フレーズ一致
フレーズ一致を使用すると、クエリ用語が完全一致フレーズとして含まれるドキュメントを検索できます。デフォルトでは、単語は同じ順序で、互いに直接隣接して出現する必要があります。たとえば、"robotics machine learning" のクエリは、"...typical robotics machine learning models..." のようなテキストに一致します。ここでは、"robotics"、"machine"、"learning" の各単語が順序どおりに、間に他の単語がない状態で出現しています。
しかし、実際のシナリオでは、厳密なフレーズ一致は柔軟性に欠ける場合があります。"...machine learning models widely adopted in robotics..." のようなテキストに一致させたい場合もあります。ここでは、同じキーワードが含まれていますが、隣接していないか、元の順序ではありません。これに対処するため、フレーズ一致は slop パラメータをサポートしており、柔軟性を導入します。slop 値は、フレーズ内の用語間で許可される位置シフトの数を定義します。たとえば、slop が 1 の場合、"machine learning" のクエリは "...machine deep learning..." のようなテキストに一致できます。ここでは、元の用語の間に 1 つの単語("deep")があります。
Overview
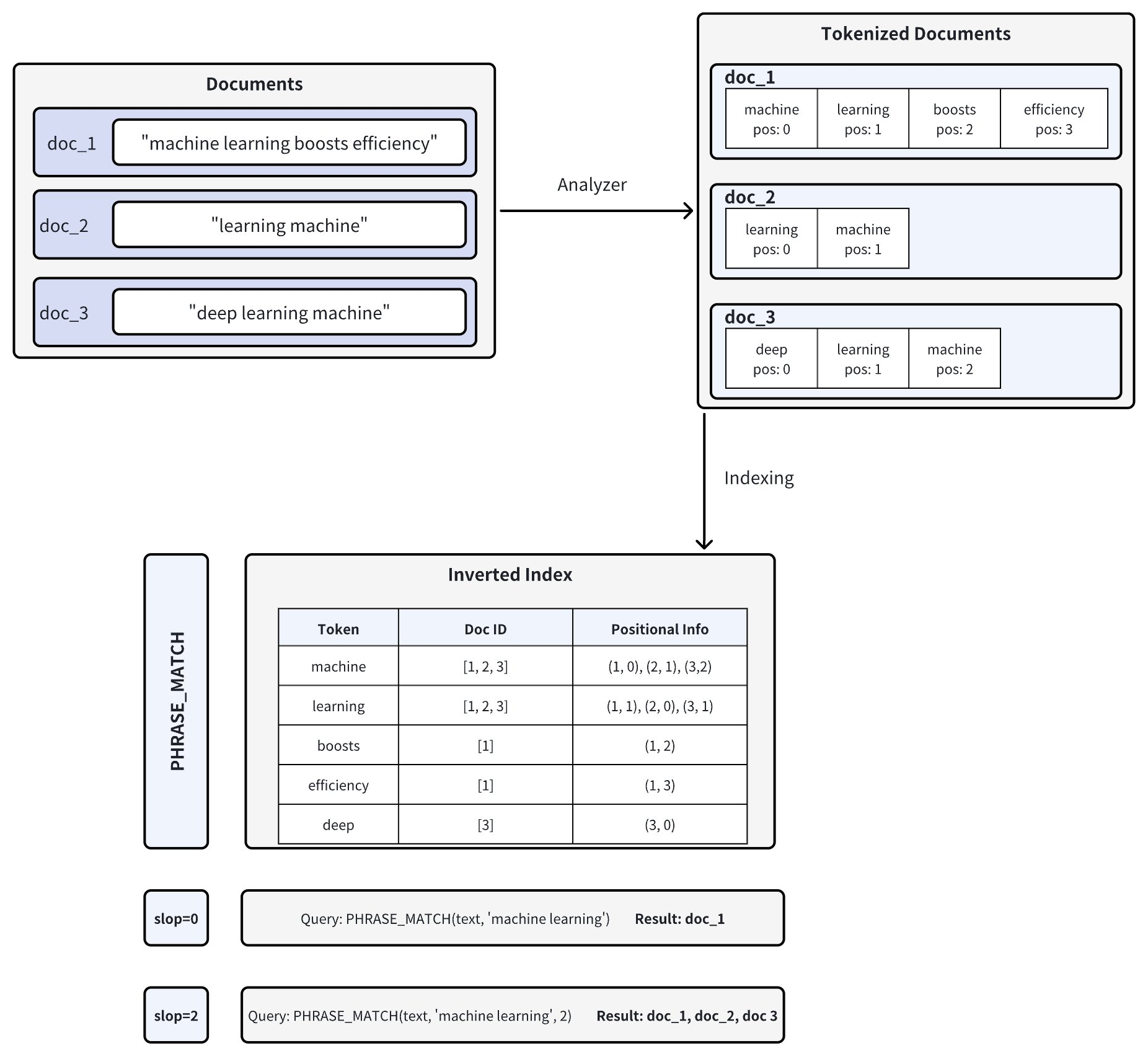
Tantivy 検索エンジンライブラリを活用して、フレーズ一致はドキュメント内の単語の位置情報を分析することで機能します。以下の図はそのプロセスを示しています:
-
ドキュメントのトークン化: Zilliz Cloud にドキュメントを挿入すると、テキストはアナライザーを使用してトークン(個々の単語または用語)に分割され、各トークンの位置情報が記録されます。たとえば、doc_1 は [ "machine" (pos=0), "learning" (pos=1), "boosts" (pos=2), "efficiency" (pos=3) ] にトークン化されます。アナライザーの詳細については、アナライザー概要 を参照してください。
-
転置インデックスの作成: Zilliz Cloud は転置インデックスを構築し、各トークンをそれが出現するドキュメントおよびそのドキュメント内でのトークンの位置にマッピングします。
-
フレーズマッチング: フレーズクエリが実行されると、Zilliz Cloud は転置インデックスで各トークンを検索し、それらの位置を確認して、正しい順序と近接性で出現しているかどうかを判断します。
slopパラメータは、一致するトークン間で許可される最大位置数を制御します:-
slop = 0 は、トークンが正確な順序で直接隣接して出現する必要があることを意味します(つまり、間に余分な単語がない)。
- この例では、doc_1("machine" が pos=0、"learning" が pos=1)のみが完全一致します。
-
slop = 2 は、一致するトークン間で最大 2 つの位置の柔軟性または並べ替えを許可します。
-
これにより、逆順("learning machine")やトークン間の小さなギャップが許可されます。
-
その結果、doc_1、doc_2("learning" が pos=0、"machine" が pos=1)、および doc_3("learning" が pos=1、"machine" が pos=2)がすべて一致します。
-
-
Enable フレーズ一致
フレーズ一致は、Zilliz Cloud の文字列データ型である VARCHAR フィールド型で機能します。
フレーズ一致を有効にするには、enable_analyzer と enable_match の両方のパラメータを True に設定してコレクションスキーマを構成します。この設定により、テキストがトークン化され、位置情報を含む転置インデックスが構築され、効率的なフレーズ検索が可能になります。
Define schema fields
特定の VARCHAR フィールドでフレーズ一致を有効にするには、フィールドスキーマを定義する際に、enable_analyzer と enable_match の両方を True に設定します。
