データに接続するAbout to Deprecate
コネクターは、様々なデータソースをベクターデータベースに簡単に接続できる無料のツールです。このガイドでは、コネクターの概念を説明し、Zilliz Cloud Pipelinesでコネクターを作成および管理する方法について説明します。
Zilliz Cloud Pipelinesは、2025年第2四半期の終わりまでに廃止され、「Data In, Data Out」という新しい機能に置き換えられます。これにより、MilvusとZilliz Cloudの両方で埋め込み生成が効率化されます。2024年12月24日現在、新規ユーザー登録は受け付けられていません。現在のユーザーは、日没日まで月額20ドルの無料手当内でサービスを継続して利用できますが、SLAは提供されていません。モデルプロバイダーまたはオープンソースモデルの埋め込みAPIを使用してベクトル埋め込みを生成することを検討してください。
コネクターの理解
コネクタは、オブジェクトストレージ、Kafka(近日公開予定)など、さまざまなデータソースからZilliz Cloudにデータを取り込むためのツールです。オブジェクトストレージコネクタを例にとると、コネクタはオブジェクトストレージバケット内のディレクトリを監視し、PDFやHTMLなどのファイルをZilliz Cloudパイプラインに同期して、ベクトル表現に変換してベクトルデータベースに保存して検索できます。インジェストおよび削除パイプラインを使用すると、Zilliz Cloud内のファイルとそのベクトル表現が同期されます。オブジェクトストレージ内のファイルの追加または削除は、ベクトルデータベースコレクションにマップされます。
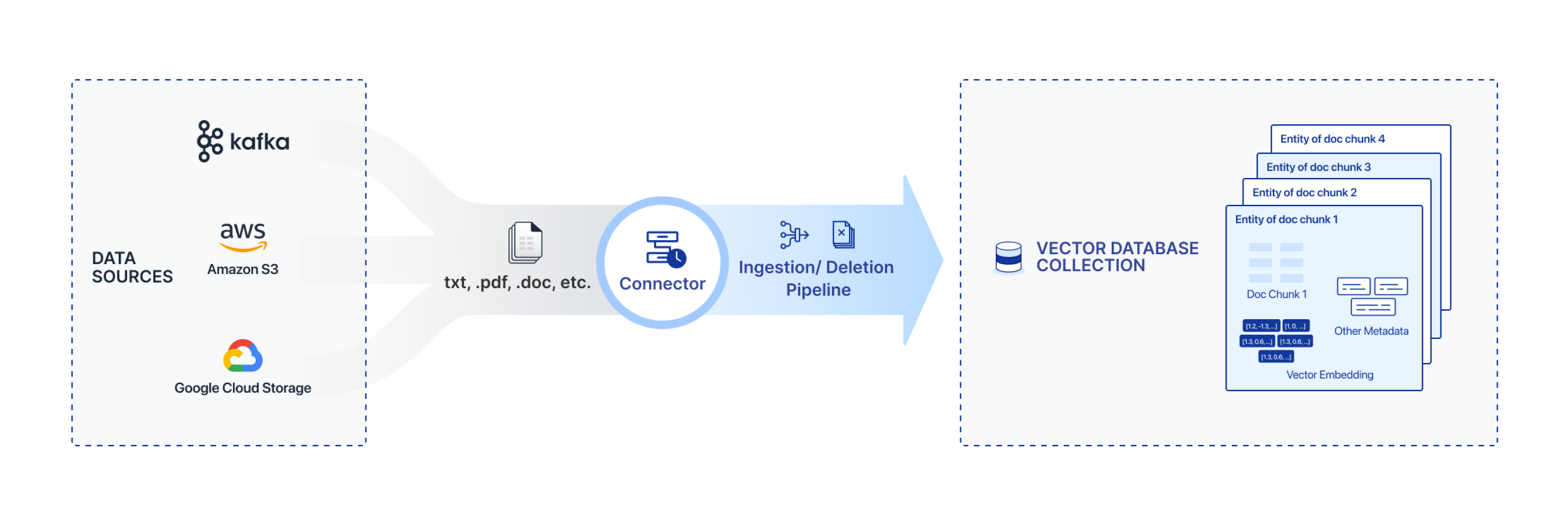
なぜコネクタを使用するのですか?
