多言語アナライザー
Zilliz Cloud がテキスト分析を実行する際、通常はコレクション内のテキストフィールド全体に単一のアナライザーを適用します。そのアナライザーが英語に最適化されている場合、中国語、スペイン語、フランス語などの他の言語で必要とされる全く異なるトークン化やステミングのルールに対応できず、再現率が低下します。たとえば、スペイン語の単語 "teléfono"(*「電話」*の意味)を検索する場合、英語中心のアナライザーは対応に苦労します:アクセント記号を削除し、スペイン語特有のステミングを適用しないため、関連する結果が見落とされる可能性があります。
多言語アナライザーは、この問題を解決するために、単一のコレクション内のテキストフィールドに複数のアナライザーを設定できるようにします。これにより、テキストフィールドに多言語ドキュメントを保存でき、Zilliz Cloud は各ドキュメントに適した言語ルールに従ってテキストを分析します。
制限
-
この機能は、BM25 ベースのテキスト検索および疎ベクトルでのみ動作します。詳細については、全文検索 を参照してください。
-
単一のコレクション内の各ドキュメントは、言語識別子フィールドの値によって決定される 1 つのアナライザーのみを使用できます。
-
パフォーマンスは、アナライザーの複雑さとテキストデータのサイズによって異なる場合があります。
概要
次の図は、Zilliz Cloud で多言語アナライザーを設定および使用するワークフローを示しています:
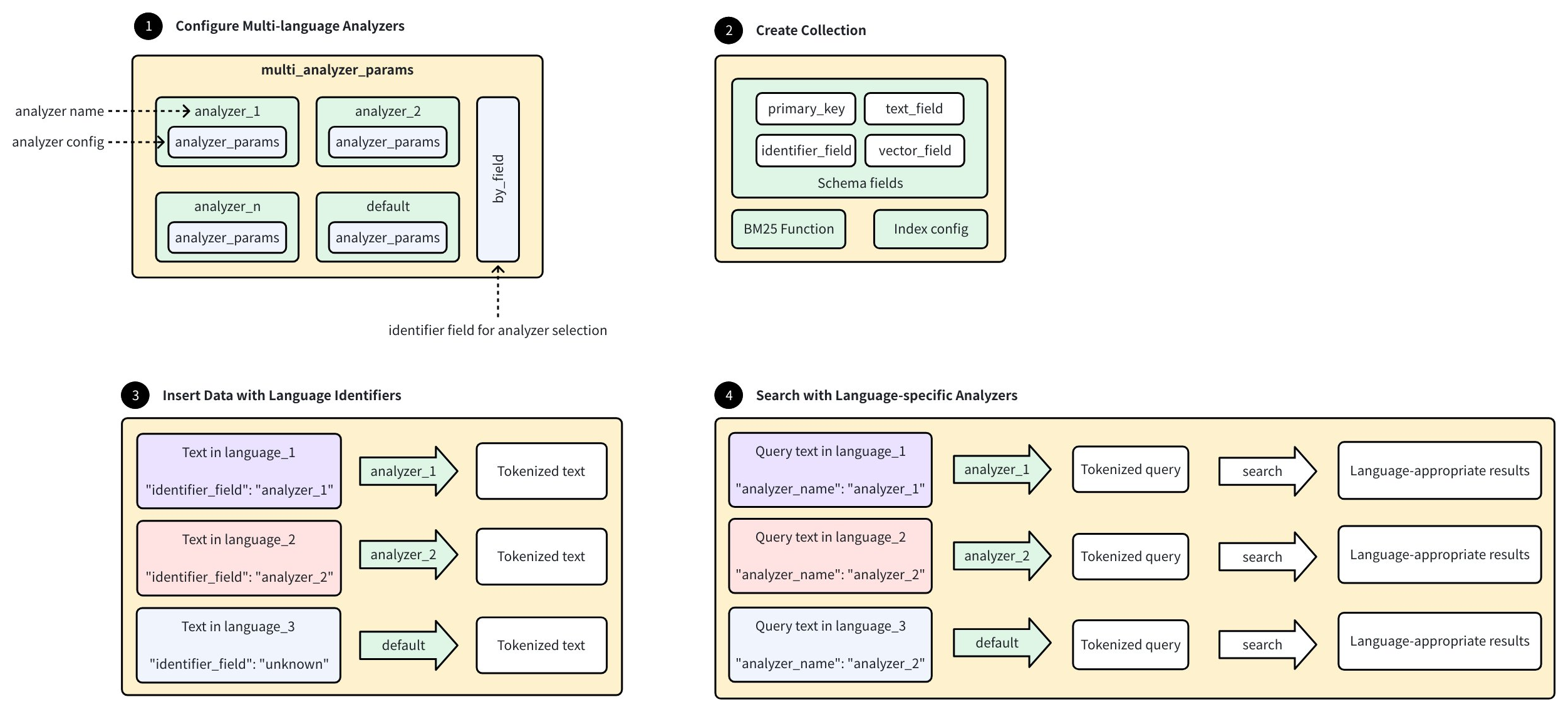
-
多言語アナライザーの設定:
-
<analyzer_name>: <analyzer_config>の形式を使用して、複数の言語固有のアナライザーを設定します。各analyzer_configは、アナライザー概要 で説明されている標準的なanalyzer_params設定に従います。 -
各ドキュメントのアナライザー選択を決定する特別な識別子フィールドを定義します。
-
不明な言語を処理するための
defaultアナライザーを設定します。
-
-
コレクションの作成:
-
必須フィールドを含むスキーマを定義します:
-
primary_key: 一意のドキュメント識別子。
-
text_field: 元のテキストコンテンツを保存します。
-
identifier_field: 各ドキュメントに使用するアナライザーを示します。
-
vector_field: BM25 関数によって生成されるスパース埋め込みを保存します。
-
-
BM25 関数とインデックスパラメーターを設定します。
-
-
言語識別子を含むデータの挿入:
-
各ドキュメントに使用するアナライザーを指定する識別子値を含む、さまざまな言語のテキストを含むドキュメントを追加します。
-
Zilliz Cloud は識別子フィールドに基づいて適切なアナライザーを選択し、不明な識別子を持つドキュメントは
defaultアナライザーを使用します。
-
-
言語固有のアナライザーでの検索:
-
アナライザー名を指定したクエリテキストを提供すると、Zilliz Cloud は指定されたアナライザーを使用してクエリを処理します。
-
トークン化は言語固有のルールに従って行われ、類似性に基づいて言語に適した結果を返します。
-
ステップ 1: multi_analyzer_params の設定
multi_analyzer_params は、Zilliz Cloud が各エンティティに適切なアナライザーを選択する方法を決定する単一の JSON オブジェクトです:
- Python
- Java
- NodeJS
- Go
- cURL
multi_analyzer_params = {
# Define language-specific analyzers
# Each analyzer follows this format: <analyzer_name>: <analyzer_params>
"analyzers": {
"english": {"type": "english"}, # English-optimized analyzer
"chinese": {"type": "chinese"}, # Chinese-optimized analyzer
"default": {"tokenizer": "icu"} # Required fallback analyzer
},
"by_field": "language", # Field determining analyzer selection
"alias": {
"cn": "chinese", # Use "cn" as shorthand for Chinese
"en": "english" # Use "en" as shorthand for English
}
}
Map<String, Object> analyzerParams = new HashMap<>();
analyzerParams.put("analyzers", new HashMap<String, Object>() {{
put("english", new HashMap<String, Object>() {{
put("type", "english");
}});
put("chinese", new HashMap<String, Object>() {{
put("type", "chinese");
}});
put("default", new HashMap<String, Object>() {{
put("tokenizer", "icu");
}});
}});
analyzerParams.put("by_field", "language");
analyzerParams.put("alias", new HashMap<String, Object>() {{
put("cn", "chinese");
put("en", "english");
}});
const multi_analyzer_params = {
