Zilliz Cloud のテキスト一致は、特定の用語に基づいて正確なドキュメント検索を可能にします。この機能は主に、特定の条件を満たすフィルタリング検索に使用され、スカラー フィルタリングを組み込むことでクエリ結果を絞り込むことができ、スカラー条件を満たすベクトル内での類似性検索を可能にします。
テキスト一致は、クエリ用語の正確な出現を見つけることに焦点を当てており、一致したドキュメントの関連性をスコアリングしません。クエリ用語のセマンティックな意味と重要度に基づいて最も関連性の高いドキュメントを取得したい場合は、フルテキスト検索の使用をお勧めします。
Zilliz Cloud では、プログラムによる方法または Web コンソールを介してテキスト一致を有効化できます。このページでは、プログラムによる方法でのテキスト一致の有効化について説明します。Web コンソールでの操作の詳細については、コレクションの管理(コンソール) を参照してください。
概要
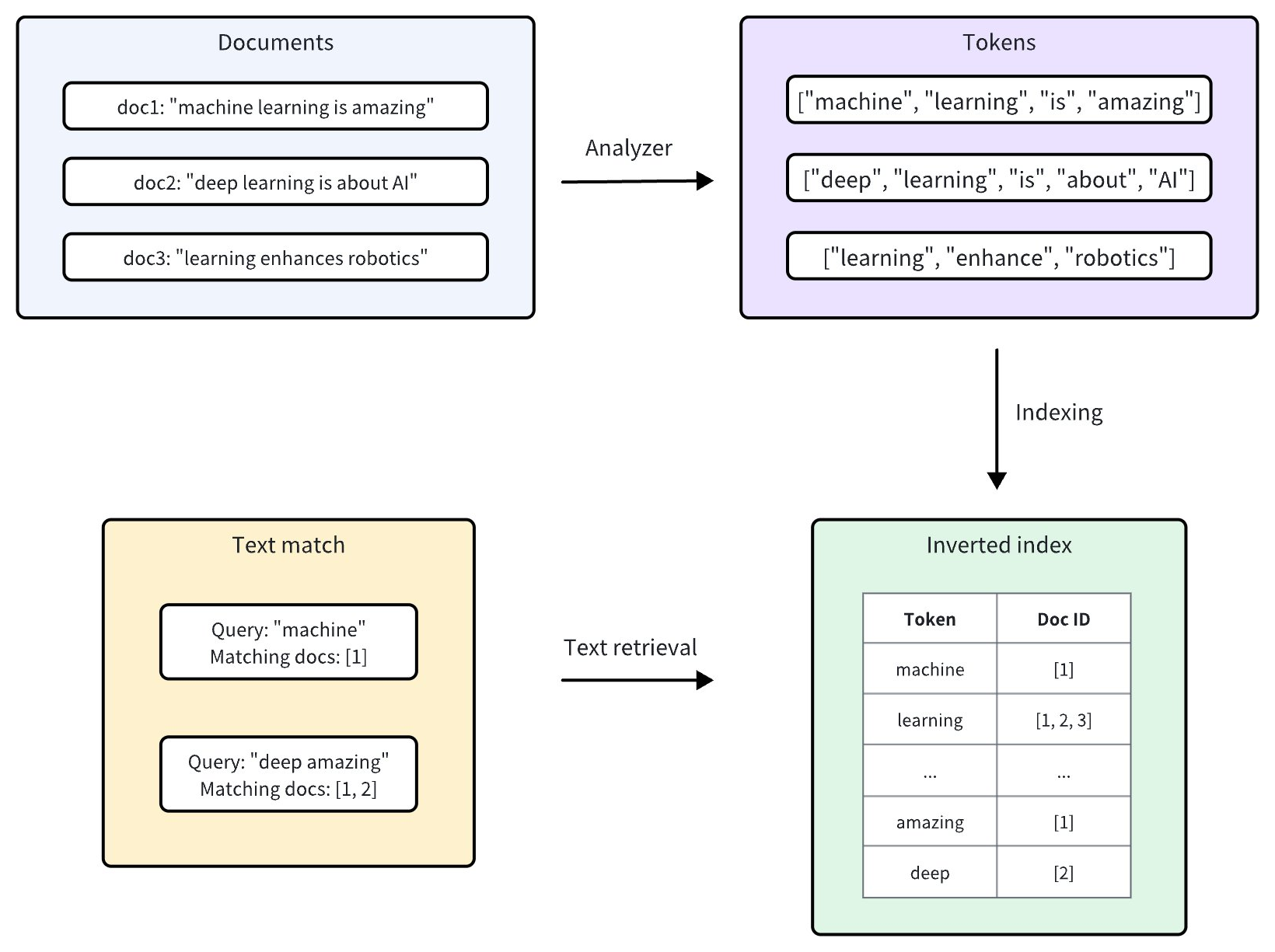
Zilliz Cloud は Tantivy を統合し、その基盤となる転置インデックスと用語ベースのテキスト検索を実現しています。各テキストエントリに対して、Zilliz Cloud は以下の手順でインデックスを作成します。
-
Analyzer: アナライザーは、入力テキストを個別の単語(トークン)にトークン化し、必要に応じてフィルターを適用することで処理します。これにより、Zilliz Cloud はこれらのトークンに基づいてインデックスを構築できます。
-
インデックス作成: テキスト分析後、Zilliz Cloud は各一意のトークンをそれを含むドキュメントにマッピングする転置インデックスを作成します。
ユーザーがテキスト一致を実行すると、転置インデックスを使用して、用語を含むすべてのドキュメントを迅速に取得できます。これは、各ドキュメントを個別にスキャンするよりもはるかに高速です。
テキスト一致の有効化
テキスト一致は、Zilliz Cloud で基本的に文字列データ型である VARCHAR フィールド型で動作します。テキスト一致を有効にするには、コレクション スキーマの定義時に enable_analyzer と enable_match の両方を True に設定し、オプションでテキスト分析用の アナライザー を構成します。
enable_analyzer と enable_match の設定
特定の VARCHAR フィールドでテキスト一致を有効にするには、フィールド スキーマの定義時に enable_analyzer パラメーターと enable_match パラメーターの両方を True に設定します。これにより、Zilliz Cloud はテキストをトークン化し、指定されたフィールドの転置インデックスを作成するよう指示され、高速で効率的なテキスト一致が可能になります。
- Python
- Java
- Go
- NodeJS
- cURL
from pymilvus import MilvusClient, DataType
schema = MilvusClient.create_schema(enable_dynamic_field=False)
schema.add_field(
field_name="id",
datatype=DataType.INT64,
is_primary=True,
