パイプラインを使用したRAGアプリケーションの構築About to Deprecate
Zilliz Cloud Pipelinesは、ドキュメント、テキスト、画像などの非構造化データを検索可能なベクトルコレクションに変換するための堅牢なソリューションです。このガイドでは、3つの主要なPipelinesタイプの詳細な説明と、Pipelinesを使用したRAGアプリケーションの構築例を提供します。
Zilliz Cloud Pipelinesは、2025年第2四半期の終わりまでに廃止され、「Data In, Data Out」という新しい機能に置き換えられます。これにより、MilvusとZilliz Cloudの両方で埋め込み生成が効率化されます。2024年12月24日現在、新規ユーザー登録は受け付けられていません。現在のユーザーは、日没日まで月額20ドルの無料手当内でサービスを継続して利用できますが、SLAは提供されていません。モデルプロバイダーまたはオープンソースモデルの埋め込みAPIを使用してベクトル埋め込みを生成することを検討してください。
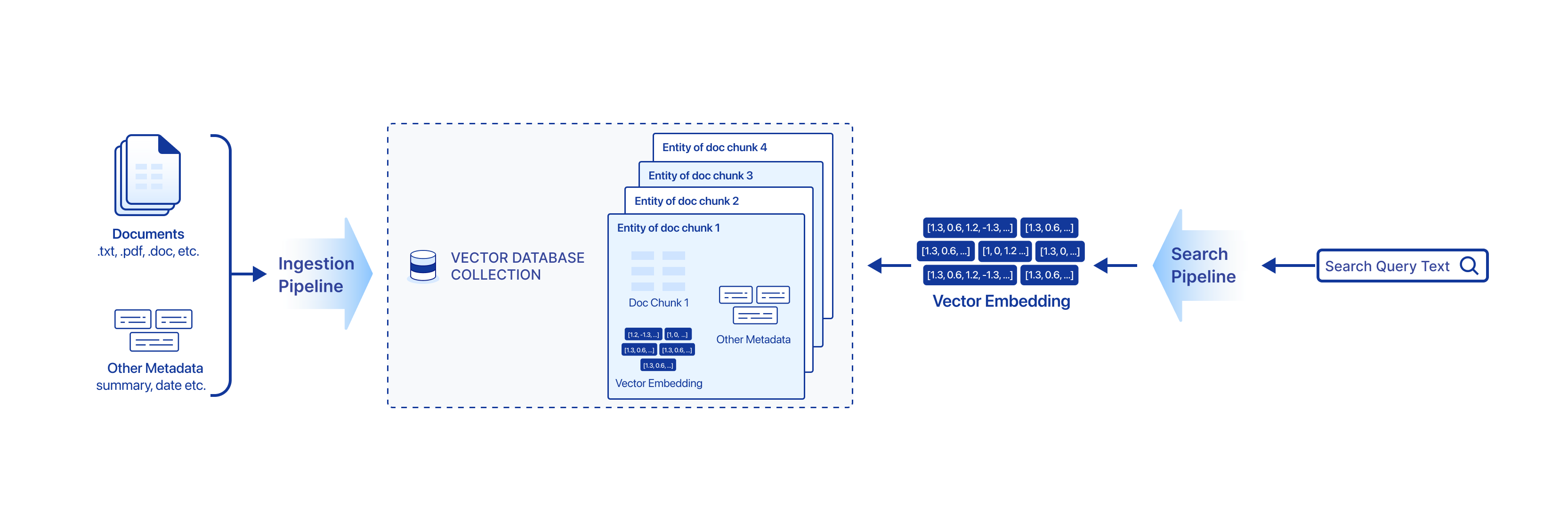
パイプラインの理解
多くの現代のサービスやアプリケーションでは、意味論による検索が必要です。クエリの意味に一致するテキストの塊を検索することから、お互いに似ている画像を見つけることまで。このようなタスクを完了する典型的な検索システムは、データの準備と埋め込み、多次元空間でテキストや画像を数値ベクトルとして表現する過程で構築されます。Zilliz Cloud Pipelinesは、シンプルで柔軟なインターフェースでこのようなユースケースを支援します。
現在、私たちはテキスト、ドキュメント、画像の意味検索のためのパイプラインを提供しており、Retrieval Augmented Generation(RAG)アプリケーションの重要な構成要素を提供しています。将来的には、ビデオフレーム検索やマルチモーダル検索など、より多くの意味検索ユースケースのために、より多くのパイプラインが追加される予定です。
Zilliz Cloudには3種類のPiplineがあります。
摂取パイプライン
インジェスチョンパイプラインは、非構造化データを検索可能なベクトル埋め込みに過程化し、Zilliz Cloudベクトルデータベースに格納することができます。
Ingestionパイプラインには、いくつかの関数が含まれており、それぞれが非構造化データ(画像、テキスト、ドキュメントなど)のベクトル埋め込みを生成し、ベクトル検索中に取得できる追加情報として入力値を保存するなど、入力フィールドの変換を記述しています。
1つのインジェスチョンパイプラインは、Zilliz Cloud上の正確に1つのベクトルデータベースコレクションにマップされます。
検索パイプライン
検索パイプラインは、入力を埋め込みベクトルに変換し、最も類似した上位K個の埋め込みベクトルと関連するメタデータを取得することにより、ベクトル類似性検索と意味検索を可能にします。検索パイプラインは、1種類の関数のみを許可します。
削除パイプライン
Deletionパイプラインは、コレクションから指定されたすべてのエンティティを削除します。Deletionパイプラインは、1種類の関数のみを許可します。
例:パイプラインを使用したRAGアプリケーションの構築
このチュートリアルでは、Zilliz Cloud Pipelinesを使用して、PythonでシンプルでスケーラブルなRetrieval Augmented Generation(RAG)アプリケーションを構築する方法を示します。統一されたAPIセットを提供することにより、Zilliz Cloud PipelinesはRAGアプリケーションの構築過程を簡素化します。DevOpsの手間を省き、シンプルなAPI呼び出しですべてを達成できます。以下の図は、基本的なRAGアプリケーションの主要なコンポーネントを示しています。
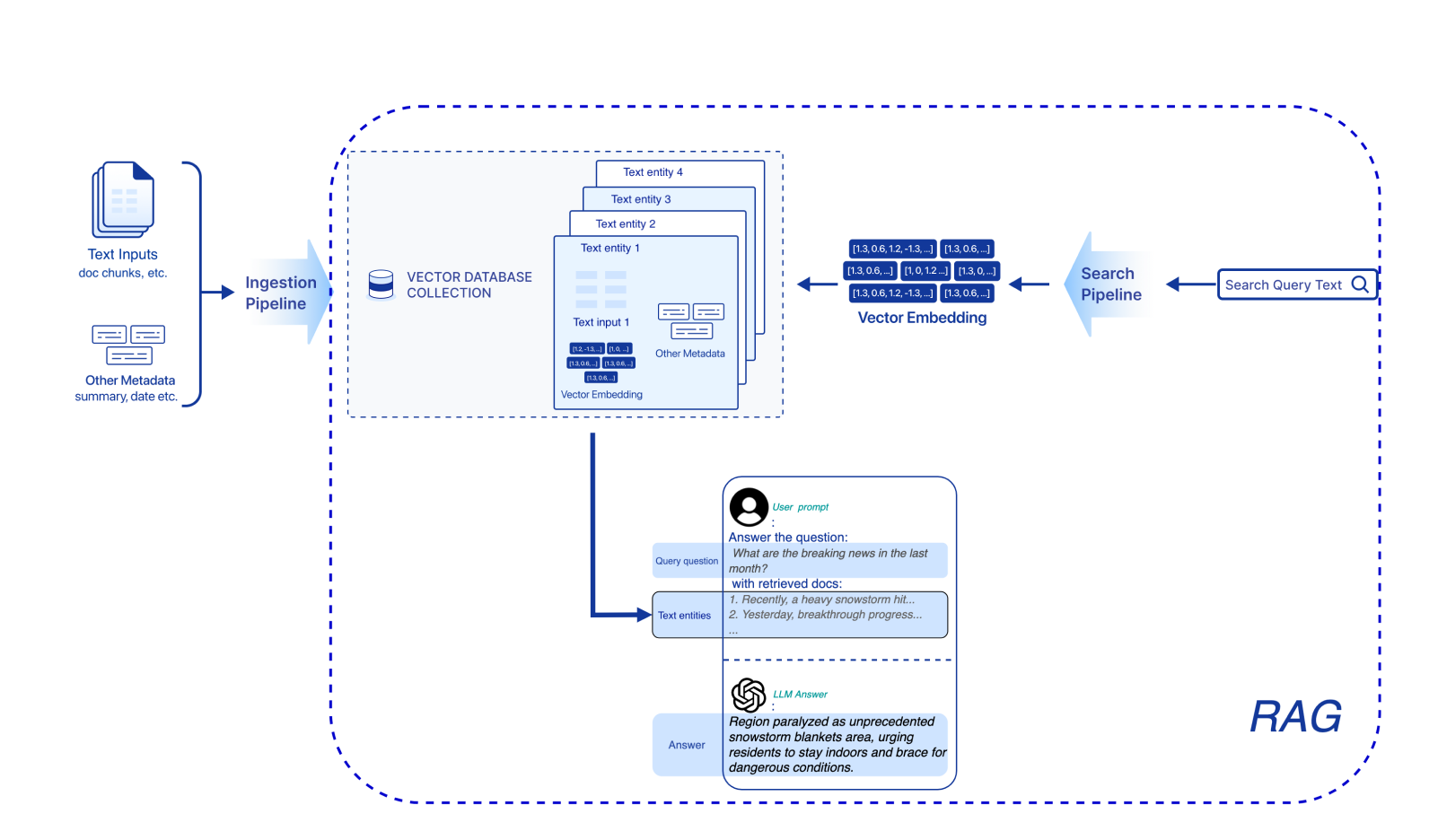
始める前に
