アナライザーの概要
テキスト処理において、アナライザーは生のテキストを構造化された検索可能な形式に変換する重要なコンポーネントです。各アナライザーは通常、2つのコア要素で構成されています:トークナイザーとフィルターです。これらが協調して入力テキストをトークンに変換し、これらのトークンを洗練させ、効率的なインデックス作成と検索のために準備します。
Zilliz Cloud では、コレクションスキーマに VARCHAR フィールドを追加する際のコレクション作成時にアナライザーが設定されます。アナライザーによって生成されたトークンは、キーワードマッチング用のインデックス構築や、全文検索のためのスパース埋め込みへの変換に使用できます。詳細については、全文検索 または テキストマッチ を参照してください。
アナライザーの使用はパフォーマンスに影響を与える可能性があります:
全文検索: 全文検索の場合、データNode および QueryNode チャネルはトークナイゼーションが完了するのを待つ必要があるため、データの消費が遅くなります。その結果、新しく取り込まれたデータが検索で利用可能になるまでに時間がかかります。
キーワードマッチ: キーワードマッチングの場合、トークナイゼーションが完了する前にインデックスを構築できないため、インデックス作成も遅くなります。
アナライザーの構造
Zilliz Cloud のアナライザーは、ちょうど1つのトークナイザーとゼロ個以上のフィルターで構成されています。
-
トークナイザー: トークナイザーは入力テキストをトークンと呼ばれる離散的な単位に分割します。これらのトークンは、トークナイザーのタイプによって単語またはフレーズになります。
-
フィルター: フィルターはトークンに適用され、例えば小文字に変換したり一般的な単語を削除したりすることで、さらに洗練させることができます。
トークナイザーは UTF-8 形式のみをサポートしています。他の形式のサポートは将来のリリースで追加される予定です。
以下のワークフローは、アナライザーがテキストを処理する方法を示しています。
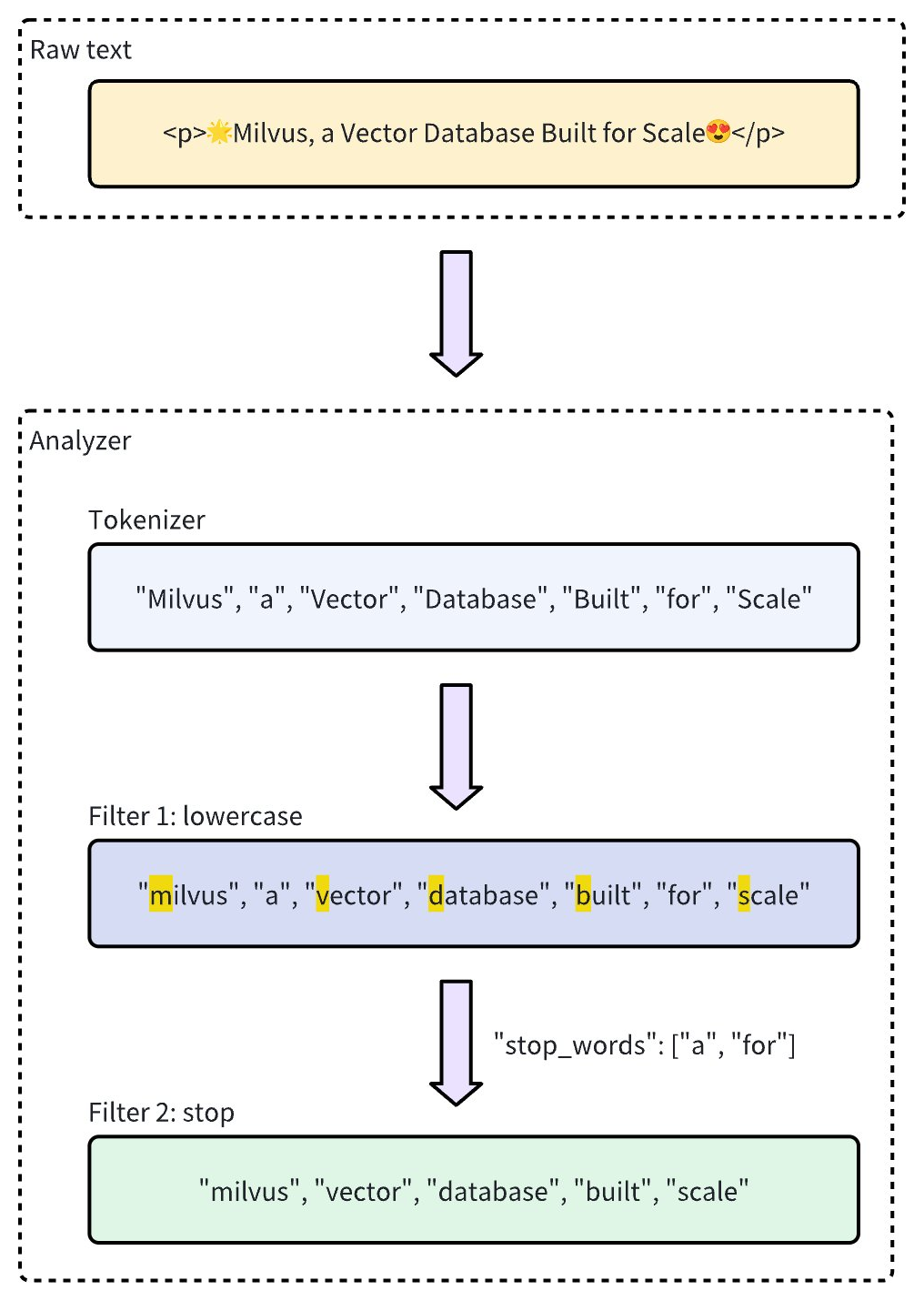
アナライザーのタイプ
Zilliz Cloud は、異なるテキスト処理ニーズに応えるために2種類のアナライザーを提供しています:
-
組み込みアナライザー: これらは一般的なテキスト処理タスクを最小限の設定でカバーする、事前定義された設定です。組み込みアナライザーは複雑な設定を必要としないため、汎用的な検索に最適です。
-
カスタムアナライザー: より高度な要件の場合、カスタムアナライザーを使用すると、トークナイザーとゼロ個以上のフィルターを指定して独自の設定を定義できます。このレベルのカスタマイズは、テキスト処理の精密な制御が必要な専門的なユースケースで特に有用です。
コレクション作成時にアナライザー設定を省略した場合、Zilliz Cloud はデフォルトですべてのテキスト処理に
standardアナライザーを使用します。詳細については、Standard を参照してください。最適な検索およびクエリパフォーマンスを得るには、テキストデータの言語に合ったアナライザーを選択してください。例えば、