-
リアルタイムデータ取り込み
リアルタイムでデータを楽々と取り込み、インデックス化することで、すべての検索問い合わせに対して最新のコンテンツが即座にアクセス可能になります。
-
スケーラブルで適応性がある
DevOpsの手間をかけずに、データ取り込みパイプラインを簡単に拡張できます。アダプティブコネクタは、変動するトラフィック負荷をシームレスに処理し、スムーズなスケーラビリティを確保します。
-
異種ソースと同期された検索インデックス
ドキュメントの追加と削除を検索インデックスに自動的に同期します。また、すべての一般的なデータソースを融合します(近日公開予定)。
-
可観測性
詳細なログを記録し、透明性を確保し、発生する可能性のある異常を検出することで、データフローの洞察を得ることができます。
コネクタの作成
Zilliz Cloud Pipelinesは、コネクタを作成する際に柔軟なオプションを提供します。コネクタが作成されると、定期的にデータソースをスキャンし、定期的な間隔でベクトルデータベースにデータを取り込みます。
前提条件
-
必ずコレクションを作成してください。
-
作成されたコレクションには、文書の取り込みパイプラインと削除パイプラインがあることを確認してください。
現在、Zilliz Cloud Connectorは文書データの処理のみをサポートしています。
手続き
-
プロジェクトに移動します。ナビゲーションパネルから[パイプライン]をクリックします。次に、[コネクタ]タブに切り替えます。[+コネクタ]をクリックします。
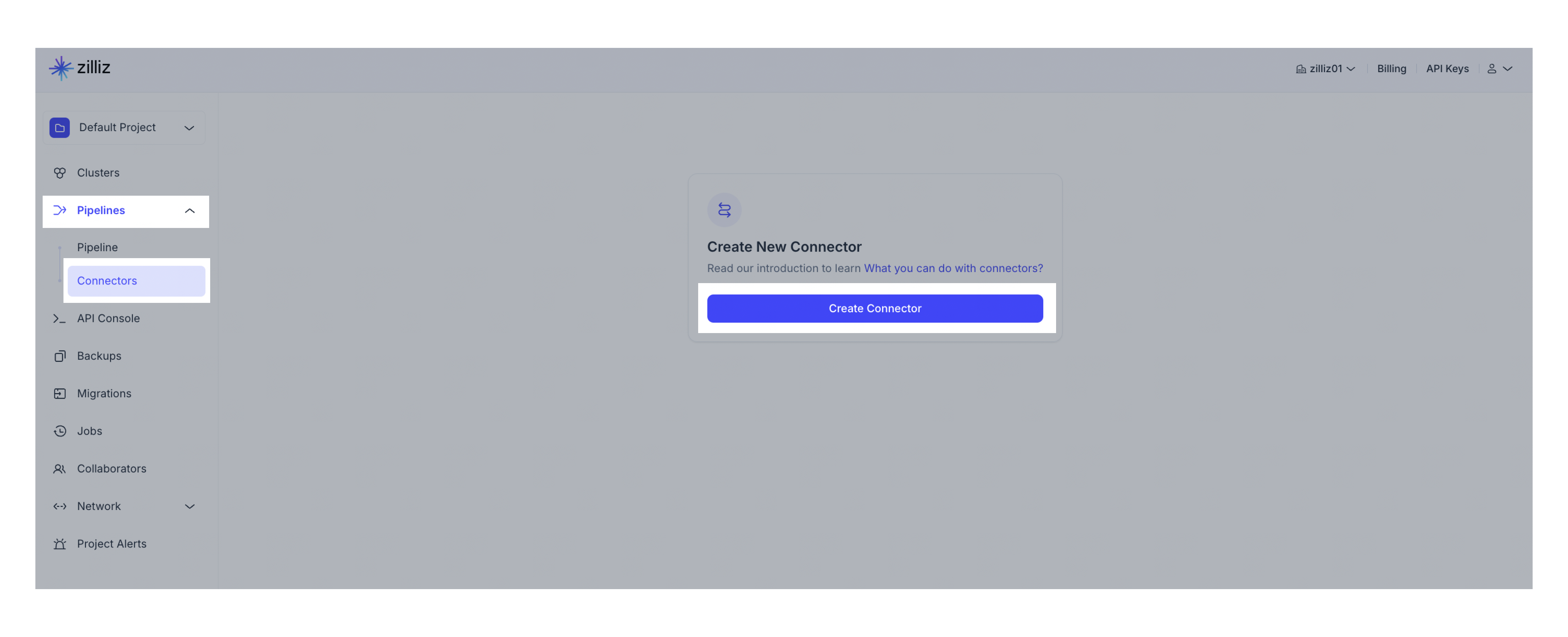
-
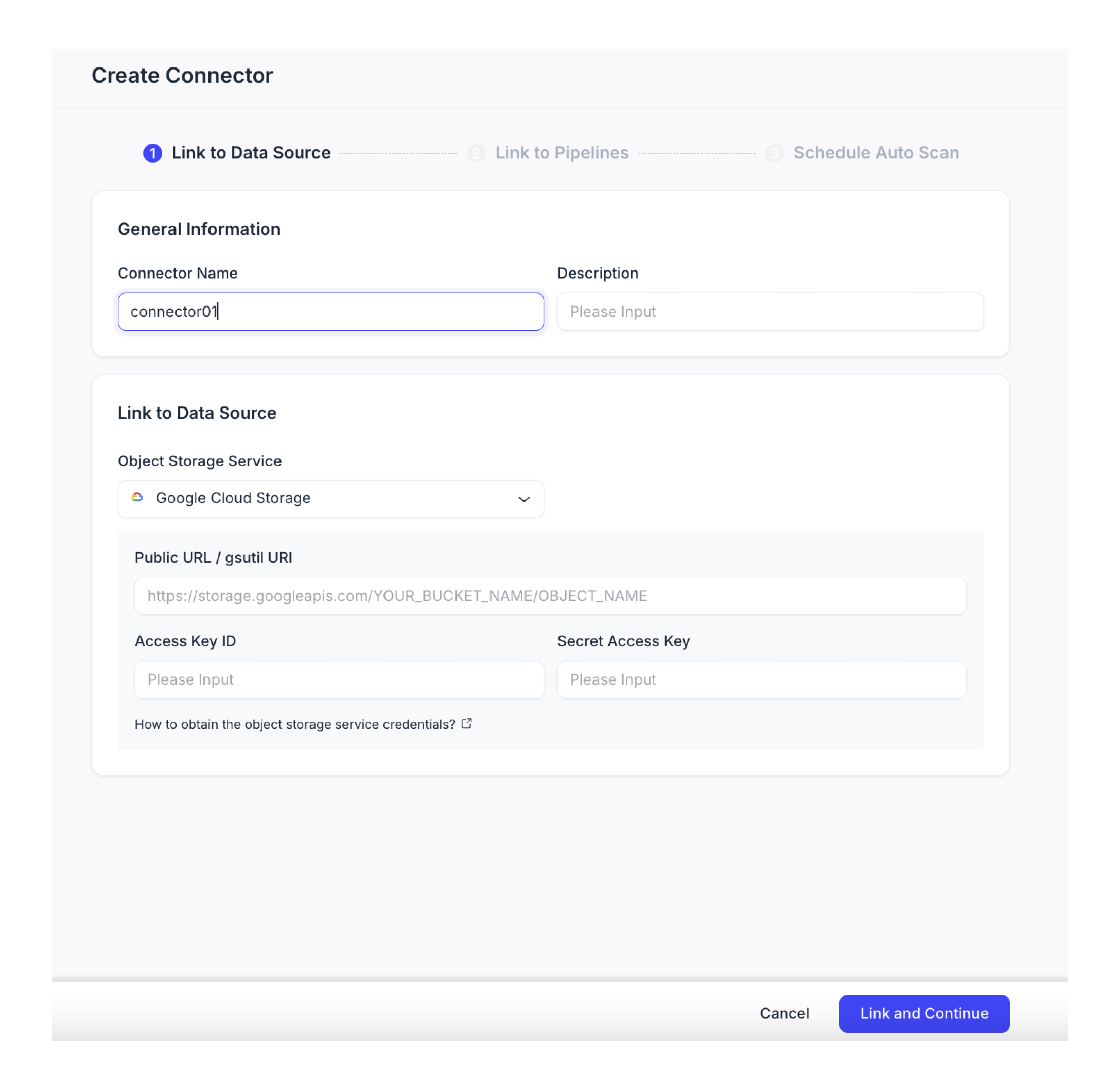
データソースへのリンク。
-
コネクタの基本情報を設定します。
パラメータ
説明する
コネクタ名
作成するコネクタの名前。
説明(オプション)
コネクタの説明。
-
データソース情報を構成します。
パラメータ
説明する
オブジェクトストレージサービス
データソースのオブジェクトストレージサービスを選択してください。利用可能なオプションには、次のものがあります:
AWSのS 3
Google Cloud Storageです。
バケットURL
ソースデータにアクセスするために使用するバケットURLを指定してください。特定のファイルではなく、ファイルディレクトリのURLを入力してください。また、ルートディレクトリはサポートされていません。
URLを取得する方法の詳細については、以下を参照してください:
認証のためのアクセスキー(任意)
必要に応じて、承認のために以下の情報を提供してください
AWS S 3の場合、アクセスキーとシークレットキーを提供してください。
Google Cloud Storageの場合、アクセスキーIDとシークレットアクセスキーを提供してください。
次のステップに進むには**、リンクと続行**をクリックしてください。
📘ノート次のステップに進む前に、Zilliz Cloudはデータソースへの接続を確認します。
-
-
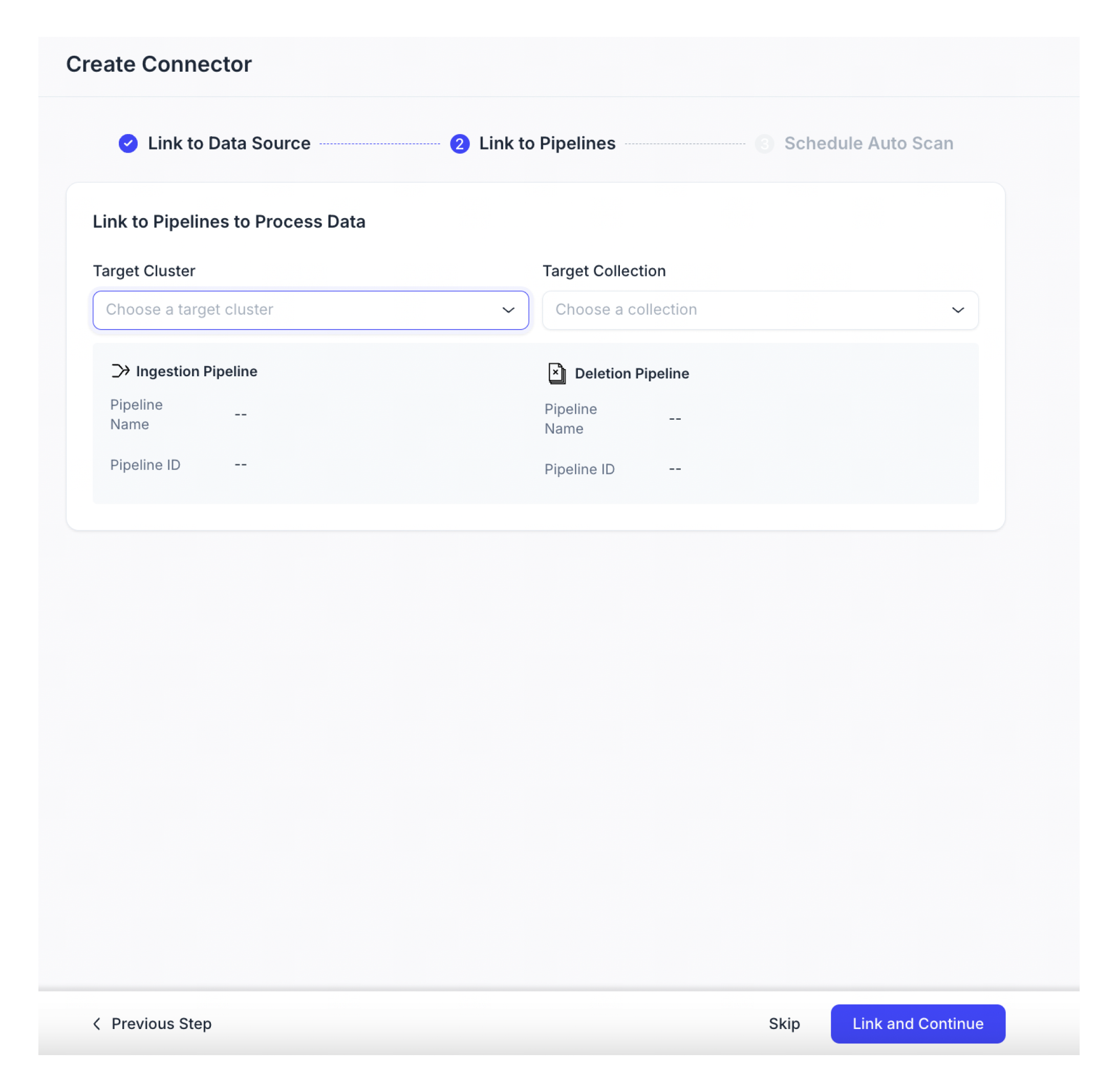
ターゲットパイプラインを追加します。
まず、ターゲットクラスタを選択し、次に1つのインジェストパイプラインと削除パイプラインを持つコレクションを選択します。ターゲットインジェストパイプラインにはINDEX_DOC関数のみが必要です。複数の削除パイプラインが利用可能な場合は、適切なものを手動で選択してください。
📘ノートスキャンを開始する前に、このステップをスキップして後で完了することができます。
-
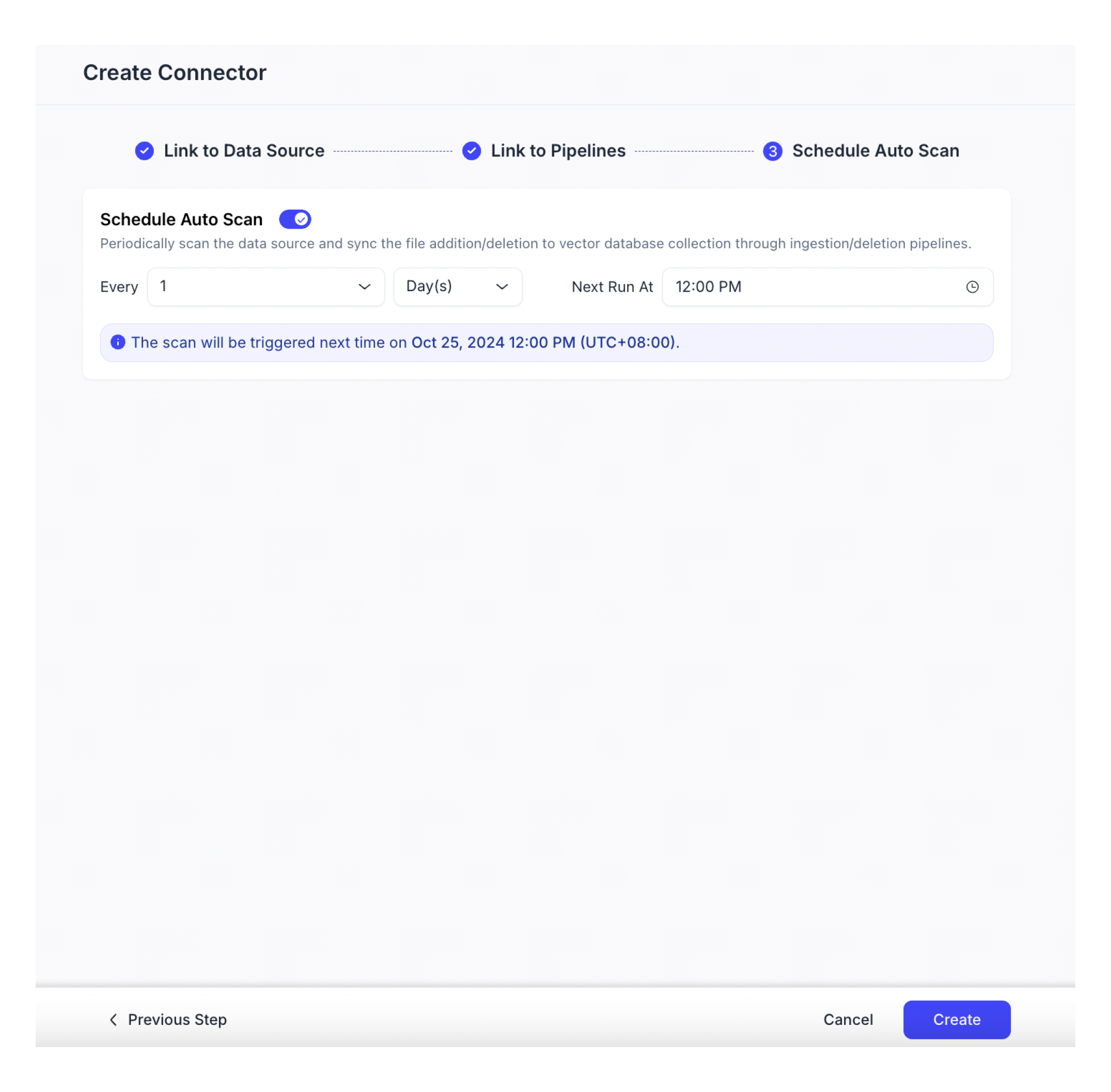
自動スキャンを有効にするかどうかを選択します。
-
無効になっている場合、ソースデータに更新がある場合は、手動でスキャンをトリガーする必要があります。
