フィルタ付き検索
ANN 検索は、指定されたベクトル埋め込みと最も類似したベクトル埋め込みを見つけます。ただし、検索結果が常に正しいとは限りません。検索リクエストにフィルタリング条件を含めることで、Zilliz Cloud が ANN 検索を実行する前にメタデータのフィルタリングを行い、検索範囲をコレクション全体から指定されたフィルタリング条件に一致するエンティティのみに絞り込むことができます。
概要
Zilliz Cloud では、フィルタリングが適用される段階に応じて、フィルタ付き検索は 標準フィルタリング と 反復フィルタリング の 2 種類に分類されます。
標準フィルタリング
コレクションにベクトル埋め込みとそのメタデータの両方が含まれている場合、ANN 検索の前にメタデータをフィルタリングして、検索結果の関連性を向上させることができます。Zilliz Cloud がフィルタリング条件を含む検索リクエストを受信すると、指定されたフィルタリング条件に一致するエンティティ内に検索範囲を制限します。
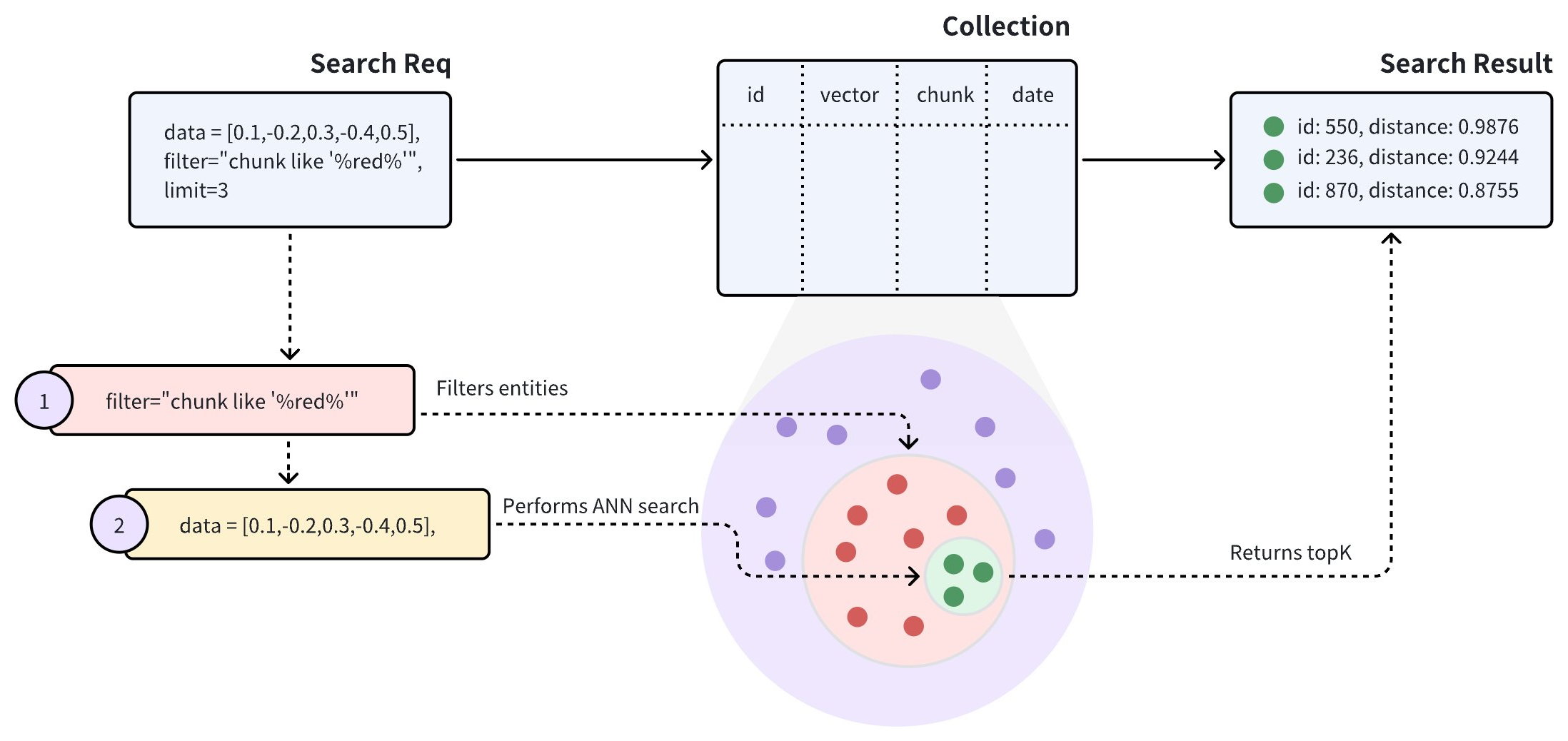
上記の図に示すように、検索リクエストはフィルタリング条件として chunk like "%red%" を含んでおり、Zilliz Cloud は chunk フィールドに red という単語を含むすべてのエンティティ内で ANN 検索を実行する必要があることを示しています。具体的には、Zilliz Cloud は以下を実行します。
-
検索リクエストに含まれるフィルタリング条件に一致するエンティティをフィルタリングします。
-
フィルタリングされたエンティティ内で ANN 検索を実行します。
-
上位 K 件のエンティティを返します。
反復フィルタリング
標準フィルタリング処理は、検索範囲を効果的に狭い範囲に絞り込みます。ただし、過度に複雑なフィルタリング式は、検索レイテンシが非常に高くなる可能性があります。このような場合、反復フィルタリングは代替手段として機能し、スカラーフィルタリングのワークロードを軽減するのに役立ちます。
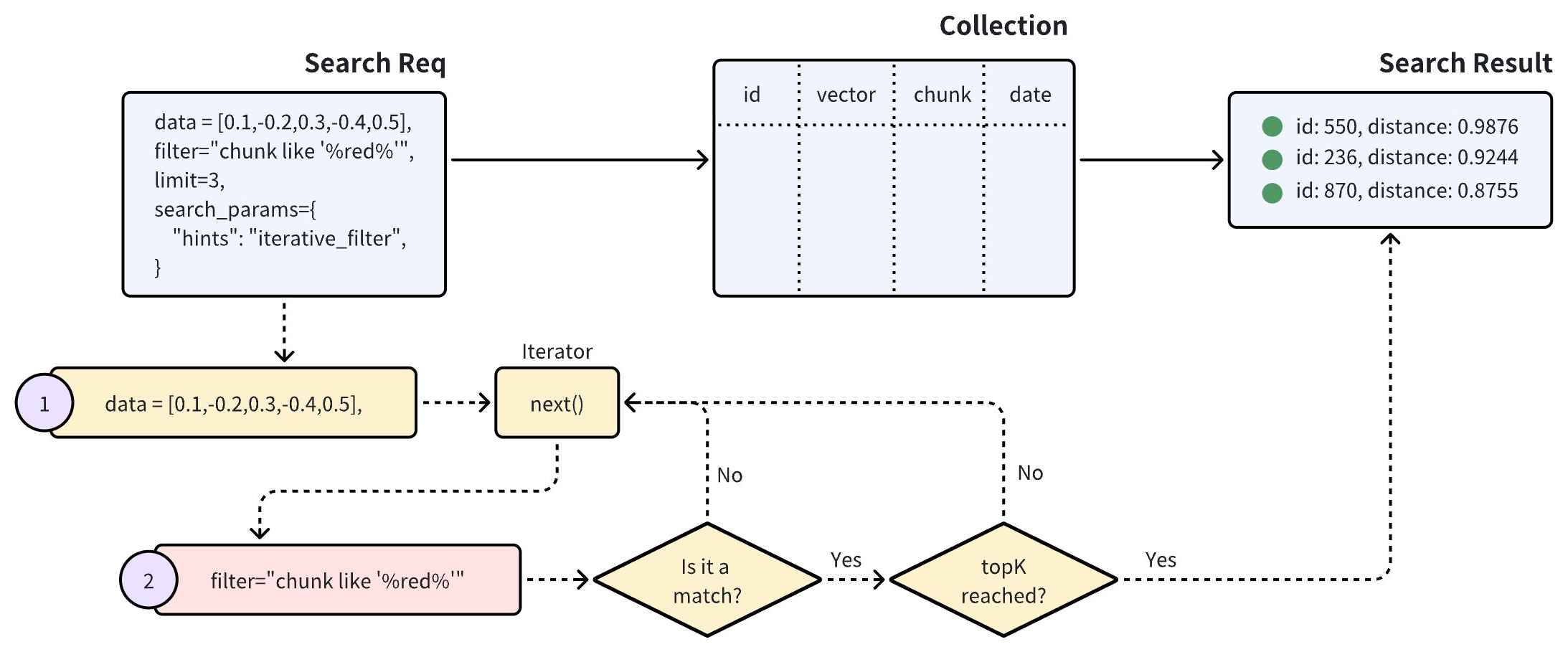
上記の図に示すように、反復フィルタリングを使用した検索は、ベクトル検索を反復処理で実行します。イテレータが返す各エンティティはスカラーフィルタリングを受け、この処理は指定された topK の結果が得られるまで続きます。
この方法により、スカラーフィルタリングの対象となるエンティティの数が大幅に削減され、特に高度に複雑なフィルタリング式の処理に有益です。
ただし、イテレータはエンティティを一度に 1 つずつ処理することに注意が必要です。この逐次アプローチにより、多くのエンティティがスカラーフィルタリングの対象となる場合、処理時間が長くなる可能性やパフォーマンス上の問題が生じる可能性があります。
例
このセクションでは、フィルタ付き検索の実行方法を示します。このセクションのコードスニペットでは、コレクションに以下のエンティティが既に存在することを前提としています。各エンティティには id、vector、color、likes の 4 つのフィールドがあります。
[
