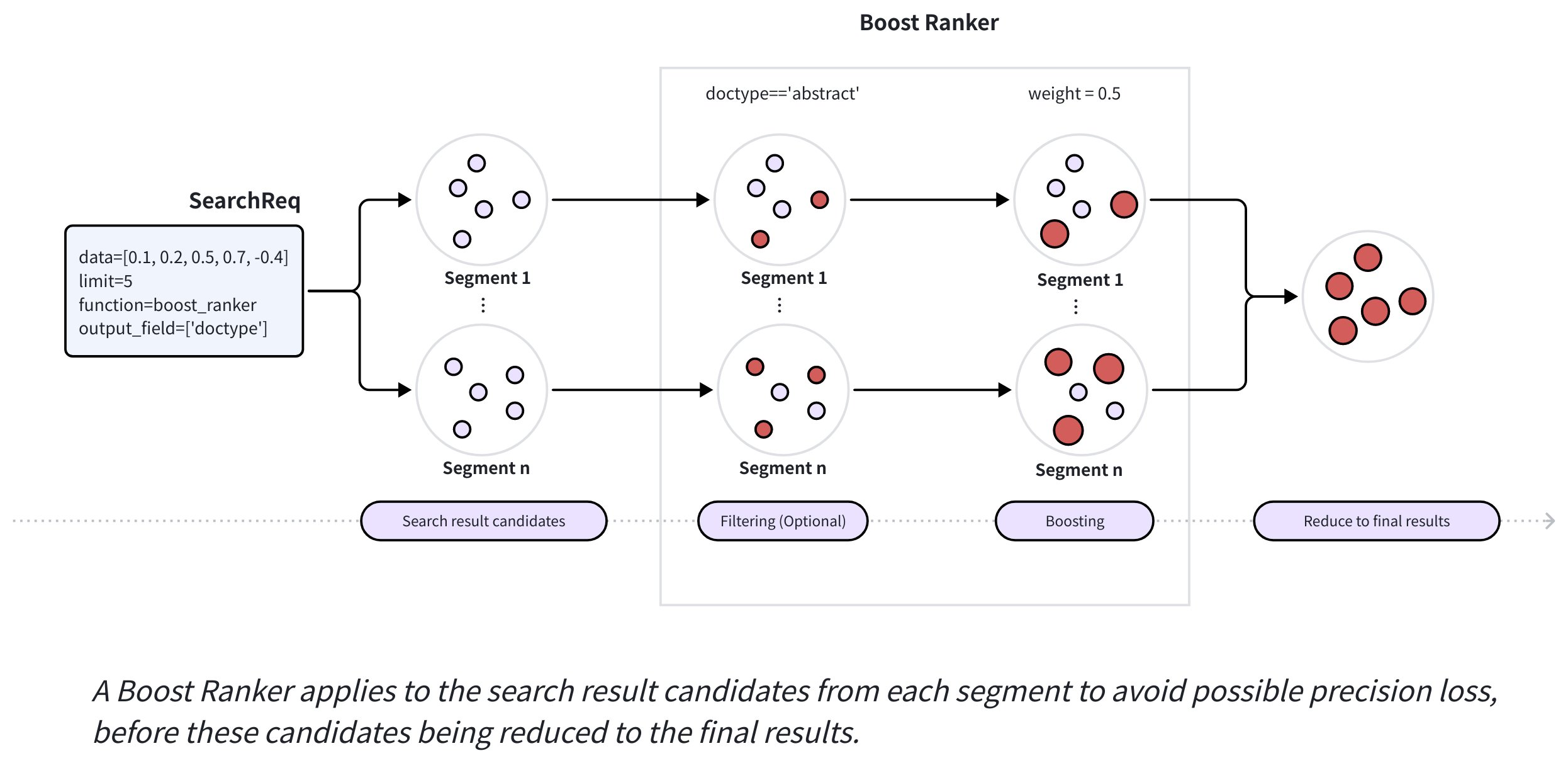
データを挿入すると、Zilliz Cloud はそれをセグメントに分散します。検索時、各セグメントは候補のセットを返し、Zilliz Cloud はすべてのセグメントからこれらの候補をランキングして最終結果を生成します。検索リクエストに Boost Ranker が含まれる場合、Zilliz Cloud はそれを各セグメントの候補結果に適用し、潜在的な精度の損失を防ぎ、再現率を向上させます。
結果を確定する前に、Milvus はこれらの候補を以下のように Boost Ranker で処理します。
-
Boost Ranker で指定されたオプションのフィルタリング式を適用し、式に一致するエンティティを特定します。
-
Boost Ranker で指定された重みを適用し、特定されたエンティティのスコアをブーストします。
Boost Ranker はマルチベクトルハイブリッド検索では使用できません。
Boost Ranker の例
以下の例は、上位 5 件の最も関連性の高いエンティティを返す必要があり、abstract ドキュメントタイプのエンティティのスコアに重みを加えるシングルベクトル検索における Boost Ranker の使用を示しています。
-
セグメント内で検索結果候補を収集する。
以下の表は、Milvus がエンティティを 2 つのセグメント(0001 と 0002)に分散し、各セグメントが 5 つの候補を返すことを想定しています。
ID
DocType
Score
Rank
segment
117
abstract
0.344
1
0001
89
abstract
0.456
2
0001
257
body
0.578
3
0001
358
title
0.788
4
0001
168
body
0.899
5
0001
46
body
0.189
1
0002
48
body
0265
2
0002
561
abstract
0.366
3
0002
344
abstract
0.444
4
0002
276
abstract
0.845
5
0002
-
Boost Ranker で指定されたフィルタリング式を適用する (
doctype='abstract')。以下の表の
DocTypeフィールドに示されるように、Milvus はdoctypeがabstractに設定されているすべてのエンティティをマークし、さらなる処理を行います。ID
DocType
Score
Rank
segment
117
abstract
0.344
1
0001
89
abstract
0.456
2
0001
257
body
0.578
3
0001
358
title
0.788
4
0001
168
body
0.899
5
0001
46
body
0.189
1
0002
48
body
0265
2
0002
561
abstract
0.366
3
0002
344
abstract
0.444
4
0002
276
abstract
0.845
5
0002
-
Boost Ranker で指定された重みを適用する (
weight=0.5)。前のステップで特定されたすべてのエンティティは、Boost Ranker で指定された重みを乗算され、その結果ランクが変化します。
ID
DocType
Score
Weighted Score
(= score x weight)
Rank
segment
117
abstract
0.344
0.172
1
0001
89
abstract
0.456
0.228
2
0001
257
body
0.578
0.578
3
0001
358
title
0.788
0.788
4
0001
168
body
0.899
0.899
5
0001
561
abstract
0.366
0.183
1
0002
46
body
0.189
0.189
2
0002
344
abstract
0.444
0.222
3
0002
48
body
0.265
0.265
4
0002
276
abstract
0.845
0.423
5
0002
📘Notes重みは、ユーザーが選択する浮動小数点数である必要があります。上記の例のように、スコアが小さいほど関連性が高い場合は、1 未満の重みを使用してください。それ以外の場合は、1 より大きい重みを使用してください。
-
重み付きスコアに基づいてすべてのセグメントから候補を集約し、結果を確定する。
ID
DocType
Score
Weighted Score
Rank
segment
117
abstract
0.344
0.172
1
0001
561
abstract
0.366
0.183
2
0002
46
body
0.189
0.189
3
0002
344
abstract
0.444
0.222
4
0002
89
abstract
0.456
0.228
5
0001
Boost Ranker の使用方法
このセクションでは、Boost Ranker を使用してシングルベクトル検索の結果に影響を与える方法の例を示します。
Boost Ranker の作成
Boost Ranker を検索リクエストのリランカーとして渡す前に、以下のように Boost Ranker をリランキング関数として適切に定義する必要があります。