auto_id=True
)
schema.add_field(
field_name='text',
datatype=DataType.VARCHAR,
max_length=1000,
enable_analyzer=True, # Whether to enable text analysis for this field
enable_match=True # Whether to enable text match
)
schema.add_field(
field_name="embeddings",
datatype=DataType.FLOAT_VECTOR,
dim=5
)
import io.milvus.v2.common.DataType;
import io.milvus.v2.service.collection.request.AddFieldReq;
import io.milvus.v2.service.collection.request.CreateCollectionReq;
CreateCollectionReq.CollectionSchema schema = CreateCollectionReq.CollectionSchema.builder()
.enableDynamicField(false)
.build();
schema.addField(AddFieldReq.builder()
.fieldName("id")
.dataType(DataType.Int64)
.isPrimaryKey(true)
.autoID(true)
.build());
schema.addField(AddFieldReq.builder()
.fieldName("text")
.dataType(DataType.VarChar)
.maxLength(1000)
.enableAnalyzer(true)
.enableMatch(true)
.build());
schema.addField(AddFieldReq.builder()
.fieldName("embeddings")
.dataType(DataType.FloatVector)
.dimension(5)
.build());
import "github.com/milvus-io/milvus/client/v2/entity"
schema := entity.NewSchema().WithDynamicFieldEnabled(false)
schema.WithField(entity.NewField().
WithName("id").
WithDataType(entity.FieldTypeInt64).
WithIsPrimaryKey(true).
WithIsAutoID(true),
).WithField(entity.NewField().
WithName("text").
WithDataType(entity.FieldTypeVarChar).
WithEnableAnalyzer(true).
WithEnableMatch(true).
WithMaxLength(1000),
).WithField(entity.NewField().
WithName("embeddings").
WithDataType(entity.FieldTypeFloatVector).
