コレクションの管理(コンソール)
コレクションは、ベクトル埋め込みとメタデータを格納するための2次元テーブルです。コレクション内のすべてのエンティティは同じスキーマを共有します。データ管理やマルチテナンシーの目的で、複数のコレクションを作成できます。
このガイドでは、Webコンソールでのコレクションの作成と管理の操作について説明します。これは、ビジュアルインターフェースを好むユーザーを対象としています。SDKに慣れている場合は、SDKを通じてコレクションを作成および管理することもできます。詳細については、コレクションの作成 を参照してください。
強力なデータ分離が必要で、管理するテナントの数が少ない場合は、各テナントに対して個別のコレクションを作成できます。
ただし、クラスタープラン に応じて、最大16,384個のコレクションしか作成できません。そのため、大規模なマルチテナンシーの場合は、ユースケースに応じて、パーティションベースまたはパーティションキーベースのマルチテナンシーなどの代替戦略を検討してください。詳細については、マルチテナンシーの実装 を参照してください。
コレクションの作成
Zilliz Cloud コンソールでは、3つの方法でコレクションを作成でき、それぞれ異なるシナリオ向けに設計されています。
-
独自のコレクションを作成: スキーマとインデックスパラメータをカスタマイズして、データセットとユースケースに合わせます。スキーマを細かく制御する必要があるユーザーに最適です。
-
サンプルコレクションを作成: 事前定義されたスキーマとサンプルデータセットですばやくコレクションをセットアップします。Zilliz Cloud を初めて利用する新規ユーザーにおすすめです。
-
既存のコレクションをデータ付きでクローン: 同じデータベース内で既存のコレクションを複製します。テスト用コレクションから本番用コレクションにスキーマとデータの両方をコピーする必要がある環境複製シナリオで有用です。
-
既存のスキーマから作成: 既存のコレクションのスキーマを使用して新しいコレクションをすばやく作成し、確定前に編集するオプションがあります。
以下のデモでは、Web UI でこれらの機能を見つける場所を示しています。
コレクションの作成時に遭遇する概念の一部を以下に示します。
コレクションの基本情報
コレクションのメタデータには以下が含まれます。
-
コレクション名
-
(オプション)コレクションの説明。最大 1024(UTF-8 バイト)です。
-
コレクションが属するデータベース。データベース は、クラスターとコレクションの間のレイヤーであり、コレクションを管理および整理するための論理コンテナーとして機能します。関連するコレクションを同じデータベース下にグループ化できます。
コレクションスキーマ
スキーマはコレクションのデータ構造を定義し、以下を含む必要があります。
-
プライマリキー(PK)フィールド 1つ
-
ベクトルフィールドは少なくとも1つ。コレクションで許可されるベクトルフィールドの数の制限については、Zilliz Cloud 制限s を参照してください。
-
(オプション)メタデータ用のスカラーフィールド
-
(オプション)動的フィールド。動的フィールドの有効化により、既存のスキーマを変更せずにデータ挿入時にフィールドを追加できるため、コレクションスキーマに柔軟性が提供されます。データ構造が固定されていない場合は、動的フィールドを有効にすることをおすすめします。フィルターやクエリで頻繁に使用されるフィールドについては、動的フィールドを使用するのではなく、事前にスキーマで定義すると、最適なクエリパフォーマンスを維持するのに役立ちます。