-
有効にすると、Zilliz Cloudは定期的にデータソースをスキャンし、指定された取り込み/削除パイプラインを介してベクトルデータベースコレクションにファイルの追加/削除を同期します。自動スキャンスケジュールを設定する必要があります。
パラメータ
説明する
周波数
システムがスキャンを実行する頻度を設定します。
デイリー: 1から7までの数字を選択してください。
毎時:オプションは1、6、12、または18時間です。
次のRun at
次のスキャンの時間を指定します。タイムゾーンは、システムタイムゾーンと組織設定で一致しています。
-
-
[作成]をクリックします。
コネクタの管理
コネクタを効率的に管理することは、スムーズなデータ統合過程を維持するために不可欠です。このガイドでは、コネクタの管理方法について詳しく説明します。
コネクタを有効または無効にする
-
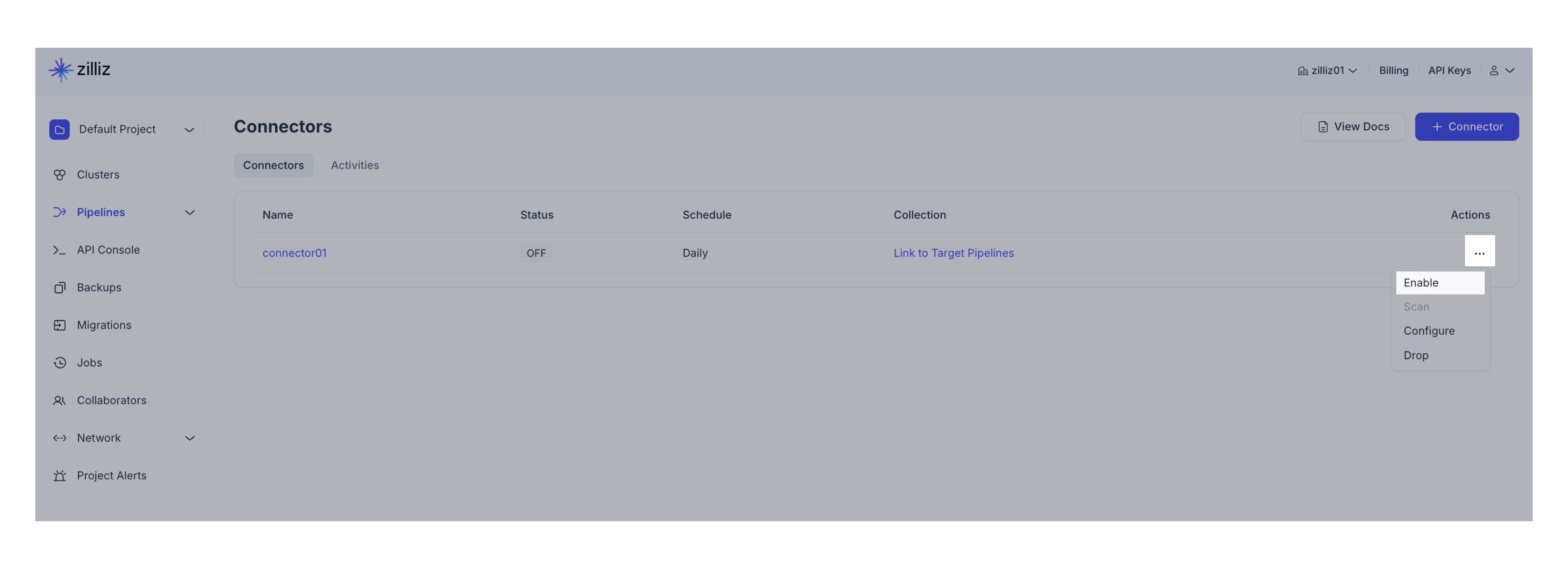