- Zilliz CloudでFree-tierクラスタを作成していることを確認してください。
Zilliz Cloudパイプラインの設定
クラスタ情報を取得する
クラスタID、クラウドリージョン、APIキー、プロジェクトIDなど、作成したFreeクラスタに関する必要な情報を取得します。
import os
CLOUD_REGION = 'gcp-us-west1'
CLUSTER_ID = 'your CLUSTER_ID'
API_KEY = 'your API_KEY'
PROJECT_ID = 'your PROJECT_ID'
インジェストパイプラインを作成する
インジェスチョンパイプラインは、非構造化データを検索可能なベクトル埋め込みに変換し、Zilliz Cloud Vector Databaseに保存することができます。インジェスチョンパイプラインでは、関数を指定することで、処理する非構造化データの種類を定義できます。現在、インジェスチョンパイプラインでは、以下の種類の関数を使用できます。
-
INDEX_TEXT:この関数はテキストを処理するために使用されます。各テキストをベクトル埋め込みに変換し、入力フィールド(text_list)を2つの出力フィールド(text、埋め込み)にマップします。 -
INDEX_DOC:この関数はドキュメントを処理するために使用されます。入力テキストドキュメントをチャンクに分割し、各チャンクに対してベクトル埋め込みを生成します。この関数は、入力フィールド(doc_url)を4つの出力フィールド(doc_name、chunk_id、chunk_text、および埋め込み)にマップします。 -
INDEX_IMAGE:この関数は画像を処理するために使用されます。画像の埋め込みを生成し、2つの入力フィールド(image_urlとimage_id)を2つの出力フィールド(image_idと埋め込み)にマップします。 -
PRESERVE:この関数は、追加のメタデータをスカラーフィールドとして保存するために使用されます。これらのメタデータには、通常、ドキュメントの発行者情報、タグ、発行日などのプロパティが含まれます。
このチュートリアルでは、INDEX_TEXT関数とPRESERVE関数を持つIngestionパイプラインを作成します。Ingestionパイプラインの作成の一環として、クラスタにmy_text_collectionというベクトルデータベースコレクションが作成されます。これには5つのフィールドが含まれています
-
idは各エンティティの自動生成された主キーです -
テキスト、INDEX_TEXT関数で定義された埋め込み方法 -
PRESERVE関数で定義されたタイトル。
import requests
headers = {
"Content-Type": "application/json",
"Accept": "application/json",
"Authorization": f"Bearer {API_KEY}"
}
create_pipeline_url = f"https://controller.api.{CLOUD_REGION}.zillizcloud.com/v1/pipelines"
collection_name = 'my_text_collection'
embedding_service = "zilliz/bge-base-en-v1.5"
data = {
"name": "my_ingestion_pipeline",
"description": "A pipeline that generates text embeddings and stores title information.",
"type": "INGESTION",
"projectId": PROJECT_ID,
"clusterId": CLUSTER_ID,
"collectionName": collection_name,
"functions": [
{
"name": "index_my_text",
"action": "INDEX_TEXT",
"language": "ENGLISH",