// Define language-specific analyzers
// Each analyzer follows this format: <analyzer_name>: <analyzer_params>
"analyzers": {
"english": {"type": "english"}, # English-optimized analyzer
"chinese": {"type": "chinese"}, # Chinese-optimized analyzer
"default": {"tokenizer": "icu"} # Required fallback analyzer
},
"by_field": "language", # Field determining analyzer selection
"alias": {
"cn": "chinese", # Use "cn" as shorthand for Chinese
"en": "english" # Use "en" as shorthand for English
}
}
multiAnalyzerParams := map[string]any{
"analyzers": map[string]any{
"english": map[string]string{"type": "english"},
"chinese": map[string]string{"type": "chinese"},
"default": map[string]string{"tokenizer": "icu"},
},
"by_field": "language",
"alias": map[string]string{
"cn": "chinese",
"en": "english",
},
}
# restful
export multi_analyzer_params='{
"analyzers": {
"english": {
"type": "english"
},
"chinese": {
"type": "chinese"
},
"default": {
"tokenizer": "icu"
}
},
"by_field": "language",
"alias": {
"cn": "chinese",
"en": "english"
}
}'
パラメーター | 必須? | 説明 | ルール |
|---|---|---|---|
| はい | Zilliz Cloud がテキスト処理に使用できるすべての言語固有アナライザーをリストします。
|
|
| はい | 各ドキュメントごとに Zilliz Cloud が適用すべき言語(つまりアナライザー名)を格納するフィールドの名前です。 |
|
| いいえ | アナライザーのショートカットまたは代替名を作成し、コード内での参照を容易にします。各アナライザーには1つ以上のエイリアスを設定できます。 | 各エイリアスは、既存のアナライザーキーにマッピングされている必要があります。 |
Step 2: Create collection
多言語サポート付きのコレクションを作成するには、特定のフィールドおよびインデックスを設定する必要があります。
Step 1: Add fields
このステップでは、以下の4つの必須フィールドを持つコレクションスキーマを定義します。
-
主キーフィールド (
id): コレクション内の各エンティティを一意に識別するためのフィールドです。auto_id=Trueを設定すると、Zilliz Cloud が自動的にこれらの ID を生成します。 -
言語 Indicator Field (
language): この VARCHAR フィールドは、multi_analyzer_paramsで指定したby_fieldに対応します。各エンティティの言語識別子を格納し、Zilliz Cloud がどのアナライザーを使用するかを指示します。 -
テキストコンテンツフィールド (
text): この VARCHAR フィールドは、分析および検索したい実際のテキストデータを格納します。このフィールドに対してenable_analyzer=Trueを設定することは極めて重要であり、これによりテキスト分析機能が有効になります。multi_analyzer_params設定はこのフィールドに直接アタッチされ、テキストデータと言語固有アナライザーとの関連付けを行います。 -
ベクトルフィールド (
sparse): このフィールドには、BM25関数によって生成された疎ベクトルが格納されます。これらのベクトルはテキストデータの分析可能な形式を表しており、Zilliz Cloud が実際に検索を行う対象となります。
- Python
- Java
- NodeJS
- Go
- cURL
# Import required modules
from pymilvus import MilvusClient, DataType, Function, FunctionType
# Initialize client
client = MilvusClient(
uri="YOUR_CLUSTER_ENDPOINT",
)
# Initialize a new schema
schema = client.create_schema()
# Step 2.1: Add a primary key field for unique document identification
schema.add_field(
field_name="id", # Field name
datatype=DataType.INT64, # Integer data type
is_primary=True, # Designate as primary key
auto_id=True # Auto-generate IDs (recommended)
)
# Step 2.2: Add language identifier field
# This MUST match the "by_field" value in language_analyzer_config
schema.add_field(
