全文検索
全文検索は、テキストデータセット内の特定の用語やフレーズを含むドキュメントを取得し、関連性に基づいて結果をランキングする機能です。この機能は、正確な用語を見落とす可能性があるセマンティック検索の制限を克服し、最も正確で文脈的に関連性の高い結果を確実に受け取ることができます。さらに、生テキスト入力を受け付けることでベクトル検索を簡素化し、手動でベクトル埋め込みを生成する必要なく、テキストデータを自動的にスパース埋め込みに変換します。
BM25関連性スコアリングを使用するこの機能は、特定の検索用語と密接に一致するドキュメントを優先するRAG(検索拡張生成)シナリオで特に価値があります。
全文検索をセマンティックベースの密ベクトル検索と統合することで、検索結果の精度と関連性を向上させることができます。詳細については、ハイブリッド検索を参照してください。
Zilliz Cloud は、プログラムによる方法または Web コンソールを介して全文検索を有効化することをサポートしています。このページでは、プログラムによる方法で全文検索を有効化する方法に焦点を当てています。Web コンソールでの操作の詳細については、コレクションの管理(コンソール) を参照してください。
BM25 の実装
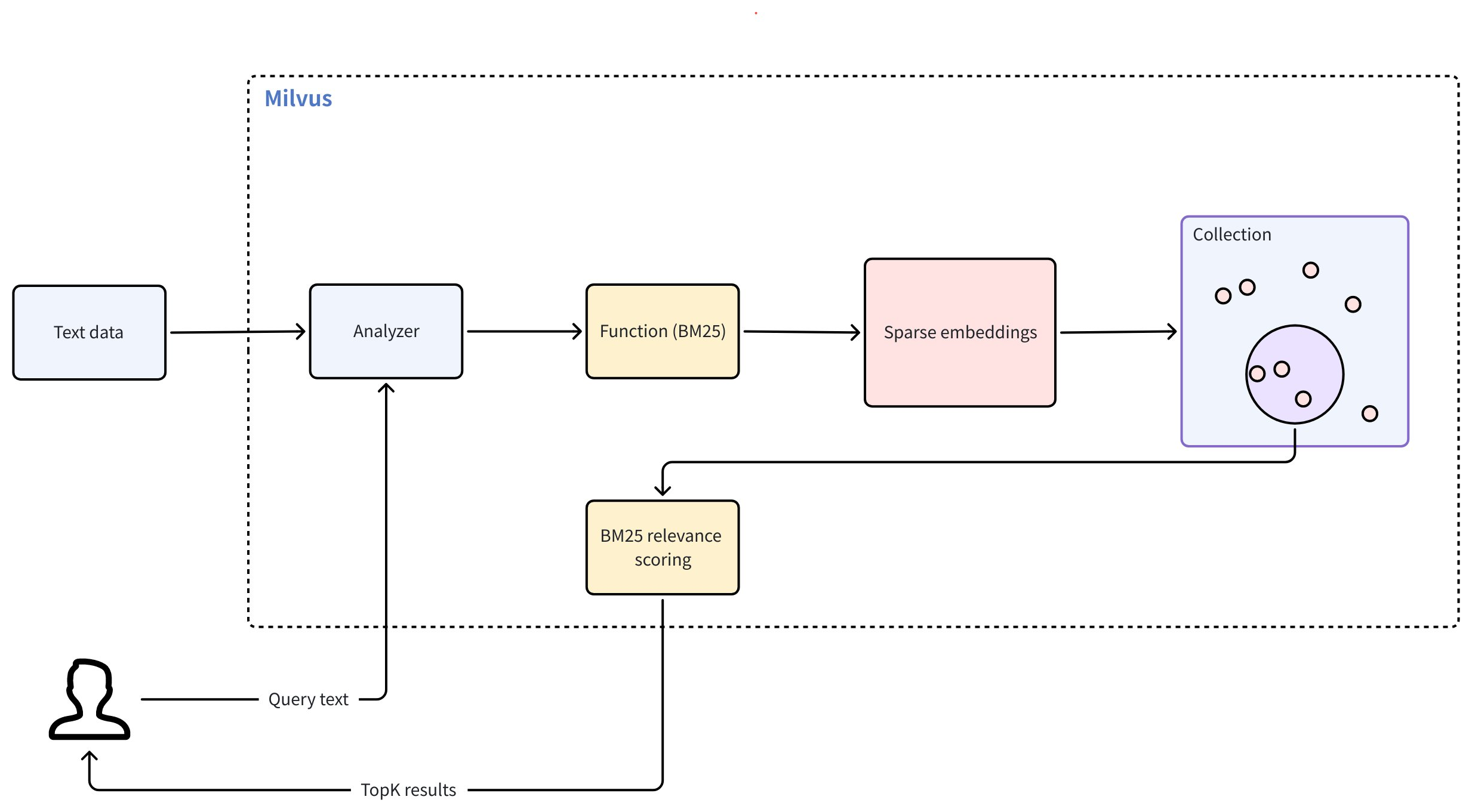
Zilliz Cloud は、情報検索システムで広く採用されているスコアリング関数である BM25 関連性アルゴリズムを活用した全文検索を提供しており、Zilliz Cloud はこれを検索ワークフローに統合して、正確で関連性ランキングされたテキスト結果を提供します。
Zilliz Cloud の全文検索は、以下のワークフローに従います:
-
生テキスト入力: プレーンテキストを使用してテキストドキュメントを挿入したり、クエリを提供したりします。埋め込みモデルは必要ありません。
-
テキスト分析: Zilliz Cloud は アナライザー を使用して、テキストをインデックス化および検索可能な意味のある用語に処理します。
-
BM25関数処理: 組み込み関数がこれらの用語を、BM25 スコアリングに最適化されたスパースベクトル表現に変換します。
-
コレクションストア: Zilliz Cloud は、結果として得られるスパース埋め込みをコレクションに保存し、高速な取得とランキングを実現します。
-
BM25関連性スコアリング: 検索時に、Zilliz Cloud は BM25 スコアリング関数を適用して、ドキュメントの関連性を計算し、クエリ用語に最も一致するランキング結果を返します。
全文検索を使用するには、以下の主要な手順に従います:
-
コレクションの作成: 必要なフィールドを設定し、生テキストをスパース埋め込みに変換する BM25 関数を定義します。
-
データの挿入: 生テキストドキュメントをコレクションに取り込みます。
-
検索の実行: 自然言語のクエリテキストを使用して、BM25 関連性に基づいてランキングされた結果を取得します。
BM25全文検索用のコレクションを作成する
BM25 を活用した全文検索を有効にするには、必要なフィールドを含むコレクションを準備し、スパースベクトルを生成する BM25 関数を定義し、インデックスを構成してから、コレクションを作成する必要があります。
スキーマフィールドの定義
コレクションスキーマには、少なくとも 3 つの必須フィールドを含める必要があります:
-
プライマリフィールド: コレクション内の各エンティティを一意に識別します。
-
テキストフィールド (
VARCHAR): 生テキストドキュメントを保存します。Zilliz Cloud が BM25 関連性ランキングのためにテキストを処理できるよう、enable_analyzer=Trueを設定する必要があります。デフォルトでは、Zilliz Cloud はテキスト分析にstandardアナライザー を使用します。異なるアナライザーを構成するには、アナライザー概要 を参照してください。 -
スパースベクトルフィールド (
SPARSE_FLOAT_VECTOR): BM25 関数によって自動的に生成されたスパース埋め込みを保存します。
- Python
- Java
- Go
- NodeJS
- cURL
from pymilvus import MilvusClient, DataType, Function, FunctionType
client = MilvusClient(