- Python
- Java
- NodeJS
- Go
- cURL
from pymilvus import MilvusClient, DataType
# Set up a MilvusClient
CLUSTER_ENDPOINT = "YOUR_CLUSTER_ENDPOINT"
TOKEN = "YOUR_CLUSTER_TOKEN"
client = MilvusClient(
uri=CLUSTER_ENDPOINT,
token=TOKEN
)
# Create a schema for a new collection
schema = client.create_schema(enable_dynamic_field=False)
# Add a primary key field
schema.add_field(
field_name="id",
datatype=DataType.INT64,
is_primary=True,
auto_id=True
)
# Add a VARCHAR field configured for phrase matching
schema.add_field(
field_name="text", # Name of the field
datatype=DataType.VARCHAR, # Field data type set as VARCHAR (string)
max_length=1000, # Maximum string length
enable_analyzer=True, # Required. Enables text analysis
enable_match=True, # Required. Enables inverted indexing for phrase matching
# Optional: Use a custom analyzer for better phrase matching in specific languages.
# analyzer_params = {"type": "english"} # Example: English analyzer; uncomment to apply custom analyzer
)
# Add a vector field for embeddings
schema.add_field(
field_name="embeddings",
datatype=DataType.FLOAT_VECTOR,
dim=5
)
import io.milvus.v2.common.DataType;
import io.milvus.v2.service.collection.request.AddFieldReq;
import io.milvus.v2.service.collection.request.CreateCollectionReq;
MilvusClientV2 client = new MilvusClientV2(ConnectConfig.builder()
.uri("YOUR_CLUSTER_ENDPOINT")
.token("YOUR_CLUSTER_TOKEN")
.build());
CreateCollectionReq.CollectionSchema schema = CreateCollectionReq.CollectionSchema.builder()
.build();
schema.addField(AddFieldReq.builder()
.fieldName("id")
.dataType(DataType.Int64)
.isPrimaryKey(true)
.autoID(true)
.build());
schema.addField(AddFieldReq.builder()
.fieldName("text")
.dataType(DataType.VarChar)
.maxLength(1000)
.enableAnalyzer(true)
.enableMatch(true)
// Optional: Use a custom analyzer for better phrase matching in specific languages.