スキーマ設定のほとんどは、コレクションが作成されると変更できません。現在および将来のビジネスニーズを満たすように、スキーマを慎重に設計してください。ベストプラクティスについては、Schema Explained を参照してください。
インデックス
インデックスは、検索とクエリを高速化するためにデータを整理するデータ構造です。Zilliz Cloud では、2種類のインデックスをサポートしています。
-
ベクトルインデックス: AUTOINDEX を使用して自動的に作成され、ベクトル検索を高速化します。スキーマに複数のベクトルフィールドがある場合、各ベクトルフィールドに対して個別のインデックスを作成できます。また、ベクトル間の距離を計算するために使用されるメトリックタイプと、インデックスのコスト、パフォーマンス、容量のトレードオフを制御する基盤となる量子化戦略を制御するインデックス構築レベルを編集することもできます。
-
スカラーインデックス: デフォルトで、Zilliz Cloud はスカラーフィールドのインデックスを自動的に作成しません。ただし、フィルタリングに一般的に使用されるスカラーフィールドに手動でインデックスを作成し、検索とクエリを高速化できます。
コレクションの作成時にインデックスの作成をスキップし、後でインデックスを追加することもできます。詳細については、Indexes を参照してください。
関数
Zilliz Cloud では、関数 は、データ挿入とクエリ実行時にコレクション内でテキスト関連機能がどのように適用されるかを定義します。
関数は、適用されるタイミングに基づいて2つの主要なカテゴリに分類されます。
-
検索前関数
検索前関数は、生のテキストを取得に使用できるベクトル表現に変換する方法を定義します。これらはコレクションの作成時に設定され、コレクションのスキーマの一部になります。
検索前関数の例には、BM25関数、モデルベースの関数などがあります。
検索前関数の動作の概念的な概要については、Function Overview を参照してください。
-
検索後関数
検索後関数は、クエリ時に検索結果の順序を最適化します。検索前関数とは異なり、検索後関数はコレクションのスキーマにバインドされません。これらは検索リクエストのパラメータとして指定され、検索によって返された候補結果に対して操作します。
検索後関数は、インデックス作成や候補の取得には影響しません。
検索後関数の動作の概念的な概要については、Function Overview を参照してください。
パーティションとパーティションキー
パーティション: パーティションは、コレクションの物理的なサブセットです。パーティションは親コレクションと同じデータスキーマを共有しますが、コレクション内のデータの一部のみを含みます。各コレクションには、デフォルトで1つのパーティションが付属しています。マルチテナンシーやデータ管理の目的で、手動でさらにパーティションを追加できます。追加のパーティションが作成されていない場合、コレクションに挿入されたすべてのデータはデフォルトのパーティションに入ります。詳細については、パーティションの管理 を参照してください。
