エンティティのアップサート
upsert 操作は、コレクションにエンティティを挿入または更新する便利な方法を提供します。
概要
upsert を使用して、新しいエンティティを挿入するか既存のエンティティを更新するかは、アップサートリクエストで提供された主キーがコレクションに存在するかどうかによって決まります。主キーが見つからない場合は、挿入操作が実行されます。それ以外の場合は、更新操作が実行されます。
アップサートリクエストは、挿入と削除を組み合わせたものです。既存のエンティティに対する upsert リクエストを受信すると、Zilliz Cloud はリクエストペイロードに含まれるデータを挿入し、同時にデータに指定された元の主キーを持つ既存のエンティティを削除します。
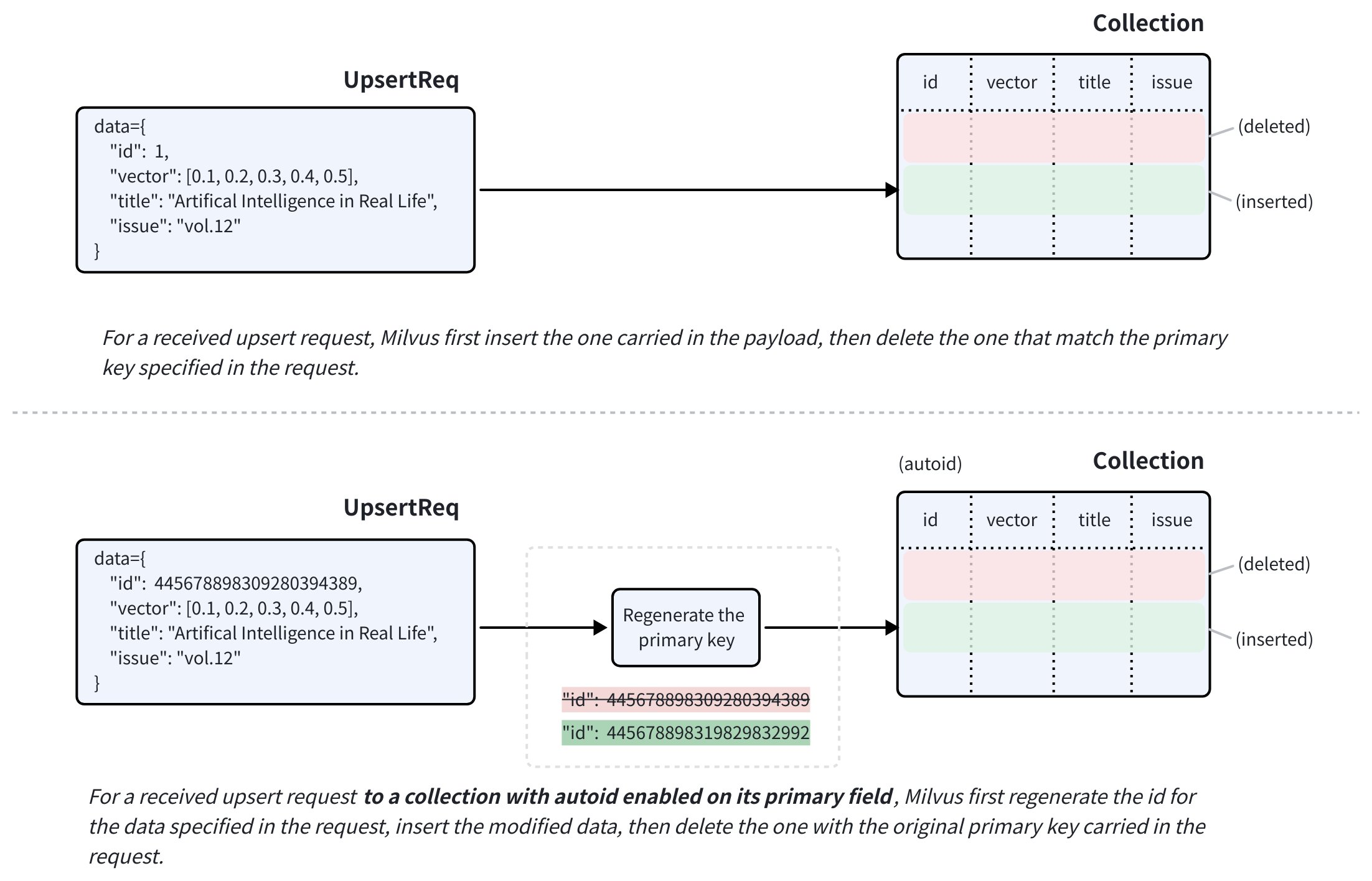
対象のコレクションで主フィールドに autoid が有効になっている場合、Zilliz Cloud は挿入前にリクエストペイロードに含まれるデータ用に新しい主キーを生成します。
nullable が有効になっているフィールドについては、更新が不要な場合は upsert リクエストで省略できます。
マージモードでの Upsert
partial_update フラグを使用して、アップサートリクエストをマージモードで動作させることもできます。これにより、リクエストペイロードに更新が必要なフィールドのみを含めることができます。
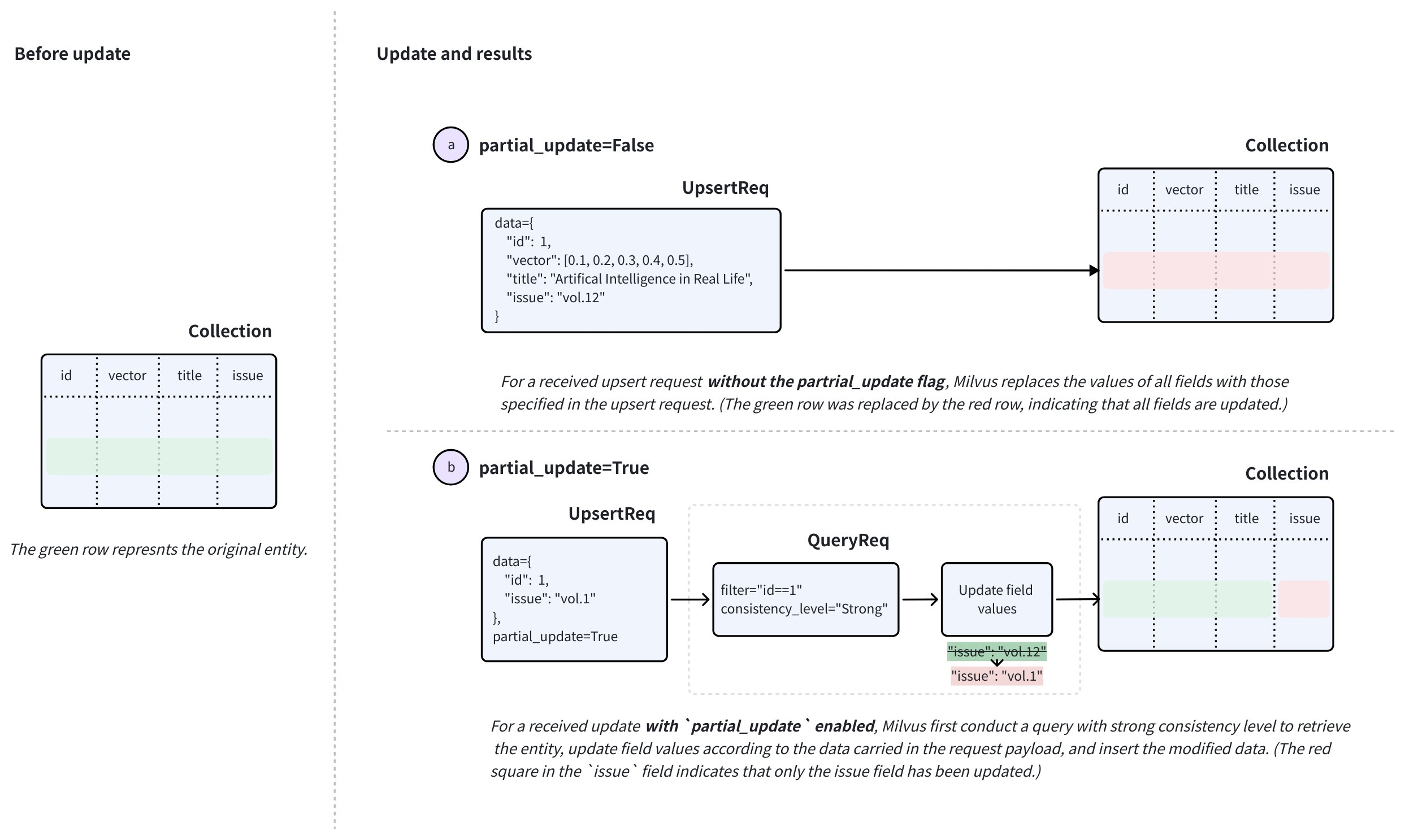
マージを実行するには、upsert リクエストで partial_update を True に設定し、主キーと新しい値で更新するフィールドを指定します。
このようなリクエストを受信すると、Zilliz Cloud は強い一貫性でクエリを実行してエンティティを取得し、リクエスト内のデータに基づいてフィールド値を更新し、変更されたデータを挿入してから、リクエストに含まれる元の主キーを持つ既存のエンティティを削除します。
フィールド値の更新
既存のエンティティのフィールド値を更新するには、マージモードでの upsert を使用します。このモードでは、リクエストに含まれるフィールドのみが更新され、他のすべてのフィールドは既存の値を保持します。
Upsert の動作: 特記事項
マージ機能を使用する前に考慮すべき特記事項がいくつかあります。以下のケースでは、title と issue という2つのスカラーフィールド、主キー id、および vector というベクトルフィールドを持つコレクションがあることを前提としています。
-
nullableが有効になっているフィールドのアップサートissueフィールドが null になりうると仮定します。これらのフィールドをアップサートする際、以下に注意してください:-
upsertリクエストでissueフィールドを省略し、partial_updateを無効にした場合、issueフィールドは元の値を保持するのではなくnullに更新されます。 -
issueフィールドの元の値を保持するには、partial_updateを有効にしてissueフィールドを省略するか、upsertリクエストに元の値を含めてissueフィールドを含める必要があります。
-
-
動的フィールド内のキーのアップサート
例のコレクションで動的キーが有効になっており、エンティティの動的フィールド内のキーと値のペアが
{"author": "John", "year": 2020, "tags": ["fiction"]}のようなものであると仮定します。author、year、tagsなどのキーでエンティティをアップサートする場合、または他のキーを追加する場合、以下に注意してください:-
partial_updateを無効にしてアップサートする場合、デフォルトの動作は 上書き です。これは、動的フィールドの値が、リクエストに含まれるすべてのスキーマ定義外のフィールドとその値によって上書きされることを意味します。例えば、リクエストに含まれるデータが
{"author": "Jane", "genre": "fantasy"}の場合、対象エンティティの動的フィールド内のキーと値のペアはそれに更新されます。 -
partial_updateを有効にしてアップサートする場合、デフォルトの動作は マージ です。これは、動的フィールドの値が、リクエストに含まれるすべてのスキーマ定義外のフィールドとその値とマージされることを意味します。例えば、リクエストに含まれるデータが
