関数とモデル推論の概要
Zilliz Cloud は、セマンティック検索、語彙検索、ハイブリッド検索、インテリジェントな再ランキングを含む、現代的な検索システムを構築するための統一された検索アーキテクチャを提供します。Zilliz Cloud は、これらの機能を個別の機能として公開するのではなく、関数という単一のコア抽象化概念を中心に整理しています。
関数とは何か?
Zilliz Cloud において、関数とは、検索ワークフローの定義された段階で特定の操作を適用する、設定可能な実行ユニットです。
関数は以下の 3 つの実践的な質問に答えます:
-
この操作はいつ実行されるか? 検索前または検索後。
-
どのような入力に対して動作するか? 生テキスト、ベクトル表現、または取得された候補結果。
-
どのような出力を生成するか? 検索に使用されるベクトル埋め込み、またはユーザーに返される並べ替えられた結果。
ワークフローの観点から見ると、関数は検索において 2 つの異なる段階で役割を果たします:
-
検索前:関数は検索前に実行され、テキストをベクトル表現に変換します。これらのベクトルにより、どの候補が取得されるかが決定されます。
-
検索後:関数は候補取得後に実行され、候補セットを変更することなく結果の順序を洗練します。
以下の図は、検索ワークフローにおいて関数がどのように機能するかの抽象化を示しています。
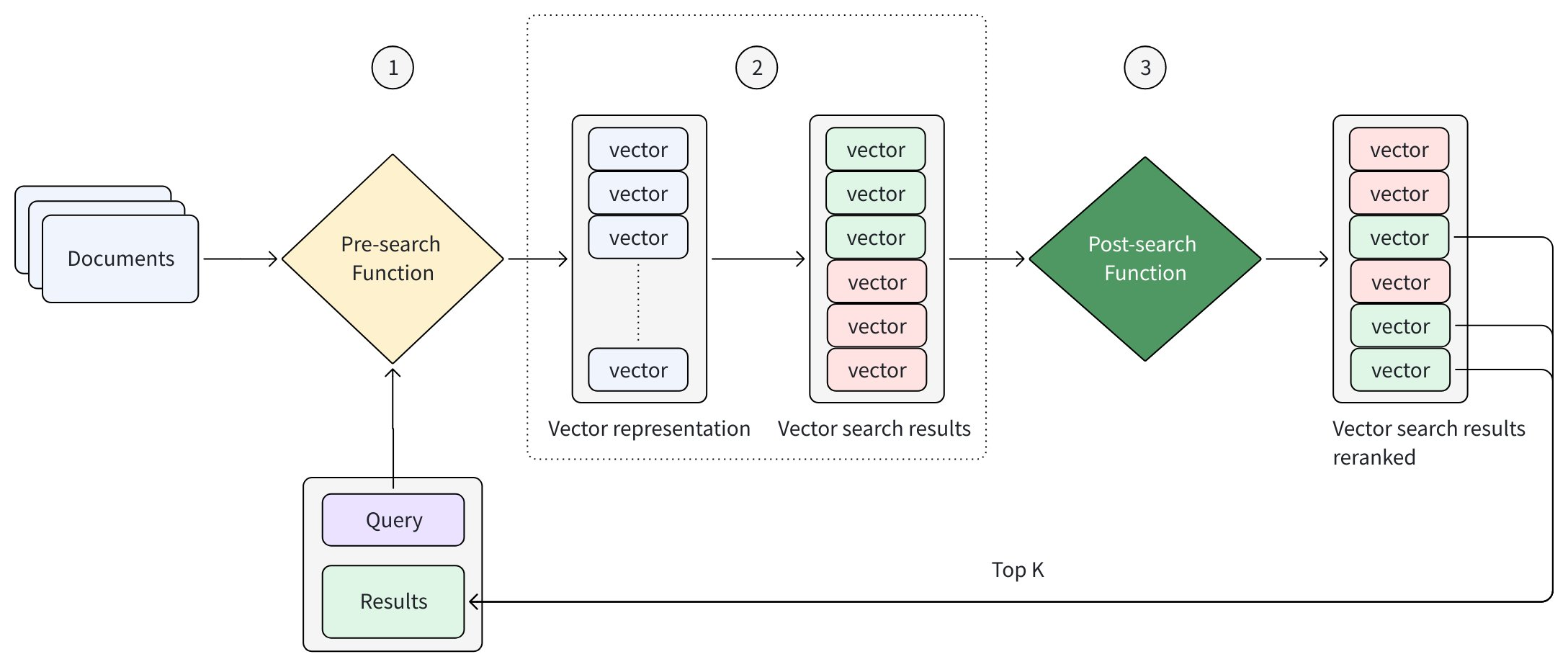
すべての検索リクエストは、同じ高レベルの流れに従います:
-
検索前関数が入力テキストからベクトル表現を生成します
-
検索エンジンがそれらのベクトルに基づいて候補結果を取得します
-
(オプション)検索後関数が取得された候補の再ランキングを行います
関数のカテゴリ
Zilliz Cloud の関数は、検索ワークフローにおける実行時期とそれらが果たす役割に基づいて分類されます。大まかに言えば、関数は 2 つのグループに分かれます:
-
検索前関数:テキストをベクトル埋め込みに変換し、候補の取得を決定します
-
検索後関数:取得された候補の順序を洗練します
検索前関数:テキストをベクトル埋め込みに変換する
検索前関数は候補取得前に実行されます。その役割は、保存されたドキュメントと受信クエリの両方である生テキストを、検索エンジンが関連する候補を特定するために使用するベクトル表現に変換することです。
異なる検索前関数は異なるタイプの埋め込みを生成し、これにより検索の実行方法が直接影響を受けます。
以下の表は、利用可能な検索前関数の概要を示しています:
関数タイプ | ベクトルタイプ | 説明 | 典型的なユースケース |
