パイプライン利用予測About to Deprecate
パイプラインの実行コストはトークンによって測定されます。トークンを基本単位として使用する大規模言語モデル(LLM)と同様に、パイプラインはテキストを解析して一連のトークンとして埋め込むことによって、ドキュメントや検索クエリを過程化します。パイプラインの実行コストを理解するには、ファイルまたはテキスト文字列のトークンをカウントするために、当社の推定パイプライン使用量ツールを使用できます。
Zilliz Cloud Pipelinesは、2025年第2四半期の終わりまでに廃止され、「Data In, Data Out」という新しい機能に置き換えられます。これにより、MilvusとZilliz Cloudの両方で埋め込み生成が効率化されます。2024年12月24日現在、新規ユーザー登録は受け付けられていません。現在のユーザーは、日没日まで月額20ドルの無料手当内でサービスを継続して利用できますが、SLAは提供されていません。モデルプロバイダーまたはオープンソースモデルの埋め込みAPIを使用してベクトル埋め込みを生成することを検討してください。
このツールはByte-Pair Encoding(BPE)トークナイザーを使用しており、処理戦略によって推定使用量が30%異なる場合があります。そのため、推定使用量は参考としてのみ使用してください。実際の使用方法については、パイプラインリストを参照してください。
トークンとは何ですか?
トークンはNLPにおける特別な概念です。それはサブワードと考えることができます。一部の単語はトークンそのものであり、一部の長い単語には複数のトークンが含まれる場合があります。トークンは言語にも依存します。一般的には、次のようになります:
-
1トークンは3~4文字の英語です
-
1トークンは1.12漢字です
-
1英単語には1.3トークンが含まれています
Pipelinesはトークンをどのように処理しますか?
Ingestion Pipelineは、ファイルをトークンに解析し、トークンシリーズを分割して埋め込むことでドキュメントを処理します。Search Pipelineは、トークンシリーズを埋め込むことでクエリを処理します。トークンを深層学習モデル(埋め込みモデルと呼ばれる)に渡すことで、テキストの「本質」をベクトル表現に変換し、ベクトルデータベースに格納して取得できます。この過程の助けを借りて、PipelinesはAPIユーザーが文やテキスト内の異なる単語の意味や意味、およびその文脈を理解するのを支援することができます。
削除パイプラインは通常、テキストをトークンとして処理することはありません。
パイプラインの利用予測
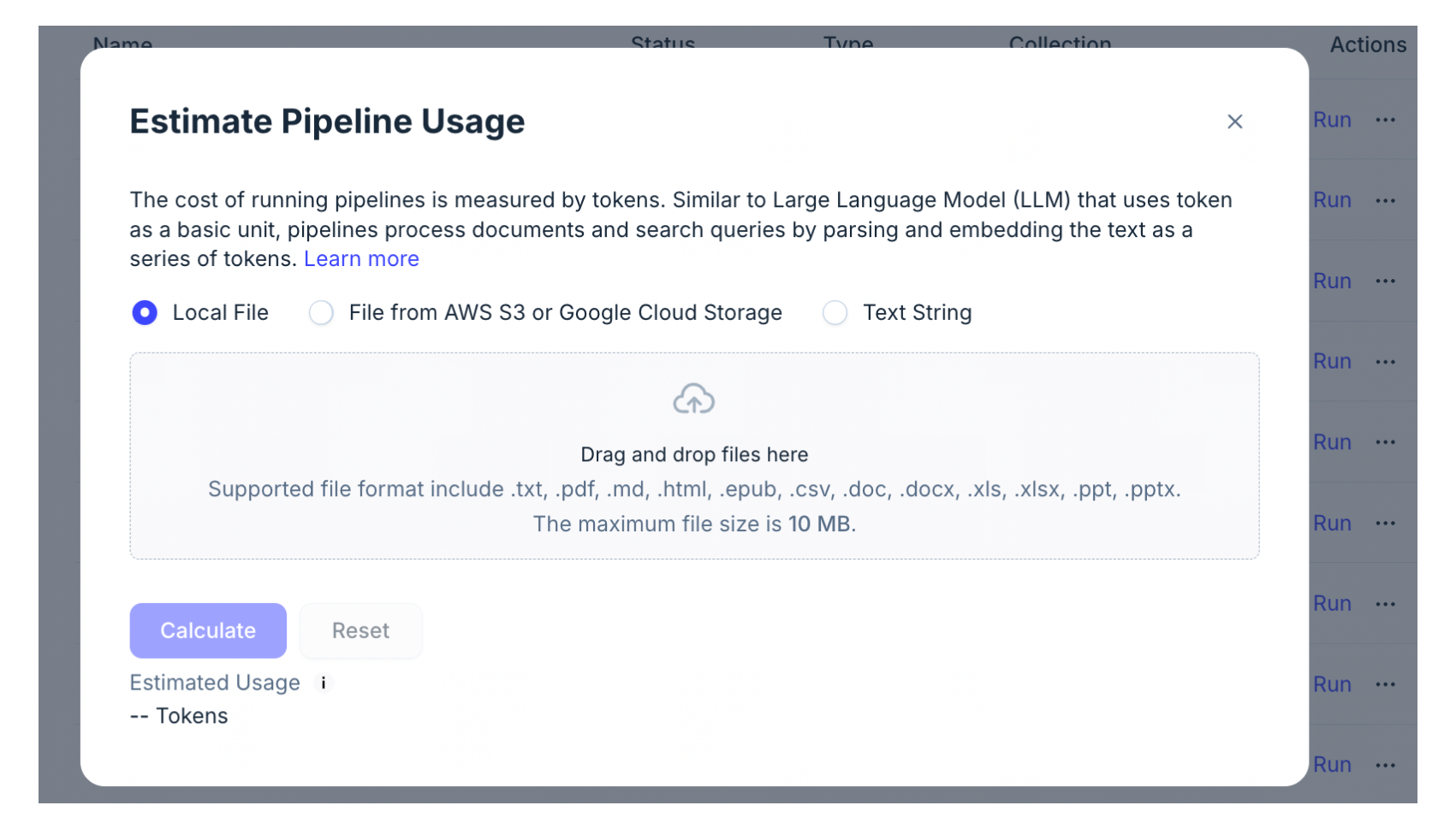
パイプラインの実行に伴うコストの影響を簡単に理解するために、ファイルやテキスト文字列のトークンを推定できるWeb UIツールを提供しています。このツールを使用して、パイプラインを実行する前にコストを推定できます。
-
入力する
-
インジェスチョンパイプラインは、ファイルを入力として受け取ります。ローカルファイルを直接アップロードするか、オブジェクトストレージからファイルを使用して、インジェスチョンパイプラインの実行の使用状況を推定できます。
-
検索パイプラインはクエリ文字列を入力として受け取ります。テキスト文字列を直接入力することで、検索パイプラインの実行状況を推定することができます。
- 入力ボックスにトークン化するテキストを直接入力してください。
📘ノート最大10万文字まで入力できます。
-
-
「計算」をクリックします。
-
ファイルの推定トークン数を確認してください。
-
[リセット]をクリックして、別のローカルファイルをアップロードします。