パーティションキー: パーティションキーは、パーティションに基づく検索最適化ソリューションです。非プライマリキーの INT64 または VARCHAR フィールドをパーティションキーとして指定すると、Zilliz Cloud によって自動的に16個のパーティションが作成され、挿入されたすべてのエンティティはそのパーティションキーの値に基づいてこれら16個の自動生成されたパーティションに入ります。コレクションでパーティションキーが有効になると、このコレクションで手動でパーティションを作成することはできなくなります。詳細については、パーティションキーの使用 を参照してください。
パーティションを作成する必要があるか、パーティションキーを使用する必要があるかを判断するために、以下の要因を考慮できます。
-
マルチテナンシー戦略: 数百万のテナントをサポートする必要がある場合は、パーティションキーを使用してください。テナント間で強力な物理的データ分離が必要な場合は、パーティションを使用してください。詳細については、マルチテナンシーの実装 を参照してください。
-
リソース管理: 自分でパーティションの作成と管理を行いたい場合は、パーティションを使用することを選択できます。パーティションの自動作成と管理が必要な場合は、パーティションキーを使用してください。
-
ホットデータとコールドデータの管理: ホットデータとコールドデータを効率的に処理する必要がある場合は、パーティションキーを使用してください。Dedicated クラスターでホットデータとコールドデータの管理にパーティションキーを使用するには、お問い合わせください。
mmap
メモリマッピング(mmap)は、ディスク上の大きなファイルをメモリに読み込まずに直接アクセスできるようにするメモリ使用量の最適化です。mmap を有効にすると、同じ CU サイズ仕様でより多くのデータを保存できます。以下に示すように、mmap は CU タイプとプランに基づいて推奨されるデフォルトで設定されています。
-
Free、Serverless、および拡張容量 CU タイプの Dedicated クラスターでは、mmap がデフォルトで有効になっています。この設定は固定されて変更できないため、コレクションの作成時に mmap の構成オプションが表示されない場合があります。
-
パフォーマンス最適化 CU タイプの Dedicated クラスターでは、mmap がデフォルトで無効になっています。
-
容量最適化 CU タイプの Dedicated クラスターでは、mmap がデフォルトで有効になっています。
クラスターレベルのデフォルトの mmap 設定の詳細については、mmap の使用 を参照してください。
コレクションの作成時に、ユースケースに応じて、コレクション レベルまたは フィールド レベルで mmap 設定をオプションで構成できます。低いレベルの設定は高いレベルの設定より優先されます: フィールド > コレクション > クラスター。
-
コレクションレベルの mmap: コレクション全体の生データに対して mmap を有効にします。この設定は後で変更できますが、まずコレクションをリリースする必要があります。
-
フィールドレベルの mmap: カスタム設定を介して、選択したフィールドの生データとスカラーインデックスに対して mmap を有効にします。一般に、データサイズが大きく、頻繁にフィルタリングやクエリが行われないフィールドに対して mmap を有効にすることをおすすめします。この設定は選択したフィールドにのみ適用され、後で変更できます。フィールドレベルの mmap 設定を変更するには、まずコレクションをリリースする必要があります。
