関数とモデル推論の概要
Zilliz Cloud は、セマンティック検索、語彙検索、ハイブリッド検索、およびインテリジェントな再ランキングを含む、現代的な検索システムの構築のための統合検索アーキテクチャを提供します。これらの機能を独立した機能として公開するのではなく、Zilliz Cloud は単一の中核的な抽象化である Function を中心にそれらを整理しています。
Function とは何か?
Zilliz Cloud において、Function は検索ワークフローの定義された段階で特定の操作を適用する、設定可能な実行単位です。
Function は 3 つの実用的な質問に答えます:
-
この操作はいつ実行されるか? 検索前または検索後。
-
どの入力に対して操作するか? 生テキスト、ベクトル表現、または取得された候補結果。
-
どのような出力を生成するか? 検索に使用されるベクトル埋め込み、またはユーザーに返される再順序付けされた結果。
ワークフローの観点から、Function は 2 つの異なる段階で検索に参加します:
-
検索前: Function は検索前に実行され、テキストをベクトル表現に変換します。これらのベクトルは、どの候補が取得されるかを決定します。
-
検索後: Function は候補取得後に実行され、結果の順序を洗練させますが、候補セットは変更しません。
以下の図は、検索ワークフローにおける Function の動作の抽象化を示しています。
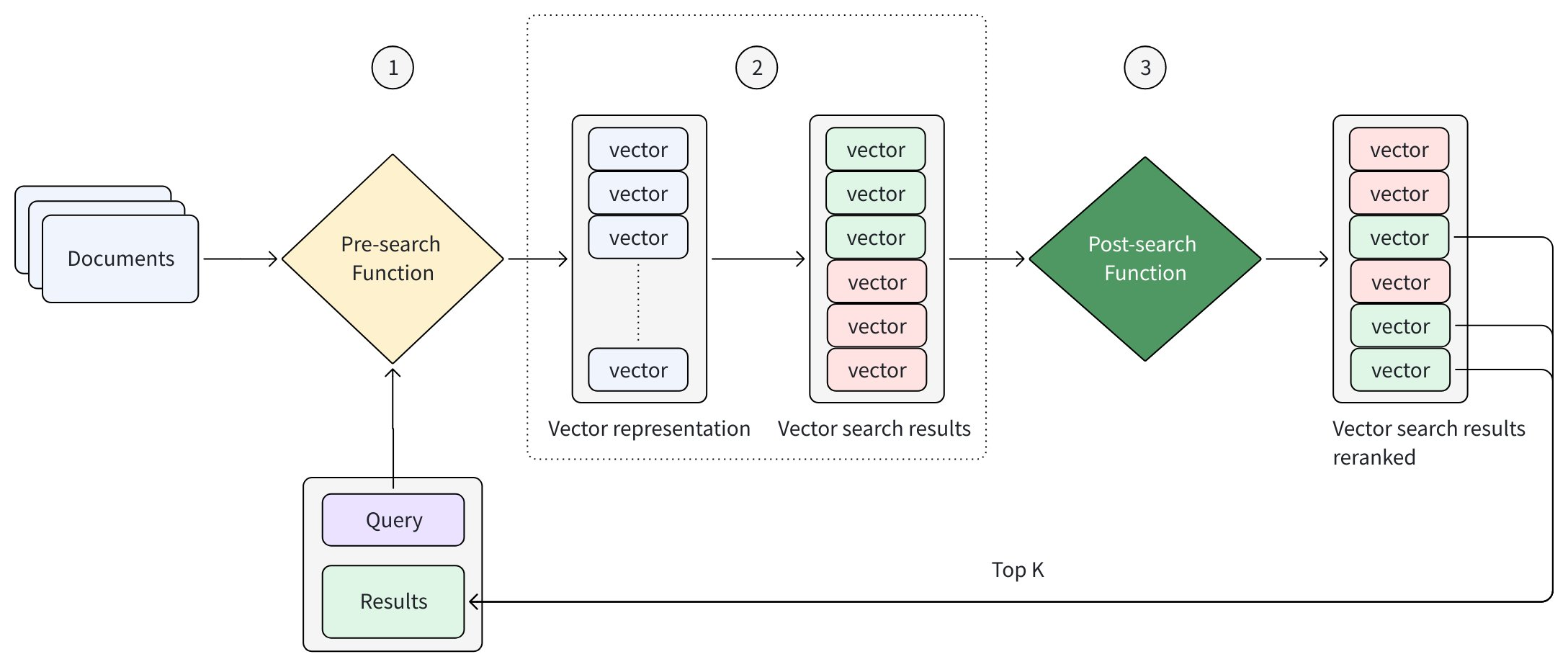
すべての検索リクエストは、同じ高レベルのフローに従います:
-
検索前関数 が入力テキストからベクトル表現を生成します
-
検索エンジンがこれらのベクトルに基づいて候補結果を取得します
-
(オプション)検索後関数 が取得された候補を再ランキングします
Function のカテゴリ
Zilliz Cloud の Function は、検索ワークフロー内でいつ実行されるか、および それらが果たす役割 に基づいて分類されます。高レベルでは、Function は 2 つのグループに分かれます:
-
検索前関数 — テキストをベクトル埋め込みに変換し、候補取得を決定する
-
検索後関数 — 取得された候補の順序を洗練させる
検索前関数:テキストをベクトル埋め込みに変換
検索前関数 は候補取得前に実行されます。その役割は、保存されたドキュメントと受信クエリの両方の生テキストを、検索エンジンが関連候補を特定するために使用するベクトル表現に変換することです。
異なる検索前関数は異なるタイプの埋め込みを生成し、これは取得の実行方法に直接影響します。
以下の表は、利用可能な検索前関数をまとめたものです:
Function Type | Vector Type | Description | Typical Scenarios |
|---|---|---|---|
BM25 Function | Sparse embeddings | Computes lexical relevance based on term matching, term frequency, and document length normalization. Executes entirely within the database engine as a local mechanism; no model inference required. | キーword-driven full text search, documentation and code search, and workloads where term matching, low latency, and deterministic behavior are critical. |
Model-based Embedding Functions | Dense embeddings | Encodes the semantic meaning of text using machine learning models, enabling similarity-based retrieval beyond exact keywords. Requires model inference via hosted models or third-party model services. | セマンティック検索, natural-language queries, Q&A and RAG pipelines, and use cases where conceptual similarity matters more than literal term overlap. |
すべての検索前関数は、ドキュメントデータとクエリテキストの両方に一貫して適用され、同じ表現空間内で検索が実行されることを保証します。
検索後関数:候補結果を再ランキング
検索後関数は 候補取得後 に適用されます。その目的は、候補セットから項目を追加または削除することなく、取得された候補のランキングを洗練させる ことです。
これらの関数は、検索段階によって返された結果のみを対象とし、結果の品質を向上させるための追加のランキングロジックまたは関連性シグナルを適用します。これらはインデックス作成、取得、またはフィルタリングの動作には影響しません — 結果の最終的な順序のみに影響します。
以下の表は、利用可能な検索後関数をまとめたものです:
Function Type | Operates On | Description | Typical Scenarios |
|---|---|---|---|
Hybrid Search Rankers | Multiple result sets retrieved from hybrid search | Combine and rebalance results retrieved from different retrieval strategies using methods such as weighted ranking or reciprocal rank fusion (RRF). | Hybrid search scenarios that combine semantic and lexical retrieval and require balanced result fusion. |
