配列型構造体を用いたデータモデル設計
現代のAIアプリケーション、特にモノのインターネット(IoT)や自動運転分野では、通常、豊かで構造化されたイベントに対して推論を行います。タイムスタンプとベクトル埋め込みを持つセンサー読み取り値、エラーコードと音声スニペットを持つ診断ログ、または位置、速度、シーンコンテキストを持つトリップセグメントなどです。これらは、データベースがネストされたデータの取り込みと検索をネイティブにサポートすることを要求します。
ユーザーに対して、原子構造のイベントをフラットなデータモデルに変換するよう求めるのではなく、Zilliz Cloud は配列型構造体を導入しました。配列内の各構造体はスカラーとベクトルを保持でき、意味的整合性を維持します。
配列型構造体を使用する理由
自動運転からマルチモーダル検索まで、現代のAIアプリケーションはますますネストされた異種データに依存しています。従来のフラットなデータモデルでは、「1つのドキュメントに多数のアノテーション付きチャンクがある」や「1つの運転シーンに複数の観測された操作がある」といった複雑な関係を表現することが困難です。ここで、Zilliz Cloud の配列型構造体データ型が活躍します。
配列型構造体では、構造化された要素の順序付きセットを保存できます。各構造体は独自のスカラーフィールドとベクトル埋め込みの組み合わせを含みます。これにより、以下の用途に最適です。
-
階層データ: 複数の子レコードを持つ親エンティティ。例えば、多数のテキストチャンクを持つ書籍、または多数のアノテーション付きフレームを持つ動画。
-
マルチモーダル埋め込み: 各構造体は、メタデータとともにテキスト埋め込みと画像埋め込みなど、複数のベクトルを保持できます。
-
時系列データまたはシーケンシャルデータ: 配列フィールド内の構造体は、自然に時系列または段階的なイベントを表現します。
JSON BLOB を保存したり、データを複数のコレクションに分割したりする従来の回避策とは異なり、配列型構造体は Zilliz Cloud 内でネイティブなスキーマ適用、ベクトルインデックス作成、および効率的なストレージを提供します。
スキーマ設計ガイドライン
検索のためのデータモデル設計 で説明されているすべてのガイドラインに加えて、データモデル設計で配列型構造体の使用を開始する前に、以下の事項も考慮する必要があります。
構造体スキーマの定義
コレクションに配列フィールドを追加する前に、内部の構造体スキーマを定義します。構造体内の各フィールドは、スカラー(VARCHAR、INT、BOOLEAN など)またはベクトル(FLOAT_VECTOR)として明示的に型指定する必要があります。
検索または表示に使用するフィールドのみを含めることで、構造体スキーマを簡潔に保つことをお勧めします。未使用のメタデータで肥大化させないでください。
最大容量を慎重に設定する
各配列フィールドには、各エンティティに対して配列フィールドが保持できる最大要素数を指定する属性があります。これはユースケースの上限に基づいて設定します。例えば、ドキュメントあたり1,000のテキストチャンク、または運転シーンあたり100の操作などです。
過度に高い値はメモリを浪費し、配列フィールド内の構造体の最大数を決定するためにいくつかの計算が必要になります。
構造体内のベクトルフィールドのインデックス作成
インデックス作成は、コレクション内のベクトルフィールドと構造体内で定義されたベクトルフィールドの両方に対して必須です。構造体内のベクトルフィールドには、インデックスタイプとして AUTOINDEX、メトリックタイプとして MAX_SIM シリーズを使用する必要があります。
適用可能なすべての制限の詳細については、制限事項 を参照してください。
実世界の例: 自動運転のための CoVLA データセットのモデリング
Turing Motors によって導入され、Winter Conference on アプリケーション of Computer Vision (WACV) 2025 で採択された包括的ビジョン・言語・アクション(CoVLA)データセットは、自動運転におけるビジョン・言語・アクション(VLA)モデルのトレーニングと評価のための豊かな基盤を提供します。通常は動画クリップである各データポイントには、生の視覚入力だけでなく、以下を記述する構造化されたキャプションも含まれます。
-
自車両の挙動(例:「対向車を譲りながら左に合流」)
-
存在する検出されたオブジェクト(例:先行車両、歩行者、交通信号)、および
-
シーンのフレームレベルキャプション。
この階層的でマルチモーダルな性質により、配列型構造体機能の理想的な候補となっています。CoVLA データセットの詳細については、CoVLA データセット Website を参照してください。
ステップ1: データセットをコレクションスキーマにマッピングする
CoVLA データセットは、10,000の動画クリップ、合計80時間以上の映像から構成される大規模なマルチモーダル運転データセットです。20Hzのレートでフレームをサンプリングし、各フレームに詳細な自然言語キャプションと、車両状態および検出されたオブジェクトの座標に関する情報をアノテーションしています。
データセットの構造は以下の通りです。
├── video_1 (VIDEO) # video.mp4
│ ├── video_id (INT)
│ ├── video_url (STRING)
│ ├── frames (ARRAY)
│ │ ├── frame_1 (STRUCT)
│ │ │ ├── caption (STRUCT) # captions.jsonl
│ │ │ │ ├── plain_caption (STRING)
│ │ │ │ ├── rich_caption (STRING)
│ │ │ │ ├── risk (STRING)
│ │ │ │ ├── risk_correct (BOOL)
│ │ │ │ ├── risk_yes_rate (FLOAT)
│ │ │ │ ├── weather (STRING)
