外部移行の基本
外部移行は、ベクトルデータベースや検索システムを Zilliz Cloud に移動するプロセスを簡素化します。Pinecone や Qdrant などのベクトルデータベースから、Elasticsearch や OpenSearch などのベクトル機能を備えた検索エンジンまで、Zilliz Cloud はデータの整合性を確保しつつ移行の複雑さを最小限に抑えるための移行ツールを提供します。
サポートされているデータソース
Zilliz Cloud は、主要なベクトルデータベースおよび検索プラットフォームからの移行をサポートしています:
データソース | タイプ | 主な機能 |
|---|---|---|
ベクトルデータベース | 類似度検索を備えたサーバーレスインデックス | |
ベクトルデータベース | オープンソースエンジン、クラウドおよびセルフホスト型 | |
検索エンジン | 全文検索をサポートする密ベクトル | |
リレーショナルデータベース | ベクトル拡張機能 (pgvector) のサポート | |
マネージドサービス | マネージドベクトルデータベースサービス | |
検索プラットフォーム | ベクトル機能を備えた KNN プラグイン |
コア機能
当社の移行ツールは、データ構造が Zilliz Cloud に完璧に適合することを保証するための広範な設定オプションを提供します:
機能カテゴリ | 機能 | 説明 |
|---|---|---|
スキーマ制御 | フィールド名のカスタマイズ | 希望する命名スタイルに合わせて、移行中にフィールド名を変更します |
動的フィールドから固定フィールドへ | 柔軟なメタデータを、より良いパフォーマンスのために固定された構造化フィールドに変換します。 メタデータにテキストが含まれている場合、それを固定フィールドに変換すると | |
追加フィールド | 進化する要件に対応するために、ソースデータ以外の新しいフィールドを追加します | |
データ型マッピング | Zilliz Cloud はフィールド型を自動的に検出してマッピングしますが、手動で調整するオプションもあります | |
コレクション設定 | スマートネーミング | デフォルトでは、Zilliz Cloud はターゲットコレクションに対してソーステーブル名を保持します。重複した名前が検出された場合、システムはエラーアラートを発行し、ユーザーに名前の変更を促します。ソーステーブル名にハイフン ( |
シャード設定 | データのクエリ方法に合わせてデータ分布を設定します | |
パーティション戦略 | 自動パーティショニングまたはカスタムグループ化を使用してデータを整理します | |
データ整合性 | 主キーの処理 | レコードの一意の識別子を作成、保持、または変更します |
フィールド属性 | フィールドに null 値を含めることができるかどうかを設定し、デフォルト値を定義します | |
検証チェック | 移行の詳細を示す詳細な移行レポートにアクセスします | |
全文検索 | 移行中に VARCHAR フィールドに対して全文検索を有効にします | 詳細設定 → 機能 で設定し、移行中に VARCHAR フィールドに対して全文検索を有効にします。 ソースにメタデータ内のテキストが含まれている場合は、固定フィールドに変換 を使用してテキストメタデータから VARCHAR を作成します。詳細については 全文検索 を参照してください。 |
