グループ化検索
グループ化検索を使用すると、Zilliz Cloud は指定したフィールドの値で検索結果をグループ化し、より高いレベルでデータを集計できます。たとえば、基本的な ANN 検索を使用して、手元の本に類似した本を見つけることができますが、グループ化検索を使用すると、その本で議論されているトピックに関連する可能性のある本のカテゴリを見つけることができます。このトピックでは、グループ化検索の使用方法と重要な考慮事項について説明します。
概要
検索結果内のエンティティがスカラーフィールドで同じ値を共有している場合、これは特定の属性において類似していることを示し、検索結果に悪影響を与える可能性があります。
コレクションに複数のドキュメント(docId で表される)が保存されていると仮定します。ドキュメントをベクトルに変換する際にできるだけ多くのセマンティック情報を保持するために、各ドキュメントはより小さく管理しやすい段落(または chunks)に分割され、別々のエンティティとして保存されます。ドキュメントが小さなセクションに分割されていても、ユーザーは通常、自分のニーズに最も関連するドキュメントを特定することに依然として関心を持っています。
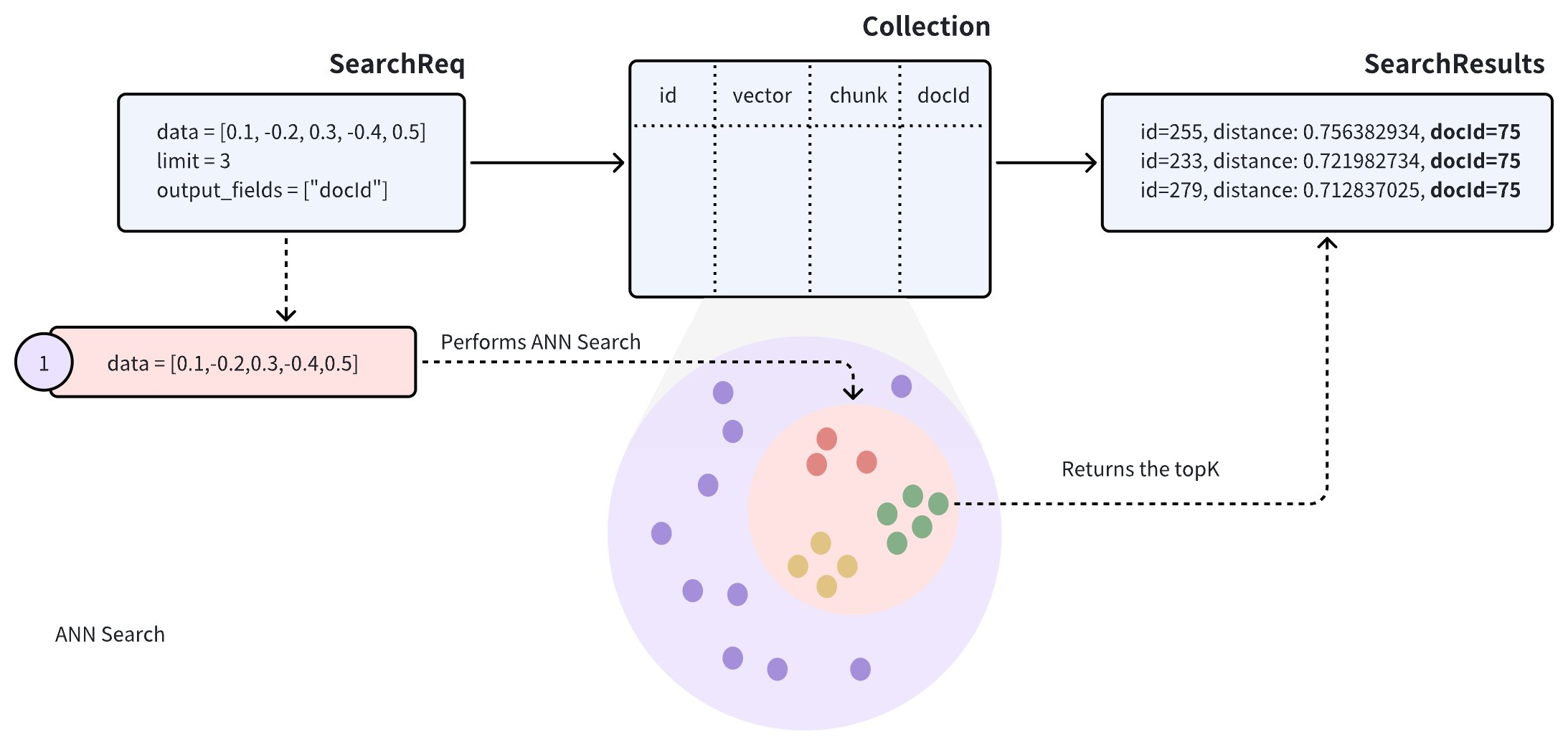
このようなコレクションで近似最近傍(ANN)検索を実行すると、検索結果に同じドキュメントからの複数の段落が含まれる可能性があり、他のドキュメントが見落とされる可能性があります。これは意図したユースケースと一致しない可能性があります。
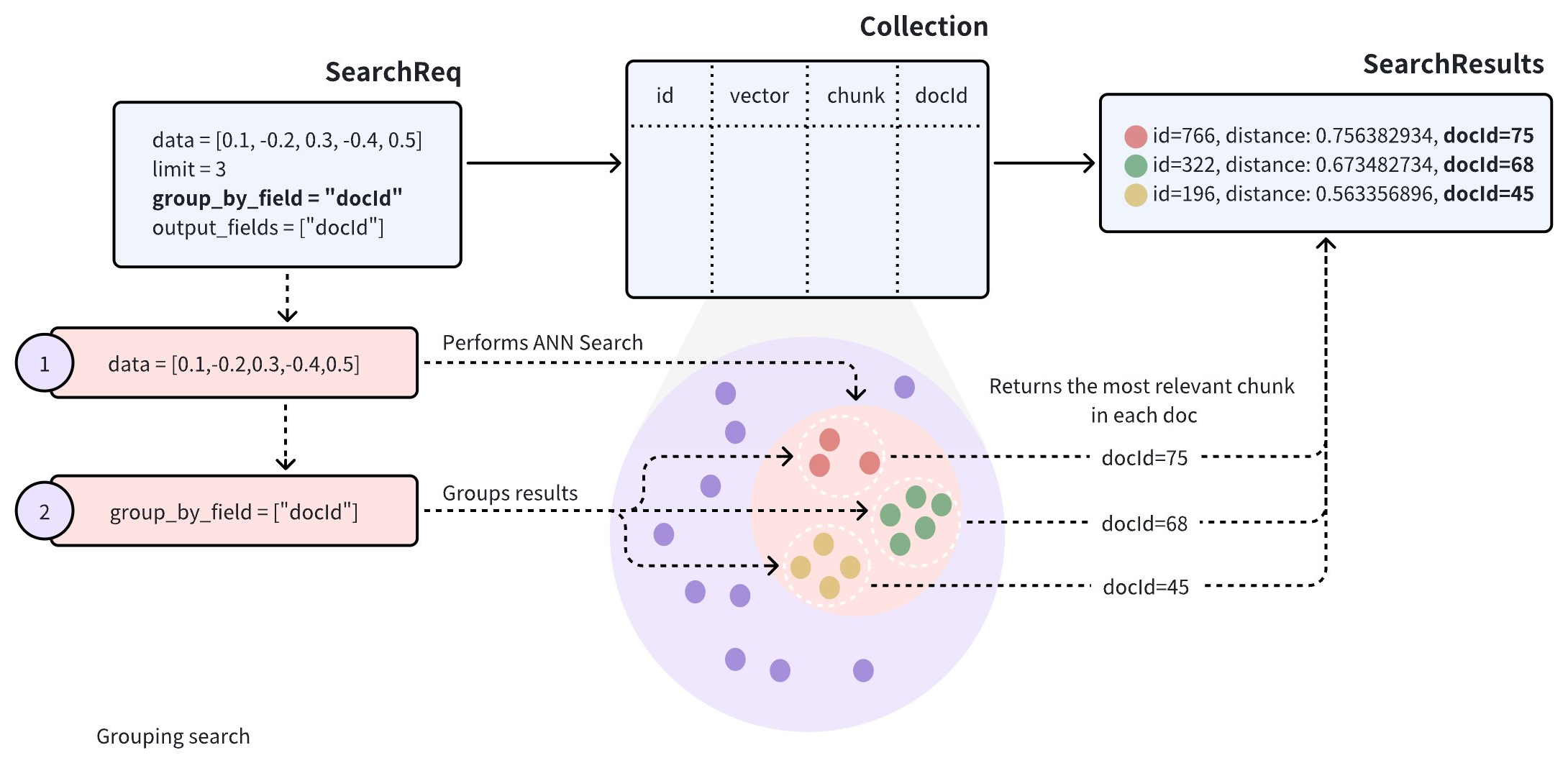
検索結果の多様性を向上させるために、検索リクエストに group_by_field パラメータを追加してグループ化検索を有効にすることができます。図に示すように、group_by_field を docId に設定できます。このリクエストを受信すると、Zilliz Cloud は以下を実行します。
-
提供されたクエリベクトルに基づいて ANN 検索を実行し、クエリに最も類似したすべてのエンティティを見つけます。
-
指定された
group_by_field(例:docId)で検索結果をグループ化します。 -
limitパラメータで定義された各グループの上位結果を、各グループから最も類似したエンティティとともに返します。
デフォルトでは、グループ化検索はグループあたり1つのエンティティのみを返します。グループあたりの返却結果数を増やしたい場合は、group_size および strict_group_size パラメータで制御できます。
グループ化検索の実行
このセクションでは、グループ化検索の使用例を示すコード例を提供します。以下の例では、コレクションに id、vector、chunk、および docId のフィールドが含まれていることを前提としています。
[
{"id": 0, "vector": [0.3580376395471989, -0.6023495712049978, 0.18414012509913835, -0.26286205330961354, 0.9029438446296592], "chunk": "pink_8682", "docId": 1},
{"id": 1, "vector": [0.19886812562848388, 0.06023560599112088, 0.6976963061752597, 0.2614474506242501, 0.838729485096104], "chunk": "red_7025", "docId": 5},
{"id": 2, "vector": [0.43742130801983836, -0.5597502546264526, 0.6457887650909682, 0.7894058910881185, 0.20785793220625592], "chunk": "orange_6781", "docId": 2},
{"id": 3, "vector": [0.3172005263489739, 0.9719044792798428, -0.36981146090600725, -0.4860894583077995, 0.95791889146345], "chunk": "pink_9298", "docId": 3},
