RTREE インデックスは、Zilliz Cloud で GEOMETRY フィールドのクエリを高速化するツリーベースのデータ構造です。コレクションに Well-known text (WKT) 形式で点、線、ポリゴンなどの幾何オブジェクトが格納されており、空間フィルタリングを高速化したい場合、RTREE は理想的な選択です。
仕組み
Zilliz Cloud は RTREE インデックスを使用して、幾何データを効率的に整理およびフィルタリングします。これは2段階のプロセスに従います:
フェーズ 1: インデックスの構築
-
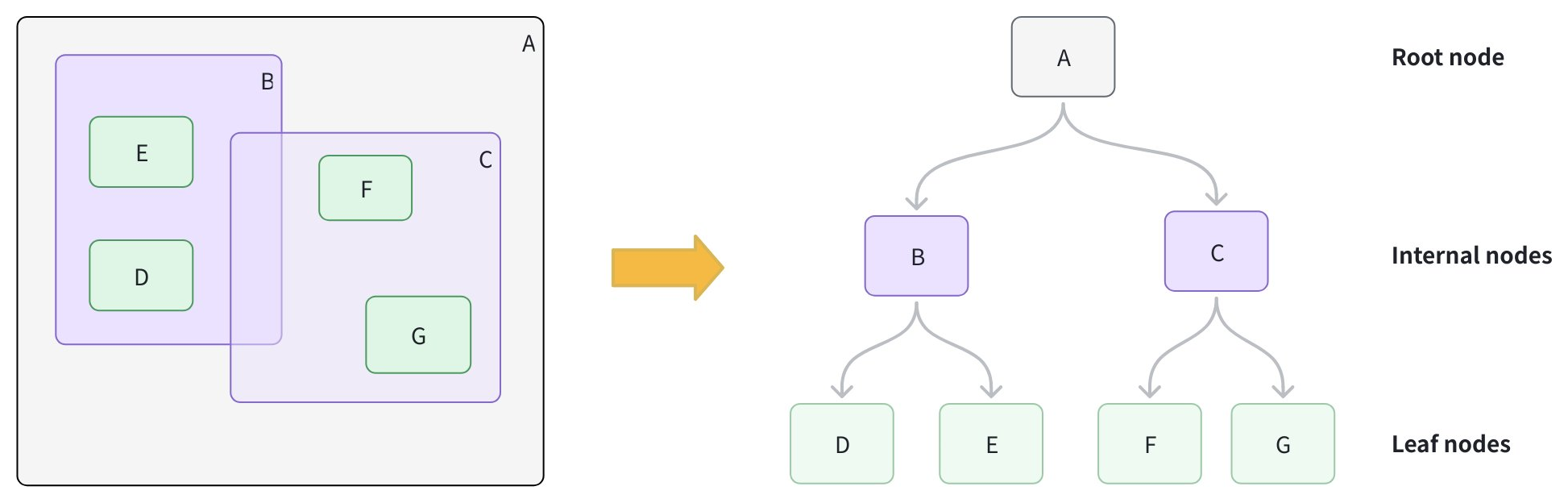
リーフノードの作成: 各幾何オブジェクトについて、Minimum Bounding Rectangle(MBR、オブジェクトを完全に含む最小の矩形)を計算し、リーフノードとして格納します。
-
より大きなボックスへのグループ化: 近くのリーフノードをクラスタリングし、各グループを新しい MBR で囲んで内部ノードを形成します。例えば、グループ B は D と E を含み、グループ C は F と G を含みます。
-
ルートノードの追加: すべての内部グループをカバーする MBR を持つルートノードを追加し、高さが平衡なツリー構造を形成します。
フェーズ 2: クエリの高速化
-
クエリ MBR の形成: クエリの幾何オブジェクトの MBR を計算します。
-
ブランチの剪定: ルートから開始し、クエリ MBR を各内部ノードと比較します。クエリ MBR と交差しない MBR を持つブランチはスキップします。
-
候補の収集: 交差するブランチを降りて、候補となるリーフノードを収集します。
-
完全一致: 各候補に対して、厳密な空間述語を実行して真の一致を判定します。
RTREE インデックスの作成
コレクションスキーマで定義された GEOMETRY フィールドに RTREE インデックスを作成できます。
from pymilvus import MilvusClient
client = MilvusClient(uri="YOUR_CLUSTER_ENDPOINT") # Replace with your server address
# Assume you have defined a GEOMETRY field named "geo" in your collection schema
# Prepare index parameters
index_params = client.prepare_index_params()
# Add RTREE index on the "geo" field
index_params.add_index(
field_name="geo",
index_type="RTREE", # Spatial index for GEOMETRY
index_name="rtree_geo", # Optional, name your index
params={} # No extra params needed
)
# Create the index on the collection
client.create_index(
collection_name="geo_demo",
index_params=index_params
)
RTREE を使用したクエリ
filter 式でジオメトリ演算子を使用してフィルタリングします。対象の GEOMETRY フィールドに RTREE が存在する場合、Zilliz Cloud は自動的にこれを使用して候補を剪定します。インデックスがない場合、フィルタはフルスキャンにフォールバックします。
使用可能なジオメトリ固有の演算子の完全なリストについては、ジオメトリ演算子 を参照してください。
例 1: フィルタのみ
指定されたポリゴン内にあるすべてのジオメトリオブジェクトを検索します:
filter_expr = "ST_CONTAINS(geo, 'POLYGON ((0 0, 10 0, 10 10, 0 10, 0 0))')"
res = client.query(
collection_name="geo_demo",
filter=filter_expr,
output_fields=["id", "geo"],
limit=10
)
print(res) # Expected: a list of rows where geo is entirely inside the polygon
例 2: ベクトル検索 + 空間フィルタ
線と交差する最も近いベクトルを検索します:
# Assume you've also created an index on "vec" and loaded the collection.
query_vec = [[0.1, 0.2, 0.3, 0.4, 0.5]]
filter_expr = "ST_INTERSECTS(geo, 'LINESTRING (1 1, 2 2)')"
hits = client.search(
collection_name="geo_demo",
data=query_vec,
limit=5,
filter=filter_expr,
output_fields=["id", "geo"]
)
print(hits) # Expected: top-k by vector similarity among rows whose geo intersects the line
GEOMETRY フィールドの使用方法の詳細については、ジオメトリ フィールド を参照してください。
インデックスを削除する
drop_index() メソッドを使用して、コレクションから既存のインデックスを削除します。
Milvus v2.6.x 互換のクラスタでは、不要になったスカラー インデックスを直接削除できます。事前にコレクションをリリースする必要はありません。
client.drop_index(
collection_name="geo_demo", # Name of the collection
index_name="rtree_geo" # Name of the index to drop
)