INVERTED
データに対して頻繁にフィルタクエリを実行する必要がある場合、INVERTED インデックスを使用することでクエリのパフォーマンスを劇的に向上させることができます。すべてのドキュメントをスキャンするのではなく、Zilliz Cloud は 転置インデックス を使用して、フィルタ条件に一致する正確なレコードを迅速に特定します。
INVERTED インデックスを使用するタイミング
以下の場合に INVERTED インデックスを使用してください:
-
特定の値でフィルタリング: フィールドが特定の値に等しいすべてのレコードを検索する(例:
category == "electronics") -
テキストコンテンツのフィルタリング:
VARCHARフィールドに対して効率的な検索を実行する -
JSON フィールド値のクエリ: JSON 構造内の特定のキーでフィルタリングする
パフォーマンス上の利点: 転置インデックス は、フルコレクションスキャンの必要性を排除することで、大規模データセットにおけるクエリ時間を秒単位からミリ秒単位に短縮できます。
INVERTED インデックスの仕組み
Zilliz Cloud の INVERTED index は、各一意のフィールド値(用語)を、その値が出現するドキュメント ID のセットにマッピングします。この構造により、繰り返される値やカテゴリ値を持つフィールドに対して高速なルックアップが可能になります。
図に示されているように、このプロセスは2つのステップで動作します:
-
順マッピング(ID → 用語): 各ドキュメント ID は、それが含むフィールド値を指します。
-
逆マッピング(用語 → IDs): Zilliz Cloud は一意の用語を収集し、各用語からそれを含むすべての ID への逆マッピングを構築します。
例えば、値 "electronics" は ID 1 と 3 にマッピングされ、"books" は ID 2 と 5 にマッピングされます。
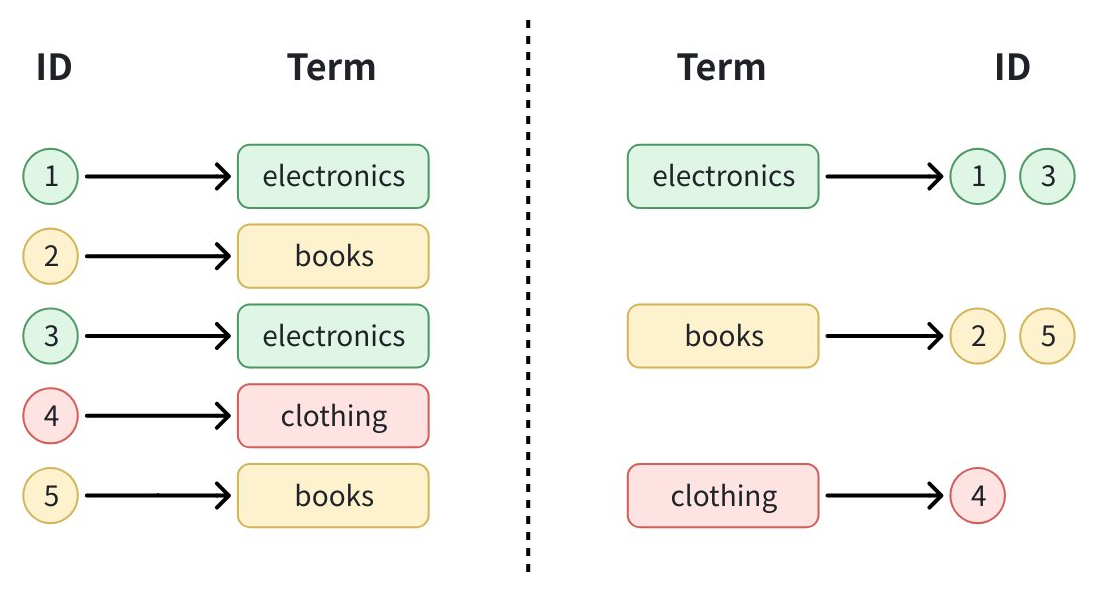
特定の値でフィルタリングする場合(例:category == "electronics")、Zilliz Cloud は単にインデックス内の用語をルックアップし、一致する ID を直接取得します。これにより、フルデータセットのスキャンが回避され、特にカテゴリ値や繰り返される値に対して高速なフィルタリングが可能になります。
INVERTED インデックスは、BOOL、INT8、INT16、INT32、INT64、FLOAT、DOUBLE、VARCHAR、JSON、ARRAY など、すべてのスカラーフィールド タイプをサポートしています。ただし、JSON フィールドのインデックス作成におけるインデックスパラメータは、通常の スカラーフィールド とは若干異なります。
非 JSON フィールドにインデックスを作成する
非 JSON フィールドにインデックスを作成するには、以下の手順に従います:
-
インデックスパラメータを準備します:
from pymilvus import MilvusClientclient = MilvusClient(uri="YOUR_CLUSTER_ENDPOINT") # Replace with your server address# Create an empty index parameter objectindex_params = client.prepare_index_params() -
INVERTEDインデックスを追加します:index_params.add_index(field_name="category", # Name of the field to indexindex_type="INVERTED", # Specify INVERTED index typeindex_name="category_index" # Give your index a name) -
インデックスを作成します:
client.create_index(collection_name="my_collection", # Replace with your collection nameindex_params=index_params)
JSON フィールドにインデックスを作成する
JSON フィールド内の特定のパスに対して INVERTED インデックスを作成することもできます。これには、JSON パスとデータ型を指定するための追加パラメータが必要です:
# Build index params
index_params.add_index(
field_name="metadata", # JSON field name
index_type="INVERTED",
index_name="metadata_category_index",
params={
"json_path": "metadata[\"category\"]", # Path to the JSON key
"json_cast_type": "varchar" # Data type to cast to during indexing
}
)
# Create index
client.create_index(
collection_name="my_collection", # Replace with your collection name
index_params=index_params
)
JSON フィールドのインデックス作成に関する詳細情報(サポートされているパス、データ型、制限事項など)については、JSON インデックス作成 を参照してください。
インデックスを削除する
drop_index() メソッドを使用して、コレクションから既存のインデックスを削除します。
Milvus v2.6.x 互換のクラスタでは、不要になったスカラーインデックスを直接削除できます。事前にコレクションをリリースする必要はありません。
client.drop_index(
collection_name="my_collection", # Name of the collection
index_name="category_index" # Name of the index to drop
)
ベストプラクティス
-
データの読み込み後にインデックスを作成する: データが既に含まれているコレクションでインデックスの構築を行うと、パフォーマンスが向上します
-
説明的なインデックス名を使用する: フィールドと目的が明確に示される名前を選択してください
-
インデックスのパフォーマンスを監視する: インデックス作成前後のクエリパフォーマンスを確認してください
-
クエリパターンを考慮する: 頻繁にフィルタリングするフィールドにインデックスを作成してください
次のステップ
-
AUTOINDEX について学習してください。
-
高度な JSONインデックス のシナリオについては、JSONインデックス を参照してください。