"embedding": embedding_service
},
{
"name": "title_info",
"action": "PRESERVE",
"inputField": "title",
"outputField": "title",
"fieldType": "VarChar"
}
]
}
response = requests.post(create_pipeline_url, headers=headers, json=data)
print(response.json())
ingestion_pipe_id = response.json()["data"]["pipelineId"]
作成に成功すると、パイプラインIDが返されます。このパイプラインIDは、後でパイプラインを実行する際に使用します。
検索パイプラインを作成する
検索パイプラインは、クエリ文字列をベクトル埋め込みに変換し、その後、上位K個の最近傍ベクトルを取得することにより、セマンティック検索を可能にします。各ベクトルは、取り込まれたドキュメントのチャンクやファイル名などの他の保存されたプロパティを表します。現在、検索パイプラインでは、以下の種類の関数が使用できます
-
SEARCH_DOC_CHUNK:この関数は、ユーザークエリを入力として受け取り、ナレッジベースから関連する文書チャンクを返します。 -
SEARCH_TEXT:この関数は、ユーザークエリを入力として受け取り、ナレッジベースから関連するテキストエンティティを返します。 -
SEARCH_IMAGE:この関数は画像のURLを入力として受け取り、最も似た画像のエンティティを返します。
このチュートリアルでは、テキスト検索にSEARCH_TEXT関数を採用します。
data = {
"projectId": PROJECT_ID,
"name": "my_search_pipeline",
"description": "A pipeline that receives text and search for semantically similar texts.",
"type": "SEARCH",
"functions": [
{
"name": "search_text_and_title",
"action": "SEARCH_TEXT",
"embedding": embedding_service,
"reranker": "zilliz/bge-reranker-base", # optional, this will rerank search results by the reranker service
"clusterId": CLUSTER_ID,
"collectionName": collection_name,
}
]
}
response = requests.post(create_pipeline_url, headers=headers, json=data)
print(response.json())
search_pipe_id = response.json()["data"]["pipelineId"]
同様に、作成に成功すると、パイプラインIDが返されます。このパイプラインIDは、後でパイプラインを実行する際に使用します。
インジェストパイプラインを実行する
このチュートリアルでは、ブログWhat Milvus version to start withからテキストピースを取り込みます。
run_pipeline_url = f"https://controller.api.{CLOUD_REGION}.zillizcloud.com/v1/pipelines/{ingestion_pipe_id}/run"
milvus_lite_data = {
"data":
{
"text_list": [