{"id": 0, "vector": [0.3580376395471989, -0.6023495712049978, 0.18414012509913835, -0.26286205330961354, 0.9029438446296592], "color": "pink_8682", "likes": 165},
{"id": 1, "vector": [0.19886812562848388, 0.06023560599112088, 0.6976963061752597, 0.2614474506242501, 0.838729485096104], "color": "red_7025", "likes": 25},
{"id": 2, "vector": [0.43742130801983836, -0.5597502546264526, 0.6457887650909682, 0.7894058910881185, 0.20785793220625592], "color": "orange_6781", "likes": 764},
{"id": 3, "vector": [0.3172005263489739, 0.9719044792798428, -0.36981146090600725, -0.4860894583077995, 0.95791889146345], "color": "pink_9298", "likes": 234},
{"id": 4, "vector": [0.4452349528804562, -0.8757026943054742, 0.8220779437047674, 0.46406290649483184, 0.30337481143159106], "color": "red_4794", "likes": 122},
{"id": 5, "vector": [0.985825131989184, -0.8144651566660419, 0.6299267002202009, 0.1206906911183383, -0.1446277761879955], "color": "yellow_4222", "likes": 12},
{"id": 6, "vector": [0.8371977790571115, -0.015764369584852833, -0.31062937026679327, -0.562666951622192, -0.8984947637863987], "color": "red_9392", "likes": 58},
{"id": 7, "vector": [-0.33445148015177995, -0.2567135004164067, 0.8987539745369246, 0.9402995886420709, 0.5378064918413052], "color": "grey_8510", "likes": 775},
{"id": 8, "vector": [0.39524717779832685, 0.4000257286739164, -0.5890507376891594, -0.8650502298996872, -0.6140360785406336], "color": "white_9381", "likes": 876},
{"id": 9, "vector": [0.5718280481994695, 0.24070317428066512, -0.3737913482606834, -0.06726932177492717, -0.6980531615588608], "color": "purple_4976", "likes": 765}