│ │ │ │ ├── weather_rate (FLOAT)
│ │ │ │ ├── road (STRING)
│ │ │ │ ├── road_rate (FLOAT)
│ │ │ │ ├── is_tunnel (BOOL)
│ │ │ │ ├── is_tunnel_yes_rate (FLOAT)
│ │ │ │ ├── is_highway (BOOL)
│ │ │ │ ├── is_highway_yes_rate (FLOAT)
│ │ │ │ ├── has_pedestrain (BOOL)
│ │ │ │ ├── has_pedestrain_yes_rate (FLOAT)
│ │ │ │ ├── has_carrier_car (BOOL)
│ │ │ ├── traffic_light (STRUCT) # traffic_lights.jsonl
│ │ │ │ ├── index (INT)
│ │ │ │ ├── class (STRING)
│ │ │ │ ├── bbox (LIST<FLOAT>)
│ │ │ ├── front_car (STRUCT) # front_cars.jsonl
│ │ │ │ ├── has_lead (BOOL)
│ │ │ │ ├── lead_prob (FLOAT)
│ │ │ │ ├── lead_x (FLOAT)
│ │ │ │ ├── lead_y (FLOAT)
│ │ │ │ ├── lead_speed_kmh (FLOAT)
│ │ │ │ ├── lead_a (FLOAT)
│ │ ├── frame_2 (STRUCT)
│ │ ├── ... (STRUCT)
│ │ ├── frame_n (STRUCT)
├── video_2
├── ...
├── video_n
CoVLA データセットの構造は高度に階層化されており、収集されたデータが複数の .jsonl ファイルに分割され、ビデオクリップは .mp4 形式で保存されていることがわかります。
Zilliz Cloud では、コレクションスキーマ内にネストされた構造を作成するために、JSON フィールドまたは 配列-of-構造体s フィールドのいずれかを使用できます。ベクトル埋め込みがネストされた形式の一部である場合、配列-of-構造体s フィールドのみがサポートされます。ただし、配列 内の 構造体 は、それ自体がさらにネストされた構造を含むことはできません。CoVLA データセットを保存しながら本質的な関係性を保持するには、不要な階層を削除し、データをフラット化して Zilliz Cloud のコレクションスキーマに適合させる必要があります。
以下の図は、このデータセットを次のスキーマを使用してモデリングする方法を示しています:
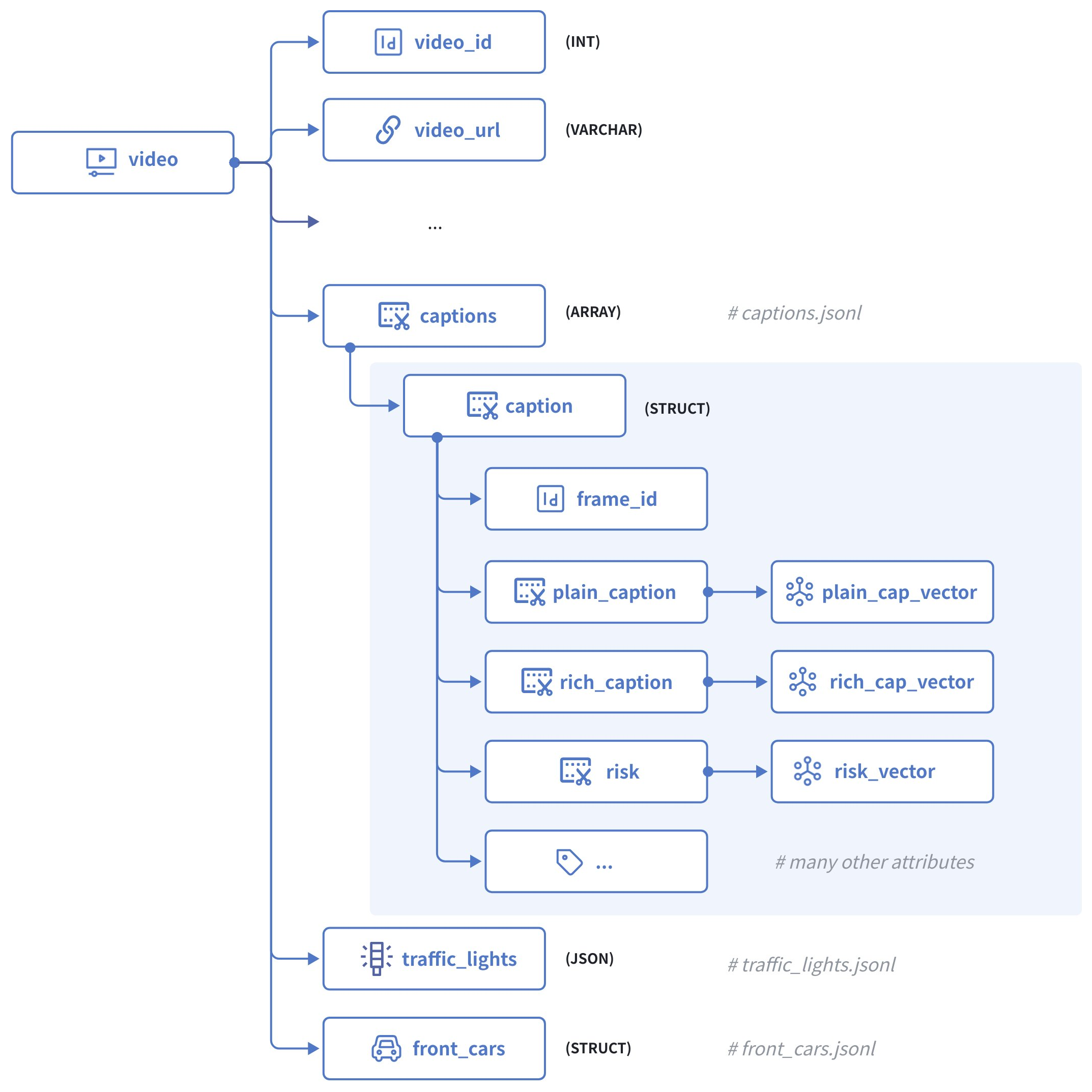
上記の図は、ビデオクリップの構造を示しており、以下のフィールドで構成されています:
-
video_idは主キーとして機能し、INT64 型の整数を受け入れます。 -
statesは、現在のビデオの各フレームにおけるエゴ車両の状態を含む生の JSON ボディです。 -
captionsは構造体の配列であり、各構造体は以下のフィールドを持ちます:-
frame_idは、現在のビデオ内の特定のフレームを識別します。 -
plain_captionは、天候や道路状況などの周囲環境を含まない現在のフレームの説明であり、plain_cap_vectorはそれに対応するベクトル埋め込みです。 -
rich_captionは、周囲環境を含む現在のフレームの説明であり、rich_cap_vectorはそれに対応するベクトル埋め込みです。 -
riskは、現在のフレームにおいてエゴ車両が直面するリスクの説明であり、risk_vectorはそれに対応するベクトル埋め込みです。 -
その他のフレーム属性すべて、例えば
road、weather、is_tunnel、has_pedestrainなど。
-
-
traffic_lightsは、現在のフレームで識別されたすべての交通信号を含む JSON ボディです。 -
front_carsは、現在のフレームで識別されたすべての先行車を含む構造体の配列でもあります。
Step 2: Initialize the schemas
まず、キャプション構造体、front_cars 構造体、およびコレクションのスキーマを初期化する必要があります。
-
キャプション構造体のスキーマを初期化します。
client = MilvusClient("YOUR_CLUSTER_ENDPOINT")# create the schema for the caption structschema_for_caption = client.create_struct_field_schema()schema_for_caption.add_field(field_name="frame_id",datatype=DataType.INT64,description="ID of the frame to which the ego vehicle's behavior belongs")schema_for_caption.add_field(field_name="plain_caption",datatype=DataType.VARCHAR,max_length=1024,description="plain description of the ego vehicle's behaviors")schema_for_caption.add_field(field_name="plain_cap_vector",datatype=DataType.FLOAT_VECTOR,dim=768,description="vectors for the plain description of the ego vehicle's behaviors")schema_for_caption.add_field(field_name="rich_caption",datatype=DataType.VARCHAR,max_length=1024,description="rich