移行プロセス
移行は、データの整合性を確保し、プロセス全体を通じて可視性を提供するように設計された 3 つのフェーズに従います:
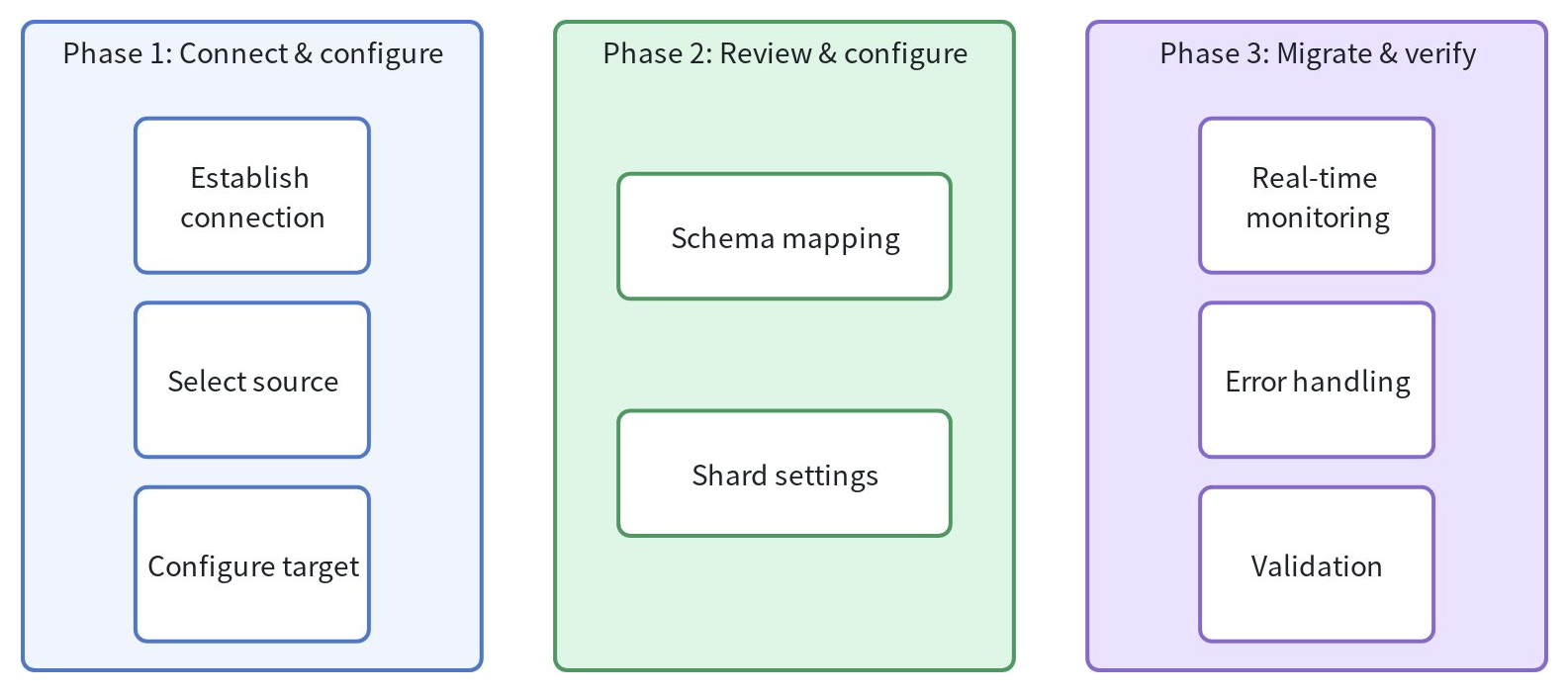
フェーズ 1: 接続と設定
-
接続を確立する: 認証情報(API キー、接続文字列)を提供してソースシステムにアクセスし、接続をテストします
-
ソースデータの選択: 移行する特定のインデックス、コレクション、またはテーブルを選択します
-
ターゲットの設定: 宛先として Zilliz Cloud クラスターとデータベースを選択します
フェーズ 2: マッピングの確認
このフェーズには、2 つの主要なコンポーネントが含まれます:
スキーママッピング
-
自動検出: システムがベクトルフィールド、スカラーフィールド、およびメタデータを識別します
-
フィールドのカスタマイズ: 必要に応じてフィールド名とタイプを調整します
-
型変換: ソースとターゲット間のデータ型マッピングを確認し、確定します
-
詳細オプション: 要件に基づいてシャード、パーティションキー、および null 許容フィールドを設定します
シャード設定
最適なパフォーマンスを得るために、データ量に基づいてシャードを設定します:
-
小規模データセット (≤100M 行): 通常、単一のシャードで十分です
-
大規模データセット (>1B 行): 最適なシャード構成については サポートにお問い合わせください
フェーズ 3: 移行と検証
設定が完了したら、移行を実行し、進捗を追跡します:
-
リアルタイム監視: ジョブページを通じて移行ステータスを追跡します
-
進捗インジケーター: 移行された行数、エラー数、推定完了時間を表示します
-
エラー処理: 問題が発生した場合は、詳細なコードログを確認します
-
検証: 自動的な行数検証により、データの完全性が保証されます
制限事項
移行を開始する前に、サポートされているすべてのデータソースに共通して適用される以下の一般的な制限事項に注意してください:
考慮事項 | 影響 | ソリューション |
|---|---|---|
自動インデックス作成またはロードなし | コレクションはすぐにクエリできません | 移行後に手動でインデックスを作成し、コレクションをロードします。詳細な手順については、ベクトルフィールドのインデックス作成 および ロードとリリース を参照してください。 |
空のソースデータ | 空のインデックス/テーブルは選択できません | 移行前にソースにデータが含まれていることを確認してください |
ベクトルフィールドの要件 | コレクションにはベクトルデータが含まれている必要があります | 移行前にソースにベクトルフィールドがあることを確認してください |
サポートされていないデータ型 | 一部の特殊なデータ型は転送されない場合があります | データ型マッピングについては、プラットフォーム固有のガイドを確認してください |
始め方
データを Zilliz Cloud に移行する準備はできましたか?
移行ポータルへのアクセス
テキストデータに対する全文検索の設定
ソースにテキストが含まれている場合、移行中に全文検索を設定してテキスト検索を改善できます。詳細については 全文検索 を参照してください。
プラットフォーム固有の移行ガイド
プラットフォーム固有の詳細な手順、前提条件、およびデータマッピング情報については: