マルチベクトルハイブリッド検索
多くのアプリケーションでは、オブジェクトはタイトルや説明文といった豊富な情報セット、またはテキスト、画像、音声などの複数のモダリティを使って検索できます。例えば、テキストと画像を含むツイートは、テキストまたは画像のいずれかが検索クエリのセマンティクスと一致する場合に検索されるべきです。ハイブリッド検索は、これらの多様なフィールドにわたる検索を組み合わせることで、検索体験を向上させます。Zilliz Cloud は、複数のベクトルフィールドでの検索を可能にし、複数の近似最近傍(ANN)検索を同時に実行することでこれをサポートします。マルチベクトルハイブリッド検索は、テキストと画像の両方を検索したい場合、同じオブジェクトを説明する複数のテキストフィールドを検索したい場合、または検索品質を向上させるために密ベクトルと疎ベクトルの両方を検索したい場合に特に有用です。
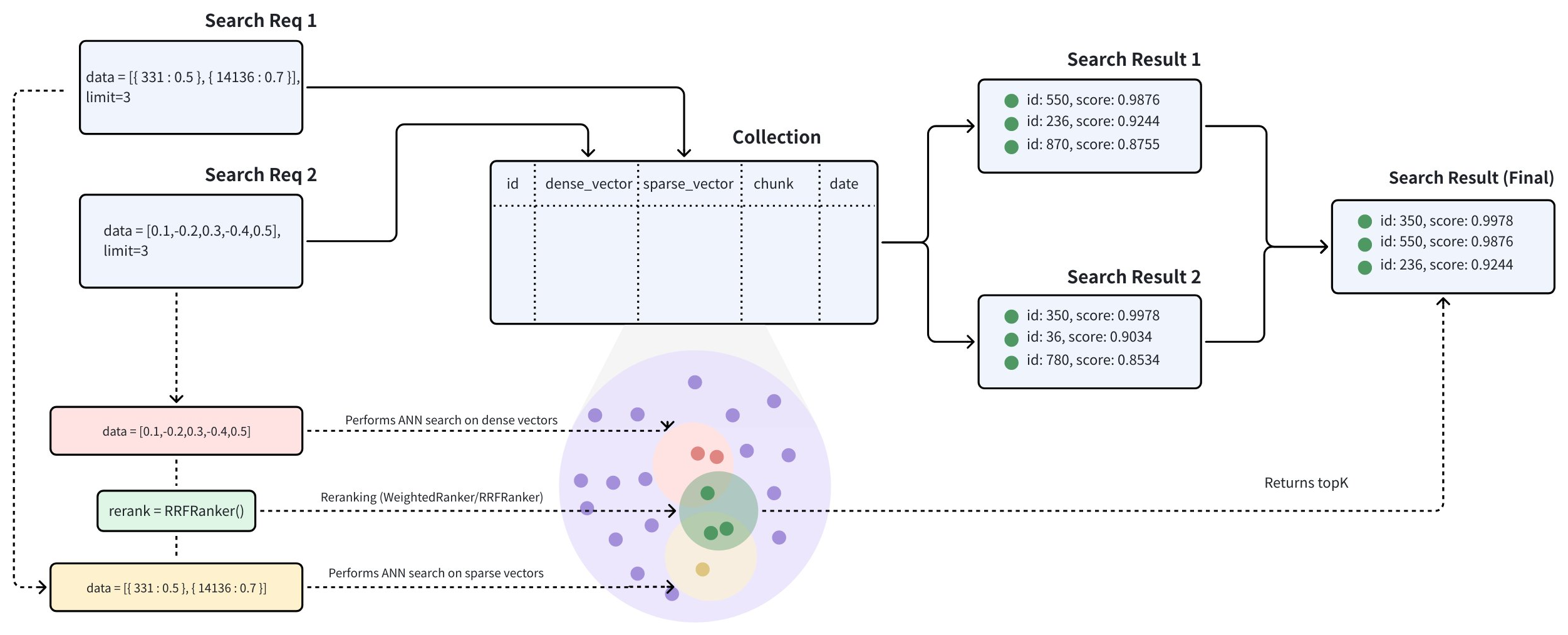
マルチベクトルハイブリッド検索は、異なる検索方法を統合したり、さまざまなモダリティからの埋め込みを横断したりします:
-
疎密ベクトル検索: 密ベクトル はセマンティックな関係性を捉えるのに優れており、疎ベクトル は正確なキーワードマッチングに非常に効果的です。ハイブリッド検索はこれらのアプローチを組み合わせることで、広範な概念的な理解と正確な用語の関連性の両方を提供し、検索結果を改善します。それぞれの方法の強みを活用することで、ハイブリッド検索は個別のアプローチの限界を克服し、複雑なクエリに対してより良いパフォーマンスを提供します。セマンティック検索と全文検索を組み合わせたハイブリッド検索の詳細なガイドはこちらです。
-
マルチモーダルベクトル検索: マルチモーダルベクトル検索は、テキスト、画像、音声などのさまざまなデータ型を横断して検索できる強力な手法です。このアプローチの主な利点は、異なるモダリティをシームレスで統一された検索体験に統合できることです。例えば、商品検索では、ユーザーがテキストクエリを入力して、テキストと画像の両方で説明された商品を見つけることがあります。ハイブリッド検索方法を通じてこれらのモダリティを組み合わせることで、検索精度を向上させたり、検索結果を充実させたりすることができます。
例
各商品にテキストの説明と画像が含まれる実世界のユースケースを考えてみましょう。利用可能なデータに基づいて、3種類の検索を実行できます:
-
セマンティックテキスト検索: これは、密ベクトルを使用して商品のテキスト説明をクエリすることを含みます。テキスト埋め込みは、BERT や Transformers などのモデル、または OpenAI などのサービスを使用して生成できます。
-
全文検索: ここでは、疎ベクトルを使用したキーワードマッチングで商品のテキスト説明をクエリします。BM25 などのアルゴリズムや、BGE-M3 や SPLADE などの疎埋め込みモデルをこの目的に利用できます。
-
マルチモーダル画像検索: この方法は、密ベクトルを使用したテキストクエリで画像を検索します。画像埋め込みは、CLIP などのモデルで生成できます。
このガイドでは、商品の生のテキスト説明と画像埋め込みが与えられた場合に、上記の検索方法を組み合わせたマルチモーダルハイブリッド検索の例を説明します。マルチベクトルデータの保存方法と、リランキング戦略を用いたハイブリッド検索の実行方法を示します。
複数のベクトルフィールドを持つコレクションの作成
コレクションの作成プロセスには、コレクションスキーマの定義、インデックスパラメータの設定、コレクションの作成という3つの重要なステップがあります。
スキーマの定義
マルチベクトルハイブリッド検索では、コレクションスキーマ内に複数のベクトルフィールドを定義する必要があります。コレクションで許可されるベクトルフィールドの数に関する制限の詳細については、Zilliz Cloud 制限s を参照してください。
この例では、スキーマに以下のフィールドを組み込みます:
-
id: テキストIDを保存するための主キーとして機能します。このフィールドのデータ型はINT64です。 -
text: テキストコンテンツを保存するために使用されます。このフィールドのデータ型はVARCHARで、最大長は1000バイトです。全文検索を可能にするために、enable_analyzerオプションがTrueに設定されています。 -
text_dense: テキストの密ベクトルを保存するために使用されます。このフィールドのデータ型はFLOAT_VECTORで、ベクトル次元は768です。 -
text_sparse: テキストの疎ベクトルを保存するために使用されます。このフィールドのデータ型はSPARSE_FLOAT_VECTORです。 -
image_dense: 商品画像の密ベクトルを保存するために使用されます。このフィールドのデータ型はFLOAT_VETORで、ベクトル次元は512です。
テキストフィールドで全文検索を実行するために組み込みのBM25アルゴリズムを使用するため、スキーマに Milvus の Function を追加する必要があります。詳細については、Full Text Search を参照してください。
- Python
- Java
- Go
- NodeJS
- cURL
from pymilvus import (
MilvusClient, DataType, Function, FunctionType
)
client = MilvusClient(
uri="YOUR_CLUSTER_ENDPOINT",
token="YOUR_CLUSTER_TOKEN"
)
# Init schema with auto_id disabled
schema = client.create_schema(auto_id=False)
# Add fields to schema
schema.add_field(field_name="id", datatype=DataType.INT64, is_primary=True, description="product id")
schema.add_field(field_name="text", datatype=DataType.VARCHAR, max_length=1000, enable_analyzer=True, description="raw text of product description")
schema.add_field(field_name="text_dense", datatype=DataType.FLOAT_VECTOR, dim=768, description="text dense embedding")
schema.add_field(field_name="text_sparse", datatype=DataType.SPARSE_FLOAT_VECTOR, description="text sparse embedding auto-generated by the built-in BM25 function")
schema.add_field(field_name="image_dense", datatype=DataType.FLOAT_VECTOR, dim=512, description="image dense embedding")
# Add function to schema
bm25_function = Function(
name="text_bm25_emb",
input_field_names=["text"],
output_field_names=["text_sparse"],
function_type=FunctionType.BM25,
)
schema.add_function(bm25_function)
import io.milvus.v2.client.ConnectConfig;
import io.milvus.v2.client.MilvusClientV2;
import io.milvus.v2.common.DataType;
import io.milvus.common.clientenum.FunctionType;
import io.milvus.v2.service.collection.request.AddFieldReq;
import io.milvus.v2.service.collection.request.CreateCollectionReq;
import io.milvus.v2.service.collection.request.CreateCollectionReq.Function;
import java.util.*;
MilvusClientV2 client = new MilvusClientV2(ConnectConfig.builder()
.uri("YOUR_CLUSTER_ENDPOINT")
.token("YOUR_CLUSTER_TOKEN")
.build());
CreateCollectionReq.CollectionSchema schema = client.createSchema();
schema.addField(AddFieldReq.builder()