field_name="language", # Field name
datatype=DataType.VARCHAR, # String data type
max_length=255 # Maximum length (adjust as needed)
)
# Step 2.3: Add text content field with multi-language analysis capability
schema.add_field(
field_name="text", # Field name
datatype=DataType.VARCHAR, # String data type
max_length=8192, # Maximum length (adjust based on expected text size)
enable_analyzer=True, # Enable text analysis
multi_analyzer_params=multi_analyzer_params # Connect with our language analyzers
)
# Step 2.4: Add sparse vector field to store the BM25 output
schema.add_field(
field_name="sparse", # Field name
datatype=DataType.SPARSE_FLOAT_VECTOR # Sparse vector data type
)
import com.google.gson.JsonObject;
import io.milvus.common.clientenum.FunctionType;
import io.milvus.v2.client.ConnectConfig;
import io.milvus.v2.client.MilvusClientV2;
import io.milvus.v2.common.DataType;
import io.milvus.v2.common.IndexParam;
import io.milvus.v2.service.collection.request.AddFieldReq;
import io.milvus.v2.service.collection.request.CreateCollectionReq;
import io.milvus.v2.service.collection.request.DropCollectionReq;
import io.milvus.v2.service.utility.request.FlushReq;
import io.milvus.v2.service.vector.request.InsertReq;
import io.milvus.v2.service.vector.request.SearchReq;
import io.milvus.v2.service.vector.request.data.EmbeddedText;
import io.milvus.v2.service.vector.response.SearchResp;
MilvusClientV2 client = new MilvusClientV2(ConnectConfig.builder()
.uri("YOUR_CLUSTER_ENDPOINT")
.build());
CreateCollectionReq.CollectionSchema collectionSchema = CreateCollectionReq.CollectionSchema.builder()
.build();
collectionSchema.addField(AddFieldReq.builder()
.fieldName("id")
.dataType(DataType.Int64)
.isPrimaryKey(true)
.autoID(true)
.build());
collectionSchema.addField(AddFieldReq.builder()
.fieldName("language")
.dataType(DataType.VarChar)
.maxLength(255)
.build());
collectionSchema.addField(AddFieldReq.builder()
.fieldName("text")
.dataType(DataType.VarChar)
.maxLength(8192)
.enableAnalyzer(true)
.multiAnalyzerParams(analyzerParams)
.build());
collectionSchema.addField(AddFieldReq.builder()
.fieldName("sparse")
.dataType(DataType.SparseFloatVector)
.build());
import { MilvusClient, DataType, FunctionType } from "@zilliz/milvus2-sdk-node";
// Initialize client
const client = new MilvusClient({
address: "YOUR_CLUSTER_ENDPOINT",
});
// Initialize schema array
const schema = [
{
name: "id",
data_type: DataType.Int64,
is_primary_key: true,
auto_id: true,
},
{
name: "language",
data_type: DataType.VarChar,
max_length: 255,
},
{
name: "text",
data_type: DataType.VarChar,
max_length: 8192,
