レンジサーチは、返されるエンティティの距離またはスコアを特定の範囲内に制限することで、検索結果の適合性を向上させます。このページでは、レンジサーチとは何か、およびレンジサーチを実行する手順について説明します。
概要
レンジサーチリクエストを実行すると、Zilliz Cloud は ANN サーチ結果からクエリベクトルに最も類似したベクトルを中心として、サーチリクエストで指定された radius を外側の円の半径、range_filter を内側の円の半径として 2 つの同心円を描きます。この 2 つの同心円によって形成される円環領域内に類似度スコアが収まるすべてのベクトルが返されます。ここで、range_filter は 0 に設定することもでき、これは指定された類似度スコア(radius)内のすべてのエンティティが返されることを示します。
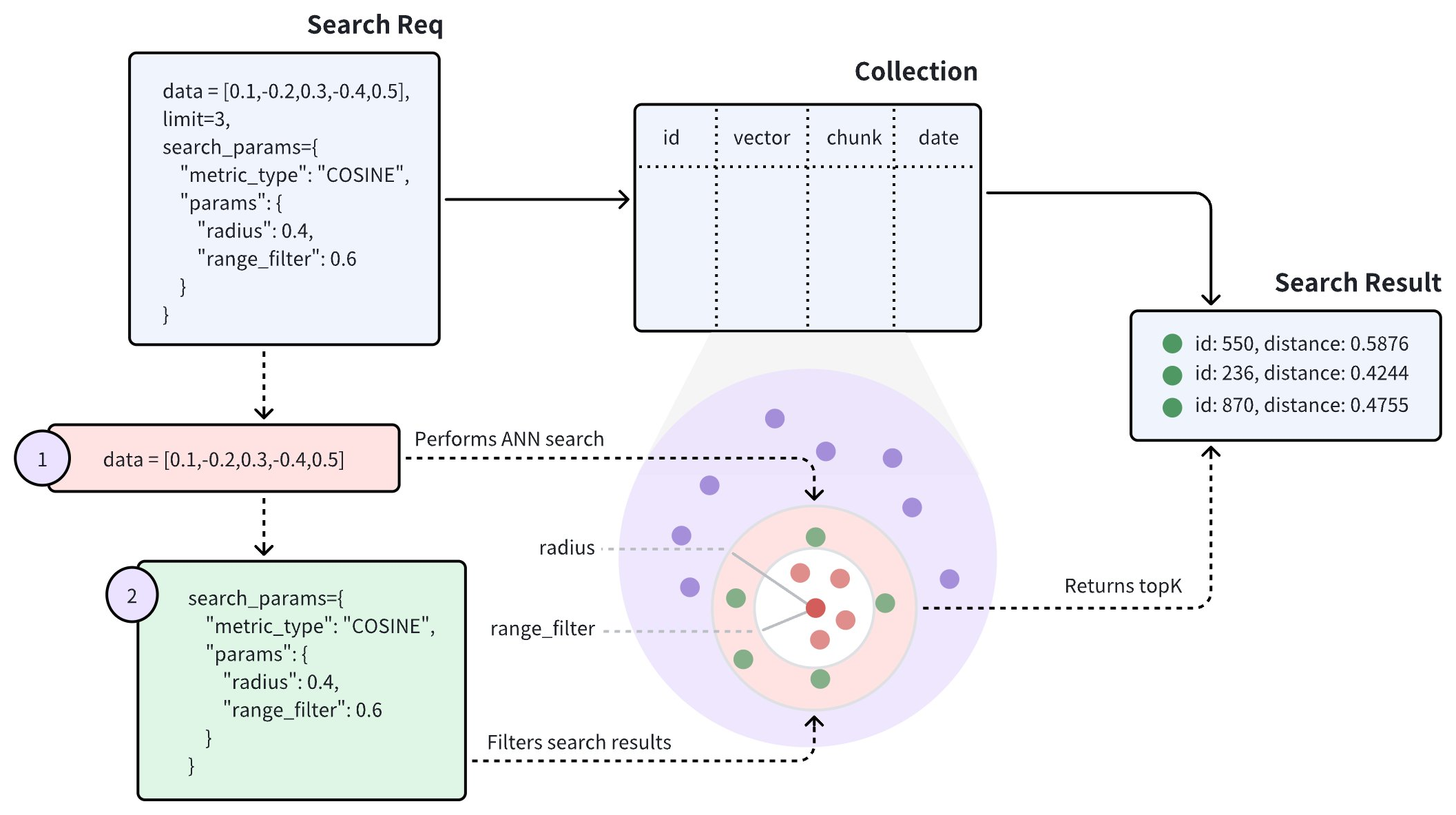
上記の図は、レンジサーチリクエストが radius と range_filter の 2 つのパラメータを含むことを示しています。レンジサーチリクエストを受信すると、Zilliz Cloud は以下を実行します。
-
指定されたメトリックタイプ(COSINE)を使用して、クエリベクトルに最も類似したすべてのベクトル埋め込みを見つけます。
-
クエリベクトルとの 距離 または スコア が radius および range_filter パラメータで指定された範囲内に収まるベクトル埋め込みをフィルタリングします。
-
フィルタリングされた結果から top-K のエンティティを返します。
radius と range_filter の設定方法は、サーチのメトリックタイプによって異なります。以下の表は、異なるメトリックタイプでこれら 2 つのパラメータを設定する際の要件を示しています。
メトリックタイプ | 表記 | radius と range_filter の設定要件 |
|---|---|---|
| L2 距離が小さいほど、類似度が高くなります。 | 最も類似したベクトル埋め込みを無視するには、以下を満たすようにします。
|
| IP 距離が大きいほど、類似度が高くなります。 | 最も類似したベクトル埋め込みを無視するには、以下を満たすようにします。
|
| COSINE 距離が大きいほど、類似度が高くなります。 | 最も類似したベクトル埋め込みを無視するには、以下を満たすようにします。
|
| Jaccard 距離が小さいほど、類似度が高くなります。 | 最も類似したベクトル埋め込みを無視するには、以下を満たすようにします。
|
| ハミング距離が小さいほど、類似度が高くなります。 | 最も類似したベクトル埋め込みを無視するには、以下を満たすようにします。
|
例
このセクションでは、レンジサーチの実行方法を示します。以下のコードスニペットのサーチリクエストはメトリックタイプを含んでいないため、デフォルトのメトリックタイプ COSINE が適用されます。この場合、radius の値が range_filter の値より小さいことを確認してください。
以下のコードスニペットでは、radius を 0.4、range_filter を 0.6 に設定し、クエリベクトルとの距離またはスコアが 0.4 から 0.6 の範囲内に収まるすべてのエンティティを Zilliz Cloud に返させます。
- Python
- Java
- Go
- NodeJS
- cURL
from pymilvus import MilvusClient
client = MilvusClient(
uri="YOUR_CLUSTER_ENDPOINT",
token="YOUR_CLUSTER_TOKEN"
)
query_vector = [0.3580376395471989, -0.6023495712049978, 0.18414012509913835, -0.26286205330961354, 0.9029438446296592]
res = client.search(
collection_name="my_collection",
data=[query_vector],
limit=3,
search_params={
"params": {
"radius": 0.4,
"range_filter": 0.6
}
}
)
for hits in res:
print("TopK results:")
for hit in hits:
print(hit)
import io.milvus.v2.client.ConnectConfig;
import io.milvus.v2.client.MilvusClientV2;
io.milvus.v2.service.vector.request.SearchReq
import io.milvus.v2.service.vector.request.data.FloatVec;
import io.milvus.v2.service.vector.response.SearchResp
MilvusClientV2 client = new MilvusClientV2(ConnectConfig.builder()
.uri("YOUR_CLUSTER_ENDPOINT")
.token("YOUR_CLUSTER_TOKEN")
.build());
FloatVec queryVector = new FloatVec(new float[]{0.3580376395471989f, -0.6023495712049978f, 0.18414012509913835f, -0.26286205330961354f, 0.9029438446296592f});
Map<String,Object> extraParams = new HashMap<>();
extraParams.put("radius", 0.4);
extraParams.put("range_filter", 0.6);
SearchReq searchReq = SearchReq.builder()
.collectionName("my_collection")
.data(Collections.singletonList(queryVector))
.topK(5)
.searchParams(extraParams)
.build();
SearchResp searchResp = client.search(searchReq);
List<List<SearchResp.SearchResult>> searchResults = searchResp.getSearchResults();
for (List<SearchResp.SearchResult> results : searchResults) {
System.out.println("TopK results:");
for (SearchResp.SearchResult result : results) {
System.out.println(result);
}
}
// Output
// TopK results:
// SearchResp.SearchResult(entity={}, score=0.5975797, id=4)
// SearchResp.SearchResult(entity={}, score=0.46704385, id=5)
import (
"context"
"fmt"
"github.com/milvus-io/milvus/client/v2/index"
"github.com/milvus-io/milvus/client/v2/entity"
"github.com/milvus-io/milvus/client/v2/milvusclient"
)
ctx, cancel := context.WithCancel(context.Background())
defer cancel()
milvusAddr := "YOUR_CLUSTER_ENDPOINT"
client, err := milvusclient.New(ctx, &milvusclient.ClientConfig{
Address: milvusAddr,
})
if err != nil {
fmt.Println(err.Error())