WithDim(5),
)
const schema = [
{
name: "id",
data_type: DataType.Int64,
is_primary_key: true,
},
{
name: "text",
data_type: "VarChar",
enable_analyzer: true,
enable_match: true,
max_length: 1000,
},
{
name: "embeddings",
data_type: DataType.FloatVector,
dim: 5,
},
];
export schema='{
"autoId": true,
"enabledDynamicField": false,
"fields": [
{
"fieldName": "id",
"dataType": "Int64",
"isPrimary": true
},
{
"fieldName": "text",
"dataType": "VarChar",
"elementTypeParams": {
"max_length": 1000,
"enable_analyzer": true,
"enable_match": true
}
},
{
"fieldName": "embeddings",
"dataType": "FloatVector",
"elementTypeParams": {
"dim": "5"
}
}
]
}'
オプション: アナライザーの設定
キーワードマッチングのパフォーマンスと精度は、選択したアナライザーに依存します。異なるアナライザーは、さまざまな言語やテキスト構造に最適化されているため、ユースケースに適したアナライザーを選択することで、検索結果に大きな影響を与えることができます。
デフォルトでは、Zilliz Cloud は standard アナライザーを使用します。このアナライザーは、空白と句読点に基づいてテキストをトークン化し、40文字を超えるトークンを削除し、テキストを小文字に変換します。このデフォルト設定を適用するために追加のパラメーターは必要ありません。詳細については、Standard を参照してください。
別のアナライザーが必要な場合は、analyzer_params パラメーターを使用してアナライザーを設定できます。たとえば、英語テキストの処理に english アナライザーを適用する場合:
- Python
- Java
- Go
- NodeJS
- cURL
analyzer_params = {
"type": "english"
}
schema.add_field(
field_name='text',
datatype=DataType.VARCHAR,
max_length=200,
enable_analyzer=True,
analyzer_params = analyzer_params,
enable_match = True,
)
Map<String, Object> analyzerParams = new HashMap<>();
analyzerParams.put("type", "english");
schema.addField(AddFieldReq.builder()
.fieldName("text")
.dataType(DataType.VarChar)
.maxLength(200)
.enableAnalyzer(true)
.analyzerParams(analyzerParams)
.enableMatch(true)
.build());
analyzerParams := map[string]any{"type": "english"}
schema.WithField(entity.NewField().
WithName("text").
WithDataType(entity.FieldTypeVarChar).
WithEnableAnalyzer(true).
WithEnableMatch(true).
WithAnalyzerParams(analyzerParams).
WithMaxLength(200),
)
const schema = [
{
name: "id",
data_type: DataType.Int64,
is_primary_key: true,
},
{
name: "text",
data_type: "VarChar",
enable_analyzer: true,
enable_match: true,
max_length: 1000,
analyzer_params: { type: 'english' },
},
{
name: "embeddings",
data_type: DataType.FloatVector,
dim: 5,
},
];
export schema='{
"autoId": true,
"enabledDynamicField": false,
"fields": [
{
"fieldName": "id",
"dataType": "Int64",
"isPrimary": true
},
{
"fieldName": "text",
"dataType": "VarChar",
"elementTypeParams": {
"max_length": 200,
"enable_analyzer": true,
"enable_match": true,
"analyzer_params": {"type": "english"}
}
},
{
"fieldName": "embeddings",
"dataType": "FloatVector",
"elementTypeParams": {
"dim": "5"
}
}
]
}'
Zilliz Cloud では、さまざまな言語やシナリオに適したその他の分析器も提供しています。詳細については、Analyzer Overview を参照してください。
テキスト一致を使用する
コレクションスキーマで VARCHAR フィールドのテキスト一致を有効にすると、TEXT_MATCH 式を使用してテキスト一致を実行できます。
TEXT_MATCH 式の構文
TEXT_MATCH 式は、検索対象のフィールドと用語を指定するために使用されます。その構文は以下のとおりです。
TEXT_MATCH(field_name, text)
-
field_name: 検索対象となる VARCHAR フィールドの名前。 -
text: 検索する語句。複数の語句は、スペースまたは言語と設定されたアナライザーに基づく適切な区切り文字で分離できます。