enable_analyzer: true,
analyzer_params: multi_analyzer_params,
},
{
name: "sparse",
data_type: DataType.SparseFloatVector,
},
];
import (
"context"
"fmt"
"github.com/milvus-io/milvus/client/v2/column"
"github.com/milvus-io/milvus/client/v2/entity"
"github.com/milvus-io/milvus/client/v2/index"
"github.com/milvus-io/milvus/client/v2/milvusclient"
)
client, err := milvusclient.New(ctx, &milvusclient.ClientConfig{
Address: "YOUR_CLUSTER_ENDPOINT",
APIKey: "YOUR_CLUSTER_TOKEN",
})
if err != nil {
fmt.Println(err.Error())
// handle error
}
schema := entity.NewSchema()
schema.WithField(entity.NewField().
WithName("id").
WithDataType(entity.FieldTypeInt64).
WithIsPrimaryKey(true).
WithIsAutoID(true),
).WithField(entity.NewField().
WithName("language").
WithDataType(entity.FieldTypeVarChar).
WithMaxLength(255),
).WithField(entity.NewField().
WithName("text").
WithDataType(entity.FieldTypeVarChar).
WithMaxLength(8192).
WithEnableAnalyzer(true).
WithMultiAnalyzerParams(multiAnalyzerParams),
).WithField(entity.NewField().
WithName("sparse").
WithDataType(entity.FieldTypeSparseVector),
)
# restful
export TOKEN="YOUR_CLUSTER_TOKEN"
export CLUSTER_ENDPOINT="YOUR_CLUSTER_ENDPOINT"
export idField='{
"fieldName": "id",
"dataType": "Int64",
"isPrimary": true,
"autoID": true
}'
export languageField='{
"fieldName": "language",
"dataType": "VarChar",
"elementTypeParams": {
"max_length": 255
}
}'
export textField='{
"fieldName": "text",
"dataType": "VarChar",
"elementTypeParams": {
"max_length": 8192,
"enable_analyzer": true,
"multiAnalyzerParam": '"$multi_analyzer_params"'
},
}'
export sparseField='{
"fieldName": "sparse",
"dataType": "SparseFloatVector"
}'
ステップ 2: BM25関数を定義する
生のテキストデータからスパースベクトル表現を生成するためのBM25関数を定義します:
- Python
- Java
- NodeJS
- Go
- cURL
# Create the BM25 function
bm25_function = Function(
name="text_to_vector", # Descriptive function name
function_type=FunctionType.BM25, # Use BM25 algorithm
input_field_names=["text"], # Process text from this field
output_field_names=["sparse"] # Store vectors in this field
)
# Add the function to our schema
schema.add_function(bm25_function)
CreateCollectionReq.Function function = CreateCollectionReq.Function.builder()
.functionType(FunctionType.BM25)
.name("text_to_vector")
.inputFieldNames(Collections.singletonList("text"))
.outputFieldNames(Collections.singletonList("sparse"))
.build();
collectionSchema.addFunction(function);
const functions = [
{
name: "text_bm25_emb",
description: "bm25 function",
type: FunctionType.BM25,
input_field_names: ["text"],
output_field_names: ["sparse"],
params: {},
},
];
function := entity.NewFunction()
schema.WithFunction(function.WithName("text_to_vector").