.fieldName("id")
.dataType(DataType.Int64)
.isPrimaryKey(true)
.autoID(false)
.build());
schema.addField(AddFieldReq.builder()
.fieldName("text")
.dataType(DataType.VarChar)
.maxLength(1000)
.enableAnalyzer(true)
.build());
schema.addField(AddFieldReq.builder()
.fieldName("text_dense")
.dataType(DataType.FloatVector)
.dimension(768)
.build());
schema.addField(AddFieldReq.builder()
.fieldName("text_sparse")
.dataType(DataType.SparseFloatVector)
.build());
schema.addField(AddFieldReq.builder()
.fieldName("image_dense")
.dataType(DataType.FloatVector)
.dimension(512)
.build());
schema.addFunction(Function.builder()
.functionType(FunctionType.BM25)
.name("text_bm25_emb")
.inputFieldNames(Collections.singletonList("text"))
.outputFieldNames(Collections.singletonList("text_sparse"))
.build());
import (
"context"
"fmt"
"github.com/milvus-io/milvus/client/v2/column"
"github.com/milvus-io/milvus/client/v2/entity"
"github.com/milvus-io/milvus/client/v2/index"
"github.com/milvus-io/milvus/client/v2/milvusclient"
)
ctx, cancel := context.WithCancel(context.Background())
defer cancel()
milvusAddr := "YOUR_CLUSTER_ENDPOINT"
client, err := milvusclient.New(ctx, &milvusclient.ClientConfig{
Address: milvusAddr,
})
if err != nil {
fmt.Println(err.Error())
// handle error
}
defer client.Close(ctx)
function := entity.NewFunction().
WithName("text_bm25_emb").
WithInputFields("text").
WithOutputFields("text_sparse").
WithType(entity.FunctionTypeBM25)
schema := entity.NewSchema()
schema.WithField(entity.NewField().
WithName("id").
WithDataType(entity.FieldTypeInt64).
WithIsPrimaryKey(true),
).WithField(entity.NewField().
WithName("text").
WithDataType(entity.FieldTypeVarChar).
WithEnableAnalyzer(true).
WithMaxLength(1000),
).WithField(entity.NewField().
WithName("text_dense").
WithDataType(entity.FieldTypeFloatVector).
WithDim(768),
).WithField(entity.NewField().
WithName("text_sparse").
WithDataType(entity.FieldTypeSparseVector),
).WithField(entity.NewField().
WithName("image_dense").
WithDataType(entity.FieldTypeFloatVector).
