mmap の使用
メモリマッピング(Mmap)は、ディスク上の大容量ファイルへの直接メモリアクセスを可能にし、Zilliz Cloud がインデックスとデータをメモリとハードドライブの両方に保存できるようにします。このアプローチにより、アクセス頻度に基づいてデータ配置ポリシーを最適化し、検索パフォーマンスに影響を与えることなくコレクションのストレージ容量を拡張できます。このページでは、Zilliz Cloud が mmap を使用して高速で効率的なデータの保存と取得を実現する方法について説明します。
異なるプランを持つソースクラスターとターゲットクラスター間でデータを移行または復元する場合、ソースコレクションの mmap 設定はターゲットクラスターに移行されません。ターゲットクラスターで mmap 設定を手動で再構成してください。
Zilliz Cloud では、プログラムによる方法または Web コンソールを介して mmap 設定を構成できます。このページでは、プログラムによる mmap の設定方法に焦点を当てています。Web コンソールでの操作の詳細については、コレクションの管理(コンソール) を参照してください。
概要
Zilliz Cloud はコレクションを使用してベクトル埋め込みとそのメタデータを整理し、コレクション内の各行はエンティティを表します。下図の左側に示すように、ベクトルフィールドにはベクトル埋め込みが保存され、スカラーフィールドにはそのメタデータが保存されます。特定のフィールドにインデックスを作成し、コレクションをロードすると、Zilliz Cloud は作成されたインデックスとすべてのフィールドの生データをメモリにロードします。
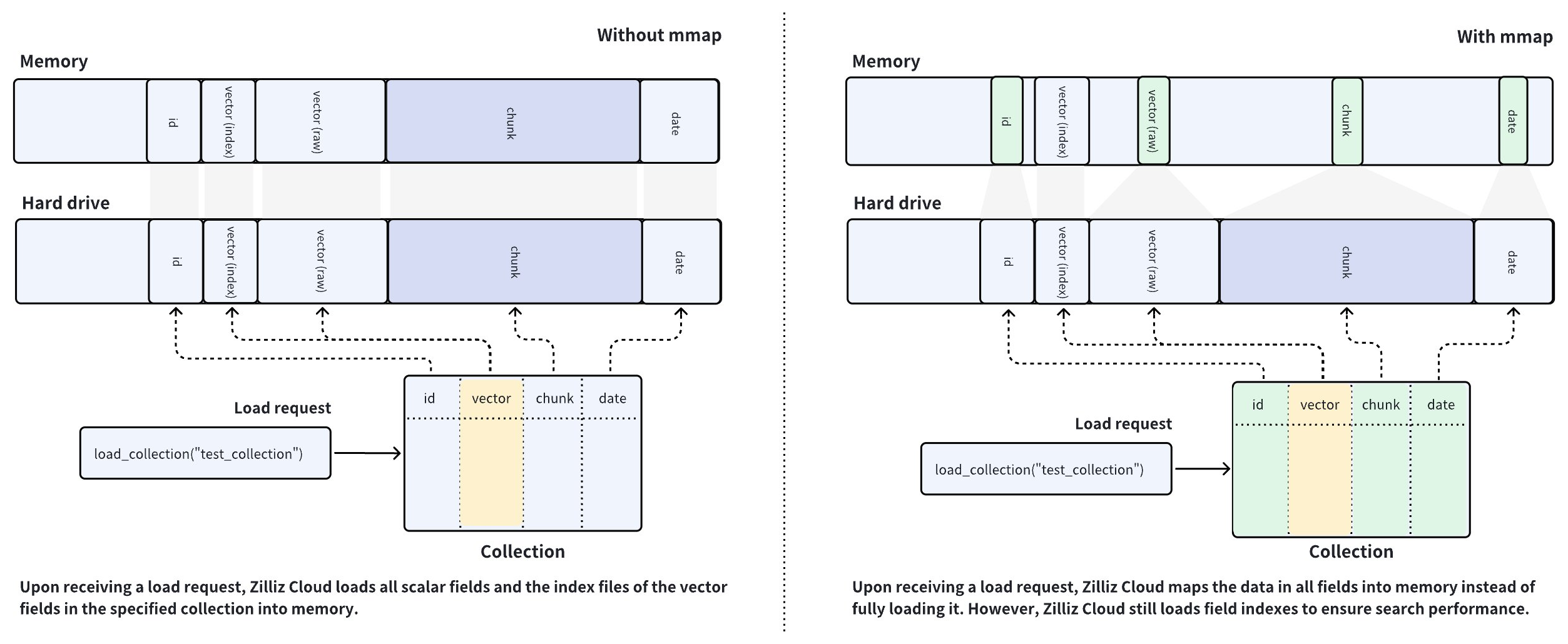
Zilliz Cloud クラスターはメモリ集約型のデータベースシステムであり、利用可能なメモリサイズがコレクションの容量を決定します。大量のデータを含むフィールドをメモリにロードすることは、データサイズがメモリ容量を超える場合には不可能であり、これは AI 駆動型アプリケーションでは通常のケースです。
このような問題を解決するために、Zilliz Cloud はコレクション内のホットデータとコールドデータのロードをバランスさせる mmap を導入しました。上図の右側に示すように、容量最適化済み CU を使用する Zilliz Cloud クラスターでは、コレクションをロードする際にベクトルインデックスのみをメモリにロードし、すべてのフィールドの生データとスカラーインデックスをメモリマッピングします。
左図と右図のデータ配置手順を比較すると、左図の方がメモリ使用量がはるかに高いことがわかります。mmap を有効にすると、メモリにロードされるべきデータがハードドライブにオフロードされ、オペレーティングシステムのページキャッシュにキャッシュされるため、メモリフットプリントが削減されます。ただし、キャッシュミスが発生するとパフォーマンスが低下する可能性があります。詳細については、この記事 を参照してください。
グローバル mmap 戦略
次の表は、異なるティアのクラスターに対するグローバル mmap 戦略を示しています。
パフォーマンス最適化済み | 容量最適化済み | 階層型ストレージ | |
|---|---|---|---|
スカラーフィールドの生データ | 無効 & 変更可能 | 有効 & 変更可能 | 有効 & 変更不可 |
スカラーフィールドのインデックス | 無効 & 変更可能 | 有効 & 変更可能 | 有効 & 変更不可 |
ベクトルフィールドの生データ | 有効 & 変更可能 | 有効 & 変更可能 | 有効 & 変更不可 |
ベクトルフィールドのインデックス | 無効 & 変更不可 | 無効 & 変更不可 | 有効 & 変更不可 |
パフォーマンス最適化済み CU を使用するクラスターでは、Zilliz Cloud はベクトルフィールドの生データに対してのみ mmap を有効にし、スカラーフィールドの生データとすべてのフィールドインデックスをメモリにロードします。検索およびクエリ時のメタデータフィルタリングと取得のパフォーマンスを確保するために、グローバル設定を維持することをお勧めします。ただし、メタデータフィルタリングに関与しないフィールドまたは出力フィールドとして使用されるフィールドに対しては、引き続き mmap を有効にすることができます。
容量最適化済み CU を使用するクラスターでは、Zilliz Cloud は自動インデックス作成のためにベクトルフィールドのインデックスに対して mmap を無効にし、スカラーフィールドのインデックスとすべてのフィールドの生データをメモリマッピングして、最大のストレージ容量を確保します。メタデータフィルタリング条件で使用されるフィールドまたは出力フィールドにリストされているフィールドの生データが大きすぎて、ハードドライブに残すと応答が遅くなったりネットワークが不安定になったりする場合は、これらのフィールドに対して mmap を無効にして検索パフォーマンスを向上させることを検討できます。
拡張容量CU を使用するクラスターおよび専用クラスターでは、Zilliz Cloud はすべてのフィールドの生データとインデックスに対して mmap を有効にし、システムキャッシュを最大限に活用してホットデータのパフォーマンスを向上させ、コールドデータのコストを削減します。
コレクション固有の mmap 設定
mmap 設定を変更するには、コレクションをリリースして変更を行い、再度ロードして変更を有効にする必要があります。特定のフィールド、フィールドインデックス、またはコレクションに対して mmap を構成できます。