"As the name suggests, Milvus Lite is a lightweight version that integrates seamlessly with Google Colab and Jupyter Notebook. It is packaged as a single binary with no additional dependencies, making it easy to install and run on your machine or embed in Python applications. Additionally, Milvus Lite includes a CLI-based Milvus standalone server, providing flexibility for running it directly on your machine. Whether you embed it within your Python code or utilize it as a standalone server is entirely up to your preference and specific application requirements.",
"Milvus Lite is ideal for rapid prototyping and local development, offering support for quick setup and experimentation with small-scale datasets on your machine. However, its limitations become apparent when transitioning to production environments with larger datasets and more demanding infrastructure requirements. As such, while Milvus Lite is an excellent tool for initial exploration and testing, it may not be suitable for deploying applications in high-volume or production-ready settings.",
"Milvus Lite is perfect for prototyping on your laptop."
],
"title": 'Milvus Lite'
}
}
milvus_standalone_data = {
"data":
{
"text_list": [
"Milvus Standalone is a mode of operation for the Milvus vector database system where it operates independently as a single instance without any clustering or distributed setup. Milvus runs on a single server or machine in this mode, providing functionalities such as indexing and searching for vectors. It is suitable for situations where the data and traffic volume scale is relatively small and does not require the distributed capabilities provided by a clustered setup.",
"Milvus Standalone offers high performance and flexibility for conducting vector searches on your datasets, making it suitable for smaller-scale deployments, CI/CD, and offline deployments when you have no Kubernetes support."