WithDim(512),
).WithFunction(function)
import { MilvusClient, DataType } from "@zilliz/milvus2-sdk-node";
const address = "YOUR_CLUSTER_ENDPOINT";
const token = "YOUR_CLUSTER_TOKEN";
const client = new MilvusClient({address, token});
// Define fields
const fields = [
{
name: "id",
data_type: DataType.Int64,
is_primary_key: true,
auto_id: false
},
{
name: "text",
data_type: DataType.VarChar,
max_length: 1000,
enable_match: true
},
{
name: "text_dense",
data_type: DataType.FloatVector,
dim: 768
},
{
name: "text_sparse",
data_type: DataType.SPARSE_FLOAT_VECTOR
},
{
name: "image_dense",
data_type: DataType.FloatVector,
dim: 512
}
];
// define function
const functions = [
{
name: "text_bm25_emb",
description: "text bm25 function",
type: FunctionType.BM25,
input_field_names: ["text"],
output_field_names: ["text_sparse"],
params: {},
},
];
export bm25Function='{
"name": "text_bm25_emb",
"type": "BM25",
"inputFieldNames": ["text"],
"outputFieldNames": ["text_sparse"],
"params": {}
}'
export schema='{
"autoId": false,
"functions": [$bm25Function],
"fields": [
{
"fieldName": "id",
"dataType": "Int64",
"isPrimary": true
},
{
"fieldName": "text",
"dataType": "VarChar",
"elementTypeParams": {
"max_length": 1000,
"enable_analyzer": true
}
},
{
"fieldName": "text_dense",
"dataType": "FloatVector",
"elementTypeParams": {
"dim": "768"
}
},
{
"fieldName": "text_sparse",
"dataType": "SparseFloatVector"
},
{
"fieldName": "image_dense",
"dataType": "FloatVector",
"elementTypeParams": {
"dim": "512"
}
}
]
}'
インデックスの作成
コレクションスキーマを定義した後、次のステップはベクトルインデックスを設定し、類似性メトリックを指定することです。以下の例では:
-
text_dense_index: テキスト密ベクトルフィールドに対して、AUTOINDEXタイプでIPメトリックタイプのインデックスを作成しています。 -
text_sparse_index: テキスト疎ベクトルフィールドに対して、SPARSE_INVERTED_INDEXタイプでBM25メトリックタイプのインデックスを使用しています。 -
image_dense_index: 画像密ベクトルフィールドに対して、AUTOINDEXタイプでIPメトリックタイプのインデックスを作成しています。
- Python
- Java
- Go
- NodeJS
- cURL
# Prepare index parameters
index_params = client.prepare_index_params()
# Add indexes
index_params.add_index(
field_name="text_dense",
index_name="text_dense_index",
index_type="AUTOINDEX",
metric_type="IP"
)
index_params.add_index(
field_name="text_sparse",
index_name="text_sparse_index",
index_type="AUTOINDEX",
metric_type="BM25"
)
index_params.add_index(
field_name="image_dense",
index_name="image_dense_index",
index_type="AUTOINDEX",
metric_type="IP"
)
import io.milvus.v2.common.IndexParam;
import java.util.*;
Map<String, Object> denseParams = new HashMap<>();
IndexParam indexParamForTextDense = IndexParam.builder()
.fieldName("text_dense")
.indexName("text_dense_index")
.indexType(IndexParam.IndexType.AUTOINDEX)
.metricType(IndexParam.MetricType.IP)
.build();
Map<String, Object> sparseParams = new HashMap<>();
sparseParams.put("inverted_index_algo": "DAAT_MAXSCORE");
IndexParam indexParamForTextSparse = IndexParam.builder()
.fieldName("text_sparse")
.indexName("text_sparse_index")
.indexType(IndexParam.IndexType.SPARSE_INVERTED_INDEX)
.metricType(IndexParam.MetricType.BM25)
.extraParams(sparseParams)
.build();
IndexParam indexParamForImageDense = IndexParam.builder()
.fieldName("image_dense")
.indexName("image_dense_index")
.indexType(IndexParam.IndexType.AUTOINDEX)
.metricType(IndexParam.MetricType.IP)
.build();
List<IndexParam> indexParams = new ArrayList<>();
indexParams.add(indexParamForTextDense);
indexParams.add(indexParamForTextSparse);
indexParams.add(indexParamForImageDense);
indexOption1 := milvusclient.NewCreateIndexOption("my_collection", "text_dense",
index.NewAutoIndex(index.MetricType(entity.IP)))
indexOption2 := milvusclient.NewCreateIndexOption("my_collection", "text_sparse",
index.NewSparseInvertedIndex(entity.BM25, 0.2))
indexOption3 := milvusclient.NewCreateIndexOption("my_collection", "image_dense",
index.NewAutoIndex(index.MetricType(entity.IP)))
)
const index_params = [{
field_name: "text_dense",
index_name: "text_dense_index",
index_type: "AUTOINDEX",
metric_type: "IP"
},{
field_name: "text_sparse",
index_name: "text_sparse_index",
index_type: "IndexType.SPARSE_INVERTED_INDEX",
metric_type: "BM25",
params: {
inverted_index_algo: "DAAT_MAXSCORE",
}
},{
field_name: "image_dense",
index_name: "image_dense_index",
index_type: "AUTOINDEX",
metric_type: "IP"
}]
export indexParams='[
{
"fieldName": "text_dense",
"metricType": "IP",
"indexName": "text_dense_index",
"indexType":"AUTOINDEX"
},
{
"fieldName": "text_sparse",
"metricType": "BM25",
"indexName": "text_sparse_index",
"indexType": "SPARSE_INVERTED_INDEX",
"params":{"inverted_index_algo": "DAAT_MAXSCORE"}
},
{
"fieldName": "image_dense",
"metricType": "IP",
"indexName": "image_dense_index",
"indexType":"AUTOINDEX"
}
]'
コレクションの作成
前の2つの手順で設定したコレクションスキーマとインデックスを使用して、demo という名前のコレクションを作成します。
- Python
- Java
- Go
- NodeJS
- cURL
client.create_collection(
collection_name="my_collection",
schema=schema,
index_params=index_params
)
CreateCollectionReq createCollectionReq = CreateCollectionReq.builder()
.collectionName("my_collection")
.collectionSchema(schema)
.indexParams(indexParams)
.build();
client.createCollection(createCollectionReq);
err = client.CreateCollection(ctx,
milvusclient.NewCreateCollectionOption("my_collection", schema).