mmap 設定の変更には注意が必要です。不適切な mmap 設定は、以下の問題を引き起こす可能性があります:
パフォーマンス最適化済みの専用クラスターでは、検索およびクエリ時のスカラーフィールドの高速取得を確保するために、すべてのスカラーフィールドの生データとベクトルインデックスがデフォルトでメモリにロードされます。デフォルトの mmap 設定を変更すると、パフォーマンスが低下する可能性があります。
容量最適化済みの専用クラスターでは、最大ストレージ容量を確保するために、ベクトルインデックスのみがデフォルトでメモリにロードされます。デフォルトの mmap 設定を変更すると、メモリ不足(OOM)によるロード失敗が発生する可能性があります。
特定のフィールドに対する mmap の構成
小規模なパフォーマンス最適化済み CU を持つ専用クラスターを使用しており、データセット内のフィールドの生データが大きい場合は、mmap を有効にしてコレクションにフィールドを追加することを検討してください。
次の例では、パフォーマンス最適化済みの専用クラスターに接続していることを前提とし、フィールド追加時に doc_chunk という名前の VarChar フィールドで mmap を有効にする方法を示します。
- Python
- Java
- NodeJS
- Go
- cURL
from pymilvus import MilvusClient, DataType
CLUSTER_ENDPOINT="YOUR_CLUSTER_ENDPOINT"
TOKEN="YOUR_CLUSTER_TOKEN"
client = MilvusClient(
uri=CLUSTER_ENDPOINT,
token=TOKEN
)
schema = MilvusClient.create_schema()
schema.add_field("id", DataType.INT64, is_primary=True, auto_id=False)
schema.add_field("vector", DataType.FLOAT_VECTOR, dim=5)
# Disable mmap on a field upon creating the schema for a collection
schema.add_field(
field_name="doc_chunk",
datatype=DataType.INT64,
max_length=512,
mmap_enabled=False,
)
client.create_collection(collection_name="my_collection", schema=schema)
# Disable mmap on an existing field
# The following assumes that you have a collection named \`my_collection\`
client.alter_collection_field(
collection_name="my_collection",
field_name="doc_chunk",
field_params={"mmap.enabled": True}
)
import io.milvus.param.Constant;
import io.milvus.v2.client.ConnectConfig;
import io.milvus.v2.client.MilvusClientV2;
import io.milvus.v2.common.DataType;
import io.milvus.v2.service.collection.request.*;
import java.util.*;
String CLUSTER_ENDPOINT = "YOUR_CLUSTER_ENDPOINT";
String TOKEN = "YOUR_CLUSTER_TOKEN";
client = new MilvusClientV2(ConnectConfig.builder()
.uri(CLUSTER_ENDPOINT)
.token(TOKEN)
.build());
CreateCollectionReq.CollectionSchema schema = client.createSchema();
schema.addField(AddFieldReq.builder()
.fieldName("id")
.dataType(DataType.Int64)
.isPrimaryKey(true)
.autoID(false)
.build());
schema.addField(AddFieldReq.builder()
.fieldName("vector")
.dataType(DataType.FloatVector)
.dimension(5)
.build());
Map<String, String> typeParams = new HashMap<String, String>() {{
put(Constant.MMAP_ENABLED, "false");
}};
schema.addField(AddFieldReq.builder()
.fieldName("doc_chunk")
.dataType(DataType.VarChar)
.maxLength(512)
.typeParams(typeParams)
.build());