- Python
- Java
- Go
- NodeJS
- cURL
from pymilvus import Function, FunctionType
rerank = Function(
name="boost",
input_field_names=[], # Must be an empty list
function_type=FunctionType.RERANK,
params={
"reranker": "boost",
"filter": "doctype == 'abstract'",
"random_score": {
"seed": 126,
"field": "id"
},
"weight": 0.5
}
)
import io.milvus.v2.service.vector.request.ranker.BoostRanker;
BoostRanker rerank = BoostRanker.builder()
.name("boost")
.filter("doctype == \"abstract\"")
.weight(5.0f)
.randomScoreField("id")
.randomScoreSeed(126)
.build();
// go
import {FunctionType} from '@zilliz/milvus2-sdk-node';
const rerank = {
name: "boost",
input_field_names: [],
type: FunctionType.RERANK,
params: {
reranker: "boost",
filter: "doctype == 'abstract'",
random_score: {
seed: 126,
field: "id",
},
weight: 0.5,
},
};
# restful
パラメータ | 必須ですか? | 説明 | 値/例 |
|---|---|---|---|
| はい | この関数の一意の識別子 |
|
| はい | 関数を適用するベクトルフィールドのリスト(Boost Ranker の場合は空である必要があります) |
|
| はい | 呼び出す関数のタイプ。再ランキング戦略を指定するには |
|
| はい | 再ランカーのタイプを指定します。 Boost Ranker を使用するには、 |
|
| はい | 生の検索結果内の一致するエンティティのスコアに掛けられる重みを指定します。 値は浮動小数点数である必要があります。
|
|
| いいえ | 検索結果のエンティティの中からエンティティをマッチさせるために使用されるフィルター式を指定します。フィルタリングの説明に記載されている任意の有効な基本フィルター式を使用できます。 注: |
|
| いいえ |
|
|
単一の Boost Ranker を使用した検索
Boost Ranker 関数の準備が整ったら、検索リクエストでそれを参照できます。以下の例では、id、vector、および doctype というフィールドを持つコレクションがすでに作成されていることを前提としています。
- Python
- Java
- Go
- NodeJS
- cURL
from pymilvus import MilvusClient
# Connect to the Milvus server
client = MilvusClient(
uri="YOUR_CLUSTER_ENDPOINT",
token="YOUR_CLUSTER_TOKEN"
)
# Assume you have a collection set up
# Conduct a similarity search using the created ranker
client.search(
collection_name="my_collection",
data=[[-0.619954382375778, 0.4479436794798608, -0.17493894838751745, -0.4248030059917294, -0.8648452746018911]],
anns_field="vector",
params={},
output_field=["doctype"],
ranker=rerank
)
import io.milvus.v2.client.ConnectConfig;
import io.milvus.v2.client.MilvusClientV2;
import io.milvus.v2.service.vector.request.SearchReq;
import io.milvus.v2.service.vector.response.SearchResp;
import io.milvus.v2.service.vector.request.data.FloatVec;
MilvusClientV2 client = new MilvusClientV2(ConnectConfig.builder()
.uri("YOUR_CLUSTER_ENDPOINT")
.token("YOUR_CLUSTER_TOKEN")
.build());
SearchResp searchReq = client.search(SearchReq.builder()