WithType(entity.FunctionTypeBM25).
WithInputFields("text").
WithOutputFields("sparse"))
# restful
export function='{
"name": "text_to_vector",
"type": "BM25",
"inputFieldNames": ["text"],
"outputFieldNames": ["sparse"]
}'
export schema="{
\"autoID\": true,
\"fields\": [
$idField,
$languageField,
$textField,
$sparseField
],
\"functions\": [
$function
]
}"
この関数は、各テキストエントリの言語識別子に基づいて、適切なアナライザーを自動的に適用します。BM25 ベースのテキスト検索の詳細については、全文検索 を参照してください。
Step 3: インデックスパラメータの設定
効率的な検索を可能にするため、スパースベクトルフィールドにインデックスを作成します。
- Python
- Java
- NodeJS
- Go
- cURL
# Configure index parameters
index_params = client.prepare_index_params()
# Add index for sparse vector field
index_params.add_index(
field_name="sparse", # Field to index (our vector field)
index_type="AUTOINDEX", # Let Milvus choose optimal index type
metric_type="BM25" # Must be BM25 for this feature
)
List<IndexParam> indexes = new ArrayList<>();
indexes.add(IndexParam.builder()
.fieldName("sparse")
.indexType(IndexParam.IndexType.AUTOINDEX)
.metricType(IndexParam.MetricType.BM25)
.build());
const index_params = [{
field_name: "sparse",
index_type: "AUTOINDEX",
metric_type: "BM25"
}];
idx := index.NewAutoIndex(index.MetricType(entity.BM25))
indexOption := milvusclient.NewCreateIndexOption("multilingual_documents", "sparse", idx)
# restful
export IndexParams='[
{
"fieldName": "sparse",
"indexType": "AUTOINDEX",
"metricType": "BM25",
"params": {}
}
]'
インデックスは、疎ベクトルを整理してBM25類似度計算を効率的に行えるようにすることで、検索パフォーマンスを向上させます。
ステップ4: コレクションの作成
この最終的な作成ステップでは、これまでに設定した内容をすべて統合します:
-
collection_name="multilang_demo"は、コレクションに今後の参照用の名前を付けます。 -
schema=schemaは、定義したフィールド構造と関数を適用します。 -
index_params=index_paramsは、効率的な検索のためのインデックス戦略を実装します。
- Python
- Java
- NodeJS
- Go
- cURL
# Create collection
COLLECTION_NAME = "multilingual_documents"
# Check if collection already exists
if client.has_collection(COLLECTION_NAME):
client.drop_collection(COLLECTION_NAME) # Remove it for this example
print(f"Dropped existing collection: {COLLECTION_NAME}")
# Create the collection
client.create_collection(
collection_name=COLLECTION_NAME, # Collection name
schema=schema, # Our multilingual schema
index_params=index_params # Our search index configuration
)
client.dropCollection(DropCollectionReq.builder()
.collectionName("multilingual_documents")
.build());
CreateCollectionReq requestCreate = CreateCollectionReq.builder()
.collectionName("multilingual_documents")
.collectionSchema(collectionSchema)
.indexParams(indexes)
.build();
client.createCollection(requestCreate);
const COLLECTION_NAME = "multilingual_documents";
// Create the collection
await client.createCollection({
collection_name: COLLECTION_NAME,
schema: schema,
index_params: index_params,
functions: functions
});
err = client.CreateCollection(ctx,
milvusclient.NewCreateCollectionOption("multilingual_documents", schema).