uri="YOUR_CLUSTER_ENDPOINT",
token="YOUR_CLUSTER_TOKEN"
)
schema = client.create_schema()
schema.add_field(field_name="id", datatype=DataType.INT64, is_primary=True, auto_id=True) # Primary field
schema.add_field(field_name="text", datatype=DataType.VARCHAR, max_length=1000, enable_analyzer=True) # Text field
schema.add_field(field_name="sparse", datatype=DataType.SPARSE_FLOAT_VECTOR) # Sparse vector field; no dim required for sparse vectors
import io.milvus.v2.common.DataType;
import io.milvus.v2.service.collection.request.AddFieldReq;
import io.milvus.v2.service.collection.request.CreateCollectionReq;
CreateCollectionReq.CollectionSchema schema = CreateCollectionReq.CollectionSchema.builder()
.build();
schema.addField(AddFieldReq.builder()
.fieldName("id")
.dataType(DataType.Int64)
.isPrimaryKey(true)
.autoID(true)
.build());
schema.addField(AddFieldReq.builder()
.fieldName("text")
.dataType(DataType.VarChar)
.maxLength(1000)
.enableAnalyzer(true)
.build());
schema.addField(AddFieldReq.builder()
.fieldName("sparse")
.dataType(DataType.SparseFloatVector)
.build());
import (
"context"
"fmt"
"github.com/milvus-io/milvus/client/v2/column"
"github.com/milvus-io/milvus/client/v2/entity"
"github.com/milvus-io/milvus/client/v2/index"
"github.com/milvus-io/milvus/client/v2/milvusclient"
)
ctx, cancel := context.WithCancel(context.Background())
defer cancel()
milvusAddr := "YOUR_CLUSTER_ENDPOINT"
token := "YOUR_CLUSTER_TOKEN"
client, err := milvusclient.New(ctx, &milvusclient.ClientConfig{
Address: milvusAddr,
APIKey: token
})
if err != nil {
fmt.Println(err.Error())
// handle error
}
defer client.Close(ctx)
schema := entity.NewSchema()
schema.WithField(entity.NewField().
WithName("id").
WithDataType(entity.FieldTypeInt64).
WithIsPrimaryKey(true).
WithIsAutoID(true),
).WithField(entity.NewField().
WithName("text").
WithDataType(entity.FieldTypeVarChar).
WithEnableAnalyzer(true).
WithMaxLength(1000),
).WithField(entity.NewField().