{"id": 4, "vector": [0.4452349528804562, -0.8757026943054742, 0.8220779437047674, 0.46406290649483184, 0.30337481143159106], "chunk": "red_4794", "docId": 3},
{"id": 5, "vector": [0.985825131989184, -0.8144651566660419, 0.6299267002202009, 0.1206906911183383, -0.1446277761879955], "chunk": "yellow_4222", "docId": 4},
{"id": 6, "vector": [0.8371977790571115, -0.015764369584852833, -0.31062937026679327, -0.562666951622192, -0.8984947637863987], "chunk": "red_9392", "docId": 1},
{"id": 7, "vector": [-0.33445148015177995, -0.2567135004164067, 0.8987539745369246, 0.9402995886420709, 0.5378064918413052], "chunk": "grey_8510", "docId": 2},
{"id": 8, "vector": [0.39524717779832685, 0.4000257286739164, -0.5890507376891594, -0.8650502298996872, -0.6140360785406336], "chunk": "white_9381", "docId": 5},
{"id": 9, "vector": [0.5718280481994695, 0.24070317428066512, -0.3737913482606834, -0.06726932177492717, -0.6980531615588608], "chunk": "purple_4976", "docId": 3},
]
検索リクエストでは、group_by_field と output_fields の両方を docId に設定します。Zilliz Cloud は指定されたフィールドで結果をグループ化し、各グループから最も類似度の高いエンティティを返します。返される各エンティティには docId の値が含まれます。
- Python
- Java
- Go
- NodeJS
- cURL
from pymilvus import MilvusClient
client = MilvusClient(
uri="YOUR_CLUSTER_ENDPOINT",
token="YOUR_CLUSTER_TOKEN"
)
query_vectors = [
[0.14529211512077012, 0.9147257273453546, 0.7965055218724449, 0.7009258593102812, 0.5605206522382088]]
# Group search results
res = client.search(
collection_name="my_collection",
data=query_vectors,
limit=3,
group_by_field="docId",
output_fields=["docId"]
)
# Retrieve the values in the \`docId\` column
doc_ids = [result['entity']['docId'] for result in res[0]]
import io.milvus.v2.client.ConnectConfig;
import io.milvus.v2.client.MilvusClientV2;
import io.milvus.v2.service.vector.request.SearchReq
import io.milvus.v2.service.vector.request.data.FloatVec;
import io.milvus.v2.service.vector.response.SearchResp
MilvusClientV2 client = new MilvusClientV2(ConnectConfig.builder()
.uri("YOUR_CLUSTER_ENDPOINT")
.token("YOUR_CLUSTER_TOKEN")
.build());
FloatVec queryVector = new FloatVec(new float[]{0.14529211512077012f, 0.9147257273453546f, 0.7965055218724449f, 0.7009258593102812f, 0.5605206522382088f});
SearchReq searchReq = SearchReq.builder()
.collectionName("my_collection")
.data(Collections.singletonList(queryVector))
.topK(3)
.groupByFieldName("docId")
.outputFields(Collections.singletonList("docId"))
.build();
SearchResp searchResp = client.search(searchReq);
List<List<SearchResp.SearchResult>> searchResults = searchResp.getSearchResults();
for (List<SearchResp.SearchResult> results : searchResults) {
System.out.println("TopK results:");
for (SearchResp.SearchResult result : results) {
System.out.println(result);
}
}
// Output
// TopK results:
// SearchResp.SearchResult(entity={docId=5}, score=0.74767184, id=1)
// SearchResp.SearchResult(entity={docId=2}, score=0.6254269, id=7)
// SearchResp.SearchResult(entity={docId=3}, score=0.3611898, id=3)
import (
"context"
"fmt"
"github.com/milvus-io/milvus/client/v2/entity"
"github.com/milvus-io/milvus/client/v2/milvusclient"
)
ctx, cancel := context.WithCancel(context.Background())
defer cancel()
milvusAddr := "YOUR_CLUSTER_ENDPOINT"
client, err := milvusclient.New(ctx, &milvusclient.ClientConfig{
Address: milvusAddr,
})
if err != nil {
fmt.Println(err.Error())
// handle error
}
defer client.Close(ctx)
queryVector := []float32{0.3580376395471989, -0.6023495712049978, 0.18414012509913835, -0.26286205330961354, 0.9029438446296592}
resultSets, err := client.Search(ctx, milvusclient.NewSearchOption(
"my_collection", // collectionName
3, // limit
[]entity.Vector{entity.FloatVector(queryVector)},
).WithANNSField("vector").
WithGroupByField("docId").
WithOutputFields("docId"))
if err != nil {
fmt.Println(err.Error())
// handle error
}
for _, resultSet := range resultSets {
fmt.Println("IDs: ", resultSet.IDs.FieldData().GetScalars())
fmt.Println("Scores: ", resultSet.Scores)
fmt.Println("docId: ", resultSet.GetColumn("docId").FieldData().GetScalars())
}
import { MilvusClient, DataType } from "@zilliz/milvus2-sdk-node";
const address = "YOUR_CLUSTER_ENDPOINT";
const token = "YOUR_CLUSTER_TOKEN";
const client = new MilvusClient({address, token});
var query_vector = [0.3580376395471989, -0.6023495712049978, 0.18414012509913835, -0.26286205330961354, 0.9029438446296592]
res = await client.search({
collection_name: "my_collection",
data: [query_vector],
limit: 3,
group_by_field: "docId"
})
// Retrieve the values in the \`docId\` column
var docIds = res.results.map(result => result.entity.docId)
export CLUSTER_ENDPOINT="YOUR_CLUSTER_ENDPOINT"
export TOKEN="YOUR_CLUSTER_TOKEN"
curl --request POST \
--url "${CLUSTER_ENDPOINT}/v2/vectordb/entities/search" \
--header "Authorization: Bearer ${TOKEN}" \
--header "Content-Type: application/json" \
-d '{
"collectionName": "my_collection",
"data": [
[0.3580376395471989, -0.6023495712049978, 0.18414012509913835, -0.26286205330961354, 0.9029438446296592]
],
"annsField": "vector",
"limit": 3,
"groupingField": "docId",
"outputFields": ["docId"]
}'
上記のリクエストにおいて、limit=3 はシステムが3つのグループから検索結果を返すことを示しており、各グループにはクエリベクトルに対して最も類似度の高い単一のエンティティが含まれます。
グループサイズの設定
デフォルトでは、Grouping Search は各グループにつき1つのエンティティのみを返します。グループごとに複数の結果を取得したい場合は、group_size パラメータおよび strict_group_size パラメータを調整してください。
- Python
- Java
- Go
- NodeJS
- cURL
# Group search results
res = client.search(
collection_name="my_collection",
data=query_vectors, # query vector
limit=5, # number of groups to return
group_by_field="docId", # grouping field
group_size=2, # p to 2 entities to return from each group
strict_group_size=True, # return exact 2 entities from each group
output_fields=["docId"]
)
FloatVec queryVector = new FloatVec(new float[]{0.14529211512077012f, 0.9147257273453546f, 0.7965055218724449f, 0.7009258593102812f, 0.5605206522382088f});
SearchReq searchReq = SearchReq.builder()
.collectionName("my_collection")
.data(Collections.singletonList(queryVector))
.topK(5)
.groupByFieldName("docId")
.groupSize(2)
.strictGroupSize(true)
.outputFields(Collections.singletonList("docId"))
.build();
SearchResp searchResp = client.search(searchReq);
List<List<SearchResp.SearchResult>> searchResults = searchResp.getSearchResults();
for (List<SearchResp.SearchResult> results : searchResults) {
System.out.println("TopK results:");
for (SearchResp.SearchResult result : results) {
System.out.println(result);
}
}
// Output
// TopK results:
// SearchResp.SearchResult(entity={docId=5}, score=0.74767184, id=1)
// SearchResp.SearchResult(entity={docId=5}, score=-0.49148706, id=8)
// SearchResp.SearchResult(entity={docId=2}, score=0.6254269, id=7)
// SearchResp.SearchResult(entity={docId=2}, score=0.38515577, id=2)
// SearchResp.SearchResult(entity={docId=3}, score=0.3611898, id=3)
// SearchResp.SearchResult(entity={docId=3}, score=0.19556211, id=4)
import (
"context"
"fmt"
"github.com/milvus-io/milvus/client/v2/entity"
"github.com/milvus-io/milvus/client/v2/milvusclient"
)
ctx, cancel := context.WithCancel(context.Background())
defer cancel()
milvusAddr := "YOUR_CLUSTER_ENDPOINT"
client, err := milvusclient.New(ctx, &milvusclient.ClientConfig{
Address: milvusAddr,
})
if err != nil {
fmt.Println(err.Error())
// handle error
}
defer client.Close(ctx)
queryVector := []float32{0.3580376395471989, -0.6023495712049978, 0.18414012509913835, -0.26286205330961354, 0.9029438446296592}
resultSets, err := client.Search(ctx, milvusclient.NewSearchOption(
"my_collection", // collectionName
5, // limit
[]entity.Vector{entity.FloatVector(queryVector)},
).WithANNSField("vector").
WithGroupByField("docId").
WithStrictGroupSize(true).
WithGroupSize(2).
WithOutputFields("docId"))
if err != nil {
fmt.Println(err.Error())
// handle error
}
for _, resultSet := range resultSets {
fmt.Println("IDs: ", resultSet.IDs.FieldData().GetScalars())
fmt.Println("Scores: ", resultSet.Scores)
fmt.Println("docId: ", resultSet.GetColumn("docId").FieldData().GetScalars())
}
import { MilvusClient, DataType } from "@zilliz/milvus2-sdk-node";
const address = "YOUR_CLUSTER_ENDPOINT";
const token = "YOUR_CLUSTER_TOKEN";
const client = new MilvusClient({address, token});
var query_vector = [0.3580376395471989, -0.6023495712049978, 0.18414012509913835, -0.26286205330961354, 0.9029438446296592]
res = await client.search({
collection_name: "my_collection",
data: [query_vector],
limit: 5,
group_by_field: "docId",
group_size: 2,
strict_group_size: true
})
// Retrieve the values in the \`docId\` column
var docIds = res.results.map(result => result.entity.docId)
curl --request POST \
--url "${CLUSTER_ENDPOINT}/v2/vectordb/entities/search" \
--header "Authorization: Bearer ${TOKEN}" \
--header "Content-Type: application/json" \
-d '{
"collectionName": "my_collection",
"data": [
[0.3580376395471989, -0.6023495712049978, 0.18414012509913835, -0.26286205330961354, 0.9029438446296592]
],
"annsField": "vector",
"limit": 5,
"groupingField": "docId",
"groupSize":2,
"strictGroupSize":true,
"outputFields": ["docId"]
}'
上記の例では:
-
group_size: グループあたり返すエンティティの希望数を指定します。例えば、group_size=2を設定すると、各グループ(または各docId)は理想的に最も類似した2つの段落(または チャンク)を返します。group_sizeが設定されていない場合、システムはデフォルトでグループあたり1つの結果を返します。 -
strict_group_size: このブール値パラメータは、システムがgroup_sizeで設定された数を厳密に適用するかどうかを制御します。strict_group_size=Trueの場合、システムは各グループにgroup_sizeで指定された正確な数のエンティティ(例: 2つの段落)を含めようとしますが、そのグループに十分なデータがない場合を除きます。デフォルト(strict_group_size=False)では、システムは各グループにgroup_sizeのエンティティが含まれることを保証するよりも、limitパラメータで指定されたグループ数を満たすことを優先します。このアプローチは、データの分布が不均一な場合に一般的に効率的です。
追加のパラメータの詳細については、search を参照してください。
Order groups by a scalar field
Grouping Search を order_by_fields と組み合わせて、グループをスカラーフィールドで並べ替えることができます。これは、グループ間で多様な結果を得たいが、グループが価格や評価などのビジネス関連の順序に従うようにしたい場合に便利です。
次の例では、検索結果を category でグループ化し、グループあたり最大3つのエンティティを返し、返されたグループを price の低い順から高い順に並べ替えます。
- Python
- Java
- NodeJS
- Go
- cURL
res = client.search(
collection_name="product_catalog",
data=query_vectors,
anns_field="embedding",
limit=20,
group_by_field="category",
group_size=3,
strict_group_size=True,
output_fields=["category", "price", "rating"],
order_by_fields=[
{"field": "price", "order": "asc"}
],
)
// java
// nodejs
// go
# restful
上記のリクエストでは、limit=20 は Zilliz Cloud が最大 20 グループを選択することを意味し、20 エンティティではありません。group_size=3 であるため、フラットな結果リストには合計最大 60 エンティティを含めることができます。
group_by_field とともに order_by_fields を使用する場合、Zilliz Cloud は各グループのトップエンティティの指定されたスカラーフィールド値でグループを並べ替えます。各グループ内では、エンティティはクエリベクトルとの類似度スコア順に並びます。
考慮事項
-
グループ数:
limitパラメータは、検索結果が返されるグループの数を制御し、各グループ内の特定のエンティティ数ではありません。適切なlimitを設定することで、検索の多様性とクエリパフォーマンスを制御できます。データが高密度に分布している場合やパフォーマンスが懸念される場合は、limitを減らすことで計算コストを削減できます。 -
グループあたりのエンティティ数:
group_sizeパラメータは、グループあたりに返されるエンティティの数を制御します。ユースケースに基づいてgroup_sizeを調整することで、検索結果の豊富さを高めることができます。ただし、データが不均一に分布している場合、特にデータが限られたシナリオでは、一部のグループがgroup_sizeで指定された数よりも少ないエンティティを返すことがあります。 -
厳密なグループサイズ:
strict_group_size=Trueの場合、システムはそのグループに十分なデータがない場合を除き、各グループに指定された数のエンティティ(group_size)を返そうとします。この設定により、グループあたりのエンティティ数が一貫することが保証されますが、データの分布が不均一であったりリソースが限られている場合、パフォーマンスが低下する可能性があります。厳密なエンティティ数が必要ない場合は、strict_group_size=Falseを設定することでクエリ速度を向上させることができます。 -
クエリベクトルが既にターゲットコレクションに存在する場合は、検索前に取得する代わりに
idsを使用することを検討してください。詳細については、プライマリキー検索 を参照してください。