JSONシュレッディング
JSONシュレッディングは、従来の行指向ストレージを最適化されたカラム指向ストレージに変換することで、JSONクエリを高速化します。データモデリングにおけるJSONの柔軟性を維持しつつ、Zilliz Cloudはバックグラウンドでカラム指向の最適化を実行し、アクセスおよびクエリ効率を劇的に向上させます。
JSONシュレッディングは、ほとんどのJSONクエリシナリオで効果を発揮します。そのパフォーマンス上のメリットは、以下のケースで特に顕著になります。
-
大規模で複雑なJSONドキュメント - ドキュメントサイズが大きくなるほど、パフォーマンス向上の効果が高まります
-
読み込み集中型ワークロード - JSONキーに対するフィルタリング、ソート、検索が頻繁に行われる場合
-
混合クエリパターン - 異なるJSONキーに対するクエリにおいて、ハイブリッドストレージ方式が有効です
仕組み
JSONシュレッディング処理は、高速なデータ取得のために3つの明確なフェーズで行われます。
フェーズ1: インジェスチョンとキー分類
新しいJSONドキュメントが書き込まれる際、Zilliz Cloudは継続的にサンプリングおよび分析を行い、各JSONキーの統計情報を構築します。この分析には、キーの出現率および型安定性(ドキュメント間でデータ型が一貫しているかどうか)が含まれます。
これらの統計情報に基づき、JSONキーは最適なストレージのために以下のように分類されます。
JSONキーのカテゴリ
キー Type | Description |
|---|---|
型付きキー | キーs that exist in most documents and always have the same data type (e.g., all integers or all strings). |
動的キー | キーs that appear frequently but have a mixed data type (e.g., sometimes a string, sometimes an integer). |
共有キー | Infrequently appearing or nested keys that fall below a configurable frequency threshold. |
分類の例
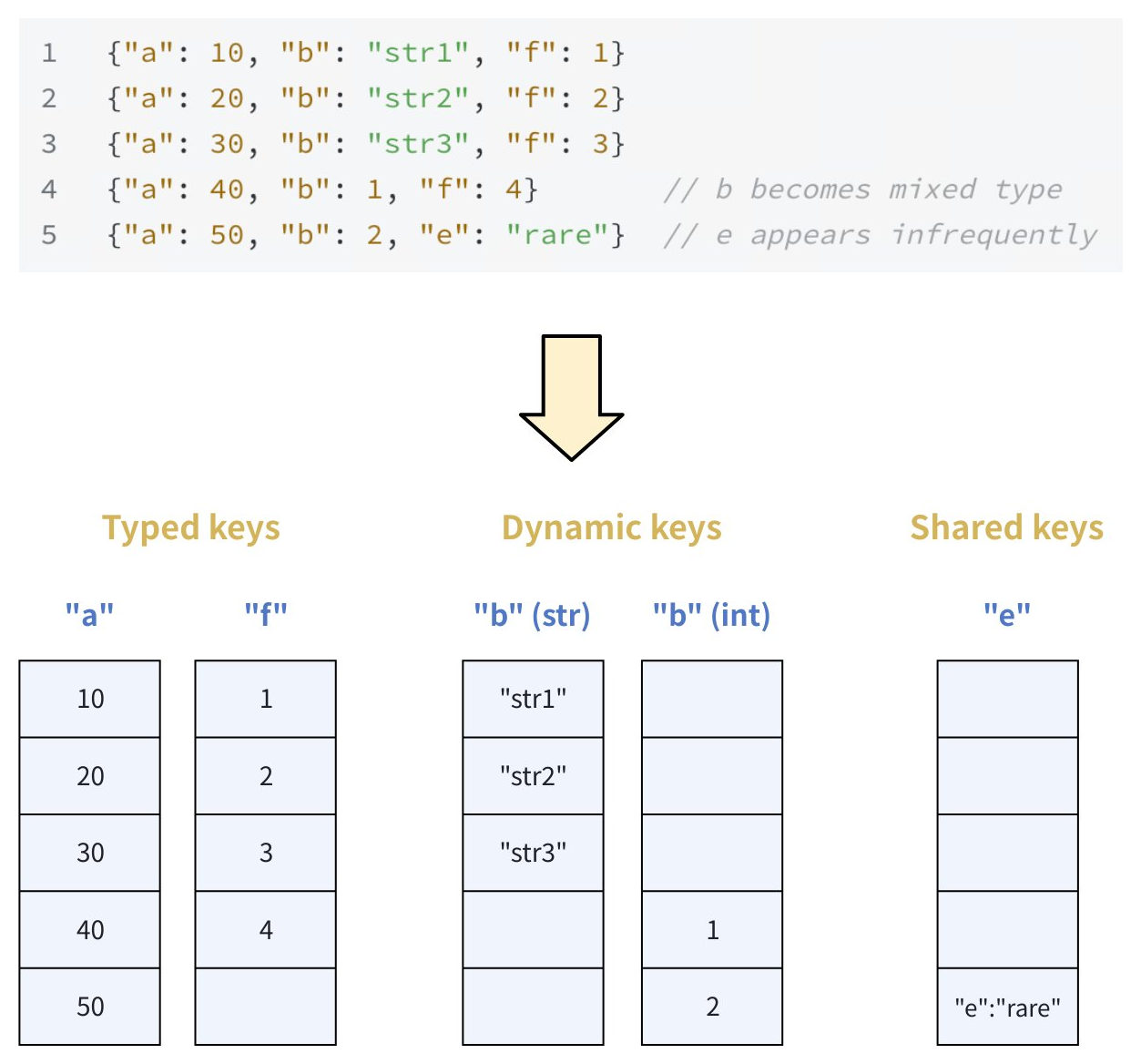
以下のJSONキーを含むサンプルJSONデータを考えてみましょう。
{"a": 10, "b": "str1", "f": 1}
{"a": 20, "b": "str2", "f": 2}
{"a": 30, "b": "str3", "f": 3}
{"a": 40, "b": 1, "f": 4} // b becomes mixed type
{"a": 50, "b": 2, "e": "rare"} // e appears infrequently
このデータに基づき、キーは次のように分類されます。
-
型付きキー:
aおよびf(常に整数) -
動的キー:
b(文字列と整数が混在) -
共有キー:
e(出現頻度が低いキー)
Phase 2: Storage optimization
Phase 1 で行われた分類結果に基づき、ストレージレイアウトが決定されます。Zilliz Cloud はクエリに最適化されたカラム形式を採用しています。
-
シャーデッドカラム: typed および dynamic keys については、専用のカラムにデータが書き込まれます。このカラム型ストレージにより、クエリ実行時に Zilliz Cloud がドキュメント全体を処理することなく、対象キーに必要なデータのみを直接スキャンできるため、高速な処理が可能になります。
-