WithName("sparse").
WithDataType(entity.FieldTypeSparseVector),
)
import { MilvusClient, DataType } from "@zilliz/milvus2-sdk-node";
const address = "YOUR_CLUSTER_ENDPOINT";
const token = "YOUR_CLUSTER_TOKEN";
const client = new MilvusClient({address, token});
const schema = [
{
name: "id",
data_type: DataType.Int64,
is_primary_key: true,
},
{
name: "text",
data_type: "VarChar",
enable_analyzer: true,
enable_match: true,
max_length: 1000,
},
{
name: "sparse",
data_type: DataType.SparseFloatVector,
},
];
console.log(res.results)
export schema='{
"autoId": true,
"enabledDynamicField": false,
"fields": [
{
"fieldName": "id",
"dataType": "Int64",
"isPrimary": true
},
{
"fieldName": "text",
"dataType": "VarChar",
"elementTypeParams": {
"max_length": 1000,
"enable_analyzer": true
}
},
{
"fieldName": "sparse",
"dataType": "SparseFloatVector"
}
]
}'
上記の設定において、
-
id: 主キーとして機能し、auto_id=Trueにより自動的に生成されます。 -
text: 全文検索操作用の生テキストデータを格納します。データ型はVARCHARでなければなりません。これは、Zilliz Cloud におけるテキスト格納用の文字列データ型です。 -
sparse: 全文検索操作のために内部で生成されたスパース埋め込みを格納するためのベクトルフィールドです。データ型はSPARSE_FLOAT_VECTORでなければなりません。
BM25関数の定義
BM25関数は、トークン化されたテキストをBM25スコアリングをサポートする疎ベクトルに変換します。
関数を定義し、スキーマに追加します:
- Python
- Java
- Go
- NodeJS
- cURL
bm25_function = Function(
name="text_bm25_emb", # Function name
input_field_names=["text"], # Name of the VARCHAR field containing raw text data
output_field_names=["sparse"], # Name of the SPARSE_FLOAT_VECTOR field reserved to store generated embeddings
function_type=FunctionType.BM25, # Set to \`BM25\`
)
schema.add_function(bm25_function)
import io.milvus.common.clientenum.FunctionType;
import io.milvus.v2.service.collection.request.CreateCollectionReq.Function;
import java.util.*;
schema.addFunction(Function.builder()
.functionType(FunctionType.BM25)
.name("text_bm25_emb")
.inputFieldNames(Collections.singletonList("text"))
.outputFieldNames(Collections.singletonList("sparse"))
.build());
function := entity.NewFunction().