管理するコネクタを探します。
-
クリック**。。。下のアクション**。
-
[有効]または[無効]を選択します。
コネクタをアクティブにするには、ターゲットパイプラインが構成されていることを確認します。
手動スキャンをトリガーする
自動スキャン機能がオフの場合は、手動スキャンを実行してください。
をクリック**。。。"ターゲットコネクタの横にあるアクション**の下で、スキャンをクリックします。
手動スキャンを開始する前に、コネクタが有効になっていることを確認してください。
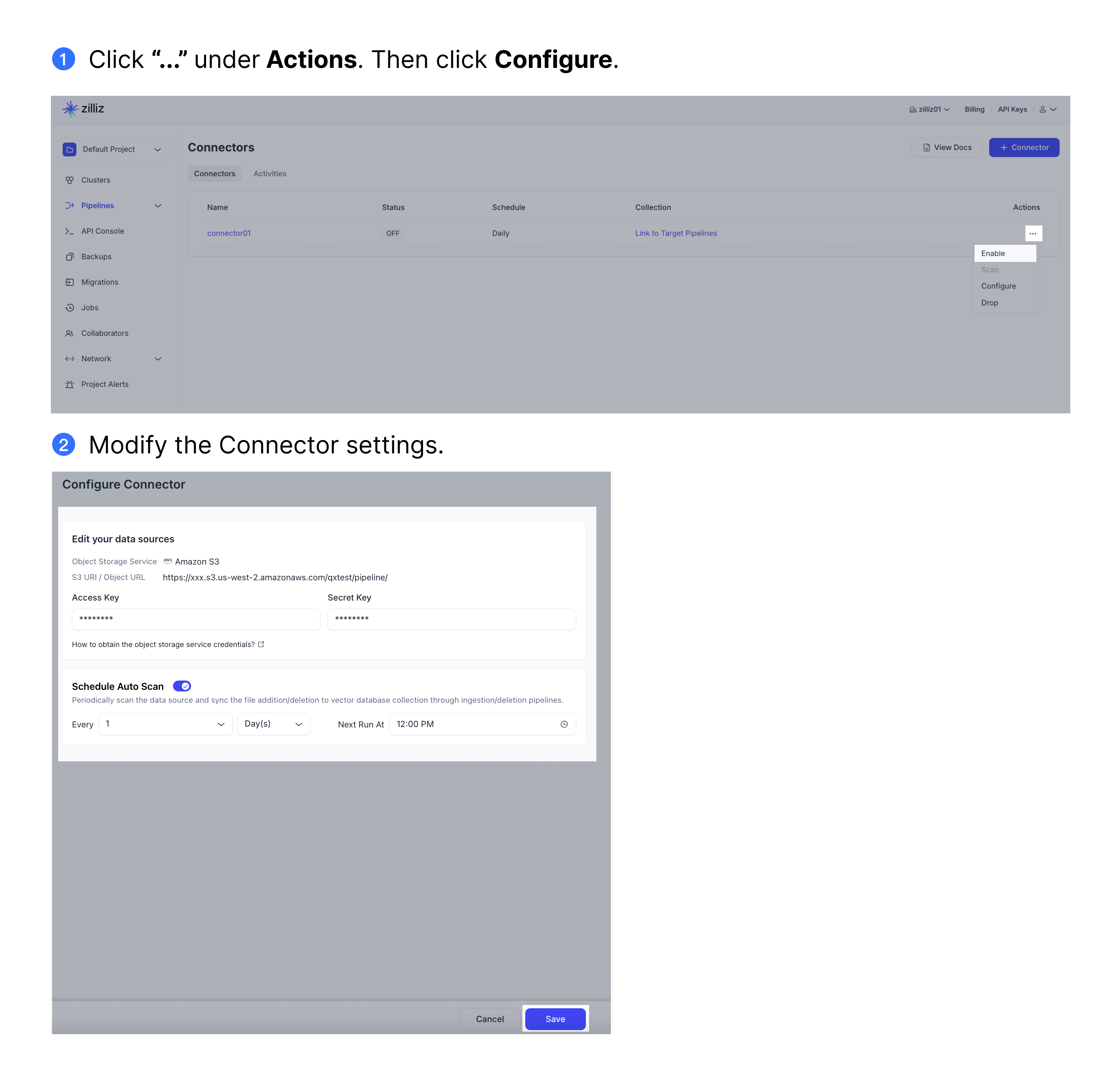
コネクタの設定
コネクタの次の設定を変更できます。
-
ストレージバケットのアクセス資格情報:
-
(AWS S 3の場合)アクセスキーとシークレットキー
-
(Google Cloud Storageの場合)アクセスキーIDとシークレットアクセスキー