standardアナライザーは多用途ですが、中国語、日本語、韓国語などの独特な文法構造を持つ言語には最適な選択ではない場合があります。このような場合、chineseなどの言語固有のアナライザーや、lindera、icuなどの専門的なトークナイザーとフィルターを使用したカスタムアナライザーを使用することで、正確なトークナイゼーションとより良い検索結果を確保することを強く推奨します。
組み込みアナライザー
Zilliz Cloud クラスターの組み込みアナライザーは、特定のトークナイザーとフィルターで事前設定されており、これらのコンポーネントを自分で定義する必要なくすぐに使用できます。各組み込みアナライザーは、プリセットのトークナイザーとフィルターを含むテンプレートとして機能し、カスタマイズのためのオプションパラメータも備えています。
例えば、standard 組み込みアナライザーを使用するには、その名前 standard を type として指定し、オプションで stop_words など、このアナライザータイプ固有の追加設定を含めるだけです:
- Python
- Java
- NodeJS
- Go
- cURL
analyzer_params = {
"type": "standard", # Uses the standard built-in analyzer
"stop_words": ["a", "an", "for"] # Defines a list of common words (stop words) to exclude from tokenization
}
Map<String, Object> analyzerParams = new HashMap<>();
analyzerParams.put("type", "standard");
analyzerParams.put("stop_words", Arrays.asList("a", "an", "for"));
const analyzer_params = {
"type": "standard", // Uses the standard built-in analyzer
"stop_words": ["a", "an", "for"] // Defines a list of common words (stop words) to exclude from tokenization
};
analyzerParams := map[string]any{"type": "standard", "stop_words": []string{"a", "an", "for"}}
export analyzerParams='{
"type": "standard",
"stop_words": ["a", "an", "for"]
}'
アナライザーの実行結果を確認するには、run_analyzer メソッドを使用します:
- Python
- Java
- NodeJS
- Go
- cURL
# Sample text to analyze
text = "An efficient system relies on a robust analyzer to correctly process text for various applications."