// .analyzerParams(Map.of("type", "english")) // Example: English analyzer; uncomment to apply custom analyzer
.build());
schema.addField(AddFieldReq.builder()
.fieldName("embeddings")
.dataType(DataType.FloatVector)
.dimension(5)
.build());
// Set up a MilvusClient
const address = "YOUR_CLUSTER_ENDPOINT"
const token = "YOUR_CLUSTER_TOKEN"
const client = new MilvusClient({address, token})
const schema = {
collection_name: 'tech_articles',
fields: [
{
name: "id",
description: "primary id",
data_type: DataType.Int64,
is_primary_key: true,
autoID: true,
},
{
name: "text",
description: "text field for phrase matching",
data_type: DataType.VarChar,
max_length: 1000,
enable_analyzer: true, // Enables text analysis
enable_match: true, // Enables inverted indexing for
},
{
name: "embeddings",
description: "vector field",
data_type: DataType.FloatVector,
dim: 5,
},
],
};
import (
"github.com/milvus-io/milvus/client/v2/entity"
)
milvusAddr := "YOUR_CLUSTER_ENDPOINT"
APIKey := "YOUR_API_KEY"
client, err := milvusclient.New(ctx, &milvusclient.ClientConfig{
Address: milvusAddr,
APIKey: APIKey
})
schema := entity.NewSchema().WithName(collectionName).
WithField(entity.NewField().WithName("id").WithDataType(entity.FieldTypeInt64).WithIsPrimaryKey(true)).
WithField(entity.NewField().WithName("text").WithDataType(entity.FieldTypeVarChar).WithMaxLength(1000).WithEnableMatch(true).WithEnableAnalyzer(true)).
WithField(entity.NewField().WithName("embeddings").WithDataType(entity.FieldTypeFloatVector).WithDim(5))
export idField='{
"fieldName": "id",
"dataType": "Int64",
"isPrimary": true,
"autoID": true
}'
export textField='{
"fieldName": "text",
"dataType": "VarChar",
"elementTypeParams": {
"max_length": 1000,
"enable_analyzer": true,
"enable_match": true
}
}'
export vectorField='{
"fieldName": "embeddings",
"dataType": "FloatVector",
"elementTypeParams": {
"dim": 5
}
}'
export schema="{
\"autoID\": false,
\"enableDynamicField\": true,
\"fields\": [
$idField,
$textField,
$vectorField
]
}"
デフォルトでは、Zilliz Cloud は standard analyzer を使用します。これは、空白と句読点でテキストをトークン化し、テキストを小文字に変換します。
テキストデータが特定の言語や形式の場合は、analyzer_params パラメータを使用してカスタムアナライザーを構成できます(例: { "type": "english" } または { "type": "jieba" })。
詳細については、Analyzer Overview を参照してください。
コレクションの作成
必要なフィールドが定義されたら、以下のコードを使用してコレクションを作成します:
- Python
- Java
- NodeJS
- Go
- cURL
# Create the collection
COLLECTION_NAME = "tech_articles" # Name your collection
if client.has_collection(COLLECTION_NAME):
client.drop_collection(COLLECTION_NAME)
client.create_collection(
collection_name=COLLECTION_NAME,
schema=schema
)
String COLLECTION_NAME = "tech_articles"; // Name your collection
if (client.hasCollection(
HasCollectionReq.builder()
.collectionName(COLLECTION_NAME)
.build()
)) {
client.dropCollection(
DropCollectionReq.builder()
.collectionName(COLLECTION_NAME)
.build()
);
}
client.createCollection(
CreateCollectionReq.builder()
.collectionName(COLLECTION_NAME)
.collectionSchema(schema)
.build()
);
// Create or recreate the collection if it already exists
const COLLECTION_NAME = "tech_articles"; // Name your collection
const hasCollection = await client.hasCollection({ collection_name: COLLECTION_NAME });
if (hasCollection.value) {
await client.dropCollection({ collection_name: COLLECTION_NAME });
}
await client.createCollection(schema);
// go
# restful
# check collection exist
export MILVUS_HOST="YOUR_CLUSTER_ENDPOINT"
export COLLECTION_NAME="tech_articles"
curl -X POST "YOUR_CLUSTER_ENDPOINT/v2/vectordb/collections/has" \
-H "Content-Type: application/json" \
-d "{
\"collectionName\": \"$COLLECTION_NAME\"