CreateCollectionReq req = CreateCollectionReq.builder()
.collectionName("my_collection")
.collectionSchema(schema)
.build();
client.createCollection(req);
client.alterCollectionField(AlterCollectionFieldReq.builder()
.collectionName("my_collection")
.fieldName("doc_chunk")
.property(Constant.MMAP_ENABLED, "true")
.build());
import { MilvusClient, DataType } from '@zilliz/milvus2-sdk-node';
const CLUSTER_ENDPOINT="YOUR_CLUSTER_ENDPOINT";
const TOKEN="YOUR_TOKEN";
const client = await MilvusClient({
address: CLUSTER_ENDPOINT,
token: TOKEN
});
const schema = [
{
name: 'vector',
data_type: DataType.FloatVector
},
{
name: "doc_chunk",
data_type: DataType.VarChar,
max_length: 512,
'mmap.enabled': false,
}
];
await client.createCollection({
collection_name: "my_collection",
schema: schema
});
await client.alterCollectionFieldProperties({
collection_name: "my_collection",
field_name: "doc_chunk",
properties: {"mmap_enable": true}
});
import (
"context"
"fmt"
"github.com/milvus-io/milvus/client/v2/column"
"github.com/milvus-io/milvus/client/v2/entity"
"github.com/milvus-io/milvus/client/v2/milvusclient"
)
ctx, cancel := context.WithCancel(context.Background())
defer cancel()
milvusAddr := "YOUR_CLUSTER_ENDPOINT"
client, err := milvusclient.New(ctx, &milvusclient.ClientConfig{
Address: milvusAddr,
})
if err != nil {
fmt.Println(err.Error())
// handle error
}
defer client.Close(ctx)
schema := entity.NewSchema().WithDynamicFieldEnabled(false)
schema.WithField(entity.NewField().
WithName("id").
WithDataType(entity.FieldTypeInt64).
WithIsPrimaryKey(true),
).WithField(entity.NewField().
WithName("vector").
WithDataType(entity.FieldTypeFloatVector).
WithDim(5),
).WithField(entity.NewField().
WithName("doc_chunk").
WithDataType(entity.FieldTypeVarChar).
WithMaxLength(512).
WithTypeParams(common.MmapEnabledKey, "false"),
)
err = client.CreateCollection(ctx,
milvusclient.NewCreateCollectionOption("my_collection", schema))
if err != nil {
fmt.Println(err.Error())
// handle error
}
err = client.AlterCollectionFieldProperty(ctx, milvusclient.NewAlterCollectionFieldPropertiesOption("my_collection", "doc_chunk").
WithProperty(common.MmapEnabledKey, "true"))
if err != nil {
fmt.Println(err.Error())
// handle error
}
#restful
export TOKEN="YOUR_CLUSTER_TOKEN"
export CLUSTER_ENDPOINT="YOUR_CLUSTER_ENDPOINT"
export idField='{
"fieldName": "id",
"dataType": "Int64",
"isPrimary": true,
"auto_id": false
}'
export vectorField='{
"fieldName": "vector",