description of the ego vehicle's behaviors")schema_for_caption.add_field(field_name="rich_cap_vector",datatype=DataType.FLOAT_VECTOR,dim=768,description="vectors for the rich description of the ego vehicle's behaviors")schema_for_caption.add_field(field_name="risk",datatype=DataType.VARCHAR,max_length=1024,description="description of the ego vehicle's risks")schema_for_caption.add_field(field_name="risk_vector",datatype=DataType.FLOAT_VECTOR,dim=768,description="vectors for the description of the ego vehicle's risks")schema_for_caption.add_field(field_name="risk_correct",datatype=DataType.BOOL,description="whether the risk assessment is correct")schema_for_caption.add_field(field_name="risk_yes_rate",datatype=DataType.FLOAT,description="probability/confidence of risk being present")schema_for_caption.add_field(field_name="weather",datatype=DataType.VARCHAR,max_length=50,description="weather condition")schema_for_caption.add_field(field_name="weather_rate",datatype=DataType.FLOAT,description="probability/confidence of the weather condition")schema_for_caption.add_field(field_name="road",datatype=DataType.VARCHAR,max_length=50,description="road type")schema_for_caption.add_field(field_name="road_rate",datatype=DataType.FLOAT,description="probability/confidence of the road type")schema_for_caption.add_field(field_name="is_tunnel",datatype=DataType.BOOL,description="whether the road is a tunnel")schema_for_caption.add_field(field_name="is_tunnel_yes_rate",datatype=DataType.FLOAT,description="probability/confidence of the road being a tunnel")schema_for_caption.add_field(field_name="is_highway",datatype=DataType.BOOL,description="whether the road is a highway")schema_for_caption.add_field(field_name="is_highway_yes_rate",datatype=DataType.FLOAT,description="probability/confidence of the road being a highway")schema_for_caption.add_field(field_name="has_pedestrian",datatype=DataType.BOOL,description="whether there is a pedestrian present")schema_for_caption.add_field(field_name="has_pedestrian_yes_rate",datatype=DataType.FLOAT,description="probability/confidence of pedestrian presence")schema_for_caption.add_field(field_name="has_carrier_car",datatype=DataType.BOOL,description="whether there is a carrier car present") -
Front Car 構造体のスキーマを初期化します
📘Notesフロントカーにはベクトル埋め込みが含まれませんが、データサイズが JSON フィールドの最大値を超えるため、構造体 の配列として含める必要があります。