{"author": "John", "year": 2020, "tags": ["fiction"]}の場合、アップサート後、対象エンティティの動的フィールド内のキーと値のペアは{"author": "John", "year": 2020, "tags": ["fiction"], "genre": "fantasy"}になります。
-
-
JSON フィールドのアップサート
例のコレクションに
extrasというスキーマ定義の JSON フィールドがあり、この JSON フィールド内のキーと値のペアが{"author": "John", "year": 2020, "tags": ["fiction"]}のようなものであると仮定します。変更された JSON データでエンティティの
extrasフィールドをアップサートする場合、JSON フィールドは全体として扱われ、個別のキーを選択的に更新することはできないことに注意してください。言い換えれば、JSON フィールドは マージ モードのアップサートをサポートしません。
制限と制約
上記の内容に基づき、以下の制限と制約に従う必要があります:
-
upsertリクエストには、常に対象エンティティの主キーを含める必要があります。 -
対象のコレクションはロードされており、クエリが利用可能な状態である必要があります。
-
リクエストで指定されたすべてのフィールドは、対象コレクションのスキーマに存在する必要があります。
-
リクエストで指定されたすべてのフィールドの値は、スキーマで定義されたデータ型と一致する必要があります。
-
関数を使用して別のフィールドから派生したフィールドについて、Zilliz Cloud はアップサート時に派生フィールドを削除して再計算を可能にします。
コレクション内のエンティティのアップサート
このセクションでは、my_collection という名前のコレクションにエンティティをアップサートします。このコレクションには id、vector、title、issue という4つのフィールドがあります。id フィールドは主フィールドであり、title と issue フィールドはスカラーフィールドです。
コレクションに存在する場合、3つのエンティティはアップサートリクエストに含まれるものによって上書きされます。
- Python
- Java
- NodeJS
- Go
- cURL
from pymilvus import MilvusClient
client = MilvusClient(
uri="YOUR_CLUSTER_ENDPOINT",
token="YOUR_CLUSTER_TOKEN"
)
data=[
{
"id": 0,
"vector": [-0.619954382375778, 0.4479436794798608, -0.17493894838751745, -0.4248030059917294, -0.8648452746018911],
"title": "Artificial Intelligence in Real Life",
"issue": "vol.12"
}, {
"id": 1,
"vector": [0.4762662251462588, -0.6942502138717026, -0.4490002642657902, -0.628696575798281, 0.9660395877041965],
"title": "Hollow Man",
"issue": "vol.19"
}, {
"id": 2,
"vector": [-0.8864122635045097, 0.9260170474445351, 0.801326976181461, 0.6383943392381306, 0.7563037341572827],
"title": "Treasure Hunt in Missouri",
"issue": "vol.12"
}
]
res = client.upsert(
collection_name='my_collection',
data=data
)
print(res)
# Output
# {'upsert_count': 3}
import com.google.gson.Gson;
import com.google.gson.JsonObject;
import io.milvus.v2.client.ConnectConfig;
import io.milvus.v2.client.MilvusClientV2;