}"
# drop existing collection
curl -X POST "http://${MILVUS_HOST}/v2/vectordb/collections/drop" \
-H "Content-Type: application/json" \
-d "{
\"collectionName\": \"${COLLECTION_NAME}\"
}"
# create new collection
curl --request POST \
--url "${CLUSTER_ENDPOINT}/v2/vectordb/collections/create" \
--header "Content-Type: application/json" \
--data "{
\"collectionName\": \"$COLLECTION_NAME\",
\"schema\": $schema
}"
コレクションの作成後、フレーズマッチを使用する前に、以下の必要な手順が実行されていることを確認してください:
-
エンティティがコレクションに挿入されていること;
-
各ベクトルフィールドにインデックスが作成されていること;
-
コレクションがメモリにロードされていること。
コード例を表示
- Python
- Java
- NodeJS
- Go
- cURL
# Insert sample data with text containing "machine learning" phrases
sample_data = [
{
"text": "Machine learning is a subset of artificial intelligence that focuses on algorithms.",
"embeddings": [0.1, 0.2, 0.3, 0.4, 0.5]
},
{
"text": "Deep learning machine algorithms require large datasets for training.",
"embeddings": [0.2, 0.3, 0.4, 0.5, 0.6]
},
{
"text": "The machine learning model showed excellent performance on the test set.",
"embeddings": [0.3, 0.4, 0.5, 0.6, 0.7]
},
{
"text": "Natural language processing and machine learning go hand in hand.",
"embeddings": [0.4, 0.5, 0.6, 0.7, 0.8]
},
{
"text": "This article discusses various learning machine techniques and applications.",
"embeddings": [0.5, 0.6, 0.7, 0.8, 0.9]
}
]
# Insert the data
client.insert(
collection_name=COLLECTION_NAME,
data=sample_data
)
# Index the vector field and load the collection
index_params = client.prepare_index_params()
index_params.add_index(
field_name="embeddings",
index_type="AUTOINDEX",
index_name="embeddings_index",
metric_type="COSINE"
)
client.create_index(collection_name=COLLECTION_NAME, index_params=index_params)
client.load_collection(collection_name=COLLECTION_NAME)
// Insert sample data with text containing "machine learning" phrases
List<JsonObject> sampleData = Arrays.asList(
createSample("Machine learning is a subset of artificial intelligence that focuses on algorithms.", new float[]{0.1f, 0.2f, 0.3f, 0.4f, 0.5f}),
createSample("Deep learning machine algorithms require large datasets for training.", new float[]{0.2f, 0.3f, 0.4f, 0.5f, 0.6f}),
createSample("The machine learning model showed excellent performance on the test set.", new float[]{0.3f, 0.4f, 0.5f, 0.6f, 0.7f}),
createSample("Natural language processing and machine learning go hand in hand.", new float[]{0.4f, 0.5f, 0.6f, 0.7f, 0.8f}),
createSample("This article discusses various learning machine techniques and applications.", new float[]{0.5f, 0.6f, 0.7f, 0.8f, 0.9f})
);
client.insert(InsertReq.builder()
.collectionName(COLLECTION_NAME)
.data(sampleData)
.build());
// Index the vector field and load the collection
IndexParam indexParam = IndexParam.builder()
.fieldName("embeddings")
.indexType(IndexParam.IndexType.AUTOINDEX)
.indexName("embeddings_index")
.metricType(IndexParam.MetricType.COSINE)
.build();
client.createIndex(CreateIndexReq.builder()
.collectionName(COLLECTION_NAME)
.indexParams(Collections.singletonList(indexParam))
.build());
client.loadCollection(LoadCollectionReq.builder()
.collectionName(COLLECTION_NAME)
.build());
// Format and insert sample data for "machine learning" phrase matching
const sampleData = [
{
text: "Machine learning is a subset of artificial intelligence that focuses on algorithms.",
embeddings: [0.1, 0.2, 0.3, 0.4, 0.5],
},
{
text: "Deep learning machine algorithms require large datasets for training.",
embeddings: [0.2, 0.3, 0.4, 0.5, 0.6],
},
{
text: "The machine learning model showed excellent performance on the test set.",