schema_for_front_car = client.create_struct_field_schema()schema_for_front_car.add_field(field_name="frame_id",datatype=DataType.INT64,description="ID of the frame to which the ego vehicle's behavior belongs")schema_for_front_car.add_field(field_name="has_lead",datatype=DataType.BOOL,description="whether there is a leading vehicle")schema_for_front_car.add_field(field_name="lead_prob",datatype=DataType.FLOAT,description="probability/confidence of the leading vehicle's presence")schema_for_front_car.add_field(field_name="lead_x",datatype=DataType.FLOAT,description="x position of the leading vehicle relative to the ego vehicle")schema_for_front_car.add_field(field_name="lead_y",datatype=DataType.FLOAT,description="y position of the leading vehicle relative to the ego vehicle")schema_for_front_car.add_field(field_name="lead_speed_kmh",datatype=DataType.FLOAT,description="speed of the leading vehicle in km/h")schema_for_front_car.add_field(field_name="lead_a",datatype=DataType.FLOAT,description="acceleration of the leading vehicle") -
コレクションのスキーマを初期化する
schema = client.create_schema()schema.add_field(field_name="video_id",datatype=DataType.VARCHAR,description="primary key",max_length=16,is_primary=True,auto_id=False)schema.add_field(field_name="video_url",datatype=DataType.VARCHAR,max_length=512,description="URL of the video")schema.add_field(field_name="captions",datatype=DataType.ARRAY,element_type=DataType.STRUCT,struct_schema=schema_for_caption,max_capacity=600,description="captions for the current video")schema.add_field(field_name="traffic_lights",datatype=DataType.JSON,description="frame-specific traffic lights identified in the current video")schema.add_field(field_name="front_cars",datatype=DataType.ARRAY,element_type=DataType.STRUCT,struct_schema=schema_for_front_car,max_capacity=600,description="frame-specific leading cars identified in the current video")
Step 3: Set index parameters
すべてのベクトルフィールドはインデックスを作成する必要があります。要素構造体(構造体)内のベクトルフィールドをインデックスするには、インデックスタイプとして AUTOINDEX を使用し、埋め込みリスト間の類似度を測定するために MAX_SIM シリーズのメトリックタイプを使用する必要があります。
index_params = client.prepare_index_params()
index_params.add_index(
field_name="captions[plain_cap_vector]",
index_type="AUTOINDEX",
metric_type="MAX_SIM_COSINE",
index_name="captions_plain_cap_vector_idx", # mandatory for now
index_params={"M": 16, "efConstruction": 200}
)
index_params.add_index(
field_name="captions[rich_cap_vector]",
index_type="AUTOINDEX",
metric_type="MAX_SIM_COSINE",
index_name="captions_rich_cap_vector_idx", # mandatory for now
index_params={"M": 16, "efConstruction": 200}
)
index_params.add_index(
field_name="captions[risk_vector]",
index_type="AUTOINDEX",
metric_type="MAX_SIM_COSINE",
index_name="captions_risk_vector_idx", # mandatory for now
index_params={"M": 16, "efConstruction": 200}
)
JSONフィールド内でフィルタリングを高速化するには、JSONフィールドに対してJSONシュレッディングを有効にすることをお勧めします。
Step 4: Create a collection
