検索のためのデータモデル設計
情報検索システム(検索エンジンとも呼ばれます)は、Retrieval-augmented generation (RAG)、画像検索、製品推薦など、さまざまな AI アプリケーションに不可欠です。これらのシステムの核心には、情報を整理、索引付け、取得するための慎重に設計されたデータモデルがあります。
Zilliz Cloud では、コレクションスキーマを通じて検索データモデルを指定でき、非構造化データ、それらの密または疎なベクトル表現、および構造化メタデータを整理できます。テキスト、画像、その他のデータタイプを扱っているかどうかにかかわらず、このハンズオンガイドは、主要なスキーマの概念を理解し、実際に検索データモデルを設計するために役立ちます。
データモデル
検索システムのデータモデル設計には、ビジネスニーズの分析と、情報をスキーマで表現されたデータモデルへ抽象化する作業が含まれます。明確に定義されたスキーマは、データモデルをビジネス目標に整合させ、データの一貫性とサービス品質を確保する上で重要です。さらに、適切なデータタイプとインデックスを選択することは、経済的にビジネス目標を達成するために重要です。
ビジネスニーズの分析
ビジネスニーズに効果的に対応するには、ユーザーが実行するクエリのタイプを分析し、最も適切な検索方法を決定することから始まります。
-
ユーザークエリ: ユーザーが実行すると予想されるクエリのタイプを特定します。これにより、スキーマが実世界のユースケースをサポートし、検索パフォーマンスが最適化されることが保証されます。これらには以下が含まれる可能性があります:
-
自然言語クエリに一致するドキュメントの取得
-
参照画像に類似した画像、またはテキスト記述に一致する画像の発見
-
名前、カテゴリ、ブランドなどの属性による製品の検索
-
構造化メタデータ(例:発行日、タグ、評価)に基づくアイテムのフィルタリング
-
ハイブリッドクエリにおける複数の基準の組み合わせ(例:画像検索において、画像とそのキャプションの両方のセマンティック類似性を考慮する)
-
-
検索方法: ユーザーが実行するクエリのタイプに合致する適切な検索技術を選択します。異なる方法は異なる目的を果たし、より強力な結果を得るために組み合わせて使用できることがよくあります:
-
セマンティック検索: 密ベクトルの類似性を使用して意味が類似したアイテムを見つけます。テキストや画像などの非構造化データに理想的です。
-
全文検索: キーワードマッチングによってセマンティック検索を補完します。全文検索では、長い単語を断片化したトークンに分割することを避けるために形態素解析を利用し、取得時に専門用語を把握することができます。
-
メタデータフィルタリング: ベクトル検索に加えて、日付範囲、カテゴリ、タグなどの制約を適用します。
-
ビジネス要件を検索データモデルに変換する
次のステップは、情報の核心コンポーネントとその検索方法を特定することで、ビジネス要件を具体的なデータモデルに変換することです:
-
保存が必要なデータを定義します。これには、生コンテンツ(テキスト、画像、音声)、関連メタデータ(タイトル、タグ、著者情報)、および文脈属性(タイムスタンプ、ユーザー行動など)が含まれます。
-
各要素に適したデータタイプとフォーマットを決定します。例:
-
テキスト記述 → 文字列
-
画像またはドキュメントの埋め込み → 密ベクトルまたは疎ベクトル
-
カテゴリ、タグ、フラグ → 文字列、配列、および bool
-
価格や評価などの数値属性 → 整数または浮動小数点数
-
著者詳細などの構造化情報 -> json
-
これらの要素を明確に定義することで、データの一貫性、正確な検索結果、下流のアプリケーションロジックとの統合の容易さが保証されます。
スキーマ設計
Zilliz Cloud では、データモデルはコレクションスキーマを通じて表現されます。コレクションスキーマ内で適切なフィールドを設計することは、効果的な検索を可能にする鍵となります。各フィールドはコレクションに保存される特定のデータタイプを定義し、検索プロセスにおいて独自の役割を果たします。大まかに言えば、Zilliz Cloud は 2 つの主要なフィールドタイプをサポートしています:ベクトルフィールドとスカラーフィールドです。