]
クエリベクトルがすでにターゲットコレクションに存在する場合は、検索前にそれらを取得する代わりに ids を使用することを検討してください。詳細については、Primary-キー Search を参照してください。
標準フィルタリングを使用した検索
以下のコードスニペットは、標準フィルタリングを使用した検索を示しており、次のコードスニペットのリクエストにはフィルタリング条件といくつかの出力フィールドが含まれています。
- Python
- Java
- Go
- NodeJS
- cURL
from pymilvus import MilvusClient
client = MilvusClient(
uri="YOUR_CLUSTER_ENDPOINT",
token="YOUR_CLUSTER_TOKEN"
)
query_vector = [0.3580376395471989, -0.6023495712049978, 0.18414012509913835, -0.26286205330961354, 0.9029438446296592]
res = client.search(
collection_name="my_collection",
data=[query_vector],
limit=5,
filter='color like "red%" and likes > 50',
output_fields=["color", "likes"]
)
for hits in res:
print("TopK results:")
for hit in hits:
print(hit)
import io.milvus.v2.client.ConnectConfig;
import io.milvus.v2.client.MilvusClientV2;
import io.milvus.v2.service.vector.request.SearchReq
import io.milvus.v2.service.vector.request.data.FloatVec;
import io.milvus.v2.service.vector.response.SearchResp
MilvusClientV2 client = new MilvusClientV2(ConnectConfig.builder()
.uri("YOUR_CLUSTER_ENDPOINT")
.token("YOUR_CLUSTER_TOKEN")
.build());
FloatVec queryVector = new FloatVec(new float[]{0.3580376395471989f, -0.6023495712049978f, 0.18414012509913835f, -0.26286205330961354f, 0.9029438446296592f});
SearchReq searchReq = SearchReq.builder()
.collectionName("my_collection")
.data(Collections.singletonList(queryVector))
.topK(5)