共有カラム: すべての 共有キー は、単一のコンパクトなバイナリ JSON カラムにまとめて格納されます。このカラム上には共有キー用の 転置インデックス(転置インデックス)が構築されます。このインデックスは、低頻度キーに対するクエリを高速化するために不可欠であり、Zilliz Cloud が該当キーを含む行のみに検索範囲を絞り込むことを可能にします。
Phase 3: Query execution
最終フェーズでは、最適化されたストレージレイアウトを活用し、各クエリ述語に対して最速のパスを自動的に選択します。
-
高速パス: typed/dynamic キーに対するクエリ(例:
json['a'] < 100)は、専用カラムに直接アクセスします。 -
最適化されたパス: shared キーに対するクエリ(例:
json['e'] = 'rare')は、転置インデックスを利用して関連ドキュメントを迅速に特定します。
パフォーマンス benchmarks
テスト結果から、さまざまな JSON キータイプおよびクエリパターンにおいて、著しいパフォーマンス向上が確認されました。
Test environment and methodology
-
ハードウェア: 1 コア / 8GB クラスタ
-
データセット: JSONBench から取得した 100 万件のドキュメント
-
平均ドキュメントサイズ: 478.89 バイト
-
テスト期間: QPS およびレイテンシを 100 秒間計測
結果: typed keys
このテストでは、ほとんどのドキュメントに存在するキーに対するクエリ性能を評価しました。
Query Expression | キー Value Type | QPS (without shredding) | QPS (with shredding) | パフォーマンス Boost |
|---|---|---|---|---|
| Integer | 8.69 | 287.50 | 33x |
| String | 8.42 | 126.1 | 14.9x |
結果: 共有キー
このテストでは、「shared」カテゴリに該当する疎でネストされたキーに対するクエリ性能に焦点を当てました。
Query Expression | キー Value Type | QPS (without shredding) | QPS (with shredding) | パフォーマンス Boost |
|---|---|---|---|---|
| Nested Integer | 4.33 | 385 | 88.9x |
| Nested String | 7.6 | 352 | 46.3x |
キー insights
-
共有キー検索 は最大で 89 倍の劇的な改善を示しました。
-
型付きキー検索 は一貫して 15〜30 倍のパフォーマンス向上を達成しました。
-
すべてのクエリタイプ は JSON Shredding の恩恵を受け、パフォーマンスの低下は一切見られませんでした。
FAQ
-
JSONシュレッディング と JSONインデックス のどちらを選べばよいですか?
-
JSONシュレッディング は、ドキュメント内に頻繁に出現するキー、特に複雑な JSON 構造に最適です。カラム型ストレージと転置インデックスの利点を組み合わせており、多くの異なるキーをクエリするような読み取り重視のシナリオに適しています。ただし、非常に小さい JSON ドキュメントには推奨されません。なぜなら、その場合のパフォーマンス向上はわずかだからです。キーの値が JSON ドキュメント全体に占める割合が小さいほど、シュレッディングによるパフォーマンス最適化の効果が高くなります。
-
JSONインデックス は、特定のキーに基づくクエリをターゲットに最適化する場合に適しており、ストレージオーバーヘッドも低めです。シンプルな JSON 構造に向いています。なお、JSONシュレッディング は配列内のキーに対するクエリには対応していないため、それらを高速化するには JSON インデックスが必要です。
詳細については、JSON Field Overview を参照してください。
-