],
"title": 'Milvus Standalone'
}
}
milvus_cluster_data = {
"data":
{
"text_list": [
"Milvus Cluster is a mode of operation for the Milvus vector database system where it operates and is distributed across multiple nodes or servers. In this mode, Milvus instances are clustered together to form a unified system that can handle larger volumes of data and higher traffic loads compared to a standalone setup. Milvus Cluster offers scalability, fault tolerance, and load balancing features, making it suitable for scenarios that need to handle big data and serve many concurrent queries efficiently.",
"Milvus Cluster provides unparalleled availability, scalability, and cost optimization for enterprise-grade workloads, making it the preferred choice for large-scale, highly available production environments."
],
"title": 'Milvus Cluster'
}
}
for data in [milvus_lite_data, milvus_standalone_data, milvus_cluster_data]:
response = requests.post(run_pipeline_url, headers=headers, json=data)
print(response.json())
今、対応するタイトルと埋め込みを持つテキストピースをベクトルデータベースに正常に取り込みました。取り込まれたデータは、このコレクションのデータプレビュータブ(my_text_collection)のZilliz Cloud Web UIで確認できます。
RAGアプリケーションを構築する
検索パイプラインの実行
import pprint
def retrieval_with_pipeline(question, search_pipe_id, top_k=2, verbose=False):
run_pipeline_url = f"https://controller.api.{CLOUD_REGION}.zillizcloud.com/v1/pipelines/{search_pipe_id}/run"
data = {
"data": {
"query_text": question
},
"params": {
"limit": top_k,
"offset": 0,
"outputFields": [
"text",
"title"
],
"filter": 'title == "Milvus Lite"'
}
}
response = requests.post(run_pipeline_url, headers=headers, json=data)
if verbose:
pprint.pprint(response.json())
results = response.json()["data"]["result"]
retrieved_texts = [{'text': result['text'], 'title': result['title']} for result in results]
return retrieved_texts
question = 'Which Milvus should I choose if I want to use in the jupyter notebook with a small scale of data?'
retrieval_with_pipeline(question, search_pipe_id, top_k=2, verbose=True)
paramsでは、上位k件の検索結果を取得し、「Milvus Lite」というタイトルの記事のみをフィルタリングし、テキストとタイトルフィールドのみを返すように指定します。検索パイプラインの実行パラメータの詳細については、こちらを参照してください。
以下が出力です。
{'code': 200,
'data': {'result': [{'distance': 0.8722565174102783,
'id': 449431798276845977,
'text': 'As the name suggests, Milvus Lite is a '
'lightweight version that integrates seamlessly '
'with Google Colab and Jupyter Notebook. It is '
'packaged as a single binary with no additional '
'dependencies, making it easy to install and run '
'on your machine or embed in Python '
'applications. Additionally, Milvus Lite '
'includes a CLI-based Milvus standalone server, '
'providing flexibility for running it directly '
'on your machine. Whether you embed it within '
'your Python code or utilize it as a standalone '
'server is entirely up to your preference and '
'specific application requirements.',
'title': 'Milvus Lite'},
{'distance': 0.3541138172149658,
'id': 449431798276845978,
'text': 'Milvus Lite is ideal for rapid prototyping and '
'local development, offering support for quick '
'setup and experimentation with small-scale '
'datasets on your machine. However, its '
'limitations become apparent when transitioning '
'to production environments with larger datasets '
'and more demanding infrastructure requirements. '
'As such, while Milvus Lite is an excellent tool '
'for initial exploration and testing, it may not '
'be suitable for deploying applications in '
'high-volume or production-ready settings.',
'title': 'Milvus Lite'}],
'token_usage': 34}}
Out[7]:
[{'text': 'As the name suggests, Milvus Lite is a lightweight version that integrates seamlessly with Google Colab and Jupyter Notebook. It is packaged as a single binary with no additional dependencies, making it easy to install and run on your machine or embed in Python applications. Additionally, Milvus Lite includes a CLI-based Milvus standalone server, providing flexibility for running it directly on your machine. Whether you embed it within your Python code or utilize it as a standalone server is entirely up to your preference and specific application requirements.',
'title': 'Milvus Lite'},
{'text': 'Milvus Lite is ideal for rapid prototyping and local development, offering support for quick setup and experimentation with small-scale datasets on your machine. However, its limitations become apparent when transitioning to production environments with larger datasets and more demanding infrastructure requirements. As such, while Milvus Lite is an excellent tool for initial exploration and testing, it may not be suitable for deploying applications in high-volume or production-ready settings.',
'title': 'Milvus Lite'}]
質問をして検索パイプラインを実行すると、最も似ている上位K個の知識フラグメントが返されることがわかります。これがRAGアプリケーションを作成するための基礎となります。
RAGを使ってチャットボットを構築する
上記の便利なヘルパー関数「Retrive_with_Pipeline」を使用すると、ベクトルデータベースに取り込まれた知識を取得できます。次に、作成した知識ベースに基づいてユーザーの質問に答えることができる簡単なRAG対応チャットボットを構築しましょう。このチュートリアルでは、LLMとしてOpen AIgpt-3.5-ターボを使用します。以下のコードでは、独自のOpen AI APIキーを使用してください。
import os
from openai import OpenAI
client = OpenAI()
client.api_key = os.getenv('OPENAI_API_KEY') # your OpenAI API key
class Chatbot:
def __init__(self, search_pipe_id):
self._search_pipe_id = search_pipe_id
def retrieve(self, query: str) -> list:
"""
Retrieve relevant text with Zilliz Cloud Pipelines.
