Weighted Ranker
Weighted Ranker は、複数の検索パスからの結果をインテリジェントに統合・優先順位付けするために、それぞれに異なる重要度の重みを割り当てます。熟練したシェフが完璧な料理を作るために複数の食材をバランスよく調和させるように、Weighted Ranker は異なる検索結果をバランス取りながら、最も関連性の高い統合結果を提供します。このアプローチは、複数のベクトルフィールドやモダリティにまたがって検索を行う際に、特定のフィールドが最終的なランキングにより大きな影響を与えるべき場合に理想的です。
Weighted Ranker の使用タイミング
Weighted Ranker は、複数のベクトル検索パスの結果を統合する必要があるハイブリッド検索シナリオ向けに特別に設計されています。特に以下のケースで効果的です:
ユースケース | 例 | Weighted Ranker が有効な理由 |
|---|---|---|
Eコマース検索 | 画像類似性とテキスト説明を組み合わせた商品検索 | ファッションアイテムでは視覚的類似性を優先し、技術系製品ではテキスト説明を重視できる |
メディアコンテンツ検索 | ビジュアル特徴と音声トランスクリプトを用いた動画検索 | クエリの意図に基づき、視覚コンテンツと音声対話の重要度をバランス調整できる |
ドキュメント検索 | 企業内ドキュメント検索で、異なるセクションごとに複数の埋め込みを使用 | タイトルおよび要約の埋め込みにより高い重みを与えつつ、全文埋め込みも考慮 |
ハイブリッド検索アプリケーションにおいて、複数の検索パスを統合しつつ、それぞれの相対的重要性を制御する必要がある場合は、Weighted Ranker が最適な選択肢です。
Weighted Ranker の仕組み
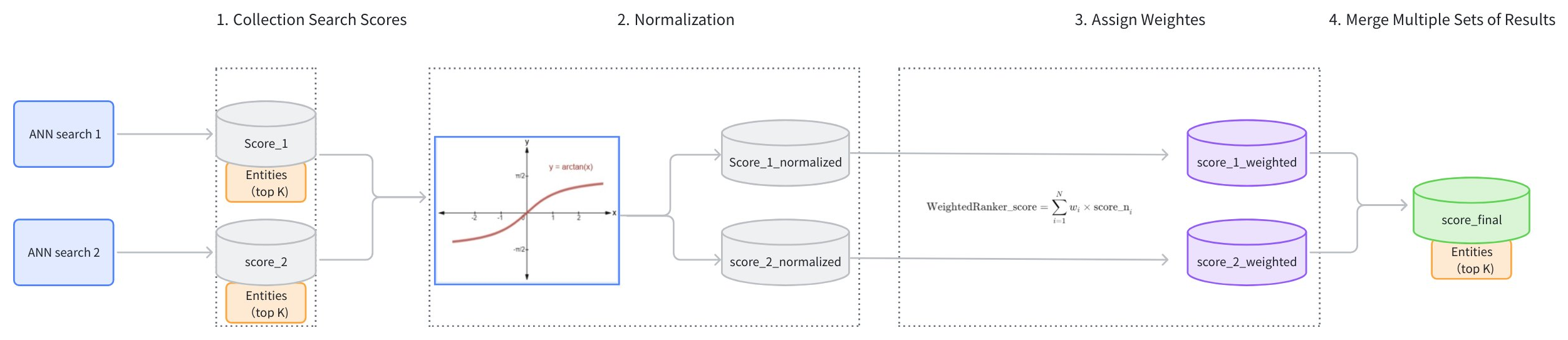
WeightedRanker 戦略の主なワークフローは以下の通りです:
-
検索スコアを収集: 各ベクトル検索パスから結果とスコアを収集します(score_1, score_2)。
-
スコアの正規化: 各検索は異なる類似度指標を使用している可能性があり、その結果スコア分布も異なります。例えば、内積(IP)を類似度タイプとして使用するとスコア範囲は [−∞,+∞] となりますが、ユークリッド距離(L2)を使用するとスコア範囲は [0,+∞] になります。異なる検索からのスコア範囲は異なり直接比較できないため、各検索パスのスコアを正規化する必要があります。通常、
arctan関数を適用してスコアを [0, 1] の範囲に変換します(score_1_normalized, score_2_normalized)。1 に近いスコアほど類似度が高いことを示します。 -
重みの割り当て: 異なるベクトルフィールドに割り当てられた重要度に基づき、正規化されたスコア(score_1_normalized, score_2_normalized)に重み(wi)を割り当てます。各パスの重みは [0,1] の範囲内である必要があります。これにより、加重スコア(score_1_weighted, score_2_weighted)が得られます。
-
スコアの統合: 加重スコア(score_1_weighted, score_2_weighted)を高い順にランク付けし、最終的なスコアセット(score_final)を生成します。
Weighted Ranker の例
この例では、画像とテキストを含むマルチモーダルハイブリッド検索(topK=5)を実施し、WeightedRanker 戦略が2つの ANN 検索結果をどのように再ランク付けするかを示します。
-
画像に対する ANN 検索結果(topK=5):
ID
Score (image)
101
0.92
203
0.88
150
0.85
198
0.83
175
0.8
-
テキストに対する ANN 検索結果(topK=5):
ID
Score (text)
198
0.91
101
0.87
110
0.85
175
0.82
250
0.78
-
WeightedRanker を使用して画像およびテキスト検索結果に重みを割り当てます。ここでは、画像 ANN 検索の重みを 0.6、テキスト検索の重みを 0.4 とします。
ID
Score (image)
Score (text)
Weighted Score
101
0.92
0.87
0.6×0.92+0.4×0.87=0.90
203
0.88
N/A
0.6×0.88+0.4×0=0.528
150
0.85
N/A
0.6×0.85+0.4×0=0.51
198
0.83
0.91
0.6×0.83+0.4×0.91=0.86
175
0.80
0.82
0.6×0.80+0.4×0.82=0.81
110
Not in Image
0.85
0.6×0+0.4×0.85=0.34
250
Not in Image
0.78
0.6×0+0.4×0.78=0.312
-
再ランク付け後の最終結果(topK=5):
Rank
ID
Final Score