embeddings: [0.3, 0.4, 0.5, 0.6, 0.7],
},
{
text: "Natural language processing and machine learning go hand in hand.",
embeddings: [0.4, 0.5, 0.6, 0.7, 0.8],
},
{
text: "This article discusses various learning machine techniques and applications.",
embeddings: [0.5, 0.6, 0.7, 0.8, 0.9],
},
];
// Insert the data into the collection
await client.insert({
collection_name: COLLECTION_NAME,
data: sampleData,
});
// Create an index on the vector field and load the collection
await client.createIndex({
collection_name: COLLECTION_NAME,
field_name: "embeddings",
index_type: "AUTOINDEX",
index_name: "embeddings_index",
metric_type: "COSINE",
});
await client.loadCollection({
collection_name: COLLECTION_NAME,
});
// go
# restful
# Insert the data into the collection
curl -X POST "YOUR_CLUSTER_ENDPOINT/v2/vectordb/entities/insert" \
-H "Content-Type: application/json" \
-H "Authorization: Bearer <token>" \
-d '{
"collectionName": "tech_articles",
"data": [
{
"text": "Machine learning is a subset of artificial intelligence that focuses on algorithms.",
"embeddings": [0.1, 0.2, 0.3, 0.4, 0.5]
},
{
"text": "Deep learning machine algorithms require large datasets for training.",
"embeddings": [0.2, 0.3, 0.4, 0.5, 0.6]
},
{
"text": "The machine learning model showed excellent performance on the test set.",
"embeddings": [0.3, 0.4, 0.5, 0.6, 0.7]
},
{
"text": "Natural language processing and machine learning go hand in hand.",
"embeddings": [0.4, 0.5, 0.6, 0.7, 0.8]
},
{
"text": "This article discusses various learning machine techniques and applications.",
"embeddings": [0.5, 0.6, 0.7, 0.8, 0.9]
}
]
}'
# Create an index on the vector field and load the collection
curl -X POST "YOUR_CLUSTER_ENDPOINT/v2/vectordb/indexes/create" \
-H "Content-Type: application/json" \
-H "Authorization: Bearer <token>" \
-d '{
"collectionName": "tech_articles",
"indexParams": [
{
"fieldName": "embeddings",
"indexName": "embeddings_index",
"metricType": "COSINE",
"indexType": "AUTOINDEX"
}
]
}'
curl -X POST "YOUR_CLUSTER_ENDPOINT/v2/vectordb/collections/load" \
-H "Content-Type: application/json" \
-H "Authorization: Bearer <token>" \
-d '{
"collectionName": "tech_articles"
}'
フレーズ一致を使用する
コレクションスキーマ内の VARCHAR フィールドに対してフレーズ一致を有効化した後、PHRASE_MATCH 式を使用してフレーズ一致検索を実行できます。
PHRASE_MATCH 式は大文字・小文字を区別しません。PHRASE_MATCH または phrase_match のどちらを使用しても構いません。
PHRASE_MATCH 式の構文
検索時にフィールド、フレーズ、およびオプションの柔軟性(slop)を指定するために PHRASE_MATCH 式を使用します。構文は次のとおりです:
- Python
- Java
- NodeJS
- Go
- cURL
PHRASE_MATCH(field_name, phrase, slop)
String filter = "PHRASE_MATCH(text, 'machine learning')";
PHRASE_MATCH(field_name, phrase, slop)
// go
# restful
export filter = "PHRASE_MATCH(field_name, phrase, slop)"
-
field_name: フレーズ一致を実行するVARCHARフィールドの名前。 -
phrase: 検索する正確なフレーズ。 -
slop(オプション): 一致するトークン間に許容される最大位置数を指定する整数。-
0(デフォルト): 完全一致のフレーズのみに一致します。例: "machine learning" に対するフィルターは、"machine learning" に完全一致するもののみに一致し、"machine boosts learning" や "learning machine" には一致しません。 -
1: 1つの追加語や位置のわずかなずれなど、わずかな変動を許容します。例: "machine learning" に対するフィルターは、"machine boosts learning" ("machine" と "learning" の間に1トークンある) には一致しますが、"learning machine" (語順が逆) には一致しません。 -
2: 語順の反転や、最大2トークンの間隔など、より柔軟な一致を許容します。例: "machine learning" に対するフィルターは、"learning machine" (語順が逆) や "machine quickly boosts learning" ("machine" と "learning" の間に2トークンある) に一致します。
-
Query with フレーズ一致
query() メソッドを使用する際、PHRASE_MATCH はスカラー・フィルターとして機能します。指定されたフレーズ(許容される slop の範囲内)を含むドキュメントのみが返されます。
Example: slop = 0 (exact match)
この例では、"machine learning" という正確なフレーズを含み、その間に余分なトークンが一切ないドキュメントを返します。
- Python
- Java
- NodeJS
- Go
- cURL
# Match documents containing exactly "machine learning"
filter = "PHRASE_MATCH(text, 'machine learning')"
result = client.query(
collection_name=COLLECTION_NAME,
filter=filter,
output_fields=["id", "text"]
)
print("Query result: ", result)
# Expected output:
# Query result: data: ["{'id': 461366973343948097, 'text': 'Machine learning is a subset of artificial intelligence that focuses on algorithms.'}", "{'id': 461366973343948099, 'text': 'The machine learning model showed excellent performance on the test set.'}", "{'id': 461366973343948100, 'text': 'Natural language processing and machine learning go hand in hand.'}"]
import io.milvus.v2.service.vector.request.QueryReq;
import io.milvus.v2.service.vector.response.QueryResp;
String filter = "PHRASE_MATCH(text, 'machine learning')";
QueryResp result = client.query(QueryReq.builder()
.collectionName(COLLECTION_NAME)
.filter(filter)
.outputFields(Arrays.asList("id", "text"))
.build());
const filter = "PHRASE_MATCH(text, 'machine learning')";
const result = await client.query({
collection_name: COLLECTION_NAME,
filter: filter,
output_fields: ["id", "text"]
});
// go
# restful
curl -X POST "YOUR_CLUSTER_ENDPOINT/v2/vectordb/entities/query" \
-H "Content-Type: application/json" \
-H "Authorization: Bearer <token>" \
-d '{
"collectionName": "tech_articles",
"filter": "PHRASE_MATCH(text, '\''machine learning'\'')",
"outputFields": ["id", "text"],
"limit": 100
}'
フレーズ一致での検索
検索操作において、PHRASE_MATCH はベクトル類似度ランキングを適用する前にドキュメントを事前フィルタリングするために使用されます。この2段階のアプローチでは、まずテキスト一致によって候補セットを絞り込み、その後ベクトル埋め込みに基づいてそれらの候補を再ランキングします。
例: slop = 1
ここでは、slop(許容誤差)を1に設定しています。このフィルターは、フレーズ "learning machine" をわずかな柔軟性をもって含むドキュメントに適用されます。
- Python
- Java
- NodeJS
- Go
- cURL
# Example: Filter documents containing "learning machine" with slop=1
filter_slop1 = "PHRASE_MATCH(text, 'learning machine', 1)"
result_slop1 = client.search(
collection_name=COLLECTION_NAME,
anns_field="embeddings",
data=[[0.1, 0.2, 0.3, 0.4, 0.5]],
filter=filter_slop1,
search_params={},
limit=10,
output_fields=["id", "text"]
)
print("Slop 1 result: ", result_slop1)
# Expected output:
# Slop 1 result: data: [[{'id': 461366973343948098, 'distance': 0.9949367046356201, 'entity': {'text': 'Deep learning machine algorithms require large datasets for training.', 'id': 461366973343948098}}, {'id': 461366973343948101, 'distance': 0.9710607528686523, 'entity': {'text': 'This article discusses various learning machine techniques and applications.', 'id': 461366973343948101}}]]
import io.milvus.v2.service.vector.request.SearchReq;
import io.milvus.v2.service.vector.response.SearchResp;
String filterSlop1 = "PHRASE_MATCH(text, 'learning machine', 1)";
List<Float> queryVector = Arrays.asList(0.1f, 0.2f, 0.3f, 0.4f, 0.5f);
SearchResp resultSlop1 = client.search(SearchReq.builder()
.collectionName(COLLECTION_NAME)
.annsField("embeddings")
.data(Collections.singletonList(queryVector))
.filter(filterSlop1)
.searchParams(Collections.emptyMap())
.topK(10)
.outputFields(Arrays.asList("id", "text"))
.build());
System.out.println("Slop 1 result: " + resultSlop1);
const filter_slop1 = "PHRASE_MATCH(text, 'learning machine', 1)";
const result_slop1 = await client.search({
collection_name: COLLECTION_NAME,
anns_field: "embeddings",
data: [0.1, 0.2, 0.3, 0.4, 0.5],
filter: filter_slop1,
limit: 10,
output_fields: ["id", "text"],
});
// go
# restful
export MILVUS_HOST="YOUR_CLUSTER_ENDPOINT"
export COLLECTION_NAME="tech_articles"
export AUTH_TOKEN="your_token_here"
# Search数据
echo "Searching with PHRASE_MATCH filter (slop=1)..."