.collectionName("my_collection")
.data(Collections.singletonList(new FloatVec(new float[]{-0.619954f, 0.447943f, -0.174938f, -0.424803f, -0.864845f})))
.annsField("vector")
.outputFields(Collections.singletonList("doctype"))
.functionScore(FunctionScore.builder()
.addFunction(rerank)
.build())
.build());
SearchResp searchResp = client.search(searchReq);
// go
import { MilvusClient } from '@zilliz/milvus2-sdk-node';
// Connect to the Milvus server
const client = new MilvusClient({
address: 'YOUR_CLUSTER_ENDPOINT',
token: 'YOUR_CLUSTER_TOKEN'
});
// Assume you have a collection set up
// Conduct a similarity search
const searchResults = await client.search({
collection_name: 'my_collection',
data: [-0.619954382375778, 0.4479436794798608, -0.17493894838751745, -0.4248030059917294, -0.8648452746018911],
anns_field: 'vector',
output_fields: ['doctype'],
rerank: rerank,
});
console.log('Search results:', searchResults);
# restful
Search with multiple Boost Rankers
単一の検索で複数の Boost Ranker を組み合わせて、検索結果に影響を与えることができます。これを行うには、複数の Boost Ranker を作成し、FunctionScore インスタンスでそれらを参照して、検索リクエストのランカーとして FunctionScore インスタンスを使用します。
以下の例では、0.8 から 1.2 の間の重みを適用することで、特定されたすべてのエンティティのスコアを変更する方法を示しています。
- Python
- Java
- Go
- NodeJS
- cURL
from pymilvus import MilvusClient, Function, FunctionType, FunctionScore
# Create a Boost Ranker with a fixed weight
fix_weight_ranker = Function(
name="boost",
input_field_names=[], # Must be an empty list
function_type=FunctionType.RERANK,
params={
"reranker": "boost",
"weight": 0.8
}
)
# Create a Boost Ranker with a randomly generated weight between 0 and 0.4
random_weight_ranker = Function(
name="boost",
input_field_names=[], # Must be an empty list
function_type=FunctionType.RERANK,
params={
"reranker": "boost",
"random_score": {
"seed": 126,
},
"weight": 0.4
}
)
# Create a Function Score
ranker = FunctionScore(
functions=[
fix_weight_ranker,
random_weight_ranker
],
params={
"boost_mode": "Multiply",
"function_mode": "Sum"
}
)
# Conduct a similarity search using the created Function Score
client.search(
collection_name="my_collection",
data=[[-0.619954382375778, 0.4479436794798608, -0.17493894838751745, -0.4248030059917294, -0.8648452746018911]],
anns_field="vector",
params={},
output_field=["doctype"],
ranker=ranker
)
import io.milvus.common.clientenum.FunctionType;