"""
results = retrieval_with_pipeline(query, self._search_pipe_id, top_k=2)
return results
def generate_answer(self, query: str, context_str: list) -> str:
"""
Generate answer based on context, which is from the result of Search pipeline run.
"""
completion = client.chat.completions.create(
model="gpt-3.5-turbo",
temperature=0,
messages=
[
{"role": "user",
"content":
f"We have provided context information below. \n"
f"---------------------\n"
f"{context_str}"
f"\n---------------------\n"
f"Given this information, please answer the question: {query}"
}
]
).choices[0].message.content
return completion
def chat_with_rag(self, query: str) -> str:
context_str = self.retrieve(query)
completion = self.generate_answer(query, context_str)
return completion
def chat_without_rag(self, query: str) -> str:
return client.chat.completions.create(
model="gpt-3.5-turbo",
temperature=0,
messages=
[
{"role": "user",
"content": query
}
]
).choices[0].message.content
chatbot = Chatbot(search_pipe_id)
上記のコードは、先ほど作成した検索パイプラインを利用して、ナレッジベースから最も関連性の高いテキストを取得するRAG対応のチャットボットを作成します。それでは、どのように動作するか見てみましょう。
チャットボットに質問してください
データセットが少ない場合、JupyterノートブックでどのMilvusバージョンを使用するかチャットボットに尋ねます。
question = 'Which Milvus should I choose if I want to use in the jupyter notebook with a small scale of data?'chatbot.chat_with_rag(question)
私たちが得た答えは以下の通りです。
Based on the context provided, you should choose Milvus Lite if you want to use it in a Jupyter Notebook with a small scale of data. Milvus Lite is specifically designed for rapid prototyping and local development, offering support for quick setup and experimentation with small-scale datasets on your machine. It is lightweight, easy to install, and integrates seamlessly with Google Colab and Jupyter Notebook.
ナレッジベースからの元のテキストは次のとおりです。
As the name suggests, Milvus Lite is a lightweight version that integrates seamlessly with Google Colab and Jupyter Notebook. It is packaged as a single binary with no additional dependencies, making it easy to install and run on your machine or embed in Python applications. Additionally, Milvus Lite includes a CLI-based Milvus standalone server, providing flexibility for running it directly on your machine. Whether you embed it within your Python code or utilize it as a standalone server is entirely up to your preference and specific application requirements.
知識ベースのテキストピースと得られた回答を比較した後、RAG対応のチャットボットが私たちの質問にドメイン知識を持つ完璧な回答を提供していることがわかります。
今度は、RAG機能なしで同じ質問をチャットボットに尋ねてみましょう。
chatbot.chat_without_rag(question)
以下の答えが得られます。
If you are working with a small scale of data in a Jupyter notebook, you may want to consider using Milvus CE (Community Edition). Milvus CE is a free and open-source vector database that is suitable for small-scale projects and experimentation. It is easy to set up and use in a Jupyter notebook environment, making it a good choice for beginners or those working with limited data. Additionally, Milvus CE offers a range of features and functionalities that can help you efficiently store and query your data in a vectorized format.
明らかに、今回、チャットボットはドメイン知識を注入されておらず、[幻覚](https://en.wikipedia.org/wiki/Hallucination_(artificial_intelligence)を見ます。
結論として
私たちは、ドメイン知識を注入し、ユーザーの質問に正確な回答を提供するRAG対応のチャットボットを成功裏に構築しました。