WithName("text_bm25_emb").
WithInputFields("text").
WithOutputFields("sparse").
WithType(entity.FunctionTypeBM25)
schema.WithFunction(function)
const functions = [
{
name: 'text_bm25_emb',
description: 'bm25 function',
type: FunctionType.BM25,
input_field_names: ['text'],
output_field_names: ['sparse'],
params: {},
},
];
export schema='{
"autoId": true,
"enabledDynamicField": false,
"fields": [
{
"fieldName": "id",
"dataType": "Int64",
"isPrimary": true
},
{
"fieldName": "text",
"dataType": "VarChar",
"elementTypeParams": {
"max_length": 1000,
"enable_analyzer": true
}
},
{
"fieldName": "sparse",
"dataType": "SparseFloatVector"
}
],
"functions": [
{
"name": "text_bm25_emb",
"type": "BM25",
"inputFieldNames": ["text"],
"outputFieldNames": ["sparse"],
"params": {}
}
]
}'
パラメータ | 説明 |
|---|---|
| 関数の名前。この関数は、 |
| テキストから疎ベクトルへの変換が必要な |
| 内部で生成された疎ベクトルを格納するフィールドの名前。 |
| 使用する関数のタイプ。必ず |
複数の VARCHAR フィールドに対して BM25 処理が必要な場合は、各フィールドごとに1つの BM25 関数を定義し、それぞれに一意の名前と出力フィールドを設定してください。
インデックスの設定
必要なフィールドと組み込み関数を使用してスキーマを定義した後、コレクションのインデックスを設定します。このプロセスを簡略化するために、index_type として AUTOINDEX を使用できます。このオプションにより、Zilliz Cloud がデータ構造に基づいて最も適切なインデックスタイプを自動的に選択・設定します。
- Python
- Java
- Go
- NodeJS
- cURL
index_params = client.prepare_index_params()
index_params.add_index(
field_name="sparse",
index_type="AUTOINDEX",
metric_type="BM25"
)
import io.milvus.v2.common.IndexParam;
Map<String,Object> params = new HashMap<>();
params.put("inverted_index_algo", "DAAT_MAXSCORE");
params.put("bm25_k1", 1.2);
params.put("bm25_b", 0.75);
List<IndexParam> indexes = new ArrayList<>();
indexes.add(IndexParam.builder()
.fieldName("sparse")
.indexType(IndexParam.IndexType.AUTOINDEX)
.metricType(IndexParam.MetricType.BM25)
.extraParams(params)
.build());
indexOption := milvusclient.NewCreateIndexOption("my_collection", "sparse",
index.NewAutoIndex(entity.MetricType(entity.BM25)))
.WithExtraParam("inverted_index_algo", "DAAT_MAXSCORE")
.WithExtraParam("bm25_k1", 1.2)
.WithExtraParam("bm25_b", 0.75)
const index_params = [
{
field_name: "sparse",
metric_type: "BM25",
index_type: "SPARSE_INVERTED_INDEX",
params: {
"inverted_index_algo": "DAAT_MAXSCORE",
"bm25_k1": 1.2,
"bm25_b": 0.75
}
},
];
export indexParams='[
{
"fieldName": "sparse",
"metricType": "BM25",
"indexType": "AUTOINDEX",
"params":{
"inverted_index_algo": "DAAT_MAXSCORE",
"bm25_k1": 1.2,
"bm25_b": 0.75
}
}
]'
パラメータ | 説明 |
|---|---|
| インデックスを作成するベクトルフィールドの名前。全文検索の場合、これは生成された疎ベクトルを格納するフィールドである必要があります。この例では、値を |
| 作成するインデックスのタイプ。 |
| このパラメータの値は、全文検索機能のために必ず |
| インデックス固有の追加パラメータを含む辞書。 |
| インデックスの構築およびクエリに使用されるアルゴリズム。有効な値:
|
| 語頻度の飽和度を制御します。値を高くすると、文書ランキングにおける語頻度の重要度が増します。値の範囲: [1.2, 2.0]。 |
| 文書長の正規化の程度を制御します。通常は 0 から 1 の間の値が使用され、一般的なデフォルト値は約 0.75 です。1 の場合、長さの正規化は行われず、0 の場合、完全に正規化されます。 |
Create the collection
次に、定義したスキーマとインデックスパラメータを使用してコレクションを作成します。
- Python
- Java
- Go
- NodeJS
- cURL
client.create_collection(
collection_name='my_collection',
schema=schema,
index_params=index_params
)
import io.milvus.v2.service.collection.request.CreateCollectionReq;
CreateCollectionReq requestCreate = CreateCollectionReq.builder()
.collectionName("my_collection")
.collectionSchema(schema)
.indexParams(indexes)
.build();
client.createCollection(requestCreate);
err = client.CreateCollection(ctx,
milvusclient.NewCreateCollectionOption("my_collection", schema).