import io.milvus.v2.service.vector.request.UpsertReq;
import io.milvus.v2.service.vector.response.UpsertResp;
import java.util.*;
MilvusClientV2 client = new MilvusClientV2(ConnectConfig.builder()
.uri("YOUR_CLUSTER_ENDPOINT")
.token("YOUR_CLUSTER_TOKEN")
.build());
Gson gson = new Gson();
List<JsonObject> data = Arrays.asList(
gson.fromJson("{\"id\": 0, \"vector\": [-0.619954382375778, 0.4479436794798608, -0.17493894838751745, -0.4248030059917294, -0.8648452746018911], \"title\": \"Artificial Intelligence in Real Life\", \"issue\": \"\vol.12\"}", JsonObject.class),
gson.fromJson("{\"id\": 1, \"vector\": [0.4762662251462588, -0.6942502138717026, -0.4490002642657902, -0.628696575798281, 0.9660395877041965], \"title\": \"Hollow Man\", \"issue\": \"vol.19\"}", JsonObject.class),
gson.fromJson("{\"id\": 2, \"vector\": [-0.8864122635045097, 0.9260170474445351, 0.801326976181461, 0.6383943392381306, 0.7563037341572827], \"title\": \"Treasure Hunt in Missouri\", \"issue\": \"vol.12\"}", JsonObject.class),
);
UpsertReq upsertReq = UpsertReq.builder()
.collectionName("my_collection")
.data(data)
.build();
UpsertResp upsertResp = client.upsert(upsertReq);
System.out.println(upsertResp);
// Output:
//
// UpsertResp(upsertCnt=3)
const { MilvusClient, DataType } = require("@zilliz/milvus2-sdk-node")
const address = "YOUR_CLUSTER_ENDPOINT";
const token = "YOUR_CLUSTER_TOKEN";
const client = new MilvusClient({address, token});
data = [
{id: 0, vector: [-0.619954382375778, 0.4479436794798608, -0.17493894838751745, -0.4248030059917294, -0.8648452746018911], title: "Artificial Intelligence in Real Life", issue: "vol.12"},
{id: 1, vector: [0.4762662251462588, -0.6942502138717026, -0.4490002642657902, -0.628696575798281, 0.9660395877041965], title: "Hollow Man", issue: "vol.19"},
{id: 2, vector: [-0.8864122635045097, 0.9260170474445351, 0.801326976181461, 0.6383943392381306, 0.7563037341572827], title: "Treasure Hunt in Missouri", issue: "vol.12"},
