NGRAM
Zilliz Cloud の NGRAM インデックスは、VARCHAR フィールドまたは JSON フィールド内の特定の JSONパス に対する LIKE クエリの高速化のために構築されます。インデックスの構築 前に、Zilliz Cloud はテキストを固定長 n の短い重複する部分文字列(n-gram と呼ばれる)に分割します。例えば、n = 3 の場合、単語 "Milvus" は 3-gram に分割されます: "Mil"、"ilv"、"lvu"、"vus"。これらの n-gram は、各 gram を出現するドキュメント ID にマッピングする 転置インデックス に格納されます。クエリ時 に、このインデックスにより Zilliz Cloud は検索範囲を少数の候補に迅速に絞り込むことができ、クエリ実行が大幅に高速化されます。
以下のような高速なプレフィックス、サフィックス、インフィックス、またはワイルドカードフィルタリングが必要な場合に使用します:
-
name LIKE "data%" -
title LIKE "%vector%" -
path LIKE "%json"
フィルタ式の構文の詳細については、基本演算子を参照してください。
動作原理
Zilliz Cloud は NGRAM インデックスを2段階のプロセスで実装します:
-
インデックスの構築: 各ドキュメントの n-gram を生成し、取り込み時に 転置インデックスを構築する。
-
クエリの高速化 : インデックスを使用して少数の候補セットにフィルタリングし、次に完全一致を検証する。
Phase 1: インデックスの構築
データ取り込み中、Zilliz Cloud は2つの主要なステップを実行して NGRAM インデックスを構築します:
-
テキストをn-gramに分解する: Zilliz Cloud は対象フィールドの各文字列に対して長さ n のウィンドウをスライドさせ、重複する部分文字列(n-gram)を抽出します。これらの部分文字列の長さは、設定可能な範囲
[min_gram, max_gram]内に収まります。-
min_gram: 生成する最短の n-gram。これは、インデックスの恩恵を受けることができる最小のクエリ部分文字列長も定義します。 -
max_gram: 生成する最長の n-gram。クエリ時 に、長いクエリ文字列を分割する際の最大ウィンドウサイズとしても使用されます。
例えば、
min_gram=2およびmax_gram=3の場合、文字列"AI database"は以下のように分解されます: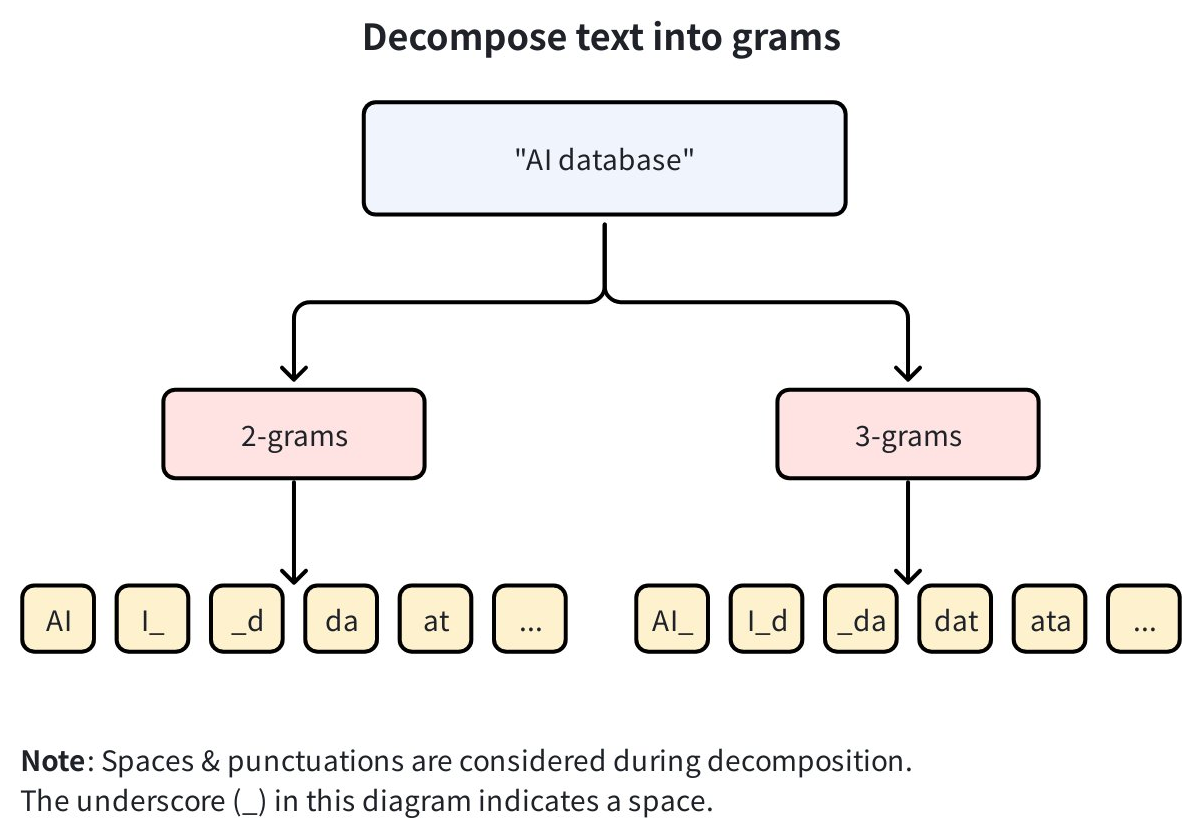
-
2-grams:
AI,I_,_d,da,at, ... -
3-grams:
AI_,I_d,_da,dat,ata, ...
📘Notes範囲
[min_gram, max_gram]に対して、Zilliz Cloud は2つの値の間(両端を含む)のすべての長さの n-gram を生成します。例えば、[2,4]と単語"text"の場合、Zilliz Cloud は以下を生成します:2-grams:
te,ex,xt3-grams:
tex,ext4-grams:
textN-gram 分解は文字ベースであり、言語に依存しません。例えば、中国語では
"向量数据库"をmin_gram = 2で分解すると:"向量","量数","数据","据库"となります。分解時、スペースと句読点は文字として扱われます。
分解は元の大文字小文字を保持し、マッチングは大文字小文字を区別します。例えば、
"データベース"と"database"は異なる n-gram を生成し、クエリ時に正確な大文字小文字の一致が必要です。
-
-
転置インデックスを構築する: 各生成された n-gram をそれを含むドキュメント ID のリストにマッピングする 転置インデックス が作成されます。
例えば、2-gram
"AI"が ID 1、5、6、8、9 のドキュメントに出現する場合、インデックスは{"AI": [1, 5, 6, 8, 9]}と記録します。このインデックスは クエリ時 に検索範囲を迅速に絞り込むために使用されます。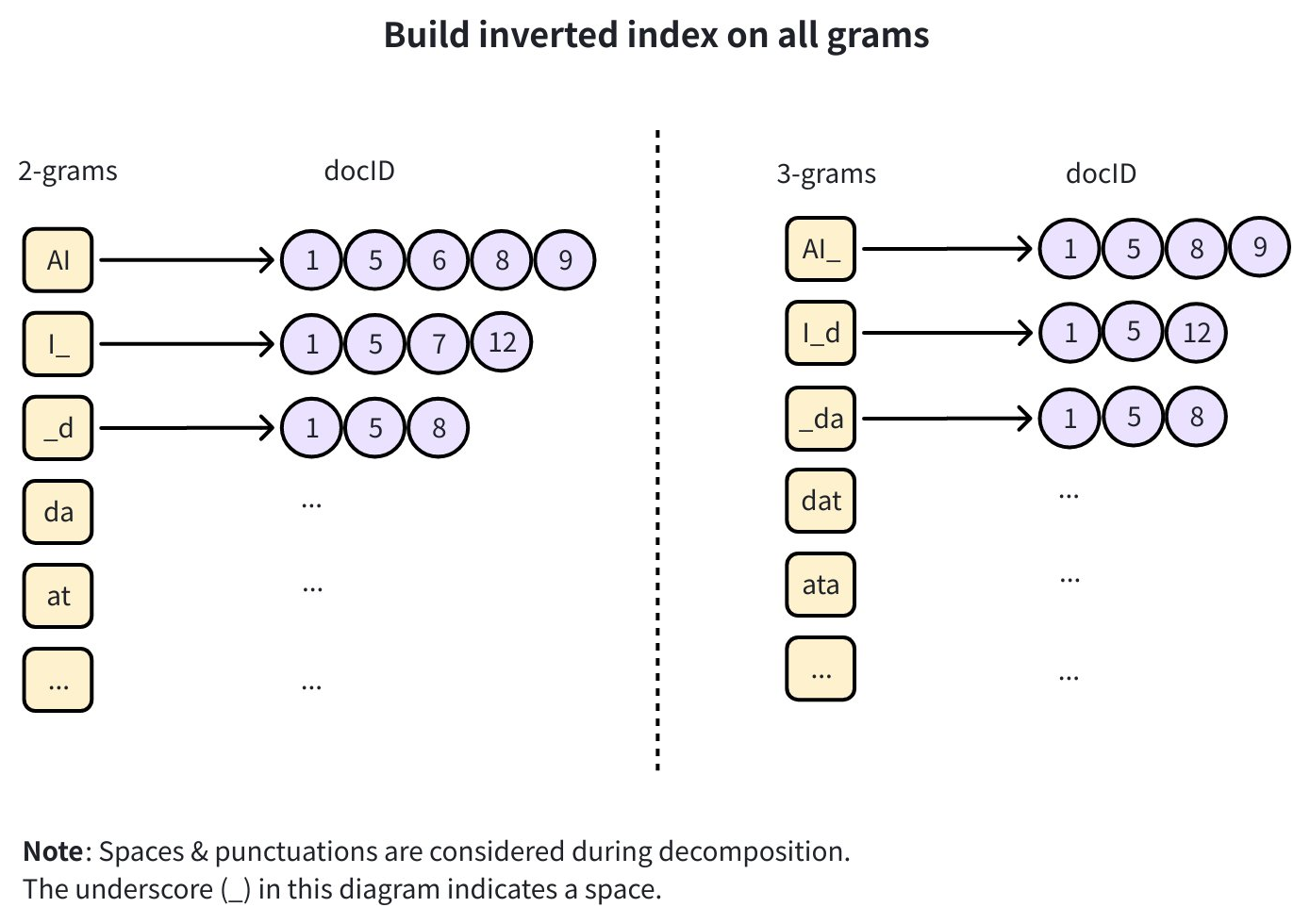 📘Notes
📘Notesより広い
[min_gram, max_gram]範囲は、より多くの gram とより大きなマッピングリストを作成します。メモリが不足している場合は、非常に大きなポスティングリストに対して mmap モードを検討してください。詳細については、mmap の使用を参照してください。
Phase 2: クエリの高速化
LIKE フィルタが実行されると、Zilliz Cloud は以下のステップで NGRAM インデックスを使用して クエリを高速化 します:

-
クエリ用語の抽出:
LIKE式からワイルドカードを除いた連続した部分文字列が抽出されます(例:"%database%"は"database"になります)。 -
クエリ用語の分解: クエリ用語は、その長さ (
L) とmin_gramおよびmax_gramの設定に基づいて n-gram に分解されます。-
L < min_gramの場合、インデックスは使用できず、クエリはフルスキャンにフォールバックします。 -
min_gram ≤ L ≤ max_gramの場合、クエリ用語全体が単一の n-gram として扱われ、さらなる分解は不要です。 -
L > max_gramの場合、クエリ用語はmax_gramと等しいウィンドウサイズを使用して重複する gram に分解されます。
例えば、
max_gramが3に設定され、クエリ用語が長さ 8 の"database"の場合、それは"dat"、"ata"、"tab"などの 3-gram 部分文字列に分解されます。 -
-
各 gram の検索と積集合: Zilliz Cloud はクエリの各 gram を 転置インデックス で検索し、結果のドキュメント ID リストの積集合を取って、少数の候補ドキュメントを見つけます。これらの候補は、クエリのすべての gram を含んでいます。
-
検証と結果の返却: 元の
LIKEフィルタが、少数の候補セットに対してのみ最終チェックとして適用され、完全一致を見つけます。
NGRAM インデックスの作成
NGRAM インデックスは、VARCHAR フィールドまたは JSON フィールド内の特定のパスに作成できます。
例 1: VARCHAR フィールドへの作成
VARCHAR フィールドの場合、field_name を指定し、min_gram と max_gram を設定するだけです。
from pymilvus import MilvusClient
client = MilvusClient(uri="YOUR_CLUSTER_ENDPOINT") # Replace with your server address
# Assume you have defined a VARCHAR field named "text" in your collection schema
# Prepare index parameters
index_params = client.prepare_index_params()
# Add NGRAM index on the "text" field
index_params.add_index(
field_name="text", # Target VARCHAR field
index_type="NGRAM", # Index type is NGRAM
index_name="ngram_index", # Custom name for the index
min_gram=2, # Minimum substring length (e.g., 2-gram: "st")
max_gram=3 # Maximum substring length (e.g., 3-gram: "sta")
)
# Create the index on the collection
client.create_index(
collection_name="Documents",
index_params=index_params
)
この設定により、text 内の各文字列に対して 2-gram および 3-gram が生成され、転置インデックスに格納されます。
例 2: JSONパス上に作成する
JSON フィールドの場合、gram 設定に加えて、以下の項目も指定する必要があります。
-
params.json_path– インデックスを作成したい値を指す JSONパス。 -
params.json_cast_type– NGRAM インデックスは文字列に対して動作するため、"varchar"(大文字小文字を区別しない)でなければなりません。
# Assume you have defined a JSON field named "json_field" in your collection schema, with a JSON path named "body"
# Prepare index parameters
index_params = client.prepare_index_params()
# Add NGRAM index on a JSON field
index_params.add_index(
field_name="json_field", # Target JSON field
index_type="NGRAM", # Index type is NGRAM
index_name="json_ngram_index", # Custom index name
min_gram=2, # Minimum n-gram length
max_gram=4, # Maximum n-gram length
params={
"json_path": "json_field[\"body\"]", # Path to the value inside the JSON field
"json_cast_type": "varchar" # Required: cast the value to varchar
}
)
# Create the index on the collection
client.create_index(
collection_name="Documents",
index_params=index_params
)
この例では:
-
json_field["body"]の値のみがインデックスされます。 -
値は n-gram トークン化の前に
VARCHARにキャストされます。 -
Zilliz Cloud は長さ 2 から 4 の部分文字列を生成し、転置インデックスに格納します。
JSON フィールドのインデックス作成方法の詳細については、JSON インデックス作成 を参照してください。
NGRAM によって高速化されるクエリ
NGRAM インデックスが適用されるためには:
-
クエリは
NGRAMインデックスを持つVARCHARフィールド(または JSONパス)を対象とする必要があります。 -
LIKEパターンのリテラル部分はmin_gram文字以上である必要があります。 (例えば、最短の想定クエリ用語が 2 文字の場合、インデックス作成時に min_gram=2 を設定してください。)
サポートされるクエリタイプ:
-
前方一致
# Match any string that starts with the substring "database"filter = 'text LIKE "database%"' -
後方一致
# Match any string that ends with the substring "database"filter = 'text LIKE "%database"' -
中間一致
# Match any string that contains the substring "database" anywherefilter = 'text LIKE "%database%"' -
ワイルドカード一致
Zilliz Cloud は、
%(ゼロ個以上の文字)と_(ちょうど1つの文字)の両方をサポートしています。# Match any string where "st" appears first, and "um" appears later in the textfilter = 'text LIKE "%st%um%"' -
JSONパス クエリ
filter = 'json_field["body"] LIKE "%database%"'
フィルタ式の構文の詳細については、基本演算子 を参照してください。
インデックスの削除
drop_index() メソッドを使用して、コレクションから既存のインデックスを削除します。
Milvus v2.6.x 互換のクラスタでは、不要になったスカラーインデックスを直接削除できます。事前にコレクションをリリースする必要はありません。
client.drop_index(
collection_name="Documents", # Name of the collection
index_name="ngram_index" # Name of the index to drop
)
使用上の注意
-
フィールド型:
VARCHARおよびJSONフィールドでサポートされています。JSON の場合は、params.json_pathとparams.json_cast_type="varchar"の両方を指定してください。 -
Unicode: NGRAM 分解は文字ベースで言語に依存せず、空白や句読点も含まれます。
-
空間的・時間的トレードオフ: より広いグラム範囲
[min_gram, max_gram]は、より多くのグラムとより大きなインデックスを生成します。メモリが不足している場合は、大きなポスティングリストに対してmmapモードを検討してください。詳細については、mmap の使用 を参照してください。 -
不変性:
min_gramとmax_gramはその場で変更できません。調整するにはインデックスを再構築してください。
ベストプラクティス
-
min_gram と max_gram を検索動作に合わせて選択する
-
min_gram=2、max_gram=3から開始してください。 -
min_gramは、ユーザーが入力すると予想される最短のリテラルに設定してください。 -
max_gramは、意味のある部分文字列の典型的な長さの近くに設定してください。max_gramが大きいほどフィルタリングは向上しますが、空間は増加します。
-
-
選択性の低いグラムを避ける
高度に繰り返されるパターン(例:
"aaaaaa")はフィルタリング効果が弱く、限られた改善しかもたらさない可能性があります。 -
一貫して正規化する
ユースケースで必要な場合は、取り込まれたテキストとクエリのリテラルに同じ正規化(例: 小文字化、トリミング)を適用してください。