-
-
自動スキャンスケジュール。詳細については、コネクタの作成手順のステップ4を参照してください。
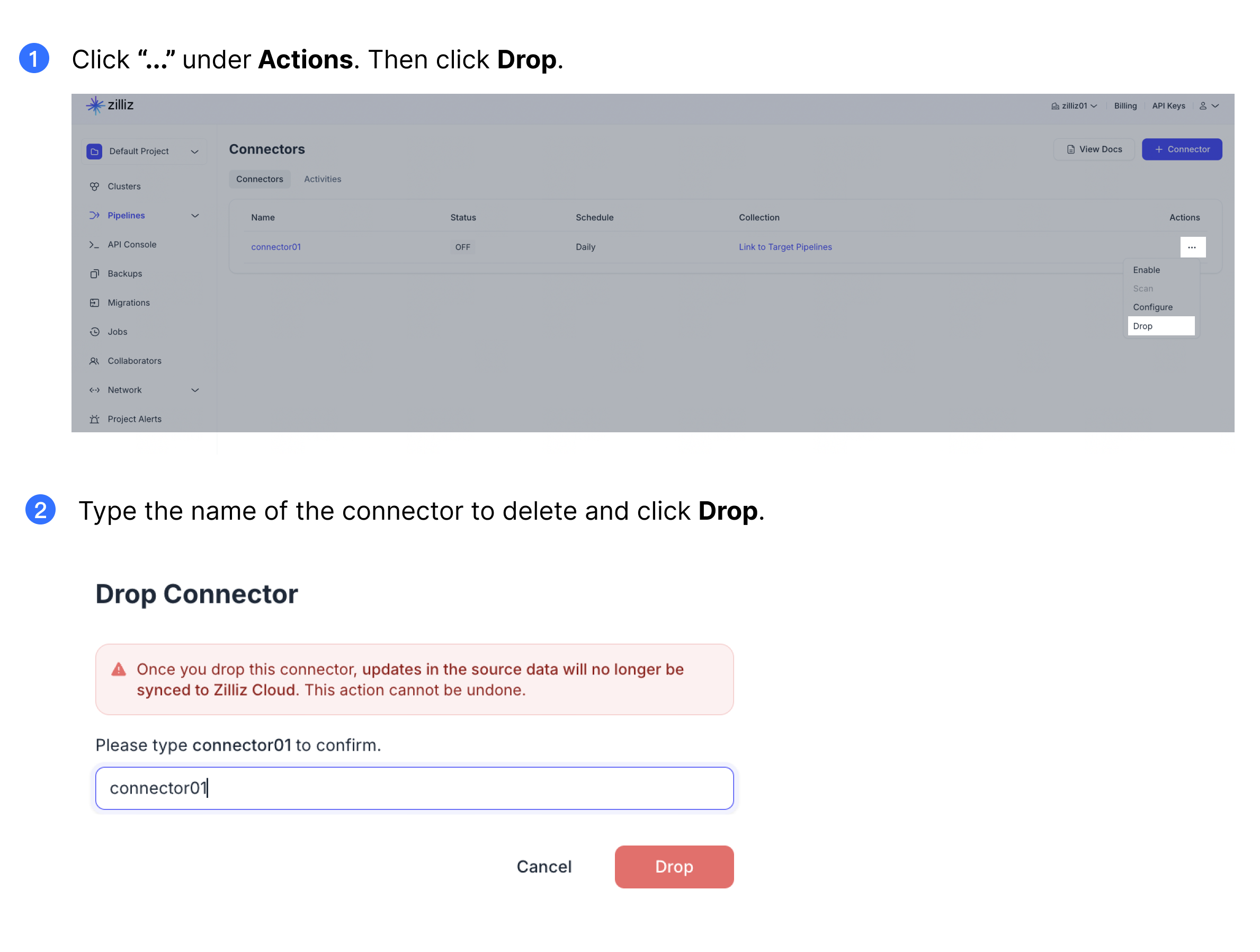
コネクタを落とす
必要がなくなった場合は、コネクタを取り外すことができます。
コネクタはドロップする前に無効にする必要があります。
コネクタログの表示
コネクタのアクティビティを監視し、問題をトラブルシューティングする:
-
コネクタのアクティビティページにアクセスしてログを表示します。
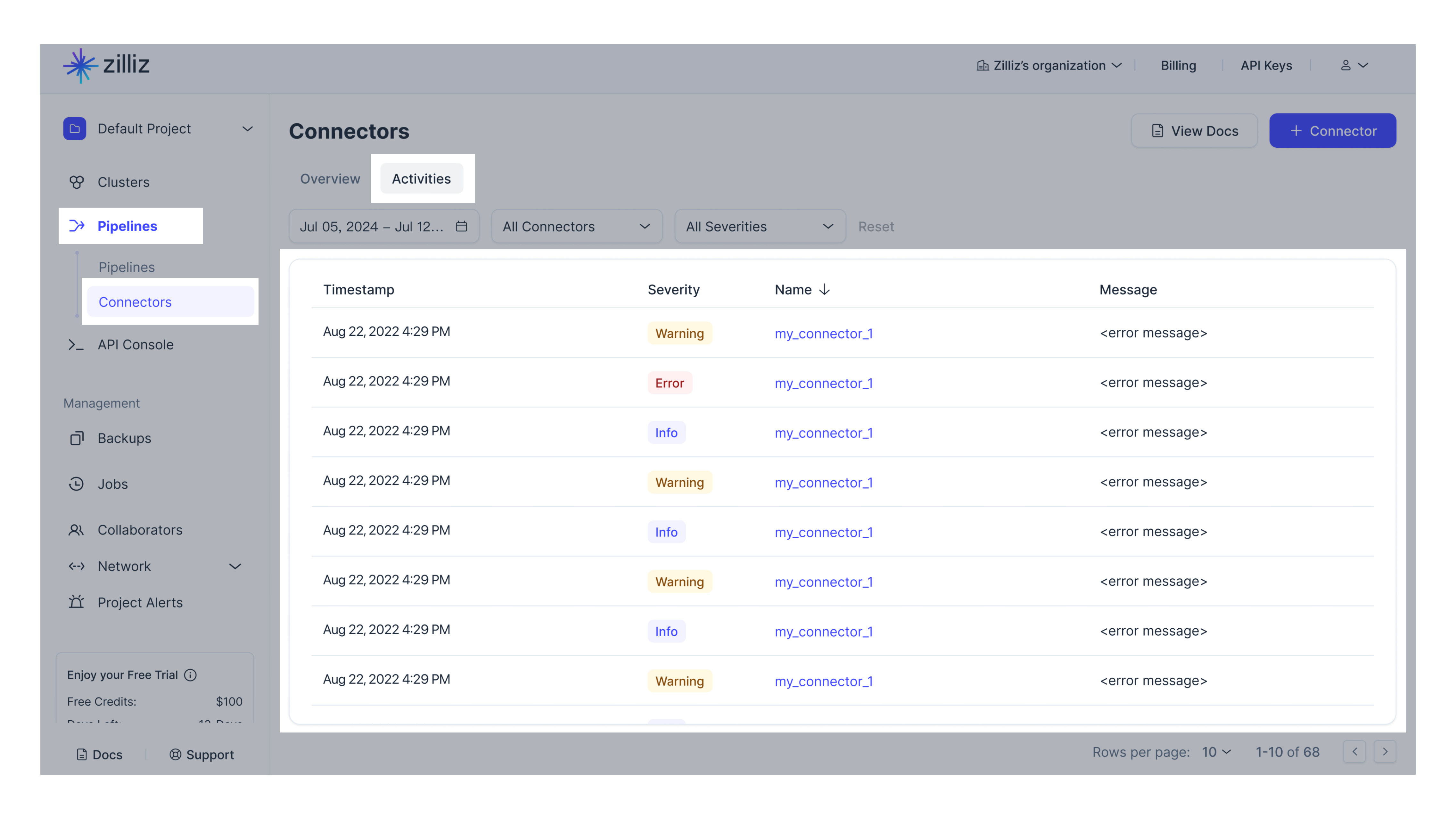
-
ステータスが
異常な場合はエラーを示します。詳細なエラーメッセージを表示するには、ステータスの横にある「?」アイコンをクリックしてください。
パイプライン内の関連コネクタを表示する
パイプライン内のすべてのリンクされたコネクタを表示するには、パイプラインの詳細を確認してください。