スキーマとインデックスの準備が完了したら、次のようにして対象のコレクションを作成できます。
client.create_collection(
collection_name="covla_dataset",
schema=schema,
index_params=index_params
)
ステップ 5: データの挿入
Turing Motos は、CoVLA データセットを複数のファイルに分けて整理しています。これには、生のビデオクリップ(.mp4)、状態(states.jsonl)、キャプション(captions.jsonl)、信号機(traffic_lights.jsonl)、前方車両(front_cars.jsonl)が含まれます。
これらのファイルから各ビデオクリップに対応するデータ片をマージし、データを挿入する必要があります。以下は、特定のビデオクリップについてデータ片をマージするスクリプトです。
import json
from openai import OpenAI
openai_client = OpenAI(
api_key='YOUR_OPENAI_API_KEY',
)
video_id = "0a0fc7a5db365174" # represent a single video with 600 frames
# get all front car records in the specified video clip
entries = []
front_cars = []
with open('data/front_car/{}.jsonl'.format(video_id), 'r') as f:
for line in f:
entries.append(json.loads(line))
for entry in entries:
for key, value in entry.items():
value['frame_id'] = int(key)
front_cars.append(value)
# get all traffic lights identified in the specified video clip
entries = []
traffic_lights = []
frame_id = 0
with open('data/traffic_lights/{}.jsonl'.format(video_id), 'r') as f:
for line in f:
entries.append(json.loads(line))
for entry in entries:
for key, value in entry.items():
if not value or (value['index'] == 1 and key != '0'):
frame_id+=1
if value:
value['frame_id'] = frame_id
traffic_lights.append(value)
else:
value_dict = {}
value_dict['frame_id'] = frame_id
traffic_lights.append(value_dict)
# get all captions generated in the video clip and convert them into vector embeddings
entries = []
captions = []
with open('data/captions/{}.jsonl'.format(video_id), 'r') as f:
for line in f:
entries.append(json.loads(line))
def get_embedding(text, model="embeddinggemma:latest"):
response = openai_client.embeddings.create(input=text, model=model)
return response.data[0].embedding
# Add embeddings to each entry
for entry in entries:
# Each entry is a dict with a single key (e.g., '0', '1', ...)
for key, value in entry.items():
value['frame_id'] = int(key) # Convert key to integer and assign to frame_id
if "plain_caption" in value and value["plain_caption"]:
value["plain_cap_vector"] = get_embedding(value["plain_caption"])
if "rich_caption" in value and value["rich_caption"]:
value["rich_cap_vector"] = get_embedding(value["rich_caption"])
if "risk" in value and value["risk"]:
value["risk_vector"] = get_embedding(value["risk"])
captions.append(value)
data = {
"video_id": video_id,
"video_url": "https://your-storage.com/{}".format(video_id),
"captions": captions,
"traffic_lights": traffic_lights,
"front_cars": front_cars
}
データを適切に処理したら、次のように挿入できます。
client.insert(
collection_name="covla_dataset",
data=[data]
)
# {'insert_count': 1, 'ids': ['0a0fc7a5db365174'], 'cost': 0}