ここで、データモデルをベクトルおよび任意の補助スカラーフィールドを含むフィールドのスキーマにマッピングできます。各フィールドがデータモデルからの属性と相関していることを確認し、特にベクトルタイプ(密または疎)とその次元に注意を払ってください。
ベクトルフィールド
ベクトルフィールドは、テキスト、画像、音声などの非構造化データタイプの埋め込みを保存します。これらの埋め込みは、データタイプと利用される検索方法に応じて、密、疎、またはバイナリである可能性があります。通常、密ベクトルはセマンティック検索に使用され、疎ベクトルは全文検索または語彙的マッチングにより適しています。バイナリベクトルは、ストレージおよび計算リソースが限られている場合に有用です。マルチモーダルまたはハイブリッド検索戦略を有効にするために、コレクションには複数のベクトルフィールドを含めることができます。このトピックに関する詳細なガイドについては、マルチベクトルハイブリッド検索 を参照してください。
Zilliz Cloud は、密ベクトル 用の FLOAT_VECTOR、疎ベクトル 用の SPARSE_FLOAT_VECTOR、および バイナリベクトル 用の BINARY_VECTOR というベクトルデータタイプをサポートしています。
スカラーおよび複合フィールド
スカラーフィールドは、数値、文字列、日付など、メタデータとして一般的に知られているプリミティブで構造化された値を保存します。これらの値はベクトル検索結果と共に返すことができ、フィルタリングおよびソートに不可欠です。これらにより、ドキュメントを特定のカテゴリに限定したり、定義された時間範囲に制限したりするなど、特定の属性に基づいて検索結果を絞り込むことができます。
Zilliz Cloud は、非ベクトルデータの保存とフィルタリングのために、BOOL、INT8/16/32/64、FLOAT、DOUBLE、VARCHAR などのスカラータイプ、および JSON や ARRAY などの複合タイプをサポートしています。これらのタイプは、検索操作の精度とカスタマイズ性を向上させます。
スキーマ設計における高度な機能の活用
スキーマを設計する際、サポートされているデータタイプを使用してデータをフィールドにマッピングするだけでは不十分です。フィールド間の関係と設定に利用可能な戦略を十分に理解することが不可欠です。設計段階で主要な機能を念頭に置くことで、スキーマが即時のデータ処理要件を満たすだけでなく、将来のニーズに対して拡張可能で適応可能であることが保証されます。これらの機能を慎重に統合することで、Zilliz Cloud の機能を最大化し、より広範なデータ戦略と目標をサポートする堅牢なデータアーキテクチャを構築できます。以下は、コレクションスキーマを作成する際の主要な機能の概要です:
プライマリキー
プライマリキーフィールドはスキーマの基本的なコンポーネントであり、コレクション内の各エンティティを一意に識別します。プライマリキーの定義は必須です。これは整数または文字列タイプのスカラーフィールドであり、is_primary=True としてマークされている必要があります。オプションで、プライマリキーに対して auto_id を有効にできます。これにより、より多くのデータがコレクションに取り込まれるにつれて単調に増加する整数が自動的に割り当てられます。
詳細については、プライマリフィールドと AutoID を参照してください。
パーティショニング
検索速度を向上させるために、オプションでパーティショニングを有効にできます。パーティショニング用に特定のスカラーフィールドを指定し、検索中にこのフィールドに基づいてフィルタリング基準を指定することで、検索範囲を関連するパーティションのみに効果的に制限できます。この方法により、検索ドメインを削減することで、検索操作の効率が大幅に向上します。
詳細については、パーティションキーの使用 を参照してください。
アナライザー
アナライザーは、テキストデータを処理および変換するための不可欠なツールです。その主な機能は、生のテキストをトークンに変換し、索引付けと取得のために構造化することです。これは、文字列をトークン化し、ストップワードを削除し、個々の単語をトークンにステミングすることによって行われます。
詳細については、アナライザーの概要 を参照してください。
関数
Zilliz Cloud では、特定のフィールドを自動的に導出するために、スキーマの一部として組み込み関数を定義できます。たとえば、全文検索をサポートするために VARCHAR フィールドから疎ベクトルを生成する組み込みの BM25 関数を追加できます。これらの関数派生フィールドは、前処理を合理化し、コレクションが自己完結型でクエリ対応の状態を維持することを保証します。