WithIndexOptions(indexOption))
if err != nil {
fmt.Println(err.Error())
// handle error
}
await client.create_collection(
collection_name: 'my_collection',
schema: schema,
index_params: index_params,
functions: functions
);
export CLUSTER_ENDPOINT="YOUR_CLUSTER_ENDPOINT"
export TOKEN="YOUR_CLUSTER_TOKEN"
curl --request POST \
--url "${CLUSTER_ENDPOINT}/v2/vectordb/collections/create" \
--header "Authorization: Bearer ${TOKEN}" \
--header "Content-Type: application/json" \
-d "{
\"collectionName\": \"my_collection\",
\"schema\": $schema,
\"indexParams\": $indexParams
}"
テキストデータの挿入
コレクションとインデックスの設定が完了したら、テキストデータを挿入できます。このプロセスでは、生のテキストを提供するだけで済みます。先ほど定義した組み込み関数が、各テキストエントリに対応するスパースベクトルを自動的に生成します。
- Python
- Java
- Go
- NodeJS
- cURL
client.insert('my_collection', [
{'text': 'information retrieval is a field of study.'},
{'text': 'information retrieval focuses on finding relevant information in large datasets.'},
{'text': 'data mining and information retrieval overlap in research.'},
])
import com.google.gson.Gson;
import com.google.gson.JsonObject;
import io.milvus.v2.service.vector.request.InsertReq;
Gson gson = new Gson();
List<JsonObject> rows = Arrays.asList(
gson.fromJson("{\"text\": \"information retrieval is a field of study.\"}", JsonObject.class),
gson.fromJson("{\"text\": \"information retrieval focuses on finding relevant information in large datasets.\"}", JsonObject.class),
gson.fromJson("{\"text\": \"data mining and information retrieval overlap in research.\"}", JsonObject.class)
);
client.insert(InsertReq.builder()
.collectionName("my_collection")
.data(rows)
.build());
// go
await client.insert({
collection_name: 'my_collection',
data: [
{'text': 'information retrieval is a field of study.'},
{'text': 'information retrieval focuses on finding relevant information in large datasets.'},
{'text': 'data mining and information retrieval overlap in research.'},
]);
curl --request POST \
--url "${CLUSTER_ENDPOINT}/v2/vectordb/entities/insert" \
--header "Authorization: Bearer ${TOKEN}" \
--header "Content-Type: application/json" \
-d '{
"data": [
{"text": "information retrieval is a field of study."},
{"text": "information retrieval focuses on finding relevant information in large datasets."},
{"text": "data mining and information retrieval overlap in research."}
],
"collectionName": "my_collection"
}'
フルテキスト検索を実行する
コレクションにデータを挿入したら、生のテキストクエリを使用してフルテキスト検索を実行できます。Zilliz Cloudは自動的にクエリをスパースベクトルに変換し、BM25アルゴリズムを用いてマッチした検索結果をランキングしたうえで、上位K件(limitで指定された件数)の結果を返します。
- Python
- Java
- Go
- NodeJS
- cURL
search_params = {
'params': {'level': 10},
}
res = client.search(
collection_name='my_collection',
data=['whats the focus of information retrieval?'],
anns_field='sparse',
output_fields=['text'], # Fields to return in search results; sparse field cannot be output
limit=3,
search_params=search_params
)
print(res)
import io.milvus.v2.service.vector.request.SearchReq;
import io.milvus.v2.service.vector.request.data.EmbeddedText;
import io.milvus.v2.service.vector.response.SearchResp;
Map<String,Object> searchParams = new HashMap<>();
searchParams.put("level", 10);
SearchResp searchResp = client.search(SearchReq.builder()
.collectionName("my_collection")
.data(Collections.singletonList(new EmbeddedText("whats the focus of information retrieval?")))