WithIndexOptions(indexOption))
if err != nil {
fmt.Println(err.Error())
// handle error
}
# restful
curl --request POST \
--url "${CLUSTER_ENDPOINT}/v2/vectordb/collections/create" \
--header "Authorization: Bearer ${TOKEN}" \
--header "Content-Type: application/json" \
--data "{
\"collectionName\": \"multilingual_documents\",
\"schema\": $schema,
\"indexParams\": $IndexParams
}"
この時点で、Zilliz Cloud は多言語アナライザーをサポートする空のコレクションを作成し、データの受信準備が整います。
Step 3: Insert example data
多言語コレクションにドキュメントを追加する際には、各ドキュメントにテキストコンテンツと言語識別子の両方を含める必要があります。
- Python
- Java
- NodeJS
- Go
- cURL
# Prepare multilingual documents
documents = [
# English documents
{
"text": "Artificial intelligence is transforming technology",
"language": "english", # Using full language name
},
{
"text": "Machine learning models require large datasets",
"language": "en", # Using our defined alias
},
# Chinese documents
{
"text": "人工智能正在改变技术领域",
"language": "chinese", # Using full language name
},
{
"text": "机器学习模型需要大型数据集",
"language": "cn", # Using our defined alias
},
]
# Insert the documents
result = client.insert(COLLECTION_NAME, documents)
# Print results
inserted = result["insert_count"]
print(f"Successfully inserted {inserted} documents")
print("Documents by language: 2 English, 2 Chinese")
# Expected output:
# Successfully inserted 4 documents
# Documents by language: 2 English, 2 Chinese
List<String> texts = Arrays.asList(
"Artificial intelligence is transforming technology",
"Machine learning models require large datasets",
"人工智能正在改变技术领域",
"机器学习模型需要大型数据集"
);
List<String> languages = Arrays.asList(
"english", "en", "chinese", "cn"
);
List<JsonObject> rows = new ArrayList<>();
for (int i = 0; i < texts.size(); i++) {
JsonObject row = new JsonObject();
row.addProperty("text", texts.get(i));
row.addProperty("language", languages.get(i));
rows.add(row);
}
client.insert(InsertReq.builder()
.collectionName("multilingual_documents")
.data(rows)
.build());
// Prepare multilingual documents
const documents = [
// English documents
{
text: "Artificial intelligence is transforming technology",
language: "english",
},
{
text: "Machine learning models require large datasets",
language: "en",
},
// Chinese documents
{
text: "人工智能正在改变技术领域",
language: "chinese",
},
{
text: "机器学习模型需要大型数据集",
language: "cn",
},
];
// Insert the documents
const result = await client.insert({
collection_name: COLLECTION_NAME,
data: documents,
});
// Print results
const inserted = result.insert_count;
console.log(\`Successfully inserted ${inserted} documents\`);
console.log("Documents by language: 2 English, 2 Chinese");
// Expected output:
// Successfully inserted 4 documents
// Documents by language: 2 English, 2 Chinese
column1 := column.NewColumnVarChar("text",
[]string{
"Artificial intelligence is transforming technology",
"Machine learning models require large datasets",
"人工智能正在改变技术领域",
"机器学习模型需要大型数据集",
})
column2 := column.NewColumnVarChar("language",
[]string{"english", "en", "chinese", "cn"})
_, err = client.Insert(ctx, milvusclient.NewColumnBasedInsertOption("multilingual_documents").