詳細については、全文検索 を参照してください。
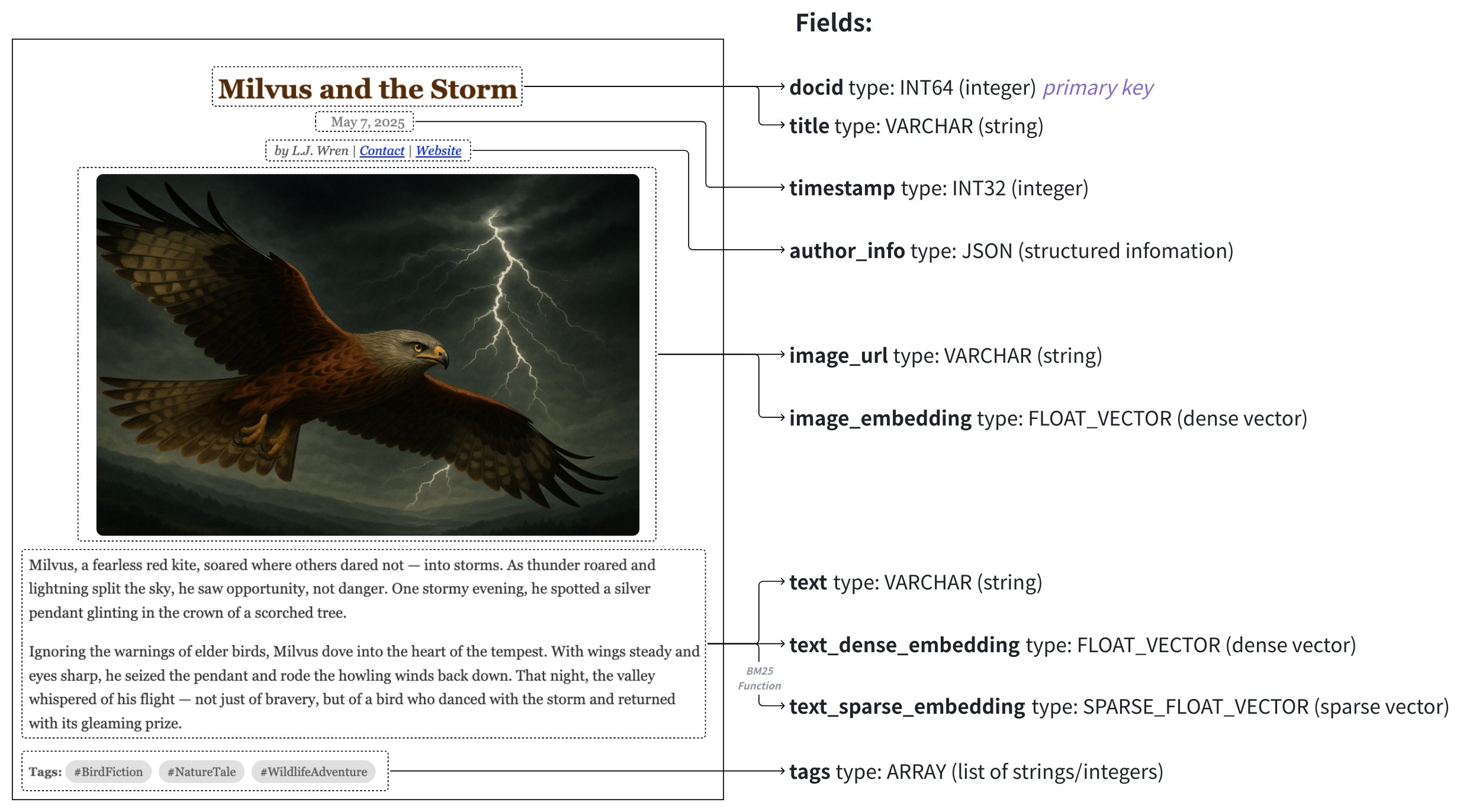
実世界の例
このセクションでは、上記の図に示されているマルチメディアドキュメント検索アプリケーションのスキーマ設計とコード例について説明します。このスキーマは、以下のフィールドにマッピングされるデータを含む記事のデータセットを管理するように設計されています:
フィールド | データソース | 検索方法で使用 | プライマリキー | パーティションキー | アナライザー | 関数の入力/出力 |
|---|---|---|---|---|---|---|
article_id ( |
| Y | N | N | N | |
title ( | 記事のタイトル | N | N | Y | N | |
timestamp ( | 発行日 | N | Y | N | N | |
text ( | 記事の生テキスト | N | N | Y | 入力 | |
text_dense_vector ( | テキスト埋め込みモデルによって生成された密ベクトル | N | N | N | N | |
text_sparse_vector ( | 組み込みの BM25 関数によって自動生成された疎ベクトル | N | N | N | 出力 |
スキーマおよび各種タイプのフィールドを追加するための詳細なガイダンスについては、スキーマの説明 を参照してください。
ステップ 1: スキーマの初期化
まず、空のスキーマを作成する必要があります。このステップは、データモデルを定義するための基盤となる構造を確立します。
- Python
- Java
- NodeJS
- Go
- cURL
from pymilvus import MilvusClient
schema = MilvusClient.create_schema()
import io.milvus.v2.client.ConnectConfig;
import io.milvus.v2.client.MilvusClientV2;
import io.milvus.v2.service.collection.request.CreateCollectionReq;
// 1. Connect to Milvus server
ConnectConfig connectConfig = ConnectConfig.builder()
.uri("YOUR_CLUSTER_ENDPOINT")
.build();
MilvusClientV2 client = new MilvusClientV2(connectConfig);
// 2. Create an empty schema
CreateCollectionReq.CollectionSchema schema = client.createSchema();
import { MilvusClient, DataType } from "@zilliz/milvus2-sdk-node";
//Skip this step using JavaScript
import "github.com/milvus-io/milvus/client/v2/entity"
schema := entity.NewSchema()
# Skip this step using cURL
ステップ 2: フィールドの追加
スキーマが作成されたら、次にデータを構成するフィールドを指定します。各フィールドは、それぞれのデータ型と属性に関連付けられています。
- Python
- Java
- NodeJS
- Go
- cURL
from pymilvus import DataType
schema.add_field(field_name="article_id", datatype=DataType.INT64, is_primary=True, auto_id=True, description="article id")
schema.add_field(field_name="title", datatype=DataType.VARCHAR, enable_analyzer=True, enable_match=True, max_length=200, description="article title")