WithIndexOptions(indexOption1, indexOption2))
if err != nil {
fmt.Println(err.Error())
// handle error
}
res = await client.createCollection({
collection_name: "my_collection",
fields: fields,
index_params: index_params,
})
export CLUSTER_ENDPOINT="YOUR_CLUSTER_ENDPOINT"
export TOKEN="YOUR_CLUSTER_TOKEN"
curl --request POST \
--url "${CLUSTER_ENDPOINT}/v2/vectordb/collections/create" \
--header "Authorization: Bearer ${TOKEN}" \
--header "Content-Type: application/json" \
-d "{
\"collectionName\": \"my_collection\",
\"schema\": $schema,
\"indexParams\": $indexParams
}"
Insert data
このセクションでは、前述のスキーマに基づいてデータを my_collection コレクションに挿入します。挿入時には、自動生成される値を持つフィールドを除き、すべてのフィールドに正しい形式でデータを提供する必要があります。この例では、以下のようになります:
-
id: 商品IDを表す整数 -
text: 商品説明を含む文字列 -
text_dense: テキスト説明のdense embedding(密ベクトル)を表す768個の浮動小数点値のリスト -
image_dense: 商品画像のdense embeddingを表す512個の浮動小数点値のリスト
各フィールドのdense embeddingを生成するために、同じモデルまたは異なるモデルを使用できます。この例では、2つのdense embeddingが異なる次元を持っているため、異なるモデルによって生成されたことを示唆しています。後述の検索を定義する際には、対応するモデルを使用して適切なクエリembeddingを生成してください。
この例では、テキストフィールドからスパース埋め込み(疎ベクトル)を生成するために組み込みのBM25関数を使用しているため、疎ベクトルを手動で提供する必要はありません。ただし、BM25を使用しない場合は、事前にスパース埋め込みを計算し、自分で提供する必要があります。
- Python
- Java
- Go
- NodeJS
- cURL
import random
# Generate example vectors
def generate_dense_vector(dim):
return [random.random() for _ in range(dim)]
data=[
{
"id": 0,
"text": "Red cotton t-shirt with round neck",
"text_dense": generate_dense_vector(768),
"image_dense": generate_dense_vector(512)
},
{
"id": 1,
"text": "Wireless noise-cancelling over-ear headphones",
"text_dense": generate_dense_vector(768),
"image_dense": generate_dense_vector(512)
},
{
"id": 2,
"text": "Stainless steel water bottle, 500ml",
"text_dense": generate_dense_vector(768),
"image_dense": generate_dense_vector(512)
}
]
res = client.insert(
collection_name="my_collection",
data=data
)
import com.google.gson.Gson;
import com.google.gson.JsonObject;
import io.milvus.v2.service.vector.request.InsertReq;
Gson gson = new Gson();
JsonObject row1 = new JsonObject();
row1.addProperty("id", 0);
row1.addProperty("text", "Red cotton t-shirt with round neck");
row1.add("text_dense", gson.toJsonTree(text_dense1));
row1.add("image_dense", gson.toJsonTree(image_dense));
JsonObject row2 = new JsonObject();
row2.addProperty("id", 1);
row2.addProperty("text", "Wireless noise-cancelling over-ear headphones");
row2.add("text_dense", gson.toJsonTree(text_dense2));
row2.add("image_dense", gson.toJsonTree(image_dense2));
JsonObject row3 = new JsonObject();
row3.addProperty("id", 2);
row3.addProperty("text", "Stainless steel water bottle, 500ml");
row3.add("text_dense", gson.toJsonTree(dense3));
row3.add("image_dense", gson.toJsonTree(sparse3));
List<JsonObject> data = Arrays.asList(row1, row2, row3);
InsertReq insertReq = InsertReq.builder()
.collectionName("my_collection")
.data(data)
.build();
InsertResp insertResp = client.insert(insertReq);
_, err = client.Insert(ctx, milvusclient.NewColumnBasedInsertOption("my_collection").