1
101
0.90
2
198
0.86
3
175
0.81
4
203
0.528
5
150
0.51
Weighted Ranker の使用方法
WeightedRanker 戦略を使用する際には、重み値を入力する必要があります。入力する重み値の数は、ハイブリッド検索内の基本 ANN 検索リクエストの数と一致させる必要があります。入力する重み値は [0,1] の範囲内であり、1 に近いほど重要度が高いことを示します。
Weighted Ranker の作成
例えば、ハイブリッド検索内にテキスト検索と画像検索という2つの基本 ANN 検索リクエストがあるとします。テキスト検索の方がより重要だと判断される場合、より大きな重みを割り当てるべきです。
- Python
- Java
- NodeJS
- Go
- cURL
from pymilvus import Function, FunctionType
rerank = Function(
name="weight",
input_field_names=[], # Must be an empty list
function_type=FunctionType.RERANK,
params={
"reranker": "weighted",
"weights": [0.1, 0.9],
"norm_score": True # Optional
}
)
import io.milvus.common.clientenum.FunctionType;
import io.milvus.v2.service.collection.request.CreateCollectionReq;
CreateCollectionReq.Function rerank = CreateCollectionReq.Function.builder()
.name("weight")
.functionType(FunctionType.RERANK)
.param("reranker", "weighted")
.param("weights", "[0.1, 0.9]")
.param("norm_score", "true")
.build();
import { FunctionType } from '@zilliz/milvus2-sdk-node';
const rerank = {
name: "weight",
input_field_names: [],
function_type: FunctionType.RERANK,
params: {
reranker: "weighted",
weights: [0.1, 0.9],
norm_score: true
}
};
// Go
# Restful
パラメータ | 必須? | 説明 | 値/例 |
|---|---|---|---|
| はい | このFunctionの一意な識別子 |
|
| はい | この関数を適用するベクトルフィールドのリスト(Weighted Rankerの場合は空にする必要があります) | [] |
| はい | 呼び出すFunctionのタイプ。リランキング戦略を指定するには |
|
| はい | 使用するリランキング方法を指定します。 Weighted Rankerを使用するには、必ず |
|
| はい | 各検索パスに対応する重みの配列。値は[0,1]の範囲内です。 詳細については、Weighted Rankerの仕組みを参照してください。 |
|
| いいえ | 重み付け前に生スコアを(arctanを使って)正規化するかどうかを指定します。 詳細については、Weighted Rankerの仕組みを参照してください。 |
|
ハイブリッド検索への適用
Weighted Rankerは、複数のベクトルフィールドを組み合わせたハイブリッド検索操作のために特別に設計されています。ハイブリッド検索を実行する際には、各検索パスの重みを指定する必要があります:
- Python
- Java
- NodeJS
- Go
- cURL
from pymilvus import MilvusClient, AnnSearchRequest
# Connect to Milvus server
milvus_client = MilvusClient(
uri="YOUR_CLUSTER_ENDPOINT",
token="YOUR_CLUSTER_TOKEN"
)
# Assume you have a collection setup
# Define text vector search request
text_search = AnnSearchRequest(
data=["modern dining table"],
anns_field="text_vector",
param={},
limit=10
)
# Define image vector search request
image_search = AnnSearchRequest(
data=[image_embedding], # Image embedding vector