schema.add_field(field_name="timestamp", datatype=DataType.INT32, description="publish date")
schema.add_field(field_name="text", datatype=DataType.VARCHAR, max_length=2000, enable_analyzer=True, description="article text content")
schema.add_field(field_name="text_dense_vector", datatype=DataType.FLOAT_VECTOR, dim=768, description="text dense vector")
schema.add_field(field_name="text_sparse_vector", datatype=DataType.SPARSE_FLOAT_VECTOR, description="text sparse vector")
import io.milvus.v2.common.DataType;
import io.milvus.v2.service.collection.request.AddFieldReq;
schema.addField(AddFieldReq.builder()
.fieldName("article_id")
.dataType(DataType.Int64)
.isPrimaryKey(true)
.autoID(true)
.build());
schema.addField(AddFieldReq.builder()
.fieldName("title")
.dataType(DataType.VarChar)
.maxLength(200)
.enableAnalyzer(true)
.enableMatch(true)
.build());
schema.addField(AddFieldReq.builder()
.fieldName("timestamp")
.dataType(DataType.Int32)
.build())
schema.addField(AddFieldReq.builder()
.fieldName("text")
.dataType(DataType.VarChar)
.maxLength(2000)
.enableAnalyzer(true)
.build());
schema.addField(AddFieldReq.builder()
.fieldName("text_dense_vector")
.dataType(DataType.FloatVector)
.dimension(768)
.build());
schema.addField(AddFieldReq.builder()
.fieldName("text_sparse_vector")
.dataType(DataType.SparseFloatVector)
.build());
const fields = [
{
name: "article_id",
data_type: DataType.Int64,
is_primary_key: true,
auto_id: true
},
{
name: "title",
data_type: DataType.VarChar,
max_length: 200,
enable_analyzer: true,
enable_match: true
},
{
name: "timestamp",
data_type: DataType.Int32
},
{
name: "text",
data_type: DataType.VarChar,
max_length: 2000,
enable_analyzer: true
},
{
name: "text_dense_vector",
data_type: DataType.FloatVector,
dim: 768
},
{
name: "text_sparse_vector",
data_type: DataType.SparseFloatVector
}
]
schema.WithField(entity.NewField().