|---|---|---|---|
BM25 関数 | スパース埋め込み | 項のマッチング、項頻度、および文書長の正規化に基づいて語彙的な関連性を計算します。 データベースエンジン内でローカルメカニズムとして完全に実行され、モデル推論は不要です。 | キーワード駆動型の全文検索、ドキュメントおよびコード検索、ならびに項のマッチング、低レイテンシ、決定論的動作が重要となるワークロード。 |
モデルベースの埋め込み関数 | デンス埋め込み | 機械学習モデルを使用してテキストの意味的意味をエンコードし、正確なキーワードを超えた類似性に基づく検索を可能にします。 ホストされたモデルまたはサードパーティのモデルサービスを介したモデル推論が必要です。 | セマンティック検索、自然言語クエリ、Q&A および RAG パイプライン、ならびに文字通りの項の重複よりも概念的な類似性が重要となるユースケース。 |
すべての検索前関数は、ドキュメントデータとクエリテキストの両方に一貫して適用され、検索が同じ表現空間内で実行されることを保証します。
検索後関数:候補結果の再ランキング
検索後関数は候補取得後に適用されます。その目的は、候補セットから項目を追加または削除することなく、取得された候補のランキングを洗練することです。
これらの関数は検索段階によって返された結果のみに対して動作し、追加のランキングロジックまたは関連性信号を適用して結果の品質を向上させます。これらはインデックス作成、検索、またはフィルタリング動作には影響せず、結果の最終的な順序のみに影響します。
以下の表は、利用可能な検索後関数の概要を示しています:
関数タイプ | 対象 | 説明 | 典型的なユースケース |
|---|---|---|---|
ハイブリッド検索ランカー | ハイブリッド検索から取得された複数の結果セット | セマンティック検索と語彙検索を組み合わせ、バランスの取れた結果融合を必要とするハイブリッド検索シナリオ。 | |
ルールベースのランカー | 単一ベクトル検索またはハイブリッド検索からの候補結果 | ビジネス主導のランキングロジック、最新性または人気度のブースト、および予測可能で非 ML の再ランキングを必要とするシナリオ。 | |
モデルベースのランカー | 単一ベクトル検索またはハイブリッド検索からの候補結果 | 機械学習モデルを使用して関連性を評価し、学習済みまたは意味的信号に基づいて結果を並べ替えます。 | インテリジェントな再ランキング、意味的理解を使用した関連性の洗練、および LLM ベースの関連性評価。 |
検索後関数は取得された候補のみに対して動作するため、これらは検索範囲ではなく結果の順序に影響を与える洗練ステップです。