]
res = await client.upsert({
collection_name: "my_collection",
data: data,
})
console.log(res.upsert_cnt)
// Output
//
// 3
//
import (
"context"
"fmt"
"github.com/milvus-io/milvus/client/v2/column"
"github.com/milvus-io/milvus/client/v2/milvusclient"
)
ctx, cancel := context.WithCancel(context.Background())
defer cancel()
milvusAddr := "YOUR_CLUSTER_ENDPOINT"
client, err := milvusclient.New(ctx, &milvusclient.ClientConfig{
Address: milvusAddr,
})
if err != nil {
fmt.Println(err.Error())
// handle error
}
defer client.Close(ctx)
titleColumn := column.NewColumnString("title", []string{
"Artificial Intelligence in Real Life", "Hollow Man", "Treasure Hunt in Missouri",
})
issueColumn := column.NewColumnString("issue", []string{
"vol.12", "vol.19", "vol.12"
})
_, err = client.Upsert(ctx, milvusclient.NewColumnBasedInsertOption("my_collection").
WithInt64Column("id", []int64{0, 1, 2, 3, 4, 5, 6, 7, 8, 9}).
WithFloatVectorColumn("vector", 5, [][]float32{
{0.3580376395471989, -0.6023495712049978, 0.18414012509913835, -0.26286205330961354, 0.9029438446296592},
{0.19886812562848388, 0.06023560599112088, 0.6976963061752597, 0.2614474506242501, 0.838729485096104},
{0.43742130801983836, -0.5597502546264526, 0.6457887650909682, 0.7894058910881185, 0.20785793220625592},
}).
WithColumns(titleColumn, issueColumn),
)
if err != nil {
fmt.Println(err.Error())
// handle err
}
export CLUSTER_ENDPOINT="YOUR_CLUSTER_ENDPOINT"
export TOKEN="YOUR_CLUSTER_TOKEN"
curl --request POST \
--url "${CLUSTER_ENDPOINT}/v2/vectordb/entities/upsert" \
--header "Authorization: Bearer ${TOKEN}" \
--header "Content-Type: application/json" \
-d '{
"data": [
{"id": 0, "vector": [0.3580376395471989, -0.6023495712049978, 0.18414012509913835, -0.26286205330961354, 0.9029438446296592], "title": "Artificial Intelligence in Real Life", "issue": "vol.12"},
{"id": 1, "vector": [0.19886812562848388, 0.06023560599112088, 0.6976963061752597, 0.2614474506242501, 0.838729485096104], "title": "Hollow Man", "issue": "vol.19"},