import io.milvus.v2.service.collection.request.CreateCollectionReq;
CreateCollectionReq.Function fixWeightRanker = CreateCollectionReq.Function.builder()
.functionType(FunctionType.RERANK)
.name("boost")
.param("reranker", "boost")
.param("weight", "0.8")
.build();
CreateCollectionReq.Function randomWeightRanker = CreateCollectionReq.Function.builder()
.functionType(FunctionType.RERANK)
.name("boost")
.param("reranker", "boost")
.param("weight", "0.4")
.param("random_score", "{\"seed\": 126}")
.build();
Map<String, String> params = new HashMap<>();
params.put("boost_mode","Multiply");
params.put("function_mode","Sum");
FunctionScore ranker = FunctionScore.builder()
.addFunction(fixWeightRanker)
.addFunction(randomWeightRanker)
.params(params)
.build()
SearchResp searchReq = client.search(SearchReq.builder()
.collectionName("my_collection")
.data(Collections.singletonList(new FloatVec(new float[]{-0.619954f, 0.447943f, -0.174938f, -0.424803f, -0.864845f})))
.annsField("vector")
.outputFields(Collections.singletonList("doctype"))
.addFunction(ranker)
.build());
SearchResp searchResp = client.search(searchReq);
// go
import {FunctionType} from '@zilliz/milvus2-sdk-node';
const fix_weight_ranker = {
name: "boost",
input_field_names: [],
type: FunctionType.RERANK,
params: {
reranker: "boost",
weight: 0.8,
},
};
const random_weight_ranker = {
name: "boost",
input_field_names: [],
type: FunctionType.RERANK,
params: {
reranker: "boost",
random_score: {
seed: 126,
},
weight: 0.4,
},
};
const ranker = {
functions: [fix_weight_ranker, random_weight_ranker],
params: {
boost_mode: "Multiply",
function_mode: "Sum",
},
};
await client.search({
collection_name: "my_collection",
data: [[-0.619954382375778, 0.4479436794798608, -0.17493894838751745, -0.4248030059917294, -0.8648452746018911]],
anns_field: "vector",
params: {},
output_field: ["doctype"],
ranker: ranker
});
# restful
具体的には、2 つの Boost Ranker があります。一方は検出されたすべてのエンティティに固定の重みを適用し、もう一方はランダムな重みを割り当てます。その後、これらの 2 つのランカーを FunctionScore で参照し、重みが検出されたエンティティのスコアにどのように影響するかを定義します。
以下の表は、FunctionScore インスタンスを作成するために必要なパラメータの一覧です。
パラメータ | 必須ですか? | 説明 | 値/例 |
|---|---|---|---|
| はい | 対象となるランカーの名前をリストで指定します。 |
|
| いいえ | 指定された重みが一致するエンティティのスコアにどのように影響するかを指定します。 可能な値は次のとおりです。
|
|
| いいえ | さまざまな Boost Ranker からの重み付き値をどのように処理するかを指定します。 可能な値は次のとおりです。
|
|