WithInt64Column("id", []int64{0, 1, 2}).
WithVarcharColumn("text", []string{
"Red cotton t-shirt with round neck",
"Wireless noise-cancelling over-ear headphones",
"Stainless steel water bottle, 500ml",
}).
WithFloatVectorColumn("text_dense", 768, [][]float32{
{0.3580376395471989, -0.6023495712049978, 0.18414012509913835, ...},
{0.19886812562848388, 0.06023560599112088, 0.6976963061752597, ...},
{0.43742130801983836, -0.5597502546264526, 0.6457887650909682, ...},
}).
WithFloatVectorColumn("image_dense", 512, [][]float32{
{0.6366019600530924, -0.09323198122475052, ...},
{0.6414180010301553, 0.8976979978567611, ...},
{-0.6901259768402174, 0.6100500332193755, ...},
}).
if err != nil {
fmt.Println(err.Error())
// handle err
}
const { MilvusClient, DataType } = require("@zilliz/milvus2-sdk-node")
var data = [
{id: 0, text: "Red cotton t-shirt with round neck" , text_dense: [0.3580376395471989, -0.6023495712049978, 0.18414012509913835, ...], image_dense: [0.6366019600530924, -0.09323198122475052, ...]},
{id: 1, text: "Wireless noise-cancelling over-ear headphones" , text_dense: [0.19886812562848388, 0.06023560599112088, 0.6976963061752597, ...], image_dense: [0.6414180010301553, 0.8976979978567611, ...]},
{id: 2, text: "Stainless steel water bottle, 500ml" , text_dense: [0.43742130801983836, -0.5597502546264526, 0.6457887650909682, ...], image_dense: [-0.6901259768402174, 0.6100500332193755, ...]}
]
var res = await client.insert({
collection_name: "my_collection",
data: data,
})
curl --request POST \
--url "${CLUSTER_ENDPOINT}/v2/vectordb/entities/insert" \
--header "Authorization: Bearer ${TOKEN}" \
--header "Content-Type: application/json" \
-d '{
"data": [
{"id": 0, "text": "Red cotton t-shirt with round neck" , "text_dense": [0.3580376395471989, -0.6023495712049978, 0.18414012509913835, ...], "image_dense": [0.6366019600530924, -0.09323198122475052, ...]},
{"id": 1, "text": "Wireless noise-cancelling over-ear headphones" , "text_dense": [0.19886812562848388, 0.06023560599112088, 0.6976963061752597, ...], "image_dense": [0.6414180010301553, 0.8976979978567611, ...]},
{"id": 2, "text": "Stainless steel water bottle, 500ml" , "text_dense": [0.43742130801983836, -0.5597502546264526, 0.6457887650909682, ...], "image_dense": [-0.6901259768402174, 0.6100500332193755, ...]}
],
"collectionName": "my_collection"
}'
ハイブリッド検索を実行する
ステップ 1: 複数の AnnSearchRequest インスタンスを作成する
ハイブリッド検索は、hybrid_search() 関数内で複数の AnnSearchRequest を作成することで実装されます。各 AnnSearchRequest は、特定のベクトルフィールドに対する基本的な ANN 検索リクエストを表します。したがって、ハイブリッド検索を実行する前に、各ベクトルフィールドに対して AnnSearchRequest を作成する必要があります。
さらに、AnnSearchRequest の expr パラメータを設定することで、ハイブリッド検索のフィルタリング条件を設定できます。詳細については、フィルタリング検索 および フィルタリングの解説 を参照してください。
ハイブリッド検索では、各 AnnSearchRequest は1つのクエリデータのみをサポートします。
さまざまな検索ベクトルフィールドの機能を実証するために、サンプルクエリを使用して3つの AnnSearchRequest 検索リクエストを構築します。このプロセスでは、事前計算された密ベクトルも使用します。検索リクエストは、以下のベクトルフィールドを対象とします。
-
text_dense: セマンティックテキスト検索用で、直接的なキーワード一致ではなく、意味に基づいて文脈を理解し、検索できるようにします。 -