# Run analyzer
result = client.run_analyzer(
text,
analyzer_params
)
import io.milvus.v2.service.vector.request.RunAnalyzerReq;
import io.milvus.v2.service.vector.response.RunAnalyzerResp;
List<String> texts = new ArrayList<>();
texts.add("An efficient system relies on a robust analyzer to correctly process text for various applications.");
RunAnalyzerResp resp = client.runAnalyzer(RunAnalyzerReq.builder()
.texts(texts)
.analyzerParams(analyzerParams)
.build());
List<RunAnalyzerResp.AnalyzerResult> results = resp.getResults();
// javascrip# Sample text to analyze
const text = "An efficient system relies on a robust analyzer to correctly process text for various applications."
// Run analyzer
const result = await client.run_analyzer({
text,
analyzer_params
});
import (
"context"
"encoding/json"
"fmt"
"github.com/milvus-io/milvus/client/v2/milvusclient"
)
bs, _ := json.Marshal(analyzerParams)
texts := []string{"An efficient system relies on a robust analyzer to correctly process text for various applications."}
option := milvusclient.NewRunAnalyzerOption(texts).
WithAnalyzerParams(string(bs))
result, err := client.RunAnalyzer(ctx, option)
if err != nil {
fmt.Println(err.Error())
// handle error
}
# restful
export MILVUS_HOST="YOUR_CLUSTER_ENDPOINT"
export TEXT_TO_ANALYZE="An efficient system relies on a robust analyzer to correctly process text for various applications."
curl -X POST "http://${MILVUS_HOST}/v2/vectordb/common/run_analyzer" \
-H "Content-Type: application/json" \
-d '{
"text": ["'"${TEXT_TO_ANALYZE}"'"],
"analyzerParams": "{\"type\":\"standard\",\"stop_words\":[\"a\",\"an\",\"for\"]}"
}'
出力は次のようになります。
['efficient', 'system', 'relies', 'on', 'robust', 'analyzer', 'to', 'correctly', 'process', 'text', 'various', 'applications']
これは、アナライザーが入力テキストを適切にトークン化し、ストップワード "a"、"an"、"for" を除外しながら、残りの意味のあるトークンを返すことを示しています。
上記の standard ビルトインアナライザーの構成は、以下のパラメーターで カスタムアナライザー を設定することと同等です。ここでは、tokenizer および filter オプションが明示的に定義され、同様の機能を実現しています。
- Python
- Java
- NodeJS
- Go
- cURL
analyzer_params = {
"tokenizer": "standard",
"filter": [
"lowercase",
{
"type": "stop",
"stop_words": ["a", "an", "for"]
}
]
}
Map<String, Object> analyzerParams = new HashMap<>();
analyzerParams.put("tokenizer", "standard");
analyzerParams.put("filter",
Arrays.asList("lowercase",
new HashMap<String, Object>() {{
put("type", "stop");
put("stop_words", Arrays.asList("a", "an", "for"));
}}));
const analyzer_params = {
"tokenizer": "standard",
"filter": [
"lowercase",
{
"type": "stop",
"stop_words": ["a", "an", "for"]
}
]
};
analyzerParams = map[string]any{"tokenizer": "standard",
"filter": []any{"lowercase", map[string]any{
"type": "stop",
"stop_words": []string{"a", "an", "for"},
}}}
export analyzerParams='{
"type": "standard",
"filter": [
"lowercase",
{
"type": "stop",
"stop_words": ["a", "an", "for"]
}
]
}'
Zilliz Cloud には、特定のテキスト処理ニーズに合わせて設計された以下の組み込みアナライザーが用意されています。
-
standard: 汎用的なテキスト処理に適しており、標準的なトークン化と小文字フィルタリングを適用します。 -
english: 英語テキスト向けに最適化されており、英語のストップワードに対応しています。 -
chinese: 中国語テキストの処理に特化しており、中国語の言語構造に合わせたトークン化を含みます。
カスタムアナライザー
より高度なテキスト処理を行うには、Zilliz Cloud のカスタムアナライザーを使用して、トークナイザーとフィルターを指定することで、用途に合わせたテキスト処理パイプラインを構築できます。この設定は、細やかな制御が必要な特殊なユースケースに最適です。
トークナイザー