mmap 設定には注意してください。デフォルトの mmap 設定を変更すると、パフォーマンスの低下やメモリ不足(OOM)の問題によるロード失敗が発生する可能性があります。ベストプラクティスについては、mmap の使用 を参照してください。
以下のデモでは、Zilliz Cloud Web コンソールでのこの機能の入り口を示しています。
シャード
シャードは、データ入力チャネルに対応するコレクションの水平スライスです。すべてのコレクションには、デフォルトで1つのシャードが付属しています。書き込みスループットを増やすために、さらにシャードを追加できます。
一般的なガイドラインとして、1億行のデータごとに1つのシャードを追加することを検討してください。許可される最大シャード数は、クラスタープランとクラスターの CU サイズによって異なります。詳細については、Zilliz Cloud 制限s を参照してください。
シャードの数は、コレクションが作成された後、コレクションのクローン 機能を介して後で編集できます。
フルテキスト検索
Zilliz Cloud コンソールでは、フルテキスト検索で使用する関数とアナライザーの構成をサポートしています。フルテキスト検索の詳細については、フルテキスト検索 を参照してください。
以下のデモでは、Zilliz Cloud Web コンソールでのこの機能の入り口を示しています。
テキスト一致
Zilliz Cloud コンソールでは、テキスト一致のフィールドとアナライザーの構成もサポートしています。テキスト一致の詳細については、テキスト一致 を参照してください。
以下のデモでは、Zilliz Cloud Web コンソールでのこの機能の入り口を示しています。
コレクションの管理
Zilliz Cloud では、Web コンソールを介して作成されたコレクションに対して、以下の管理操作をサポートしています。
-
コレクションの名前変更: 既存のコレクションの名前を変更できます。
-
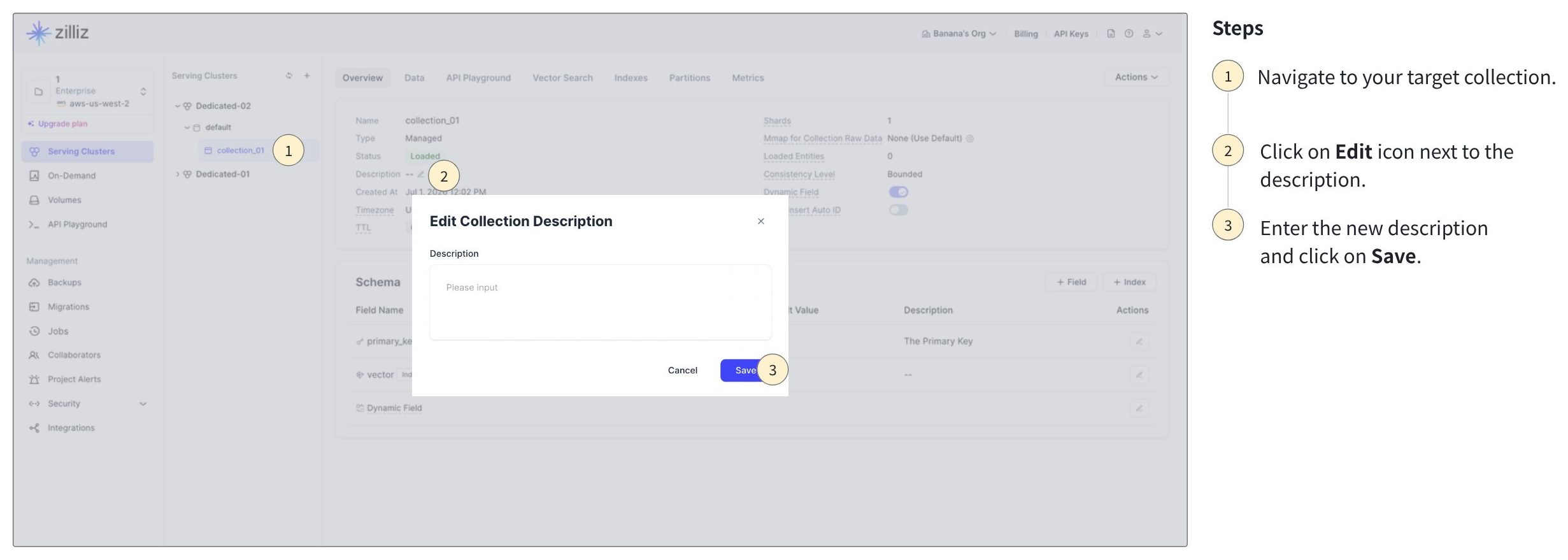
コレクションの説明の編集: 既存のコレクションの説明を変更できます。
-
コレクションスキーマと設定の編集: 現在、Zilliz Cloud では以下のスキーマと設定の編集のみをサポートしています。
-
既存の VARCHAR フィールド の
max_length値を編集できます。 -
既存の ARRAY フィールド の
max_capacity値、および ARRAY タイプが VARCHAR の場合はmax_length値も編集できます。 -
既存のスキーマに新しいスカラーフィールドを追加できます。
-
シャード 設定を変更するには、代わりに コレクションのクローン 機能を使用してください。
-
mmap または パーティションキー 設定を変更するには、代わりに SDK を使用してください。詳細については、コレクションの変更 を参照してください。
-
コレクションの作成時に動的フィールドを有効にしていない場合は、後で SDK または Web コンソールを使用して有効にできます。SDK の詳細については、コレクションの変更 を参照してください。Web コンソールで動的フィールドを有効にする方法の詳細については、上記のデモを参照してください。
その他のコレクションスキーマ設定は編集できません。変更を適用するには、希望の構成で新しいコレクションを作成し、データをインポートしてください。
-
-
コレクションのロードとリリース: Zilliz Cloud Web コンソールでは、コレクションは作成後すぐに自動的にメモリにロードされ、検索とクエリで利用できるようになります。メモリ領域を解放するには、使用していないコレクションをリリースできます。Zilliz Cloud Web コンソールでは、単一のコレクションのロードまたはリリース、または複数のコレクションの一括ロードまたはリリースをサポートしています。
-
コレクションを別のデータベースに移動: 関連するコレクションを同じデータベース内にグループ化し、必要に応じてコレクションをデータベース間で移動できます。
-
コレクション内のパーティションの管理: パーティションキーが有効になっているコレクションでは、パーティションを手動で管理する必要はありません。パーティションキーが無効になっているコレクションでは、パーティションを手動で管理し、以下の操作を実行できます。
-
パーティションの作成: 各コレクションで最大1,024個のパーティションを作成できます。詳細については、Zilliz Cloud 制限s を参照してください。
-
パーティションの削除: デフォルトのパーティションは削除できず、パーティションを削除すると、その中のすべてのデータが不可逆的に削除されます。コレクション内のパーティションを削除する前に、まずコレクションをリリースする必要があります。
-
-
コレクションエイリアスの表示: コレクションリストページで、クラスター内のすべてのコレクションのエイリアスを表示できます。
-
コレクションタイムゾーンの編集: コレクションタイムゾーンは、このコレクション内のすべての TIMESTAMPTZ エンティティのタイムゾーンを定義します。デフォルトでは UTC を使用しますが、アプリケーションのニーズに合わせて別のタイムゾーンを選択できます。
-
コレクション TTL の編集: Time-to-live(TTL)は、コレクション内のデータの有効期限を決定するコレクションプロパティです。詳細については、コレクション TTL の設定 を参照してください。
-
Allow Insert 自動ID の有効化:
allow_insert_auto_idプロパティにより、AutoID が有効になっているコレクションが、insert、upsert、および一括インポート時にユーザーが提供したプライマリキー値を受け入れることができます。詳細については、コレクションの変更 を参照してください。 -
コレクションの削除: リソースオーバーヘッドを削減するために、不要になったコレクションを削除できます。コレクションを削除すると、その中のすべてのデータが不可逆的に削除されます。
コレクションデータのプレビュー
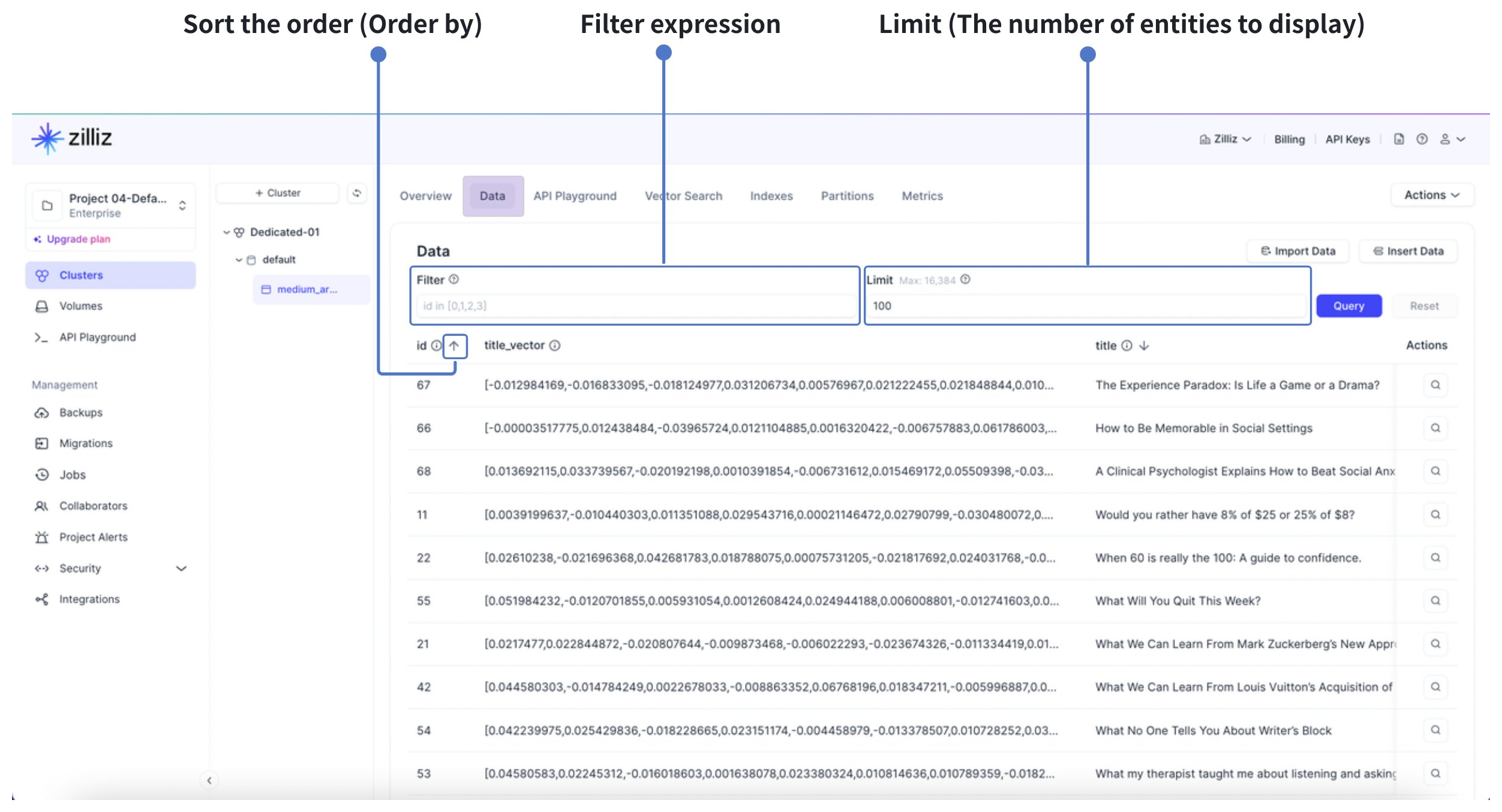
データ タブを使用して、Zilliz Cloud コンソールから直接コレクション内のエンティティをプレビューします。
フィルター式を定義し、limit パラメータを構成してプレビューに表示されるエンティティの数を制御(デフォルトで100、最大16,384)し、一致するエンティティをクエリして、テーブル内のフィールド値を確認できます。
また、Order By を使用して、プライマリキーフィールド、数値フィールド、またはスカラーフィールドでデータプレビューを昇順または降順に並べ替えることもできます。