// handle error
}
defer client.Close(ctx)
queryVector := []float32{0.3580376395471989, -0.6023495712049978, 0.18414012509913835, -0.26286205330961354, 0.9029438446296592}
annParam := index.NewCustomAnnParam()
annParam.WithRadius(0.4)
annParam.WithRangeFilter(0.6)
resultSets, err := client.Search(ctx, milvusclient.NewSearchOption(
"my_collection", // collectionName
5, // limit
[]entity.Vector{entity.FloatVector(queryVector)},
).WithConsistencyLevel(entity.ClStrong).
WithANNSField("vector").
WithAnnParam(annParam))
if err != nil {
fmt.Println(err.Error())
// handle error
}
for _, resultSet := range resultSets {
fmt.Println("IDs: ", resultSet.IDs.FieldData().GetScalars())
fmt.Println("Scores: ", resultSet.Scores)
}
import { MilvusClient, DataType } from "@zilliz/milvus2-sdk-node";
const address = "YOUR_CLUSTER_ENDPOINT";
const token = "YOUR_CLUSTER_TOKEN";
const client = new MilvusClient({address, token});
var query_vector = [0.3580376395471989, -0.6023495712049978, 0.18414012509913835, -0.26286205330961354, 0.9029438446296592]
res = await client.search({
collection_name: "my_collection",
data: [query_vector],
limit: 5,
params: {
"radius": 0.4,
"range_filter": 0.6
}
})
export CLUSTER_ENDPOINT="YOUR_CLUSTER_ENDPOINT"
export TOKEN="YOUR_CLUSTER_TOKEN"
curl --request POST \
--url "${CLUSTER_ENDPOINT}/v2/vectordb/entities/search" \
--header "Authorization: Bearer ${TOKEN}" \
--header "Content-Type: application/json" \
-d '{
"collectionName": "my_collection",
"data": [
[0.3580376395471989, -0.6023495712049978, 0.18414012509913835, -0.26286205330961354, 0.9029438446296592]
],
"annsField": "vector",
"limit": 5,
"searchParams": {
"params": {
"radius": 0.4,
"range_filter": 0.6
}
}
}'
# {"code":0,"cost":0,"data":[]}
クエリベクトルがすでにターゲットコレクションに存在する場合は、検索前にそれらを取得する代わりに、ids を使用することを検討してください。詳細については、Primary-キー Search を参照してください。