ユースケースに適したアナライザーの選択
このガイドでは、Zilliz Cloud でテキストコンテンツに最も適した アナライザー を選択および構成する方法を説明します。
本ガイドは 実用的な意思決定 に焦点を当てています:どのアナライザーを使用するか、いつカスタマイズするか、および構成を確認する方法について説明します。アナライザーのコンポーネントとパラメータの背景については、アナライザーの概要 を参照してください。
クイックコンセプト:アナライザーの仕組み
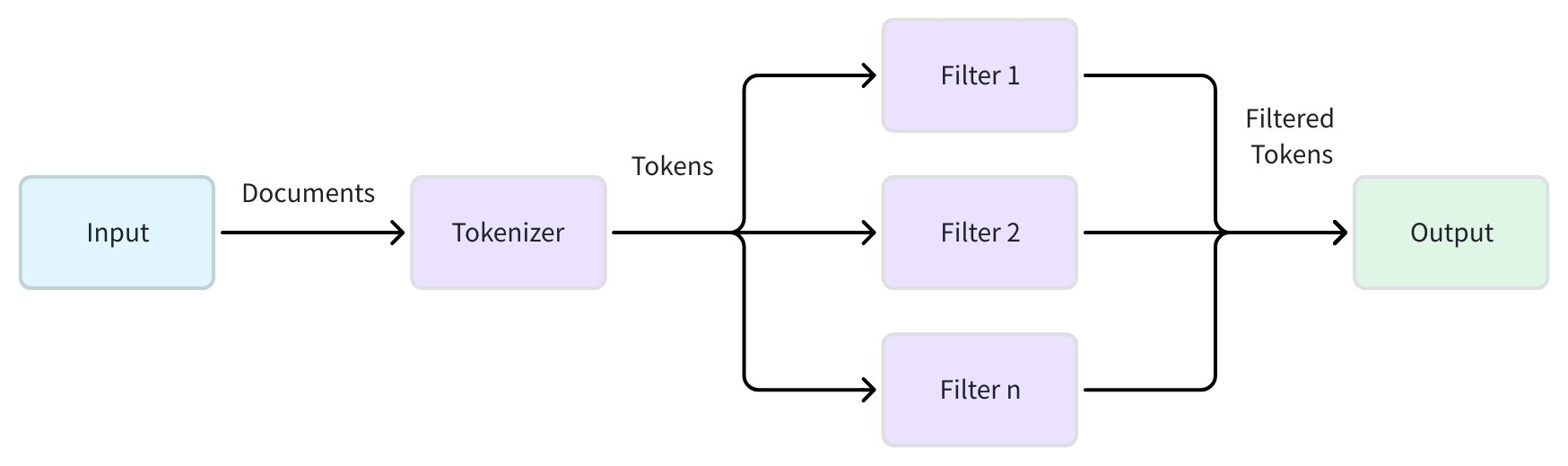
アナライザーは、全文検索(BM25 ベース)、フレーズ一致、または テキスト一致 などの機能で検索可能になるようにテキストデータを処理します。2段階のパイプラインを通じて、生のテキストを個別の検索可能なトークンに変換します。
-
トークン化(必須): この初期段階では、トークナイザー を適用して、連続したテキスト文字列をトークンと呼ばれる個別の意味のある単位に分割します。トークン化の方法は、言語やコンテンツの種類によって大きく異なる場合があります。
-
トークンフィルタリング(オプション): トークン化後、フィルター を適用してトークンを変更、削除、または絞り込みます。これらの操作には、すべてのトークンを小文字に変換する、一般的な意味のない単語(ストップワードなど)を削除する、または単語を語幹に還元する(ステミング)などが含まれます。
例:
Input: "Hello World!"
1. Tokenization → ["Hello", "World", "!"]
2. Lowercase & Punctuation Filtering → ["hello", "world"]
アナライザーの選択が重要な理由
選択するアナライザーは、検索の品質と関連性に直接影響します。
不適切なアナライザーは、過剰なトークン化や不十分なトークン化、用語の欠落、または不関連な結果を引き起こす可能性があります。
問題 | 症状 | 例(入力と出力) | 原因(不適切なアナライザー) | ソリューション(適切なアナライザー) |
|---|---|---|---|---|
過剰なトークン化 | 技術用語、識別子、または URL が誤って分割される |
|
|
|
不十分なトークン化 | 複数単語のフレーズが単一のトークンとして扱われる |
|
| |
言語の不一致 | 外国語の結果が意味をなさない | 中国語テキスト: |
|
|
ステップ 1: アナライザーを選択する必要があるか
テキスト検索機能(例: 全文検索、フレーズ一致、または テキスト一致)を使用しているが、アナライザーを明示的に指定していない場合、
Zilliz Cloud は自動的に 標準アナライザー を適用します。
標準アナライザーの動作:
-
テキストをスペースと句読点で分割する
-
すべてのトークンを小文字に変換する
変換例:
Input: "The Milvus vector database is built for scale!"
Output: ['the', 'milvus', 'vector', 'database', 'is', 'built', 'for', 'scale']
Step 2: 標準アナライザーが要件を満たすか確認する
この表を使用して、デフォルトの standard アナライザー が要件を満たすかどうかを迅速に判断してください。満たさない場合は、別の方法を選択する 必要があります。
Your Content | Standard Analyzer OK? | Why | What You Need |
|---|---|---|---|
English blog posts | ✅ Yes | Default behavior is sufficient. | Use the default (no configuration needed). |
Chinese documents | ❌ No | Chinese words have no spaces and will be treated as one token. | Use a built-in |
Technical documentation | ❌ No | Punctuation is stripped from terms like | Create a custom analyzer with a |
Space-separated languages such as French/Spanish text | ⚠️ Maybe | Accented characters ( | A custom analyzer with the |
Multilingual or unknown languages | ❌ No | The | Use a custom analyzer with the Alternatively, consider configuring 多言語アナライザーs or a 言語識別子 for more precise handling of multilingual content. |
Step 3: 方法を選択する
デフォルトの standard アナライザー が不十分な場合、2つの方法から1つを選択してください。
-
方法 A – 組み込みアナライザーを使用する(すぐに使用可能、言語固有)
-
方法 B – カスタムアナライザーを作成する(トークナイザー + フィルターのセットを手動で定義)
方法 A: 組み込みアナライザーを使用する
組み込みアナライザーは、一般的な言語向けの事前設定済みソリューションです。デフォルトの standard アナライザーが完全に適合しない場合に、最も簡単に始められる方法です。
利用可能な組み込みアナライザー
Analyzer | 言語 Support | Components | Notes |
|---|---|---|---|
Most space-separated languages (English, French, German, Spanish, etc.) |
| 一般-purpose analyzer for initial text processing. For monolingual scenarios, language-specific analyzers (like | |
Dedicated to English, which applies stemming and stop word removal for better English semantic matching |
| Recommended for English-only content over | |
Chinese |
| Currently uses Simplified Chinese dictionary by default. |
実装例
組み込みアナライザーを使用するには、フィールドスキーマを定義する際に analyzer_params でそのタイプを指定するだけです。
# Using built-in English analyzer
analyzer_params = {
"type": "english"
}
# Applying analyzer config to target VARCHAR field in your collection schema
schema.add_field(
field_name='text',
datatype=DataType.VARCHAR,
max_length=200,
enable_analyzer=True,
analyzer_params=analyzer_params,
)
Path B: カスタムアナライザーの作成
ビルトインオプションでニーズが満たされない場合は、トークナイザーと一連のフィルターを組み合わせてカスタムアナライザーを作成できます。これにより、テキスト処理パイプラインを完全に制御できます。
Step 1: 言語に基づいてトークナイザーを選択する
コンテンツの主要な言語に基づいてトークナイザーを選択してください:
西洋言語
スペース区切りの言語では、以下のオプションがあります:
トークナイザー | How It Works | Best For | Examples |
|---|---|---|---|
スペースと句読点に基づいてテキストを分割 | 一般テキスト、混在する句読点 |
| |
空白文字のみで分割 | 前処理済みコンテンツ、ユーザー書式設定テキスト |
|
東アジア言語
辞書ベースの言語では、適切な単語分割のために専用のトークナイザーが必要です:
中国語
トークナイザー | How It Works | Best For | Examples |
|---|---|---|---|
中国語辞書ベースの分割とインテリジェントアルゴリズム | 中国語コンテンツに推奨 - 辞書とインテリジェントアルゴリズムを組み合わせ、中国語専用に設計 |
| |
中国語辞書(cc-cedict)を使用した純粋な辞書ベースの形態素解析 |
|
|
日本語と韓国語
言語 | トークナイザー | Dictionary Options | Best For | Examples |
|---|---|---|---|---|
Japanese | ipadic(汎用)、ipadic-neologd(現代用語)、unidic(学術) | 固有名詞処理を含む形態素解析 |
| |
Korean | 韓国語の形態素解析 |
|
多言語または不明な言語
言語が予測不可能であったり、ドキュメント内で混在しているコンテンツの場合:
トークナイザー | How It Works | Best For | Examples |
|---|---|---|---|
Unicode対応トークン化(International Components for Unicode) | 混在するスクリプト、不明な言語、または単純なトークン化で十分な場合 |
|
icuを使用する場合:
-
言語識別が実用的でない混在言語の場合。
-
多言語アナライザーsや言語識別子のオーバーヘッドを避けたい場合。
-
主要な言語があり、全体の意味にほとんど寄与しない外国語の単語が断続的に含まれるコンテンツの場合(例:日本語やフランス語のブランド名や技術用語が断続的に含まれる英語テキスト)。
代替アプローチ: 多言語コンテンツをより正確に処理するには、多言語アナライザーsまたは言語識別子の使用を検討してください。詳細については、Multi-language Analyzersまたは言語 Identifierを参照してください。
Step 2: 精度のためのフィルターを追加する
トークナイザーの選択後は、特定の検索要件とコンテンツの特性に基づいてフィルターを適用します。
一般的に使用されるフィルター
これらのフィルターは、ほとんどのスペース区切り言語設定(英語、フランス語、ドイツ語、スペイン語など)に不可欠であり、検索品質を大幅に向上させます:
Filter | How It Works | When to Use | Examples |
|---|---|---|---|
すべてのトークンを小文字に変換 | 普遍的 - 大文字小文字の区別があるすべての言語に適用 |
| |
単語を語幹に還元 | 単語の屈折がある言語(英語、フランス語、ドイツ語など) | 英語の場合:
| |
一般的な意味のない単語を削除 | ほとんどの言語 - 特にスペース区切りの言語で効果的 |
|
東アジア言語(中国語、日本語、韓国語など)の場合は、代わりに言語固有のフィルターに焦点を当ててください。これらの言語では、通常、テキスト処理に異なるアプローチを使用し、ステミングから大きな利益を得られない場合があります。
テキスト正規化フィルター
これらのフィルターは、テキストのバリエーションを標準化して、マッチングの一貫性を向上させます:
Filter | How It Works | When to Use | Examples |
|---|---|---|---|
アクセント付き文字をASCII相当に変換 | 国際的なコンテンツ、ユーザー生成コンテンツ |
|
トークン フィルタリング
文字コンテンツまたは長さに基づいて、どのトークンを保持するかを制御します:
Filter | How It Works | When to Use | Examples |
|---|---|---|---|
スタンドアロンの句読点トークンを削除 |
|
| |
文字と数字のみを保持 | 技術コンテンツ、クリーンなテキスト処理 |
| |
指定された長さ範囲外のトークンを削除 | ノイズの除去(過度に長いトークン) |
| |
カスタムパターンに基づくフィルタリング | ドメイン固有のトークン要件 |
|
言語固有のフィルター
これらのフィルターは、特定の言語の特性を処理します:
Filter | 言語 | How It Works | Examples |
|---|---|---|---|
German | 複合語を検索可能な構成要素に分割 |
| |
Chinese | 中国語文字と英数字を保持 |
| |
Chinese | 中国語文字のみを保持 |
|
Step 3: 組み合わせて実装する
カスタムアナライザーを作成するには、analyzer_params ディクショナリでトークナイザーとフィルターのリストを定義します。フィルターは、リストされた順序で適用されます。
# Example: A custom analyzer for technical content
analyzer_params = {
"tokenizer": "whitespace",
"filter": ["lowercase", "alphanumonly"]
}
# Applying analyzer config to target VARCHAR field in your collection schema
schema.add_field(
field_name='text',
datatype=DataType.VARCHAR,
max_length=200,
enable_analyzer=True,
analyzer_params=analyzer_params,
)
最終確認:run_analyzer でのテスト
コレクションに適用する前に、常に設定を検証してください:
# Sample text to analyze
sample_text = "The Milvus vector database is built for scale!"
# Run analyzer with the defined configuration
result = client.run_analyzer(sample_text, analyzer_params)
print("Analyzer output:", result)
Common issues to check:
-
過剰なトークン化: Technical terms being split incorrectly
-
不十分なトークン化: Phrases not being separated properly
-
欠落しているトークン: Important terms being filtered out
For detailed usage, refer to run_analyzer.
ユースケース別のクイックレシピ
This section provides recommended tokenizer and filter configurations for common use cases when working with analyzers in Zilliz Cloud. Choose the combination that best matches your content type and search requirements.
Before applying an analyzer to your collection, we recommend you use run_analyzer to test and validate text analysis performance.
English
analyzer_params = {
"tokenizer": "standard",
"filter": [
"lowercase",
{
"type": "stemmer",
"language": "english"
},
{
"type": "stop",
"stop_words": [
"_english_"
]
}
]
}
中国語
{
"tokenizer": "jieba",
"filter": ["cnalphanumonly"]
}
アラビア語
{
"tokenizer": "standard",
"filter": [
"lowercase",
{
"type": "stemmer",
"language": "arabic"
}
]
}
ベンガル語
{
"tokenizer": "icu",
"filter": ["lowercase", {
"type": "stop",
"stop_words": [<put stop words list here>]
}]
}
フランス語
{
"tokenizer": "standard",
"filter": [
"lowercase",
{
"type": "stemmer",
"language": "french"
},
{
"type": "stop",
"stop_words": [
"_french_"
]
}
]
}
ドイツ語
{
"tokenizer": {
"type": "lindera",
"dict_kind": "ipadic"
},
"filter": [
"removepunct"
]
}
हिन्दी
{
"tokenizer": "icu",
"filter": ["lowercase", {
"type": "stop",
"stop_words": [<put stop words list here>]
}]
}
韓国語
{
"tokenizer": {
"type": "lindera",
"dict_kind": "ko-dic",
"filter": [
{
"kind": "korean_stop_tags",
"tags": ["SP", "SSC", "SSO", "SC", "SE", "SF", "JKS", "JKC", "JKG", "JKO", "JKB", "JKV", "JKQ", "JX", "JC", "UNK", "EP", "ETM"]
}
]
}
}
Japanese
{
"tokenizer": {
"type": "lindera",
"dict_kind": "ipadic"
},
"filter": [
"removepunct"
]
}
ポルトガル語{#portuguese}
{
"tokenizer": "standard",
"filter": [
"lowercase",
{
"type": "stemmer",
"language": "portuguese"
},
{
"type": "stop",
"stop_words": [
"_portuguese_"
]
}
]
}
ロシア語
{
"tokenizer": "standard",
"filter": [
"lowercase",
{
"type": "stemmer",
"language": "russian"
},
{
"type": "stop",
"stop_words": [
"_russian_"
]
}
]
}
スペイン語
{
"tokenizer": "standard",
"filter": [
"lowercase",
{
"type": "stemmer",
"language": "spanish"
},
{
"type": "stop",
"stop_words": [
"_spanish_"
]
}
]
}
スワヒリ語
{
"tokenizer": "standard",
"filter": ["lowercase", {
"type": "stop",
"stop_words": [<put stop words list here>]
}]
}
トルコ語
{
"tokenizer": "standard",
"filter": [
"lowercase",
{
"type": "stemmer",
"language": "turkish"
}
]
}
Urdu
{
"tokenizer": "icu",
"filter": ["lowercase", {
"type": "stop",
"stop_words": [<put stop words list here>]
}]
}
混合または多言語コンテンツ
複数の言語にまたがるコンテンツや、スクリプトが予測不能に使用されるコンテンツを扱う場合は、icu アナライザーから開始してください。この Unicode 対応アナライザーは、混合スクリプトや記号を効果的に処理します。
基本的な多言語設定(ステミングなし):
analyzer_params = {
"tokenizer": "icu",
"filter": ["lowercase", "asciifolding"]
}
高度な多言語処理:
異なる言語間でのトークン動作をより細かく制御するには:
Zilliz Cloud でアナライザーを設定およびプレビューする
Zilliz Cloud では、Zilliz Cloud コンソールから直接テキストアナライザーの設定とテストを行うことができ、コードを書く必要はありません。