curl -X POST "http://${MILVUS_HOST}/v2/vectordb/entities/search" \
-H "Content-Type: application/json" \
-H "Authorization: Bearer ${AUTH_TOKEN}" \
-d "{
\"collectionName\": \"${COLLECTION_NAME}\",
\"annsField\": \"embeddings\",
\"data\": [[0.1, 0.2, 0.3, 0.4, 0.5]],
\"filter\": \"PHRASE_MATCH(text, 'learning machine', 1)\",
\"searchParams\": {},
\"limit\": 10,
\"outputFields\": [\"id\", \"text\"]
}"
例: slop = 2
この例では slop 値が 2 に設定されており、単語 "machine" と "learning" の間に最大で 2 つの余分なトークン(または語順が逆になった語)が許容されます。
- Python
- Java
- NodeJS
- Go
- cURL
# Example: Filter documents containing "machine learning" with slop=2
filter_slop2 = "PHRASE_MATCH(text, 'machine learning', 2)"
result_slop2 = client.search(
collection_name=COLLECTION_NAME,
anns_field="embeddings", # Vector field name
data=[[0.1, 0.2, 0.3, 0.4, 0.5]], # Query vector
filter=filter_slop2, # Filter expression
search_params={},
limit=10, # Maximum results to return
output_fields=["id", "text"]
)
print("Slop 2 result: ", result_slop2)
# Expected output:
# Slop 2 result: data: [[{'id': 461366973343948097, 'distance': 0.9999999403953552, 'entity': {'text': 'Machine learning is a subset of artificial intelligence that focuses on algorithms.', 'id': 461366973343948097}}, {'id': 461366973343948098, 'distance': 0.9949367046356201, 'entity': {'text': 'Deep learning machine algorithms require large datasets for training.', 'id': 461366973343948098}}, {'id': 461366973343948099, 'distance': 0.9864400029182434, 'entity': {'text': 'The machine learning model showed excellent performance on the test set.', 'id': 461366973343948099}}, {'id': 461366973343948100, 'distance': 0.9782319068908691, 'entity': {'text': 'Natural language processing and machine learning go hand in hand.', 'id': 461366973343948100}}, {'id': 461366973343948101, 'distance': 0.9710607528686523, 'entity': {'text': 'This article discusses various learning machine techniques and applications.', 'id': 461366973343948101}}]]
// Example: Filter documents containing "machine learning" with slop=2
String filterSlop2 = "PHRASE_MATCH(text, 'machine learning', 2)";
SearchReq searchReqSlop2 = SearchReq.builder()
.collectionName(COLLECTION_NAME)
.annsField("embeddings") // Vector field name
.data(queryVector) // Query vector
.filter(filterSlop2) // Filter expression
.searchParams(new HashMap<>())
.topK(10) // Maximum results to return
.outputFields(Arrays.asList("id", "text"))
.build();
SearchResp resultSlop2 = client.search(searchReqSlop2);
System.out.println("Slop 2 result: " + resultSlop2);
const filter_slop2 = "PHRASE_MATCH(text, 'learning machine', 2)";
const result_slop2 = await client.search({
collection_name: COLLECTION_NAME,
anns_field: "embeddings",
data: [0.1, 0.2, 0.3, 0.4, 0.5],
filter: filter_slop2,
limit: 10,
output_fields: ["id", "text"],
});
// go
#restful
curl -X POST "http://${MILVUS_HOST}/v2/vectordb/entities/search" \
-H "Content-Type: application/json" \
-H "Authorization: Bearer ${AUTH_TOKEN}" \
-d "{
\"collectionName\": \"${COLLECTION_NAME}\",
\"annsField\": \"embeddings\",
\"data\": [[0.1, 0.2, 0.3, 0.4, 0.5]],
\"filter\": \"PHRASE_MATCH(text, 'machine learning', 2)\",
\"searchParams\": {},
\"limit\": 10,
\"outputFields\": [\"id\", \"text\"]
}"
例: slop = 3
この例では、slop値を3に設定することでさらに柔軟性が高まります。フィルターは**"machine learning"**を検索し、単語間に最大3トークン分の位置のずれを許容します。
- Python
- Java
- NodeJS
- Go
- cURL
# Example: Filter documents containing "machine learning" with slop=3
filter_slop3 = "PHRASE_MATCH(text, 'machine learning', 3)"
result_slop3 = client.search(
collection_name=COLLECTION_NAME,
anns_field="embeddings", # Vector field name
data=[[0.1, 0.2, 0.3, 0.4, 0.5]], # Query vector
filter=filter_slop3, # Filter expression
search_params={},
limit=10, # Maximum results to return
output_fields=["id", "text"]
)
print("Slop 3 result: ", result_slop3)
# Expected output:
# Slop 3 result: data: [[{'id': 461366973343948097, 'distance': 0.9999999403953552, 'entity': {'text': 'Machine learning is a subset of artificial intelligence that focuses on algorithms.', 'id': 461366973343948097}}, {'id': 461366973343948098, 'distance': 0.9949367046356201, 'entity': {'text': 'Deep learning machine algorithms require large datasets for training.', 'id': 461366973343948098}}, {'id': 461366973343948099, 'distance': 0.9864400029182434, 'entity': {'text': 'The machine learning model showed excellent performance on the test set.', 'id': 461366973343948099}}, {'id': 461366973343948100, 'distance': 0.9782319068908691, 'entity': {'text': 'Natural language processing and machine learning go hand in hand.', 'id': 461366973343948100}}, {'id': 461366973343948101, 'distance': 0.9710607528686523, 'entity': {'text': 'This article discusses various learning machine techniques and applications.', 'id': 461366973343948101}}]]
// Example: Filter documents containing "machine learning" with slop=3
String filterSlop3 = String.format("PHRASE_MATCH(text, '%s', %d)", "machine learning", 3);
SearchResp resultSlop3 = client.search(
SearchReq.builder()
.collectionName(COLLECTION_NAME)
.annsField("embeddings") // Vector field name
.data(queryVector) // Query vector
.filter(filterSlop3) // Filter expression
.searchParams(new HashMap<>())
.topK(10) // Maximum results to return
.outputFields(Arrays.asList("id", "text"))
.build()
);
System.out.printf("Slop 3 result: %s%n", resultSlop3);
const filter_slop3 = "PHRASE_MATCH(text, 'learning machine', 3)";
const result_slop3 = await client.search({
collection_name: COLLECTION_NAME,
anns_field: "embeddings",
data: [0.1, 0.2, 0.3, 0.4, 0.5],
filter: filter_slop3,
limit: 10,
output_fields: ["id", "text"],
});
// go
# restful
curl -X POST "http://${MILVUS_HOST}/v2/vectordb/entities/search" \
-H "Content-Type: application/json" \
-H "Authorization: Bearer ${AUTH_TOKEN}" \
-d "{
\"collectionName\": \"${COLLECTION_NAME}\",
\"annsField\": \"embeddings\",
\"data\": [[0.1, 0.2, 0.3, 0.4, 0.5]],
\"filter\": \"PHRASE_MATCH(text, 'machine learning', 3)\",
\"searchParams\": {},
\"limit\": 10,
\"outputFields\": [\"id\", \"text\"]
}"
考慮事項
-
フィールドのフレーズ一致を有効にすると、転置インデックスの作成がトリガーされ、ストレージリソースを消費します。この機能を有効にするかどうかを決定する際は、テキストサイズ、一意のトークン数、使用するアナライザーに応じて異なるため、ストレージへの影響を考慮してください。
-
スキーマでアナライザーを定義すると、その設定はそのコレクションに対して永久となります。異なるアナライザーの方がニーズに適していると判断した場合は、既存のコレクションを削除し、希望するアナライザー構成で新しいコレクションを作成することを検討してください。
-
フレーズ一致のパフォーマンスは、テキストのトークン化方法に依存します。アナライザーをコレクション全体に適用する前に、
run_analyzerメソッドを使用してトークン化の出力を確認してください。詳細については、アナライザー概要 を参照してください。 -
filter式でのエスケープ規則:-
式内で二重引用符または単一引用符で囲まれた文字は、文字列定数として解釈されます。文字列定数にエスケープ文字が含まれる場合、エスケープ文字はエスケープシーケンスで表す必要があります。たとえば、
\を表すには\\を、タブ\tを表すには\\tを、改行を表すには\\nを使用します。 -
文字列定数が単一引用符で囲まれている場合、定数内の単一引用符は
\\'として表し、二重引用符は"または\\"のいずれかとして表すことができます。例:'It\\'s milvus'。 -
文字列定数が二重引用符で囲まれている場合、定数内の二重引用符は
\\"として表し、単一引用符は'または\\'のいずれかとして表すことができます。例:"He said \\"Hi\\""。
-