"dataType": "FloatVector",
"elementTypeParams": {
"dim": 5
}
}'
export docChunkField='{
"fieldName": "doc_chunk",
"dataType": "Varchar",
"elementTypeParams": {
"max_length": 512,
"mmap.enabled": false
}
}'
export schema="{
\"autoID\": false,
\"fields\": [
$idField,
$docChunkField,
$vectorField
]
}"
curl --request POST \
--url "${CLUSTER_ENDPOINT}/v2/vectordb/collections/create" \
--header "Authorization: Bearer ${TOKEN}" \
--header "Content-Type: application/json" \
--data "{
\"collectionName\": \"my_collection\",
\"schema\": $schema
}"
curl --request POST \
--url "${CLUSTER_ENDPOINT}/v2/vectordb/collections/fields/alter_properties" \
--header "Authorization: Bearer ${TOKEN}" \
--header "Content-Type: application/json" \
-d '{
"collectionName": "my_collection",
"fieldName": "doc_chunk",
"fieldParams":{
"mmap.enabled": true
}
}'
上記のスキーマを使用して作成されたコレクションをロードする際、Zilliz Cloud は doc_chunk フィールドの生データをメモリマップします。フィールドの mmap 設定を変更するには、まずコレクションをリリースし、変更後に再度コレクションをロードする必要があることに注意してください。
スカラーフィールドのインデックスに対する mmap の設定
メタデータフィルタリングに使用される、または出力フィールドとして使用されるスカラーフィールドについては、それらをメモリにロードし、他のスカラーフィールドはハードディスク上に保持することを検討してください。
以下の例では、容量最適化型の専用クラスターに接続していることを前提として、クイックな取得のために title という名前の VarChar フィールドのインデックスに対する mmap を無効にする方法を示しています。
- Python
- Java
- NodeJS
- Go
- cURL
# Add a varchar field
schema.add_field(
field_name="title",
datatype=DataType.VARCHAR,
max_length=512
)
index_params = MilvusClient.prepare_index_params()
# Create index on the varchar field with mmap settings
index_params.add_index(
field_name="title",
index_type="AUTOINDEX",
params={ "mmap.enabled": "false" }
)
# Change mmap settings for an index
# The following assumes that you have a collection named \`my_collection\`
client.alter_index_properties(
collection_name="my_collection",
index_name="title",
properties={"mmap.enabled": True}
)
schema.addField(AddFieldReq.builder()
.fieldName("title")
.dataType(DataType.VarChar)
.maxLength(512)
.build());
List<IndexParam> indexParams = new ArrayList<>();
Map<String, Object> extraParams = new HashMap<String, Object>() {{
put(Constant.MMAP_ENABLED, false);
}};
indexParams.add(IndexParam.builder()
.fieldName("title")
.indexType(IndexParam.IndexType.AUTOINDEX)
.extraParams(extraParams)
.build());
client.alterIndexProperties(AlterIndexPropertiesReq.builder()
.collectionName("my_collection")
.indexName("title")
.property(Constant.MMAP_ENABLED, "true")
.build());
// Create index on the varchar field with mmap settings
await client.createIndex({
collection_name: "my_collection",
field_name: "title",
params: { "mmap.enabled": false }
});
// Change mmap settings for an index
// The following assumes that you have a collection named \`my_collection\`
await client.alterIndexProperties({
collection_name: "my_collection",
index_name: "title",
properties:{"mmap.enabled": true}
});
schema.WithField(entity.NewField().
WithName("title").
WithDataType(entity.FieldTypeVarChar).
WithMaxLength(512),
)
indexOption := milvusclient.NewCreateIndexOption("my_collection", "title",
index.NewInvertedIndex())
indexOption.WithExtraParam(common.MmapEnabledKey, "false")
err = client.AlterIndexProperties(ctx, milvusclient.NewAlterIndexPropertiesOption("my_collection", "title").
WithProperty(common.MmapEnabledKey, "true"))
if err != nil {
fmt.Println(err.Error())
// handle error
}
# restful
export TOKEN="YOUR_CLUSTER_TOKEN"
curl --request POST \
--url "${CLUSTER_ENDPOINT}/v2/vectordb/indexes/create" \
--header "Authorization: Bearer ${TOKEN}" \
--header "Content-Type: application/json" \
-d '{
"collectionName": "my_collection",
"indexParams": [
{
"fieldName": "title",
"params": {
"index_type": "AUTOINDEX",
"mmap.enabled": false
}
}
]
}'
curl --request POST \
--url "${CLUSTER_ENDPOINT}/v2/vectordb/indexes/alter_properties" \
--header "Authorization: Bearer ${TOKEN}" \
--header "Content-Type: application/json" \
-d '{
"collectionName": "my_collection",
"indexName": "title",
"properties": {
"mmap.enabled": true
}
}'
上記のインデックスパラメータを使用して作成されたコレクションをロードする際、Zilliz Cloud は title フィールドのインデックスをメモリに読み込みます。フィールドの mmap 設定を変更するには、まずコレクションをリリースし、変更後に再度コレクションをロードする必要があることに注意してください。
コレクションでの mmap の設定
コレクションで mmap 設定を無効にすることで、Zilliz Cloud がすべてのフィールドの生データを完全にメモリに読み込むようにできます。
以下の例では、パフォーマンス最適化型の専用クラスターに接続していることを前提として、コレクション作成時に mmap を無効にする方法を示します。
- Python
- Java
- NodeJS
- Go
- cURL
# Enable mmap when creating a collection
client.create_collection(
collection_name="my_collection",
schema=schema,
properties={ "mmap.enabled": "false" }
)
CreateCollectionReq req = CreateCollectionReq.builder()
.collectionName("my_collection")
.collectionSchema(schema)
.property(Constant.MMAP_ENABLED, "false")
.build();
client.createCollection(req);
await client.createCollection({
collection_name: "my_collection",
scheme: schema,
properties: { "mmap.enabled": false }
});
err = client.CreateCollection(ctx,
milvusclient.NewCreateCollectionOption("my_collection", schema).
WithProperty(common.MmapEnabledKey, "false"))
if err != nil {
fmt.Println(err.Error())
// handle error
}
curl --request POST \
--url "${CLUSTER_ENDPOINT}/v2/vectordb/collections/create" \
--header "Authorization: Bearer ${TOKEN}" \
--header "Content-Type: application/json" \
--data "{
\"collectionName\": \"my_collection\",
\"schema\": $schema,
\"params\": {
\"mmap.enabled\": \"false\"
}
}"
既存のコレクションのmmap設定を次のように変更することもできます。
- Python
- Java
- NodeJS
- Go
- cURL
# Release collection before change mmap settings
client.release_collection("my_collection")
# Ensure that the collection has already been released
# and run the following
client.alter_collection_properties(
collection_name="my_collection",
properties={
"mmap.enabled": false
}
)
# Load the collection to make the above change take effect
client.load_collection("my_collection")
client.releaseCollection(ReleaseCollectionReq.builder()
.collectionName("my_collection")
.build());
client.alterCollectionProperties(AlterCollectionPropertiesReq.builder()
.collectionName("my_collection")
.property(Constant.MMAP_ENABLED, "false")
.build());
client.loadCollection(LoadCollectionReq.builder()
.collectionName("my_collection")
.build());
// Release collection before change mmap settings
await client.releaseCollection({
collection_name: "my_collection"
});
// Ensure that the collection has already been released
// and run the following
await client.alterCollectionProperties({
collection_name: "my_collection",
properties: {
"mmap.enabled": false
}
});
// Load the collection to make the above change take effect
await client.loadCollection({
collection_name: "my_collection"
});
err = client.ReleaseCollection(ctx, milvusclient.NewReleaseCollectionOption("my_collection"))
if err != nil {
fmt.Println(err.Error())
// handle error
}
err = client.AlterCollectionProperties(ctx, milvusclient.NewAlterCollectionPropertiesOption("my_collection").
WithProperty(common.MmapEnabledKey, "false"))
if err != nil {
fmt.Println(err.Error())
// handle error
}
_, err := client.LoadCollection(ctx, milvusclient.NewLoadCollectionOption("my_collection"))
if err != nil {
fmt.Println(err.Error())
// handle err
}
# restful
export CLUSTER_ENDPOINT="YOUR_CLUSTER_ENDPOINT"
export TOKEN="YOUR_CLUSTER_TOKEN"
curl --request POST \
--url "${CLUSTER_ENDPOINT}/v2/vectordb/collections/release" \
--header "Authorization: Bearer ${TOKEN}" \
--header "Content-Type: application/json" \
-d '{
"collectionName": "my_collection"
}'
curl --request POST \
--url "${CLUSTER_ENDPOINT}/v2/vectordb/collections/alter_properties" \
--header "Authorization: Bearer ${TOKEN}" \
--header "Content-Type: application/json" \
-d '{
"collectionName": "my_collection",
"properties": {
"mmmap.enabled": false
}
}'
curl --request POST \
--url "${CLUSTER_ENDPOINT}/v2/vectordb/collections/load" \
--header "Authorization: Bearer ${TOKEN}" \
--header "Content-Type: application/json" \
-d '{
"collectionName": "my_collection"
}'
コレクションのプロパティを変更するには、一度コレクションをリリースし、変更を有効にするために再度コレクションをリロードする必要があります。