text_sparse: 全文検索またはキーワード一致用で、テキスト内の正確な単語またはフレーズの一致に焦点を当てます。 -
image_dense: マルチモーダルなテキストから画像への検索用で、クエリのセマンティックコンテンツに基づいて関連する商品画像を取得します。
- Python
- Java
- Go
- NodeJS
- cURL
from pymilvus import AnnSearchRequest
query_text = "white headphones, quiet and comfortable"
query_dense_vector = generate_dense_vector(768)
query_multimodal_vector = generate_dense_vector(512)
# text semantic search (dense)
search_param_1 = {
"data": [query_dense_vector],
"anns_field": "text_dense",
"limit": 2
}
request_1 = AnnSearchRequest(**search_param_1)
# full-text search (sparse)
search_param_2 = {
"data": [query_text],
"anns_field": "text_sparse",
"limit": 2
}
request_2 = AnnSearchRequest(**search_param_2)
# text-to-image search (multimodal)
search_param_3 = {
"data": [query_multimodal_vector],
"anns_field": "image_dense",
"limit": 2
}
request_3 = AnnSearchRequest(**search_param_3)
reqs = [request_1, request_2, request_3]
import io.milvus.v2.service.vector.request.AnnSearchReq;
import io.milvus.v2.service.vector.request.data.BaseVector;
import io.milvus.v2.service.vector.request.data.FloatVec;
import io.milvus.v2.service.vector.request.data.SparseFloatVec;
import io.milvus.v2.service.vector.request.data.EmbeddedText;
float[] queryDense = new float[]{-0.0475336798f, 0.0521207601f, 0.0904406682f, ...};
float[] queryMultimodal = new float[]{0.0158298651f, 0.5264158340f, ...}
List<BaseVector> queryTexts = Collections.singletonList(new EmbeddedText("white headphones, quiet and comfortable");)
List<BaseVector> queryDenseVectors = Collections.singletonList(new FloatVec(queryDense));
List<BaseVector> queryMultimodalVectors = Collections.singletonList(new FloatVec(queryMultimodal));
List<AnnSearchReq> searchRequests = new ArrayList<>();
searchRequests.add(AnnSearchReq.builder()
.vectorFieldName("text_dense")
.vectors(queryDenseVectors)
.topK(2)
.build());
searchRequests.add(AnnSearchReq.builder()
.vectorFieldName("text_sparse")
.vectors(queryTexts)
.topK(2)
.build());
searchRequests.add(AnnSearchReq.builder()
.vectorFieldName("image_dense")
.vectors(queryMultimodalVectors)
.topK(2)
.build());
queryText := entity.Text({"white headphones, quiet and comfortable"})
queryVector := []float32{0.3580376395471989, -0.6023495712049978, 0.18414012509913835, ...}
queryMultimodalVector := []float32{0.015829865178701663, 0.5264158340734488, ...}
request1 := milvusclient.NewAnnRequest("text_dense", 2, entity.FloatVector(queryVector)).
WithAnnParam(index.NewIvfAnnParam(10))
annParam := index.NewSparseAnnParam()
annParam.WithDropRatio(0.2)
request2 := milvusclient.NewAnnRequest("text_sparse", 2, queryText).
WithAnnParam(annParam)
request3 := milvusclient.NewAnnRequest("image_dense", 2, entity.FloatVector(queryMultimodalVector)).
WithAnnParam(index.NewIvfAnnParam(10))
const query_text = "white headphones, quiet and comfortable"
const query_vector = [0.3580376395471989, -0.6023495712049978, 0.18414012509913835, ...]
const query_multimodal_vector = [0.015829865178701663, 0.5264158340734488, ...]