トークナイザーはカスタムアナライザーに必須のコンポーネントであり、入力テキストを個別の単位(トークン)に分割することでアナライザーパイプラインを開始します。トークン化は、ホワイトスペースや句読点による分割など、トークナイザーの種類に応じた特定のルールに従って行われます。これにより、各単語やフレーズをより正確かつ独立的に処理できます。
例えば、トークナイザーはテキスト "Vector データベース Built for Scale" を以下のような個別のトークンに変換します:
["Vector", "Database", "Built", "for", "Scale"]
トークナイザーを指定する例:
- Python
- Java
- NodeJS
- Go
- cURL
analyzer_params = {
"tokenizer": "whitespace",
}
Map<String, Object> analyzerParams = new HashMap<>();
analyzerParams.put("tokenizer", "whitespace");
const analyzer_params = {
"tokenizer": "whitespace",
};
analyzerParams = map[string]any{"tokenizer": "whitespace"}
export analyzerParams='{
"type": "whitespace"
}'
Filter
フィルターはトークナイザーによって生成されたトークンに対して機能するオプションのコンポーネントであり、必要に応じてそれらを変換または精製します。たとえば、トークン化された語 ["Vector", "データベース", "Built", "for", "Scale"] に lowercase フィルターを適用すると、結果は次のようになります:
["vector", "database", "built", "for", "scale"]
カスタムアナライザーのフィルターは、構成要件に応じて 組み込み または カスタム のいずれかになります。
-
組み込みフィルター: Zilliz Cloud によって事前に構成されており、最小限の設定で済みます。これらのフィルターは、名前を指定するだけですぐに使用できます。以下のフィルターは、直接使用できる組み込みフィルターです:
-
lowercase: テキストを小文字に変換し、大文字小文字を区別しないマッチングを実現します。詳細については、Lowercase を参照してください。 -
asciifolding: 非 ASCII 文字を ASCII 相当の文字に変換し、多言語テキストの処理を簡素化します。詳細については、ASCII folding を参照してください。 -
alphanumonly: 英数字以外の文字を削除し、英数字のみを保持します。詳細については、アルファnumonly を参照してください。 -
cnalphanumonly: 中国語文字、英字、数字以外の文字を含むトークンを削除します。詳細については、Cnalphanumonly を参照してください。 -
cncharonly: 中国語文字以外の文字を含むトークンを削除します。詳細については、Cncharonly を参照してください。
組み込みフィルターの使用例:
- Python
- Java
- NodeJS
- Go
- cURL
analyzer_params = {"tokenizer": "standard", # Mandatory: Specifies tokenizer"filter": ["lowercase"], # Optional: Built-in filter that converts text to lowercase}Map<String, Object> analyzerParams = new HashMap<>();analyzerParams.put("tokenizer", "standard");analyzerParams.put("filter", Collections.singletonList("lowercase"));const analyzer_params = {"tokenizer": "standard", // Mandatory: Specifies tokenizer"filter": ["lowercase"], // Optional: Built-in filter that converts text to lowercase}analyzerParams = map[string]any{"tokenizer": "standard","filter": []any{"lowercase"}}export analyzerParams='{"type": "standard","filter": ["lowercase"]}' -
-
カスタムフィルター: カスタムフィルターは、専門的な設定を可能にします。有効なフィルタータイプ (
filter.type) を選択し、各フィルタータイプに固有の設定を追加することで、カスタムフィルターを定義できます。カスタマイズをサポートするフィルタータイプの例:-
stop: ストップワードのリストを設定することで、指定した一般的な単語を削除します(例:"stop_words": ["of", "to"])。詳細については、Stop を参照してください。 -
length: 最大トークン長の設定など、長さの条件に基づいてトークンを除外します。詳細については、Length を参照してください。 -
stemmer: 単語を語幹に還元することで、より柔軟なマッチングを実現します。詳細については、Stemmer を参照してください。
カスタムフィルターの設定例:
- Python
- Java
- NodeJS
- Go
- cURL
analyzer_params = {"tokenizer": "standard", # Mandatory: Specifies tokenizer"filter": [{"type": "stop", # Specifies 'stop' as the filter type"stop_words": ["of", "to"], # Customizes stop words for this filter type}]}Map<String, Object> analyzerParams = new HashMap<>();analyzerParams.put("tokenizer", "standard");analyzerParams.put("filter",Collections.singletonList(new HashMap<String, Object>() {{put("type", "stop");put("stop_words", Arrays.asList("a", "an", "for"));}}));const analyzer_params = {"tokenizer": "standard", // Mandatory: Specifies tokenizer"filter": [{"type": "stop", // Specifies 'stop' as the filter type"stop_words": ["of", "to"], // Customizes stop words for this filter type}]};analyzerParams = map[string]any{"tokenizer": "standard","filter": []any{map[string]any{"type": "stop","stop_words": []string{"of", "to"},}}}export analyzerParams='{"type": "standard","filter": [{"type": "stop","stop_words": ["a", "an", "for"]}]}' -