WithColumns(column1, column2),
)
if err != nil {
fmt.Println(err.Error())
// handle err
}
# restful
curl --request POST \
--url "${CLUSTER_ENDPOINT}/v2/vectordb/entities/insert" \
--header "Authorization: Bearer ${TOKEN}" \
--header "Content-Type: application/json" \
--data '{
"collectionName": "multilingual_documents",
"data": [
{
"text": "Artificial intelligence is transforming technology",
"language": "english"
},
{
"text": "Machine learning models require large datasets",
"language": "en"
},
{
"text": "人工智能正在改变技术领域",
"language": "chinese"
},
{
"text": "机器学习模型需要大型数据集",
"language": "cn"
}
]
}'
挿入時、Zilliz Cloud は以下の処理を行います。
-
各ドキュメントの
languageフィールドを読み取ります -
textフィールドに対応するアナライザーを適用します -
BM25関数を使用してスパースベクトル表現を生成します
-
元のテキストと生成されたスパースベクトルの両方を保存します
スパースベクトルを直接指定する必要はありません。BM25関数は、テキストと指定されたアナライザーに基づいて自動的に生成します。
ステップ 4: 検索操作を実行する
英語アナライザーの使用
多言語アナライザーを使用して検索する場合、search_params に重要な設定が含まれます。
-
metric_type="BM25"はインデックス設定と一致している必要があります。 -
analyzer_name="english"は、クエリテキストに適用するアナライザーを指定します。これは保存されたドキュメントで使用されるアナライザーとは独立しています。 -
params={"drop_ratio_search": "0"}は BM25 固有の動作を制御します。ここでは、検索時にすべての用語を保持します。詳細については、スパースベクトル を参照してください。
- Python
- Java
- NodeJS
- Go
- cURL
search_params = {
"metric_type": "BM25", # Must match index configuration
"analyzer_name": "english", # Analyzer that matches the query language
"drop_ratio_search": "0", # Keep all terms in search (tweak as needed)
}
# Execute the search
english_results = client.search(
collection_name=COLLECTION_NAME, # Collection to search
data=["artificial intelligence"], # Query text
anns_field="sparse", # Field to search against
search_params=search_params, # Search configuration
limit=3, # Max results to return
output_fields=["text", "language"], # Fields to include in the output
consistency_level="Bounded", # Data‑consistency guarantee
)
# Display English search results
print("\n=== English Search Results ===")
for i, hit in enumerate(english_results[0]):
print(f"{i+1}. [{hit.score:.4f}] {hit.entity.get('text')} "
f"(Language: {hit.entity.get('language')})")
# Expected output (English Search Results):
# 1. [2.7881] Artificial intelligence is transforming technology (Language: english)
Map<String,Object> searchParams = new HashMap<>();
searchParams.put("metric_type", "BM25");
searchParams.put("analyzer_name", "english");
searchParams.put("drop_ratio_search", 0);
SearchResp searchResp = client.search(SearchReq.builder()
.collectionName("multilingual_documents")
.data(Collections.singletonList(new EmbeddedText("artificial intelligence")))
.annsField("sparse")
.topK(3)
.searchParams(searchParams)
.outputFields(Arrays.asList("text", "language"))
.build());
System.out.println("\n=== English Search Results ===");
List<List<SearchResp.SearchResult>> searchResults = searchResp.getSearchResults();
for (List<SearchResp.SearchResult> results : searchResults) {
for (SearchResp.SearchResult result : results) {
System.out.printf("Score: %f, %s\n", result.getScore(), result.getEntity().toString());
}
}
// Execute the search
const english_results = await client.search({
collection_name: COLLECTION_NAME,
data: ["artificial intelligence"],
anns_field: "sparse",
params: {
metric_type: "BM25",
analyzer_name: "english",
drop_ratio_search: "0",
},
limit: 3,
output_fields: ["text", "language"],
consistency_level: "Bounded",
});
// Display English search results
console.log("\n=== English Search Results ===");
english_results.results.forEach((hit, i) => {
console.log(
\`${i + 1}. [${hit.score.toFixed(4)}] ${hit.entity.text} \` +
\`(Language: ${hit.entity.language})\`
);
});
annSearchParams := index.NewCustomAnnParam()
annSearchParams.WithExtraParam("metric_type", "BM25")
annSearchParams.WithExtraParam("analyzer_name", "english")
annSearchParams.WithExtraParam("drop_ratio_search", 0)
resultSets, err := client.Search(ctx, milvusclient.NewSearchOption(
"multilingual_documents", // collectionName
3, // limit
[]entity.Vector{entity.Text("artificial intelligence")},
).WithANNSField("sparse").
WithAnnParam(annSearchParams).