{"id": 2, "vector": [0.43742130801983836, -0.5597502546264526, 0.6457887650909682, 0.7894058910881185, 0.20785793220625592], "title": "Treasure Hunt in Missouri", "issue": "vol.12"},
],
"collectionName": "my_collection"
}'
# {
# "code": 0,
# "data": {
# "upsertCount": 3,
# "upsertIds": [
# 0,
# 1,
# 2,
# ]
# }
# }
パーティション内のエンティティをアップサートする
指定されたパーティションにエンティティをアップサートすることもできます。以下のコードスニペットは、コレクション内に PartitionA という名前のパーティションが存在することを前提としています。
該当パーティション内に既存のエンティティが存在する場合、リクエストに含まれるエンティティによって上書きされます。
- Python
- Java
- NodeJS
- Go
- cURL
data=[
{
"id": 10,
"vector": [0.06998888224297328, 0.8582816610326578, -0.9657938677934292, 0.6527905683627726, -0.8668460657158576],
"title": "Layour Design Reference",
"issue": "vol.34"
},
{
"id": 11,
"vector": [0.6060703043917468, -0.3765080534566074, -0.7710758854987239, 0.36993888322346136, 0.5507513364206531],
"title": "Doraemon and His Friends",
"issue": "vol.2"
},
{
"id": 12,
"vector": [-0.9041813104515337, -0.9610546012461163, 0.20033003106083358, 0.11842506351635174, 0.8327356724591011],
"title": "Pikkachu and Pokemon",
"issue": "vol.12"
},
]
res = client.upsert(
collection_name="my_collection",
data=data,
partition_name="partitionA"
)
print(res)
# Output
# {'upsert_count': 3}
import io.milvus.v2.service.vector.request.UpsertReq;
import io.milvus.v2.service.vector.response.UpsertResp;
Gson gson = new Gson();
List<JsonObject> data = Arrays.asList(
gson.fromJson("{\"id\": 10, \"vector\": [0.06998888224297328, 0.8582816610326578, -0.9657938677934292, 0.6527905683627726, -0.8668460657158576], \"title\": \"Layour Design Reference\", \"issue\": \"vol.34\"}", JsonObject.class),
gson.fromJson("{\"id\": 11, \"vector\": [0.6060703043917468, -0.3765080534566074, -0.7710758854987239, 0.36993888322346136, 0.5507513364206531], \"title\": \"Doraemon and His Friends\", \"issue\": \"vol.2\"}", JsonObject.class),