デフォルトでは、TEXT_MATCH は OR マッチングロジックを使用します。つまり、指定された語句のいずれかを含むドキュメントが返されます。たとえば、text フィールドに machine または deep を含むドキュメントを検索するには、次の式を使用します:
- Python
- Java
- Go
- NodeJS
- cURL
filter = "TEXT_MATCH(text, 'machine deep')"
String filter = "TEXT_MATCH(text, 'machine deep')";
filter := "TEXT_MATCH(text, 'machine deep')"
const filter = "TEXT_MATCH(text, 'machine deep')";
export filter="\"TEXT_MATCH(text, 'machine deep')\""
論理演算子を使用して複数の TEXT_MATCH 式を組み合わせ、AND マッチングを実行することもできます。
-
textフィールドにmachineとdeepの両方を含むドキュメントを検索するには、次の式を使用します:- Python
- Java
- Go
- NodeJS
- cURL
filter = "TEXT_MATCH(text, 'machine') and TEXT_MATCH(text, 'deep')"String filter = "TEXT_MATCH(text, 'machine') and TEXT_MATCH(text, 'deep')";filter := "TEXT_MATCH(text, 'machine') and TEXT_MATCH(text, 'deep')"const filter = "TEXT_MATCH(text, 'machine') and TEXT_MATCH(text, 'deep')"export filter="\"TEXT_MATCH(text, 'machine') and TEXT_MATCH(text, 'deep')\"" -
textフィールド内でmachineおよびlearningを含み、かつdeepを含まないドキュメントを検索するには、次の式を使用します:- Python
- Java
- Go
- NodeJS
- cURL
filter = "not TEXT_MATCH(text, 'deep') and TEXT_MATCH(text, 'machine') and TEXT_MATCH(text, 'learning')"String filter = "not TEXT_MATCH(text, 'deep') and TEXT_MATCH(text, 'machine') and TEXT_MATCH(text, 'learning')";filter := "not TEXT_MATCH(text, 'deep') and TEXT_MATCH(text, 'machine') and TEXT_MATCH(text, 'learning')"const filter = "not TEXT_MATCH(text, 'deep') and TEXT_MATCH(text, 'machine') and TEXT_MATCH(text, 'learning')";export filter="\"not TEXT_MATCH(text, 'deep') and TEXT_MATCH(text, 'machine') and TEXT_MATCH(text, 'learning')\""
テキスト一致による検索
テキスト一致は、ベクトル類似性検索と組み合わせて使用することで、検索範囲を絞り込み、検索パフォーマンスを向上させることができます。ベクトル類似性検索の前にテキスト一致でコレクションをフィルタリングすることで、検索対象となるドキュメント数を削減し、クエリの実行時間を短縮できます。
この例では、filter 式により、指定された用語 keyword1 または keyword2 に一致するドキュメントのみが検索結果に含まれるようにフィルタリングされます。その後、このフィルタリングされたドキュメントのサブセットに対してベクトル類似性検索が実行されます。
- Python
- Java
- Go
- NodeJS
- cURL
# Match entities with \`keyword1\` or \`keyword2\`
filter = "TEXT_MATCH(text, 'keyword1 keyword2')"
# Assuming 'embeddings' is the vector field and 'text' is the VARCHAR field
result = client.search(
collection_name="my_collection", # Your collection name
anns_field="embeddings", # Vector field name
data=[query_vector], # Query vector
filter=filter,
search_params={"params": {"nprobe": 10}},
limit=10, # Max. number of results to return
output_fields=["id", "text"] # Fields to return
)
String filter = "TEXT_MATCH(text, 'keyword1 keyword2')";
SearchResp searchResp = client.search(SearchReq.builder()
.collectionName("my_collection")
.annsField("embeddings")
.data(Collections.singletonList(queryVector)))
.filter(filter)
.topK(10)
.outputFields(Arrays.asList("id", "text"))
.build());
filter := "TEXT_MATCH(text, 'keyword1 keyword2')"
resultSets, err := client.Search(ctx, milvusclient.NewSearchOption(
"my_collection", // collectionName
10, // limit
[]entity.Vector{entity.FloatVector(queryVector)},
).WithANNSField("embeddings").
WithFilter(filter).
WithOutputFields("id", "text"))
if err != nil {
fmt.Println(err.Error())
// handle error
}
// Match entities with \`keyword1\` or \`keyword2\`
const filter = "TEXT_MATCH(text, 'keyword1 keyword2')";
// Assuming 'embeddings' is the vector field and 'text' is the VARCHAR field
const result = await client.search(
collection_name: "my_collection", // Your collection name
anns_field: "embeddings", // Vector field name
data: [query_vector], // Query vector
filter: filter,
params: {"nprobe": 10},
limit: 10, // Max. number of results to return
output_fields: ["id", "text"] //Fields to return
);
export filter="\"TEXT_MATCH(text, 'keyword1 keyword2')\""
export CLUSTER_ENDPOINT="YOUR_CLUSTER_ENDPOINT"
export TOKEN="YOUR_CLUSTER_TOKEN"
curl --request POST \
--url "${CLUSTER_ENDPOINT}/v2/vectordb/entities/search" \
--header "Authorization: Bearer ${TOKEN}" \
--header "Content-Type: application/json" \
-d '{
"collectionName": "my_collection",
"annsField": "embeddings",
"data": [[0.19886812562848388, 0.06023560599112088, 0.6976963061752597, 0.2614474506242501, 0.838729485096104]],
"filter": '"$filter"',
"searchParams": {
"params": {
"nprobe": 10
}
},
"limit": 10,
"outputFields": ["text","id"]
}'
Query with テキスト一致
テキスト一致は、クエリ操作におけるスカラーフィルタリングにも使用できます。query() メソッドの expr パラメータに TEXT_MATCH 式を指定することで、指定された用語に一致するドキュメントを取得できます。
以下の例では、text フィールドに keyword1 と keyword2 の両方の用語が含まれるドキュメントを取得します。
- Python
- Java
- Go
- NodeJS
- cURL
# Match entities with both \`keyword1\` and \`keyword2\`
filter = "TEXT_MATCH(text, 'keyword1') and TEXT_MATCH(text, 'keyword2')"
result = client.query(
collection_name="my_collection",
filter=filter,
output_fields=["id", "text"]
)
String filter = "TEXT_MATCH(text, 'keyword1') and TEXT_MATCH(text, 'keyword2')";
QueryResp queryResp = client.query(QueryReq.builder()
.collectionName("my_collection")
.filter(filter)
.outputFields(Arrays.asList("id", "text"))
.build()
);
filter = "TEXT_MATCH(text, 'keyword1') and TEXT_MATCH(text, 'keyword2')"
resultSet, err := client.Query(ctx, milvusclient.NewQueryOption("my_collection").
WithFilter(filter).
WithOutputFields("id", "text"))
if err != nil {
fmt.Println(err.Error())
// handle error
}
// Match entities with both \`keyword1\` and \`keyword2\`
const filter = "TEXT_MATCH(text, 'keyword1') and TEXT_MATCH(text, 'keyword2')";
const result = await client.query(
collection_name: "my_collection",
filter: filter,
output_fields: ["id", "text"]
)
export filter="\"TEXT_MATCH(text, 'keyword1') and TEXT_MATCH(text, 'keyword2')\""
export CLUSTER_ENDPOINT="YOUR_CLUSTER_ENDPOINT"
export TOKEN="YOUR_CLUSTER_TOKEN"
curl --request POST \
--url "${CLUSTER_ENDPOINT}/v2/vectordb/entities/query" \
--header "Authorization: Bearer ${TOKEN}" \
--header "Content-Type: application/json" \
-d '{
"collectionName": "my_collection",
"filter": '"$filter"',
"outputFields": ["id", "text"]
}'
Considerations
-
フィールドに対して用語マッチングを有効にすると、転置インデックスが作成され、ストレージリソースを消費します。この機能を有効にするかどうかを決定する際は、テキストのサイズ、固有のトークン数、使用されるアナライザーによって異なるストレージへの影響を考慮してください。
-
スキーマでアナライザーを定義 once すると、その設定は該当のコレクションに対して永続的になります。別のアナライザーの方がニーズに適していると判断した場合は、既存のコレクションを削除し、希望のアナライザー構成で新しいコレクションを作成することを検討してください。
-
filter式におけるエスケープ規則:-
式内で二重引用符または単一引用符で囲まれた文字は文字列定数として解釈されます。文字列定数にエスケープ文字が含まれる場合、エスケープ文字はエスケープシーケンスで表現する必要があります。例えば、
\を表すには\\を、タブ\tを表すには\\tを、改行を表すには\\nを使用します。 -
文字列定数が単一引用符で囲まれている場合、定数内の単一引用符は
\\'として表現する必要があり、二重引用符は"または\\"のいずれかで表現できます。例:'It\\'s milvus' -
文字列定数が二重引用符で囲まれている場合、定数内の二重引用符は
\\"として表現する必要があり、単一引用符は'または\\'のいずれかで表現できます。例:"He said \\"Hi\\""
-