WithName("article_id").
WithDataType(entity.FieldTypeInt64).
WithIsPrimaryKey(true).
WithIsAutoID(true).
WithDescription("article id"),
).WithField(entity.NewField().
WithName("title").
WithDataType(entity.FieldTypeVarChar).
WithMaxLength(200).
WithEnableAnalyzer(true).
WithEnableMatch(true).
WithDescription("article title"),
).WithField(entity.NewField().
WithName("timestamp").
WithDataType(entity.FieldTypeInt32).
WithDescription("publish date"),
).WithField(entity.NewField().
WithName("text").
WithDataType(entity.FieldTypeVarChar).
WithMaxLength(2000).
WithEnableAnalyzer(true).
WithDescription("article text content"),
).WithField(entity.NewField().
WithName("text_dense_vector").
WithDataType(entity.FieldTypeFloatVector).
WithDim(768).
WithDescription("text dense vector"),
).WithField(entity.NewField().
WithName("text_sparse_vector").
WithDataType(entity.FieldTypeSparseVector).
WithDescription("text sparse vector"),
)
export fields='[
{
"fieldName": "article_id",
"dataType": "Int64",
"isPrimary": true
},
{
"fieldName": "title",
"dataType": "VarChar",
"elementTypeParams": {
"max_length": 200,
"enable_analyzer": true,
"enable_match": true
}
},
{
"fieldName": "timestamp",
"dataType": "Int32"
},
{
"fieldName": "text",
"dataType": "VarChar",
"elementTypeParams": {
"max_length": 2000,
"enable_analyzer": true
}
},
{
"fieldName": "text_dense_vector",
"dataType": "FloatVector",
"elementTypeParams": {
"dim": 768
}
},
{
"fieldName": "text_sparse_vector",
"dataType": "SparseFloatVector",
}
]'
export schema="{
\"autoID\": true,
\"fields\": $fields
}"
この例では、フィールドに対して以下の属性が指定されています。
-
プライマリキー:
article_idがプライマリキーとして使用され、受信エンティティのプライマリキーを自動的に割り当てることができます。 -
パーティションキー:
timestampがパーティションキーとして割り当てられ、パーティションによるフィルタリングが可能になります。 -
テキストアナライザー:テキストアナライザーが 2 つの文字列フィールド
titleとtextに適用され、それぞれテキスト一致と全文検索をサポートします。
Step 3: (Optional) Add functions
データクエリ機能を強化するために、関数をスキーマに組み込むことができます。たとえば、特定のフィールドに関連する処理を行う関数を作成できます。
- Python
- Java
- NodeJS
- Go
- cURL
from pymilvus import Function, FunctionType
bm25_function = Function(
name="text_bm25",
input_field_names=["text"],
output_field_names=["text_sparse_vector"],
function_type=FunctionType.BM25,
)
schema.add_function(bm25_function)
import io.milvus.common.clientenum.FunctionType;
import io.milvus.v2.service.collection.request.CreateCollectionReq.Function;
import java.util.*;
schema.addFunction(Function.builder()
.functionType(FunctionType.BM25)
.name("text_bm25")
.inputFieldNames(Collections.singletonList("text"))
.outputFieldNames(Collections.singletonList("text_sparse_vector"))
.build());
import FunctionType from "@zilliz/milvus2-sdk-node";
const functions = [
{
name: 'text_bm25',
description: 'bm25 function',
type: FunctionType.BM25,
input_field_names: ['text'],
output_field_names: ['text_sparse_vector'],
params: {},
},
];
function := entity.NewFunction().
WithName("text_bm25").
WithInputFields("text").
WithOutputFields("text_sparse_vector").
WithType(entity.FunctionTypeBM25)
schema.WithFunction(function)
export myFunctions='[
{
"name": "text_bm25",
"type": "BM25",
"inputFieldNames": ["text"],
"outputFieldNames": ["text_sparse_vector"],
"params": {}
}
]'
export schema="{
\"autoID\": true,
\"fields\": $fields
\"functions\": $myFunctions
}"
この例では、スキーマに組み込みの BM25 関数を追加し、text フィールドを入力として使用して、結果の疎ベクトルを text_sparse_vector フィールドに格納します。