gson.fromJson("{\"id\": 12, \"vector\": [-0.9041813104515337, -0.9610546012461163, 0.20033003106083358, 0.11842506351635174, 0.8327356724591011], \"title\": \"Pikkachu and Pokemon\", \"issue\": \"vol.12\"}", JsonObject.class),
);
UpsertReq upsertReq = UpsertReq.builder()
.collectionName("my_collection")
.partitionName("partitionA")
.data(data)
.build();
UpsertResp upsertResp = client.upsert(upsertReq);
System.out.println(upsertResp);
// Output:
//
// UpsertResp(upsertCnt=3)
const { MilvusClient, DataType } = require("@zilliz/milvus2-sdk-node")
// 6. Upsert data in partitions
data = [
{id: 10, vector: [0.06998888224297328, 0.8582816610326578, -0.9657938677934292, 0.6527905683627726, -0.8668460657158576], title: "Layour Design Reference", issue: "vol.34"},
{id: 11, vector: [0.6060703043917468, -0.3765080534566074, -0.7710758854987239, 0.36993888322346136, 0.5507513364206531], title: "Doraemon and His Friends", issue: "vol.2"},
{id: 12, vector: [-0.9041813104515337, -0.9610546012461163, 0.20033003106083358, 0.11842506351635174, 0.8327356724591011], title: "Pikkachu and Pokemon", issue: "vol.12"},
]
res = await client.upsert({
collection_name: "my_collection",
data: data,
partition_name: "partitionA"
})
console.log(res.upsert_cnt)
// Output
//
// 3
//
titleColumn = column.NewColumnString("title", []string{
"Layour Design Reference", "Doraemon and His Friends", "Pikkachu and Pokemon",
})
issueColumn = column.NewColumnString("issue", []string{
"vol.34", "vol.2", "vol.12",
})
_, err = client.Upsert(ctx, milvusclient.NewColumnBasedInsertOption("my_collection").
WithPartition("partitionA").
WithInt64Column("id", []int64{10, 11, 12, 13, 14, 15, 16, 17, 18, 19}).
WithFloatVectorColumn("vector", 5, [][]float32{
{0.3580376395471989, -0.6023495712049978, 0.18414012509913835, -0.26286205330961354, 0.9029438446296592},
{0.19886812562848388, 0.06023560599112088, 0.6976963061752597, 0.2614474506242501, 0.838729485096104},
{0.43742130801983836, -0.5597502546264526, 0.6457887650909682, 0.7894058910881185, 0.20785793220625592},
}).