.filter("color like \"red%\" and likes > 50")
.outputFields(Arrays.asList("color", "likes"))
.build();
SearchResp searchResp = client.search(searchReq);
List<List<SearchResp.SearchResult>> searchResults = searchResp.getSearchResults();
for (List<SearchResp.SearchResult> results : searchResults) {
System.out.println("TopK results:");
for (SearchResp.SearchResult result : results) {
System.out.println(result);
}
}
// Output
// TopK results:
// SearchResp.SearchResult(entity={color=red_4794, likes=122}, score=0.5975797, id=4)
// SearchResp.SearchResult(entity={color=red_9392, likes=58}, score=-0.24996188, id=6)
import (
"context"
"fmt"
"github.com/milvus-io/milvus/client/v2/entity"
"github.com/milvus-io/milvus/client/v2/milvusclient"
)
ctx, cancel := context.WithCancel(context.Background())
defer cancel()
milvusAddr := "YOUR_CLUSTER_ENDPOINT"
token := "YOUR_CLUSTER_TOKEN"
client, err := client.New(ctx, &client.ClientConfig{
Address: milvusAddr,
APIKey: token,
})
if err != nil {
fmt.Println(err.Error())
// handle error
}
defer client.Close(ctx)
queryVector := []float32{0.3580376395471989, -0.6023495712049978, 0.18414012509913835, -0.26286205330961354, 0.9029438446296592}
resultSets, err := client.Search(ctx, milvusclient.NewSearchOption(
"my_collection", // collectionName
5, // limit
[]entity.Vector{entity.FloatVector(queryVector)},
).WithConsistencyLevel(entity.ClStrong).
WithANNSField("vector").
WithFilter("color like 'red%' and likes > 50").