Rule-based Rankers | Candidate results from single-vector or hybrid search | Adjust ranking based on predefined rules or numeric signals, such as boosting or decay-based scoring. | Business-driven ranking logic, recency or popularity boosts, and scenarios requiring predictable, non-ML reranking. |
モデルベースのランカー | Candidate results from single-vector or hybrid search | Use machine learning models to evaluate relevance and reorder results based on learned or semantic signals. | Intelligent reranking, relevance refinement using semantic understanding, and LLM-based relevance evaluation. |
検索後関数は取得された候補のみを対象とするため、これらは取得スコープではなく結果の順序に影響を与える洗練ステップです。
モデル推論を理解する
Zilliz Cloud の Function ベースのアーキテクチャにおいて、モデル推論は独立した概念または実行段階ではありません。代わりに、機械学習ベースのシグナルが必要な特定の Function タイプによって使用される実装の詳細です。
モデル推論の位置づけ
モデル推論とは、セマンティックシグナルを生成するために機械学習モデルを実行時に実行することを指します。例えば:
-
テキストから派生した密なベクトル埋め込み
-
検索結果を再ランキングするために使用される関連性スコア
Zilliz Cloud 内では、モデル推論は モデルベースの関数 によってのみ使用されます。これには以下が含まれます:
-
モデルベースの検索前関数 — 生テキストを密なベクトル埋め込みに変換する
-
モデルベースのランカー — 関連性を評価し、取得された候補を再順序付けする
BM25 Function やルールベースのランカーなどの他の Function は、データベースエンジン内で完全に実行され、モデル推論を必要としません。
モデル推論のソース
Zilliz Cloud は 2 つのモデル推論のソースをサポートしています。両方ともモデルベースの機能を提供しますが、モデルのプロビジョニングと管理方法が異なります:
Aspect | Hosted Models | Third-Party Model Services |
|---|---|---|
Where models run | Inside Zilliz Cloud | External model provider (OpenAI, Voyage AI, etc.) |
Who manages models | Zilliz Cloud | External model provider |
How access is set up | Zilliz Cloud サポート経由 | Through モデルプロバイダー連携 on your own |
Credentials | Provided during onboarding with Zilliz Cloud support | Provided by you (for example, API keys) |
Typical use cases | Tightly integrated or customized deployments | Using standard models from established providers |
Setup complexity | Higher (requires onboarding) | Lower (connect your existing API keys) |
Hosted Models を選択する場合:
-
Zilliz Cloud との緊密な統合が必要な場合(単一ベンダー、統合サポート)
-
カスタムモデルのファインチューニングや専用モデルが必要な場合
-
予測可能なパフォーマンスとレイテンシが必要な場合
-
クレデンシャル管理の簡素化が必要な場合
Third-Party Model Services を選択する場合:
-
すでにモデルプロバイダーとの既存の関係がある場合
-
OpenAI などのプロバイダーから最新のモデルを活用したい場合
-
プロバイダーの切り替えの柔軟性を好む場合
サポートされているモデルプロバイダー
Zilliz Cloud は、異なる機能を提供する主要なモデルプロバイダーと連携しています。以下の表は、どのプロバイダーがテキスト埋め込みと再ランキングをサポートしているかを示しています:
Provider availability and supported capabilities may vary by region and release. Refer to provider-specific documentation for the most up-to-date information.
モデルプロバイダー | Text Embedding | Reranking |
|---|---|---|
OpenAI | No | |
Voyage AI | ||
Cohere |