const search_param_1 = {
"data": query_vector,
"anns_field": "text_dense",
"limit": 2
}
const search_param_2 = {
"data": query_text,
"anns_field": "text_sparse",
"limit": 2
}
const search_param_3 = {
"data": query_multimodal_vector,
"anns_field": "image_dense",
"limit": 2
}
export req='[
{
"data": [[0.3580376395471989, -0.6023495712049978, 0.18414012509913835, ...]],
"annsField": "text_dense",
"limit": 2
},
{
"data": ["white headphones, quiet and comfortable"],
"annsField": "text_sparse",
"limit": 2
},
{
"data": [[0.015829865178701663, 0.5264158340734488, ...]],
"annsField": "image_dense",
"limit": 2
}
]'
パラメータ limit が 2 に設定されているため、各 AnnSearchRequest は 2 件の検索結果を返します。この例では、3 つの AnnSearchRequest インスタンスが作成され、合計 6 件の検索結果が得られます。
Step 2: リランキング戦略の設定
ANN 検索結果のセットをマージしてリランキングするには、適切なリランキング戦略を選択することが不可欠です。Zilliz Cloud では、いくつかのタイプのリランキング戦略を提供しています。これらのリランキングメカニズムの詳細については、Weighted Ranker または RRF Ranker を参照してください。
この例では、特定の検索クエリを特に重視する必要がないため、RRFRanker 戦略を使用して進めます。
- Python
- Java
- NodeJS
- Go
- cURL
ranker = Function(
name="rrf",
input_field_names=[], # Must be an empty list
function_type=FunctionType.RERANK,
params={
"reranker": "rrf",
"k": 100 # Optional
}
)
import io.milvus.common.clientenum.FunctionType;
import io.milvus.v2.service.collection.request.CreateCollectionReq.Function;
Function ranker = Function.builder()
.name("rrf")
.functionType(FunctionType.RERANK)
.param("reranker", "rrf")
.param("k", "100")
.build()
const ranker = {
name: 'rrf',
description: 'bm25 function',
type: FunctionType.RERANK,
input_field_names: [],
params: {
"reranker": "rrf",
"k": 100
},
};
import (
"github.com/milvus-io/milvus/client/v2/entity"
)
ranker := entity.NewFunction().
WithName("rrf").
WithType(entity.FunctionTypeRerank).
WithParam("reranker", "rrf").
WithParam("k", "100")
# Restful
export ranker='{
"functions": [
{
"name": "rrf",
"type": "Rerank",
"inputFieldNames": [],
"params": {
"reranker": "rrf",
"k": 100
}
}
]
}'
ステップ 3: ハイブリッド検索を実行する
ハイブリッド検索を開始する前に、コレクションがロードされていることを確認してください。コレクション内のベクトルフィールドにインデックスが設定されていない場合や、メモリにロードされていない場合は、ハイブリッド検索メソッドの実行時にエラーが発生します。
- Python
- Java
- Go
- NodeJS
- cURL
res = client.hybrid_search(
collection_name="my_collection",
reqs=reqs,
ranker=ranker,
limit=2
)
for hits in res:
print("TopK results:")
for hit in hits:
print(hit)
import io.milvus.v2.common.ConsistencyLevel;
import io.milvus.v2.service.vector.request.HybridSearchReq;
import io.milvus.v2.service.vector.response.SearchResp;
HybridSearchReq hybridSearchReq = HybridSearchReq.builder()
.collectionName("my_collection")
.searchRequests(searchRequests)
.ranker(ranker)
.topK(2)
.build();
SearchResp searchResp = client.hybridSearch(hybridSearchReq);
resultSets, err := client.HybridSearch(ctx, milvusclient.NewHybridSearchOption(
"my_collection",
2,
request1,
request2,
request3,
).WithReranker(ranker))
if err != nil {
fmt.Println(err.Error())
// handle error
}
for _, resultSet := range resultSets {
fmt.Println("IDs: ", resultSet.IDs.FieldData().GetScalars())
fmt.Println("Scores: ", resultSet.Scores)
}
const { MilvusClient, DataType } = require("@zilliz/milvus2-sdk-node")
res = await client.loadCollection({
collection_name: "my_collection"
})
import { MilvusClient, RRFRanker, WeightedRanker } from '@zilliz/milvus2-sdk-node';
const search = await client.search({
collection_name: "my_collection",
data: [search_param_1, search_param_2, search_param_3],
limit: 2,
rerank: ranker
});
curl --request POST \
--url "${CLUSTER_ENDPOINT}/v2/vectordb/entities/hybrid_search" \
--header "Authorization: Bearer ${TOKEN}" \
--header "Content-Type: application/json" \
-d "{
\"collectionName\": \"my_collection\",
\"search\": ${req},
\"rerank\": {
\"strategy\":\"rrf\",
\"params\": ${ranker}
},
\"limit\": 2
}"
以下が出力です:
["['id: 1, distance: 0.006047376897186041, entity: {}', 'id: 2, distance: 0.006422005593776703, entity: {}']"]
ハイブリッド検索に limit=2 パラメータを指定すると、Zilliz Cloud は3つの検索から得られた6件の結果を再ランキングし、最終的に類似度が最も高い上位2件のみを返します。