データのマージAbout to Deprecate
既存の Zilliz Cloud コレクションのデータと、ローカルファイルまたは外部オブジェクトストレージバケットのデータをマージして、両方のソースからのデータを組み合わせたコレクションを作成できます。これをデータマージ操作と呼び、既存のコレクションにデータを持つフィールドを追加する回避策として使用できます。
- この機能は現在 PRIVATE PREVIEW です。この機能に興味があり、試してみたい場合は、遠慮なく Zilliz Cloud サポート までお問い合わせください。
概要
データマージ操作は、リレーショナルデータベースの LEFT JOIN 操作に似ており、コレクションのデータと指定されたデータソースからのすべての一致するレコードを組み合わせ、マージされたデータを新しいコレクションに保存します。
データソースは、Zilliz Cloud ボリュームまたはオブジェクトストレージバケットに保存された一連の PARQUET ファイルである必要があります。
次の図に示すように、3つのフィールドを含むコレクションがあり、id フィールドがプライマリキーとして機能しています。さらに、id と date という2つのフィールドを持つ PARQUET ファイルがあります。id フィールドはマージキーとして機能し、その値はソースコレクションの値と一致する必要があります。date フィールドは追加するフィールドです。
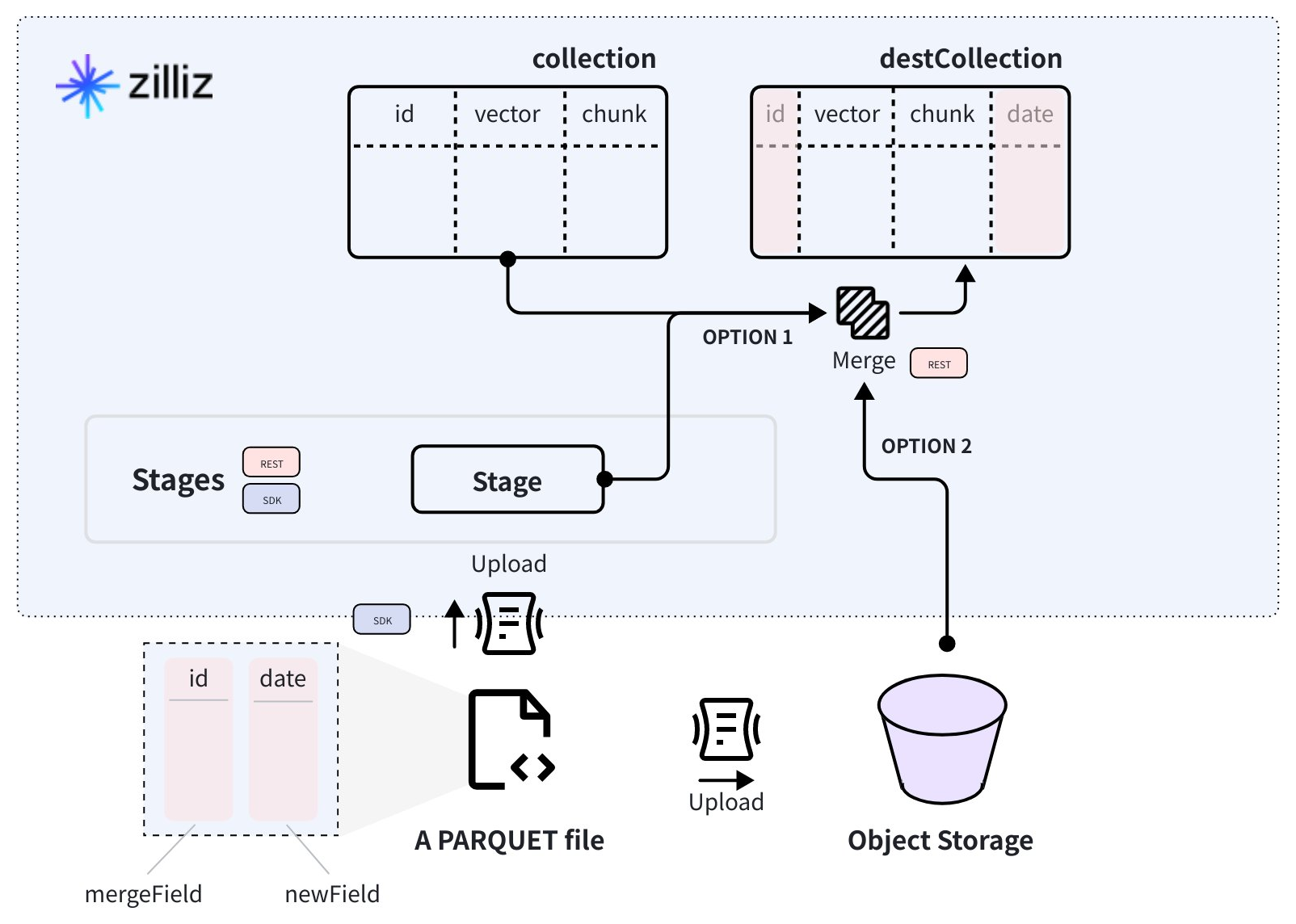
PARQUET ファイルを Zilliz Cloud ボリュームまたはオブジェクトストレージバケットにアップロードしたら、Merge データ API を使用して、両方のソースからのデータを保存するターゲットコレクションを作成できます。
データソースはオプションです。データソースを指定せずに Merge データ API を使用して、既存のコレクションにフィールドを追加する回避策としても使用できます。
このガイドでは、Merge データ API を使用して、データを持つフィールドとデータを持たないフィールドを追加する方法を説明します。
データを持つフィールドの追加
データを持つフィールドを追加するには、ソースコレクション、データソース、およびターゲットコレクションに追加する新しいフィールドを提供する必要があります。
データソースは、Zilliz Cloud ボリュームまたは AWS S3 バケット内の一連の PARQUET ファイルである必要があります。
ボリュームの使用
ボリュームを使用してデータマージ操作を実行するには、まずボリュームを作成し、ローカルファイルシステムからデータをアップロードします。これが完了したら、データマージ操作を実行して、既存のコレクションとボリュームの両方からのデータを組み合わせた新しいコレクションを作成できます。
次のコードスニペットは、ボリュームを使用してデータマージ操作を実行する方法を示しています。ボリュームの作成方法とデータのアップロード方法の詳細については、ステージの管理を参照してください。
export BASE_URL="https://api.cloud.zilliz.com"
export TOKEN="YOUR_API_KEY"
curl --request POST \
--url "${BASE_URL}/v2/etl/merge" \
--header "Authorization: Bearer ${TOKEN}" \
--header "Content-Type: application/json" \
-d '{
"clusterId": "in00-xxxxxxxxxxxxxxx",
"dbName": "my_database",
"collectionName": "my_collection",
"destDbName": "my_database",
"destCollectionName": "my_merged_collection",
"dataSource": {
"type": "volume",
"volumeName": "my_volume",
"dataPath": "path/to/your/parquet.parquet"
},
"mergeField": "id",
"newFields": [
{
"fieldName": "date",
"dataType": "VARCHAR",
"params": {
"maxLength": 10
}
}
]
}'
上記のコマンドを実行する前に、以下のフィールドに注意が必要です。
-
dbNameおよびcollectionNameこの2つのパラメータは、データマージ操作のソースコレクションを決定します。
-
destDbNameおよびdestCollectionNameこの2つのパラメータは、データマージ操作後に生成されるターゲットコレクションを決定します。ターゲットコレクションは、ソースコレクションと同じクラスター内にある必要があります。
-
dataSourceこのパラメータはオプションで、データソースの設定(データソースのタイプや、列指向データを含むParquetファイルへのパスなど)を指定します。このデータはソースコレクションのデータとマージされ、ターゲットコレクションに格納されます。
中間ストレージとしてボリュームを使用する場合、
typeをvolumeに設定した後、volumeNameおよびdataPathを設定する必要があります。📘NotesdataPathパラメータの値は、ボリュームのルートからの相対パスで指定するファイルの絶対パス、またはボリューム内の複数のParquetファイルを含むフォルダーのいずれかになります。フォルダーを指定する場合は、そのフォルダー内のParquetファイルがすべて同じデータ構造を持っていることを確認してください。
たとえば、値は
path/to/your/file.parquet(ファイル)またはpath/to/your/folder/(フォルダー)となります。- データを追加せずに単にフィールドを追加したいだけの場合は、このパラメータを指定しないままにしておくことができます。
-
mergeFieldデータマージ操作はリレーショナルデータベースシステムにおける LEFT JOIN 操作と類似しており、マージフィールドがソースコレクションと列指向データを含むParquetファイル間の共通キーとして機能します。
-
newFieldsこれは、データマージ操作後にターゲットコレクションに追加するフィールドのスキーマのリストです。サポートされているデータ型は、VARCHAR、INT8、INT16、INT32、INT64、FLOAT、DOUBLE、および BOOL です。
上記のコマンドはデータマージジョブを作成し、そのジョブIDを返します。
{
"code": 0,
"data": {
"jobId": "job-xxxxxxxxxxxxxxxxxxxxx"
}
}
オブジェクトストレージの使用
オブジェクトストレージバケットを使用してデータマージ操作を実行するには、まずオブジェクトストレージバケットを作成し、そのバケットにデータをアップロードします。それが完了したら、既存のコレクションとバケットの両方からデータを結合した新しいコレクションを作成するデータマージ操作を実行できます。
次のコードスニペットは、オブジェクトストレージバケットを使用してデータマージ操作を実行する方法を示しています。バケットの作成方法やデータのアップロード方法については、ご利用のブロックストレージサービスプロバイダーのドキュメントをご参照ください。
export BASE_URL="https://api.cloud.zilliz.com"
export TOKEN="YOUR_API_KEY"
curl --request POST \
--url "${BASE_URL}/v2/etl/merge" \
--header "Authorization: Bearer ${TOKEN}" \
--header "Content-Type: application/json" \
-d '{
"clusterId": "in00-xxxxxxxxxxxxxxx",
"dbName": "my_database",
"collectionName": "my_collection",
"destDbName": "my_database",
"destCollectionName": "my_merged_collection",
"dataSource": {
"type": "s3",
"dataPath": "s3://my_bucket/path/to/your/parquet.parquet",
"credential": {
"accessKey": "xxxx",
"secretKey": "xxxx"
}
},
"mergeField": "id",
"newFields": [
{
"fieldName": "date",
"dataType": "VARCHAR",
"params": {
"maxLength": 10
}
}
]
}'
上記のコマンドを実行する前に、注意が必要なフィールドがいくつかあります。
-
dbNameおよびcollectionNameこの2つのパラメータは、データマージ操作のソースコレクションを決定します。
-
destDbNameおよびdestCollectionNameこの2つのパラメータは、データマージ操作後に生成されるターゲットコレクションを決定します。ターゲットコレクションは、ソースコレクションと同じクラスター内に存在する必要があります。
-
dataSourceこのパラメータはオプションであり、データソースの設定(データソースのタイプや、ソースコレクションのデータとマージされターゲットコレクションに格納される列指向データを含むParquetファイルのパスなど)を含みます。
S3互換のオブジェクトストレージバケットを中間ストレージとして使用する場合、
typeをs3に設定した後、dataPathおよびcredentialを設定する必要があります。📘NotesdataPathパラメータの値は、バケットのルートを基準としたファイルへの絶対パス、または複数のParquetファイルを含むバケット内のフォルダを指定できます。フォルダを指定する場合、そのフォルダ内のParquetファイルがすべて同じデータ構造を持っていることを確認してください。
例えば、値は
s3://path/to/your/file.parquet(ファイル)またはs3://path/to/your/folder/(フォルダ)のようになります。- データなしで単にフィールドを追加したい場合は、このパラメータを指定しないままにしておくことができます。
-
mergeFieldデータマージ操作はリレーショナルデータベースシステムにおける LEFT JOIN 操作に類似しており、マージフィールドはソースコレクションと列指向データを含むParquetファイルとの間で共有キーとして機能します。
-
newFieldsこれは、データマージ操作後にターゲットコレクションに追加されるフィールドのスキーマのリストです。サポートされているデータ型は、VARCHAR、INT8、INT16、INT32、INT64、FLOAT、DOUBLE、および BOOL です。
上記のコマンドはデータマージジョブを作成し、そのジョブIDを返します。
{
"code": 0,
"data": {
"jobId": "job-xxxxxxxxxxxxxxxxxxxxx"
}
}
データなしでフィールドを追加する
既存のコレクションにフィールドを追加するための回避策として、Merge データ API を使用することもできます。この場合、データソースを設定する必要はありません。
export BASE_URL="https://api.cloud.zilliz.com"
export TOKEN="YOUR_API_KEY"
curl --request POST \
--url "${BASE_URL}/v2/etl/merge" \
--header "Authorization: Bearer ${TOKEN}" \
--header "Content-Type: application/json" \
-d '{
"clusterId": "in00-xxxxxxxxxxxxxxx",
"dbName": "my_database",
"collectionName": "my_collection",
"destDbName": "my_database",
"destCollectionName": "my_merged_collection",
"mergeField": "id",
"newFields": [
{
"fieldName": "date",
"dataType": "VARCHAR",
"params": {
"maxLength": 10
}
}
]
}'
上記のコマンドはデータマージジョブを作成し、そのIDを返します。
{
"code": 0,
"data": {
"jobId": "job-xxxxxxxxxxxxxxxxxxxxx"
}
}
結果の確認
データマージジョブの ID を取得した後、Describe Job または Manage Project ジョブ に記載されている手順を使用して、ジョブのステータスを詳細に確認できます。
データマージジョブが完了したら、ターゲットコレクションのスキーマとターゲットコレクション内のエンティティ数が期待どおりであるかどうかを確認できます。
トラブルシューティング
-
Parquet ファイル内の行のマージキーがソースコレクション内のいずれのエンティティとも一致しない場合、どのように対処すればよいですか?
リレーショナルデータベースシステムでの左結合操作と同様に、データマージ操作はソースコレクションのすべての行と、指定された Parquet ファイル内の一致する行を結合します。これにより、ソースのすべてのフィールド、
newFieldsで定義されたフィールド、および結合されたデータを含む新しい宛先コレクションが作成されます。Parquet ファイル内の行のうち、ソースコレクション内のマージキーと一致する行のみがマージされます。マージキーがソースコレクション内のいずれのエンティティとも一致しない行はスキップされます。Parquet ファイル内の行がいずれもエンティティと一致しない場合、設定されている場合、
newFieldsで指定されたフィールドのみが null 値で作成されます。