.annsField("sparse")
.topK(3)
.searchParams(searchParams)
.outputFields(Collections.singletonList("text"))
.build());
annSearchParams := index.NewCustomAnnParam()
resultSets, err := client.Search(ctx, milvusclient.NewSearchOption(
"my_collection", // collectionName
3, // limit
[]entity.Vector{entity.Text("whats the focus of information retrieval?")},
).WithConsistencyLevel(entity.ClStrong).
WithANNSField("sparse").
WithAnnParam(annSearchParams).
WithOutputFields("text"))
if err != nil {
fmt.Println(err.Error())
// handle error
}
for _, resultSet := range resultSets {
fmt.Println("IDs: ", resultSet.IDs.FieldData().GetScalars())
fmt.Println("Scores: ", resultSet.Scores)
fmt.Println("text: ", resultSet.GetColumn("text").FieldData().GetScalars())
}
await client.search(
collection_name: 'my_collection',
data: ['whats the focus of information retrieval?'],
anns_field: 'sparse',
output_fields: ['text'],
limit: 3,
params: {'level': 10},
)
curl --request POST \
--url "${CLUSTER_ENDPOINT}/v2/vectordb/entities/search" \
--header "Authorization: Bearer ${TOKEN}" \
--header "Content-Type: application/json" \
--data-raw '{
"collectionName": "my_collection",
"data": [
"whats the focus of information retrieval?"
],
"annsField": "sparse",
"limit": 3,
"outputFields": [
"text"
],
"searchParams":{
"params":{}
}
}'
パラメータ | 説明 |
|---|---|
| 検索パラメータを含む辞書。 |
| 簡略化された検索最適化により、検索精度を制御します。詳細については、Tune Recall Rate を参照してください。 |
| 自然言語による生のクエリテキスト。Zilliz Cloud は、BM25関数を使用してテキストクエリを自動的に疎ベクトルに変換します — 事前に計算済みのベクトルを提供しないでください。 |
| 内部で生成された疎ベクトルを含むフィールドの名前。 |
| 検索結果に含めるフィールド名のリスト。BM25関数によって生成された埋め込みを含む疎ベクトルフィールド以外のすべてのフィールドをサポートします。一般的な出力フィールドには、主キー(例: |
| 返される上位一致件数の最大値。 |
FAQ
Can I output or access the 疎ベクトル generated by the BM25関数 in full text search?
いいえ、全文検索において BM25 関数によって生成された疎ベクトルに直接アクセスしたり出力したりすることはできません。詳細は以下の通りです:
-
BM25 関数はランキングおよび検索のために内部で疎ベクトルを生成します
-
これらのベクトルは疎フィールドに保存されますが、
output_fieldsに含めることはできません -
出力できるのは元のテキストフィールドとメタデータ(例:
id、text)のみです
例:
# ❌ This throws an error - you cannot output the sparse field
client.search(
collection_name='my_collection',
data=['query text'],
anns_field='sparse',
output_fields=['text', 'sparse'] # 'sparse' causes an error
limit=3,
search_params=search_params
)
# ✅ This works - output text fields only
client.search(
collection_name='my_collection',
data=['query text'],
anns_field='sparse',
output_fields=['text']
limit=3,
search_params=search_params
)
なぜアクセスできないのに疎ベクトルフィールドを定義する必要があるのですか?
疎ベクトルフィールドは、ユーザーが直接操作しないデータベースのインデックスと同様に、内部検索インデックスとして機能します。
設計思想:
-
関心の分離: ユーザーはテキストを扱い(入出力)、Milvus はベクトルを処理します(内部処理)
-
パフォーマンス: 事前計算された疎ベクトルにより、クエリ時の高速な BM25 ランキングが可能になります
-
ユーザーエクスペリエンス: 複雑なベクトル操作をシンプルなテキストインターフェースの背後に抽象化します
ベクトルへのアクセスが必要な場合:
-
全文検索ではなく、手動の疎ベクトル操作を使用してください
-
カスタム疎ベクトルワークフロー用に別のコレクションを作成してください
詳細については、疎ベクトル を参照してください。