nlohmann::json analyzer_params = {
{"type", "standard"},
{"filter", {{{"type", "stop"}, {"stop_words", {"a", "an", "for"}}}}},
};
使用例
この例では、以下の要素を含むコレクションスキーマを作成します。
- 埋め込み(embeddings)用のベクトルフィールド。
- テキスト処理用の2つの
VARCHARフィールド:- 1つのフィールドは組み込みアナライザーを使用します。
- もう1つのフィールドはカスタムアナライザーを使用します。
これらの設定をコレクションに組み込む前に、run_analyzer メソッドを使って各アナライザーを検証します。
ステップ 1: MilvusClient の初期化とスキーマの作成
まず、Milvus クライアントをセットアップし、新しいスキーマを作成します。
- Python
- Java
- NodeJS
- Go
- cURL
from pymilvus import MilvusClient, DataType
# Set up a Milvus client
client = MilvusClient(
uri="YOUR_CLUSTER_ENDPOINT",
token="YOUR_CLUSTER_TOKEN"
)
# Create a new schema
schema = client.create_schema(auto_id=True, enable_dynamic_field=False)
import io.milvus.v2.client.ConnectConfig;
import io.milvus.v2.client.MilvusClientV2;
import io.milvus.v2.common.DataType;
import io.milvus.v2.common.IndexParam;
import io.milvus.v2.service.collection.request.AddFieldReq;
import io.milvus.v2.service.collection.request.CreateCollectionReq;
// Set up a Milvus client
ConnectConfig config = ConnectConfig.builder()
.uri("YOUR_CLUSTER_ENDPOINT")
.token("YOUR_CLUSTER_TOKEN")
.build();
MilvusClientV2 client = new MilvusClientV2(config);
// Create schema
CreateCollectionReq.CollectionSchema schema = CreateCollectionReq.CollectionSchema.builder()
.enableDynamicField(false)
.build();
import { MilvusClient, DataType } from "@zilliz/milvus2-sdk-node";
// Set up a Milvus client
const client = new MilvusClient({
address: "YOUR_CLUSTER_ENDPOINT",
token: "YOUR_CLUSTER_TOKEN"
);
import (
"context"
"fmt"
"github.com/milvus-io/milvus/client/v2/column"
"github.com/milvus-io/milvus/client/v2/entity"
"github.com/milvus-io/milvus/client/v2/index"
"github.com/milvus-io/milvus/client/v2/milvusclient"
)
ctx, cancel := context.WithCancel(context.Background())
defer cancel()
cli, err := milvusclient.New(ctx, &milvusclient.ClientConfig{
Address: "YOUR_CLUSTER_ENDPOINT",
token: "YOUR_CLUSTER_TOKEN"
})
if err != nil {
fmt.Println(err.Error())
// handle err
}
defer client.Close(ctx)
schema := entity.NewSchema().WithAutoID(true).WithDynamicFieldEnabled(false)
# restful
export MILVUS_HOST="YOUR_CLUSTER_ENDPOINT"
export MILVUS_TOKEN="YOUR_CLUSTER_TOKEN"
curl -X POST "http://${MILVUS_HOST}/v2/vectordb/collections/create" \
-H "Content-Type: application/json" \
-H "Authorization: Bearer ${MILVUS_TOKEN}" \
-d '{
"collectionName": "my_collection",
"dimension": 768,
"schema": {
"autoId": true,
"enableDynamicField": false
}
}'
ステップ 2: アナライザーの設定を定義および検証する
-
組み込みアナライザー(
english)の設定と検証:-
設定: 組み込みの英語アナライザー用にアナライザーのパラメータを定義します。
-
検証:
run_analyzerを使用して、設定が期待されるトークン化を生成することを確認します。
- Python
- Java
- NodeJS
- Go
- cURL
# Built-in analyzer configuration for English text processinganalyzer_params_built_in = {"type": "english"}# Verify built-in analyzer configurationsample_text = "Milvus simplifies text analysis for search."result = client.run_analyzer(sample_text, analyzer_params_built_in)print("Built-in analyzer output:", result)# Expected output:# Built-in analyzer output: ['milvus', 'simplifi', 'text', 'analysi', 'search']Map<String, Object> analyzerParamsBuiltin = new HashMap<>();analyzerParamsBuiltin.put("type", "english");List<String> texts = new ArrayList<>();texts.add("Milvus simplifies text analysis for search.");RunAnalyzerResp resp = client.runAnalyzer(RunAnalyzerReq.builder().texts(texts).analyzerParams(analyzerParamsBuiltin).build());List<RunAnalyzerResp.AnalyzerResult> results = resp.getResults();// Use a built-in analyzer for VARCHAR field \`title_en\`const analyzer_params_built_in = {type: "english",};const sample_text = "Milvus simplifies text analysis for search.";const result = await client.run_analyzer({text: sample_text,analyzer_params: analyzer_params_built_in});analyzerParamsBuiltin := map[string]any{"type": "english"}bs, _ := json.Marshal(analyzerParamsBuiltin)texts := []string{"Milvus simplifies text analysis for search."}option := milvusclient.NewRunAnalyzerOption(texts).WithAnalyzerParams(string(bs))result, err := client.RunAnalyzer(ctx, option)if err != nil {fmt.Println(err.Error())// handle error}# restfulexport MILVUS_HOST="YOUR_CLUSTER_ENDPOINT"export SAMPLE_TEXT="Milvus simplifies text analysis for search."curl -X POST "http://${MILVUS_HOST}/v2/vectordb/common/run_analyzer" \-H "Content-Type: application/json" \-d '{"text": ["'"${SAMPLE_TEXT}"'"],"analyzerParams": "{\"type\":\"english\"}"}' -
-
カスタムアナライザーの設定と検証:
-
設定: 標準のトークナイザーと組み込みの lowercase フィルター、およびトークン長とストップワード用のカスタムフィルターを使用するカスタムアナライザーを定義します。
-
検証:
run_analyzerを使用して、カスタム設定が意図通りにテキストを処理することを確認します。
- Python
- Java
- NodeJS
- Go
- cURL
# Custom analyzer configuration with a standard tokenizer and custom filtersanalyzer_params_custom = {"tokenizer": "standard","filter": ["lowercase", # Built-in filter: convert tokens to lowercase{"type": "length", # Custom filter: restrict token length"max": 40},{"type": "stop", # Custom filter: remove specified stop words"stop_words": ["of", "for"]}]}# Verify custom analyzer configurationsample_text = "Milvus provides flexible, customizable analyzers for robust text processing."result = client.run_analyzer(sample_text, analyzer_params_custom)print("Custom analyzer output:", result)# Expected output:# Custom analyzer output: ['milvus', 'provides', 'flexible', 'customizable', 'analyzers', 'robust', 'text', 'processing']// Configure a custom analyzerMap<String, Object> analyzerParamsCustom = new HashMap<>();analyzerParamsCustom.put("tokenizer", "standard");analyzerParamsCustom.put("filter",Arrays.asList("lowercase",new HashMap<String, Object>() {{put("type", "length");put("max", 40);}},new HashMap<String, Object>() {{put("type", "stop");put("stop_words", Arrays.asList("of", "for"));}}));List<String> texts = new ArrayList<>();texts.add("Milvus provides flexible, customizable analyzers for robust text processing.");RunAnalyzerResp resp = client.runAnalyzer(RunAnalyzerReq.builder().texts(texts).analyzerParams(analyzerParamsCustom).build());List<RunAnalyzerResp.AnalyzerResult> results = resp.getResults();// Configure a custom analyzer for VARCHAR field \`title\`const analyzer_params_custom = {tokenizer: "standard",filter: ["lowercase",{type: "length",max: 40,},{type: "stop",stop_words: ["of", "to"],},],};const sample_text = "Milvus provides flexible, customizable analyzers for robust text processing.";const result = await client.run_analyzer({text: sample_text,analyzer_params: analyzer_params_custom});analyzerParamsCustom = map[string]any{"tokenizer": "standard","filter": []any{"lowercase",map[string]any{"type": "length","max": 40,map[string]any{"type": "stop","stop_words": []string{"of", "to"},}}}bs, _ := json.Marshal(analyzerParamsCustom)texts := []string{"Milvus provides flexible, customizable analyzers for robust text processing."}option := milvusclient.NewRunAnalyzerOption(texts).WithAnalyzerParams(string(bs))result, err := client.RunAnalyzer(ctx, option)if err != nil {fmt.Println(err.Error())// handle error}# curlexport MILVUS_HOST="YOUR_CLUSTER_ENDPOINT"export SAMPLE_TEXT="Milvus provides flexible, customizable analyzers for robust text processing."# 使用自定义分析器配置curl -X POST "http://${MILVUS_HOST}/v2/vectordb/common/run_analyzer" \-H "Content-Type: application/json" \-d '{"text": ["'"${SAMPLE_TEXT}"'"],"analyzerParams": "{\"tokenizer\":\"standard\",\"filter\":[\"lowercase\",{\"type\":\"length\",\"max\":40},{\"type\":\"stop\",\"stop_words\":[\"of\",\"for\"]}]}"}' -
ステップ 3: スキーマフィールドにアナライザーを追加する
アナライザーの設定を確認できたので、スキーマフィールドにそれらを追加します:
- Python
- Java
- NodeJS
- Go
- cURL
# Add VARCHAR field 'title_en' using the built-in analyzer configuration
schema.add_field(
field_name='title_en',
datatype=DataType.VARCHAR,
max_length=1000,
enable_analyzer=True,
analyzer_params=analyzer_params_built_in,
enable_match=True,
)
# Add VARCHAR field 'title' using the custom analyzer configuration
schema.add_field(
field_name='title',
datatype=DataType.VARCHAR,
max_length=1000,
enable_analyzer=True,
analyzer_params=analyzer_params_custom,
enable_match=True,
)
# Add a vector field for embeddings
schema.add_field(field_name="embedding", datatype=DataType.FLOAT_VECTOR, dim=3)
# Add a primary key field
schema.add_field(field_name="id", datatype=DataType.INT64, is_primary=True)
schema.addField(AddFieldReq.builder()
.fieldName("title_en")
.dataType(DataType.VarChar)
.maxLength(1000)
.enableAnalyzer(true)
.analyzerParams(analyzerParamsBuiltin)
.enableMatch(true) // must enable this if you use TextMatch
.build());
schema.addField(AddFieldReq.builder()
.fieldName("title")
.dataType(DataType.VarChar)
.maxLength(1000)
.enableAnalyzer(true)
.analyzerParams(analyzerParamsCustom)
.enableMatch(true) // must enable this if you use TextMatch
.build());
// Add vector field
schema.addField(AddFieldReq.builder()
.fieldName("embedding")
.dataType(DataType.FloatVector)
.dimension(3)
.build());
// Add primary field
schema.addField(AddFieldReq.builder()
.fieldName("id")
.dataType(DataType.Int64)
.isPrimaryKey(true)
.autoID(true)
.build());
// Create schema
const schema = {
auto_id: true,
fields: [
{
name: "id",
type: DataType.INT64,
is_primary: true,
},
{
name: "title_en",
data_type: DataType.VARCHAR,
max_length: 1000,
enable_analyzer: true,
analyzer_params: analyzerParamsBuiltIn,
enable_match: true,
},
{
name: "title",
data_type: DataType.VARCHAR,
max_length: 1000,
enable_analyzer: true,
analyzer_params: analyzerParamsCustom,
enable_match: true,
},
{
name: "embedding",
data_type: DataType.FLOAT_VECTOR,
dim: 4,
},
],
};
schema.WithField(entity.NewField().
WithName("id").
WithDataType(entity.FieldTypeInt64).
WithIsPrimaryKey(true).
WithIsAutoID(true),
).WithField(entity.NewField().
WithName("embedding").
WithDataType(entity.FieldTypeFloatVector).
WithDim(3),
).WithField(entity.NewField().
WithName("title_en").
WithDataType(entity.FieldTypeVarChar).
WithMaxLength(1000).
WithEnableAnalyzer(true).
WithAnalyzerParams(analyzerParamsBuiltin).
WithEnableMatch(true),
).WithField(entity.NewField().
WithName("title").
WithDataType(entity.FieldTypeVarChar).
WithMaxLength(1000).
WithEnableAnalyzer(true).
WithAnalyzerParams(analyzerParamsCustom).
WithEnableMatch(true),
)
# restful
export SCHEMA_CONFIG='{
"autoId": false,
"enableDynamicField": false,
"fields": [
{
"fieldName": "id",
"dataType": "Int64",
"isPrimary": true
},
{
"fieldName": "title_en",
"dataType": "VarChar",
"elementTypeParams": {
"max_length": "1000",
"enable_analyzer": true,
"analyzer_params": "{\"type\":\"english\"}",
"enable_match": true
}
},
{
"fieldName": "title",
"dataType": "VarChar",
"elementTypeParams": {
"max_length": "1000",
"enable_analyzer": true,
"analyzer_params": "{\"tokenizer\":\"standard\",\"filter\":[\"lowercase\",{\"type\":\"length\",\"max\":40},{\"type\":\"stop\",\"stop_words\":[\"of\",\"for\"]}]}",
"enable_match": true
}
},
{
"fieldName": "embedding",
"dataType": "FloatVector",
"elementTypeParams": {
"dim": "3"
}
}
]
}'
ステップ 4: インデックスパラメータを準備してコレクションを作成する
- Python
- Java
- NodeJS
- Go
- cURL
# Set up index parameters for the vector field
index_params = client.prepare_index_params()
index_params.add_index(field_name="embedding", metric_type="COSINE", index_type="AUTOINDEX")
# Create the collection with the defined schema and index parameters
client.create_collection(
collection_name="my_collection",
schema=schema,
index_params=index_params
)
// Set up index params for vector field
List<IndexParam> indexes = new ArrayList<>();
indexes.add(IndexParam.builder()
.fieldName("embedding")
.indexType(IndexParam.IndexType.AUTOINDEX)
.metricType(IndexParam.MetricType.COSINE)
.build());
// Create collection with defined schema
CreateCollectionReq requestCreate = CreateCollectionReq.builder()
.collectionName("my_collection")
.collectionSchema(schema)
.indexParams(indexes)
.build();
client.createCollection(requestCreate);
// Set up index params for vector field
const indexParams = [
{
name: "embedding",
metric_type: "COSINE",
index_type: "AUTOINDEX",
},
];
// Create collection with defined schema
await client.createCollection({
collection_name: "my_collection",
schema: schema,
index_params: indexParams,
});
console.log("Collection created successfully!");
idx := index.NewAutoIndex(index.MetricType(entity.COSINE))
indexOption := milvusclient.NewCreateIndexOption("my_collection", "embedding", idx)
err = client.CreateCollection(ctx,
milvusclient.NewCreateCollectionOption("my_collection", schema).
WithIndexOptions(indexOption))
if err != nil {
fmt.Println(err.Error())
// handle error
}
export INDEX_PARAMS='[{"fieldName": "embedding", "metricType": "COSINE", "indexType": "AUTOINDEX"}]'
# restful
curl -X POST "YOUR_CLUSTER_ENDPOINT/v2/vectordb/collections/create" \
-H "Content-Type: application/json" \
-d "{
\"collectionName\": \"my_collection\",
\"schema\": ${SCHEMA_CONFIG},
\"indexParams\": ${INDEX_PARAMS}
}"
Zilliz Cloud コンソールでの使用例
上記の操作は Zilliz Cloud コンソールからも実行できます。詳細については、以下のデモをご覧ください。
Analyzer の設定はコレクション作成後に変更することはできません。Analyzer の設定を変更する場合は、必要な設定で新しいコレクションを作成し、データを移行してください。
次のステップ
Analyzer を設定する際には、ユースケースに最適な設定を決定するために、以下のベストプラクティス記事を参照することをお勧めします。
Analyzer の設定後は、Zilliz Cloud が提供するテキスト検索機能と統合できます。詳細については以下をご覧ください。