WithColumns(titleColumn, issueColumn),
)
if err != nil {
fmt.Println(err.Error())
// handle err
}
export CLUSTER_ENDPOINT="YOUR_CLUSTER_ENDPOINT"
export TOKEN="YOUR_CLUSTER_TOKEN"
curl --request POST \
--url "${CLUSTER_ENDPOINT}/v2/vectordb/entities/upsert" \
--header "Authorization: Bearer ${TOKEN}" \
--header "Content-Type: application/json" \
-d '{
"data": [
{"id": 10, "vector": [0.06998888224297328, 0.8582816610326578, -0.9657938677934292, 0.6527905683627726, -0.8668460657158576], "title": "Layour Design Reference", "issue": "vol.34"},
{"id": 11, "vector": [0.6060703043917468, -0.3765080534566074, -0.7710758854987239, 0.36993888322346136, 0.5507513364206531], "title": "Doraemon and His Friends", "issue": "vol.2"},
{"id": 12, "vector": [-0.9041813104515337, -0.9610546012461163, 0.20033003106083358, 0.11842506351635174, 0.8327356724591011], "title": "Pikkachu and Pokemon", "issue": "vol.12"},
],
"collectionName": "my_collection",
"partitionName": "partitionA"
}'
# {
# "code": 0,
# "data": {
# "upsertCount": 3,
# "upsertIds": [
# 10,
# 11,
# 12,
# ]
# }
# }
マージモードでエンティティをアップサートする
以下のコード例は、部分的な更新(partial updates)を伴うエンティティのアップサート方法を示しています。更新が必要なフィールドとその新しい値のみを提供し、明示的に部分更新フラグを指定します。
以下の例では、アップサートリクエストで指定されたエンティティの issue フィールドが、リクエストに含まれる値に更新されます。
マージモードでアップサートを実行する際は、リクエストに関与するエンティティが同一のフィールドセットを持つことを確認してください。たとえば、以下のコードスニペットのように2つ以上のエンティティをアップサートする場合、エラーを防ぎデータの整合性を維持するために、それらが同一のフィールドを含んでいることが重要です。
- Python
- Java
- Go
- NodeJS
- cURL
data=[
{
"id": 1,
"issue": "vol.14"
},
{
"id": 2,
"issue": "vol.7"
}
]
res = client.upsert(
collection_name="my_collection",
data=data,
partial_update=True
)
print(res)
# Output
# {'upsert_count': 2}
JsonObject row1 = new JsonObject();
row1.addProperty("id", 1);
row1.addProperty("issue", "vol.14");
JsonObject row2 = new JsonObject();
row2.addProperty("id", 2);
row2.addProperty("issue", "vol.7");
UpsertReq upsertReq = UpsertReq.builder()
.collectionName("my_collection")
.data(Arrays.asList(row1, row2))
.partialUpdate(true)
.build();
UpsertResp upsertResp = client.upsert(upsertReq);
System.out.println(upsertResp);
// Output:
//
// UpsertResp(upsertCnt=2)
pkColumn := column.NewColumnInt64("id", []int64{1, 2})
issueColumn = column.NewColumnString("issue", []string{
"vol.17", "vol.7",
})
_, err = client.Upsert(ctx, milvusclient.NewColumnBasedInsertOption("my_collection").
WithColumns(pkColumn, issueColumn).
WithPartialUpdate(true),
)
if err != nil {
fmt.Println(err.Error())
// handle err
}
const data=[
{
"id": 1,
"issue": "vol.14"
},
{
"id": 2,
"issue": "vol.7"
}
];
const res = await client.upsert({
collection_name: "my_collection",
data,
partial_update: true
});
console.log(res)
// Output
//
// 2
//
export CLUSTER_ENDPOINT="YOUR_CLUSTER_ENDPOINT"
export TOKEN="YOUR_CLUSTER_TOKEN"
export COLLECTION_NAME="my_collection"
export UPSERT_DATA='[
{
"id": 1,
"issue": "vol.14"
},
{
"id": 2,
"issue": "vol.7"
}
]'
curl -X POST "YOUR_CLUSTER_ENDPOINT/v2/vectordb/entities/upsert" \
-H "Content-Type: application/json" \
-H "Authorization: Bearer ${TOKEN}" \
-d "{
\"collectionName\": \"${COLLECTION_NAME}\",
\"data\": ${UPSERT_DATA},
\"partialUpdate\": true
}"
# {
# "code": 0,
# "data": {
# "upsertCount": 2,
# "upsertIds": [
# 3,
# 12,
# ]
# }
# }