anns_field="image_vector",
param={},
limit=10
)
# Apply Weighted Ranker to product hybrid search
# Text search has 0.8 weight, image search has 0.3 weight
hybrid_results = milvus_client.hybrid_search(
collection_name,
[text_search, image_search], # Multiple search requests
ranker=rerank, # Apply the weighted ranker
limit=10,
output_fields=["product_name", "price", "category"]
)
import io.milvus.v2.client.ConnectConfig;
import io.milvus.v2.client.MilvusClientV2;
import io.milvus.v2.service.vector.request.AnnSearchReq;
import io.milvus.v2.service.vector.request.HybridSearchReq;
import io.milvus.v2.service.vector.response.SearchResp;
import io.milvus.v2.service.vector.request.data.EmbeddedText;
import io.milvus.v2.service.vector.request.data.FloatVec;
MilvusClientV2 client = new MilvusClientV2(ConnectConfig.builder()
.uri("YOUR_CLUSTER_ENDPOINT")
.token("YOUR_CLUSTER_TOKEN")
.build());
List<AnnSearchReq> searchRequests = new ArrayList<>();
searchRequests.add(AnnSearchReq.builder()
.vectorFieldName("text_vector")
.vectors(Collections.singletonList(new EmbeddedText("\"modern dining table\"")))
.limit(10)
.build());
searchRequests.add(AnnSearchReq.builder()
.vectorFieldName("image_vector")
.vectors(Collections.singletonList(new FloatVec(imageEmbedding)))
.limit(10)
.build());
HybridSearchReq hybridSearchReq = HybridSearchReq.builder()
.collectionName(COLLECTION_NAME)
.searchRequests(searchRequests)
.ranker(ranker)
.limit(10)
.outputFields(Arrays.asList("product_name", "price", "category"))
.build();
SearchResp searchResp = client.hybridSearch(hybridSearchReq);
import { MilvusClient, FunctionType } from "@zilliz/milvus2-sdk-node";
const milvusClient = new MilvusClient({
address: "YOUR_CLUSTER_ENDPOINT",
token: "YOUR_CLUSTER_TOKEN"
});
const text_search = {
data: ["modern dining table"],
anns_field: "text_vector",
param: {},
limit: 10,
};
const image_search = {
data: [image_embedding],
anns_field: "image_vector",
param: {},
limit: 10,
};
const search = await milvusClient.search({
collection_name: collection_name,
limit: 10,
data: [text_search, image_search],
rerank: rerank,
output_fields = ["product_name", "price", "category"],
});
// go
# restful
ハイブリッド検索の詳細については、マルチベクターハイブリッド検索を参照してください。