WithOutputFields("color", "likes"))
if err != nil {
fmt.Println(err.Error())
// handle error
}
for _, resultSet := range resultSets {
fmt.Println("IDs: ", resultSet.IDs.FieldData().GetScalars())
fmt.Println("Scores: ", resultSet.Scores)
fmt.Println("color: ", resultSet.GetColumn("color").FieldData().GetScalars())
fmt.Println("likes: ", resultSet.GetColumn("likes").FieldData().GetScalars())
}
import { MilvusClient, DataType } from "@zilliz/milvus2-sdk-node";
const address = "YOUR_CLUSTER_ENDPOINT";
const token = "YOUR_CLUSTER_TOKEN";
const client = new MilvusClient({address, token});
const query_vector = [0.3580376395471989, -0.6023495712049978, 0.18414012509913835, -0.26286205330961354, 0.9029438446296592]
const res = await client.search({
collection_name: "my_collection",
data: [query_vector],
limit: 5,
filters: 'color like "red%" and likes > 50',
output_fields: ["color", "likes"]
})
export CLUSTER_ENDPOINT="YOUR_CLUSTER_ENDPOINT"
export TOKEN="YOUR_CLUSTER_TOKEN"
curl --request POST \
--url "${CLUSTER_ENDPOINT}/v2/vectordb/entities/search" \
--header "Authorization: Bearer ${TOKEN}" \
--header "Content-Type: application/json" \
-d '{
"collectionName": "my_collection",
"data": [
[0.3580376395471989, -0.6023495712049978, 0.18414012509913835, -0.26286205330961354, 0.9029438446296592]
],
"annsField": "vector",
"filter": "color like \"red%\" and likes > 50",
"limit": 5,
"outputFields": ["color", "likes"]
}'
# {"code":0,"cost":0,"data":[]}
検索リクエストに含まれるフィルタリング条件は color like "red%" and likes > 50 です。この条件は and 演算子を使用して2つの条件を組み合わせています。1つ目の条件は、color フィールドの値が red で始まるエンティティを要求し、もう1つの条件は、likes フィールドの値が 50 より大きいエンティティを要求します。これらの要件を満たすエンティティは2つしか存在しません。top-K が 3 に設定されているため、Zilliz Cloud はこの2つのエンティティとクエリベクトルとの距離を計算し、検索結果として返します。
[
{
"id": 4,
"distance": 0.3345786594834839,
"entity": {
"vector": [0.4452349528804562, -0.8757026943054742, 0.8220779437047674, 0.46406290649483184, 0.30337481143159106],
"color": "red_4794",
"likes": 122
}
},
{
"id": 6,
"distance": 0.6638239834383389,
"entity": {
"vector": [0.8371977790571115, -0.015764369584852833, -0.31062937026679327, -0.562666951622192, -0.8984947637863987],
"color": "red_9392",
"likes": 58
}
},
]
メタデータフィルタリングで使用できる演算子の詳細については、フィルタリング を参照してください。
反復フィルタリングを使用した検索
反復フィルタリングを使用したフィルタリング検索を実行するには、以下のようにします。
- Python
- Java
- Go
- NodeJS
- cURL
from pymilvus import MilvusClient
client = MilvusClient(
uri="YOUR_CLUSTER_ENDPOINT",
token="YOUR_CLUSTER_TOKEN"
)
query_vector = [0.3580376395471989, -0.6023495712049978, 0.18414012509913835, -0.26286205330961354, 0.9029438446296592]
res = client.search(
collection_name="my_collection",
data=[query_vector],
limit=5,
filter='color like "red%" and likes > 50',
output_fields=["color", "likes"],
search_params={
"hints": "iterative_filter"
}
)
for hits in res:
print("TopK results:")
for hit in hits:
print(hit)
import io.milvus.v2.client.ConnectConfig;
import io.milvus.v2.client.MilvusClientV2;
import io.milvus.v2.service.vector.request.SearchReq;
import io.milvus.v2.service.vector.request.data.FloatVec;
import io.milvus.v2.service.vector.response.SearchResp;
MilvusClientV2 client = new MilvusClientV2(ConnectConfig.builder()
.uri("YOUR_CLUSTER_ENDPOINT")
.token("YOUR_CLUSTER_TOKEN")
.build());
FloatVec queryVector = new FloatVec(new float[]{0.3580376395471989f, -0.6023495712049978f, 0.18414012509913835f, -0.26286205330961354f, 0.9029438446296592f});