WithOutputFields("text", "language"))
if err != nil {
fmt.Println(err.Error())
// handle error
}
for _, resultSet := range resultSets {
for i := 0; i < len(resultSet.Scores); i++ {
text, _ := resultSet.GetColumn("text").GetAsString(i)
lang, _ := resultSet.GetColumn("language").GetAsString(i)
fmt.Println("Score: ", resultSet.Scores[i], "Text: ", text, "Language:", lang)
}
}
# restful
curl --request POST \
--url "${CLUSTER_ENDPOINT}/v2/vectordb/entities/search" \
--header "Authorization: Bearer ${TOKEN}" \
--header "Content-Type: application/json" \
--data '{
"collectionName": "multilingual_documents",
"data": ["artificial intelligence"],
"annsField": "sparse",
"limit": 3,
"searchParams": {
"metric_type": "BM25",
"analyzer_name": "english",
"drop_ratio_search": "0"
},
"outputFields": ["text", "language"],
"consistencyLevel": "Strong"
}'
中国語アナライザーの使用
この例では、異なるクエリテキストに対して中国語アナライザー(そのエイリアス "cn" を使用)に切り替える方法を示します。他のすべてのパラメータは同じですが、クエリテキストが中国語特有のトークン化ルールで処理されるようになります。
- Python
- Java
- NodeJS
- Go
- cURL
search_params["analyzer_name"] = "cn"
chinese_results = client.search(
collection_name=COLLECTION_NAME, # Collection to search
data=["人工智能"], # Query text
anns_field="sparse", # Field to search against
search_params=search_params, # Search configuration
limit=3, # Max results to return
output_fields=["text", "language"], # Fields to include in the output
consistency_level="Bounded", # Data‑consistency guarantee
)
# Display Chinese search results
print("\n=== Chinese Search Results ===")
for i, hit in enumerate(chinese_results[0]):
print(f"{i+1}. [{hit.score:.4f}] {hit.entity.get('text')} "
f"(Language: {hit.entity.get('language')})")
# Expected output (Chinese Search Results):
# 1. [3.3814] 人工智能正在改变技术领域 (Language: chinese)
searchParams.put("analyzer_name", "cn");
searchResp = client.search(SearchReq.builder()
.collectionName("multilingual_documents")
.data(Collections.singletonList(new EmbeddedText("人工智能")))
.annsField("sparse")
.topK(3)
.searchParams(searchParams)
.outputFields(Arrays.asList("text", "language"))
.build());
System.out.println("\n=== Chinese Search Results ===");
searchResults = searchResp.getSearchResults();
for (List<SearchResp.SearchResult> results : searchResults) {
for (SearchResp.SearchResult result : results) {
System.out.printf("Score: %f, %s\n", result.getScore(), result.getEntity().toString());
}
}
// Execute the search
const cn_results = await client.search({
collection_name: COLLECTION_NAME,
data: ["人工智能"],
anns_field: "sparse",
params: {
metric_type: "BM25",
analyzer_name: "cn",
drop_ratio_search: "0",
},
limit: 3,
output_fields: ["text", "language"],
consistency_level: "Bounded",
});
// Display Chinese search results
console.log("\n=== Chinese Search Results ===");
cn_results.results.forEach((hit, i) => {
console.log(
\`${i + 1}. [${hit.score.toFixed(4)}] ${hit.entity.text} \` +
\`(Language: ${hit.entity.language})\`
);
});
annSearchParams.WithExtraParam("analyzer_name", "cn")
resultSets, err = client.Search(ctx, milvusclient.NewSearchOption(
"multilingual_documents", // collectionName
3, // limit
[]entity.Vector{entity.Text("人工智能")},
).WithANNSField("sparse").
WithAnnParam(annSearchParams).
WithOutputFields("text", "language"))
if err != nil {
fmt.Println(err.Error())
// handle error
}
for _, resultSet := range resultSets {
for i := 0; i < len(resultSet.Scores); i++ {
text, _ := resultSet.GetColumn("text").GetAsString(i)
lang, _ := resultSet.GetColumn("language").GetAsString(i)
fmt.Println("Score: ", resultSet.Scores[i], "Text: ", text, "Language:", lang)
}
}
# restful
curl --request POST \
--url "${CLUSTER_ENDPOINT}/v2/vectordb/entities/search" \
--header "Authorization: Bearer ${TOKEN}" \
--header "Content-Type: application/json" \
--data '{
"collectionName": "multilingual_documents",
"data": ["人工智能"],
"annsField": "sparse",
"limit": 3,
"searchParams": {
"analyzer_name": "cn"
},
"outputFields": ["text", "language"],
"consistencyLevel": "Strong"
}'