SearchReq searchReq = SearchReq.builder()
.collectionName("my_collection")
.data(Collections.singletonList(queryVector))
.topK(5)
.filter("color like \"red%\" and likes > 50")
.outputFields(Arrays.asList("color", "likes"))
.searchParams(new HashMap<>("hints", "iterative_filter"))
.build();
SearchResp searchResp = client.search(searchReq);
List<List<SearchResp.SearchResult>> searchResults = searchResp.getSearchResults();
for (List<SearchResp.SearchResult> results : searchResults) {
System.out.println("TopK results:");
for (SearchResp.SearchResult result : results) {
System.out.println(result);
}
}
// Output
// TopK results:
// SearchResp.SearchResult(entity={color=red_4794, likes=122}, score=0.5975797, id=4)
// SearchResp.SearchResult(entity={color=red_9392, likes=58}, score=-0.24996188, id=6)
import (
"context"
"fmt"
"github.com/milvus-io/milvus/client/v2/entity"
"github.com/milvus-io/milvus/client/v2/milvusclient"
)
ctx, cancel := context.WithCancel(context.Background())
defer cancel()
milvusAddr := "YOUR_CLUSTER_ENDPOINT"
token := "YOUR_CLUSTER_TOKEN"
client, err := client.New(ctx, &client.ClientConfig{
Address: milvusAddr,
APIKey: token,
})
if err != nil {
fmt.Println(err.Error())
// handle error
}
defer client.Close(ctx)
queryVector := []float32{0.3580376395471989, -0.6023495712049978, 0.18414012509913835, -0.26286205330961354, 0.9029438446296592}
resultSets, err := client.Search(ctx, milvusclient.NewSearchOption(
"my_collection", // collectionName
5, // limit
[]entity.Vector{entity.FloatVector(queryVector)},
).WithConsistencyLevel(entity.ClStrong).
WithANNSField("vector").
WithFilter("color like 'red%' and likes > 50").
WithOutputFields("color", "likes").
WithSearchParam("hints", "iterative_filter"))
if err != nil {
fmt.Println(err.Error())
// handle error
}
for _, resultSet := range resultSets {
fmt.Println("IDs: ", resultSet.IDs.FieldData().GetScalars())
fmt.Println("Scores: ", resultSet.Scores)
fmt.Println("color: ", resultSet.GetColumn("color").FieldData().GetScalars())
fmt.Println("likes: ", resultSet.GetColumn("likes").FieldData().GetScalars())
}
import { MilvusClient, DataType } from "@zilliz/milvus2-sdk-node";
const address = "YOUR_CLUSTER_ENDPOINT";
const token = "YOUR_CLUSTER_TOKEN";
const client = new MilvusClient({address, token});
const query_vector = [0.3580376395471989, -0.6023495712049978, 0.18414012509913835, -0.26286205330961354, 0.9029438446296592]
const res = await client.search({
collection_name: "filtered_search_collection",
data: [query_vector],
limit: 5,
filters: 'color like "red%" and likes > 50',
hints: "iterative_filter",
output_fields: ["color", "likes"]
})
export CLUSTER_ENDPOINT="YOUR_CLUSTER_ENDPOINT"
export TOKEN="YOUR_CLUSTER_TOKEN"
curl --request POST \
--url "${CLUSTER_ENDPOINT}/v2/vectordb/entities/search" \
--header "Authorization: Bearer ${TOKEN}" \
--header "Content-Type: application/json" \
-d '{
"collectionName": "my_collection",
"data": [
[0.3580376395471989, -0.6023495712049978, 0.18414012509913835, -0.26286205330961354, 0.9029438446296592]
],
"annsField": "vector",
"filter": "color like \"red%\" and likes > 50",
"searchParams": {"hints": "iterative_filter"},
"limit": 5,
"outputFields": ["color", "likes"]
}'
# {"code":0,"cost":0,"data":[]}