ドキュメントデータAbout to Deprecate
Zilliz CloudのWeb UIは、パイプラインを作成、実行、管理するためのシンプルで直感的な方法を提供し、RESTful APIはWeb UIに比べてより柔軟性とカスタマイズ性を提供します。
このガイドでは、文書パイプラインの作成、埋め込み文書データの意味検索の実行、パイプラインが不要になった場合の削除に必要な手順について説明します。
Zilliz Cloud Pipelinesは、2025年第2四半期の終わりまでに廃止され、「Data In, Data Out」という新しい機能に置き換えられます。これにより、MilvusとZilliz Cloudの両方で埋め込み生成が効率化されます。2024年12月24日現在、新規ユーザー登録は受け付けられていません。現在のユーザーは、日没日まで月額20ドルの無料手当内でサービスを継続して利用できますが、SLAは提供されていません。モデルプロバイダーまたはオープンソースモデルの埋め込みAPIを使用してベクトル埋め込みを生成することを検討してください。
前提条件と制限
-
Google Cloud Platform(GCP)上のus-west 1にデプロイされたクラスタを作成していることを確認してください。
-
一つのプロジェクトでは、同じタイプのパイプラインを最大100個まで作成できます。詳細については、Zillizクラウドの制限を参照してください。
文書データを取り込む
データを取り込むには、まず取り込みパイプラインを作成してから実行する必要があります。
文書摂取パイプラインの作成
- Cloud Console
- Bash
-
プロジェクトに移動します。
-
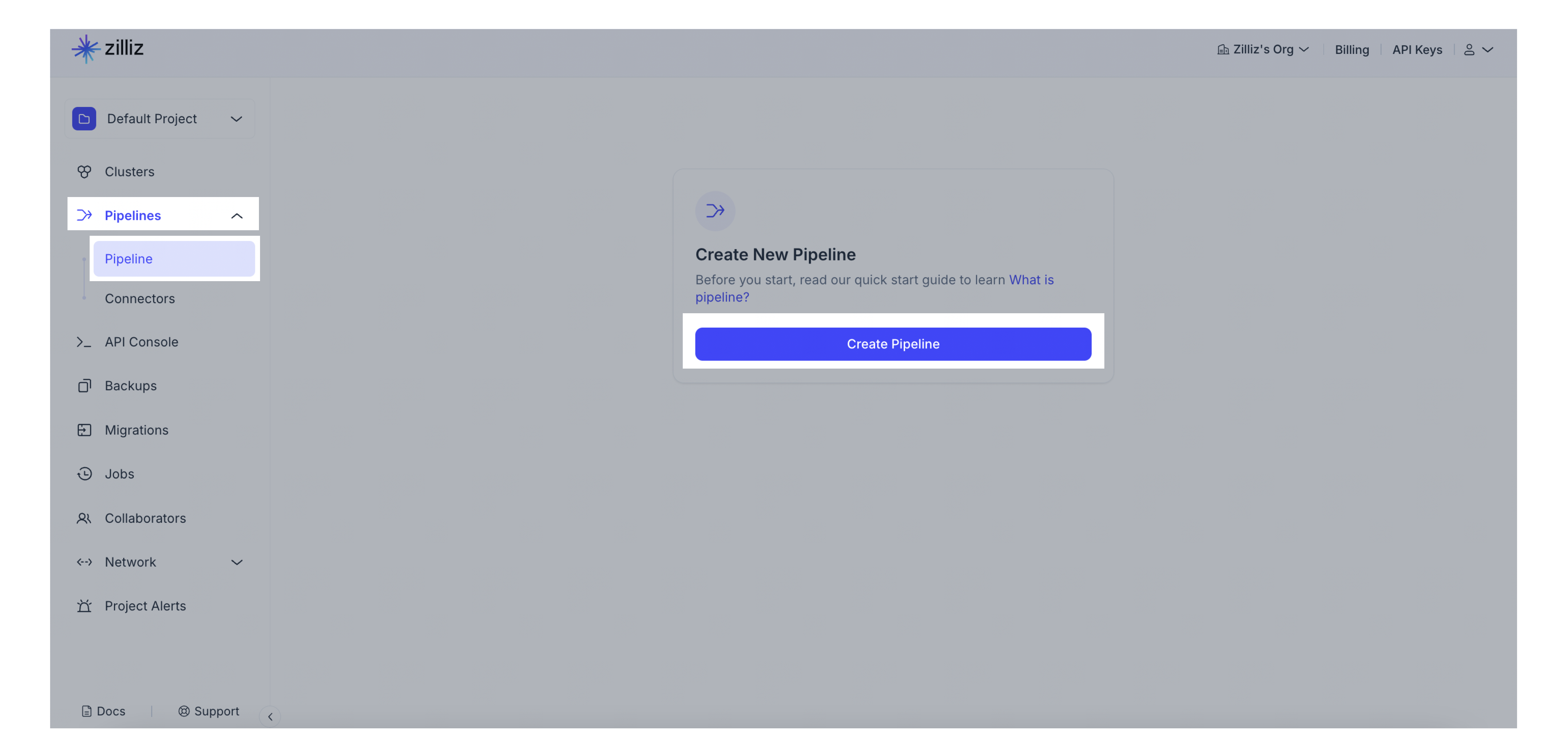
ナビゲーションパネルからパイプラインをクリックします。次に、概要タブに切り替えて、パイプラインをクリックします。パイプラインを作成するには、+パイプラインをクリックしてください。
-
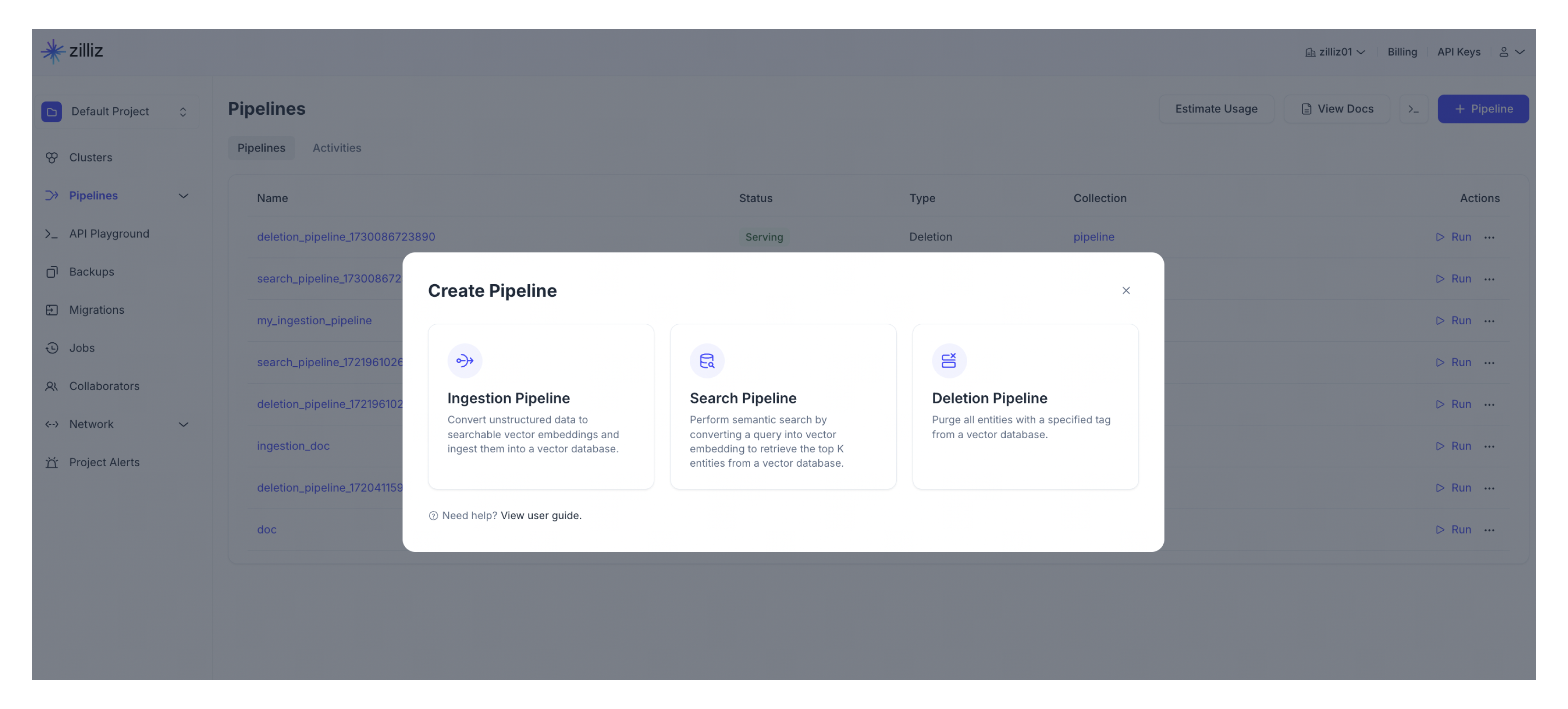
作成するパイプラインの種類を選択します。[+パイプライン]ボタンをクリックします。Ingestion Pipeline列。
-
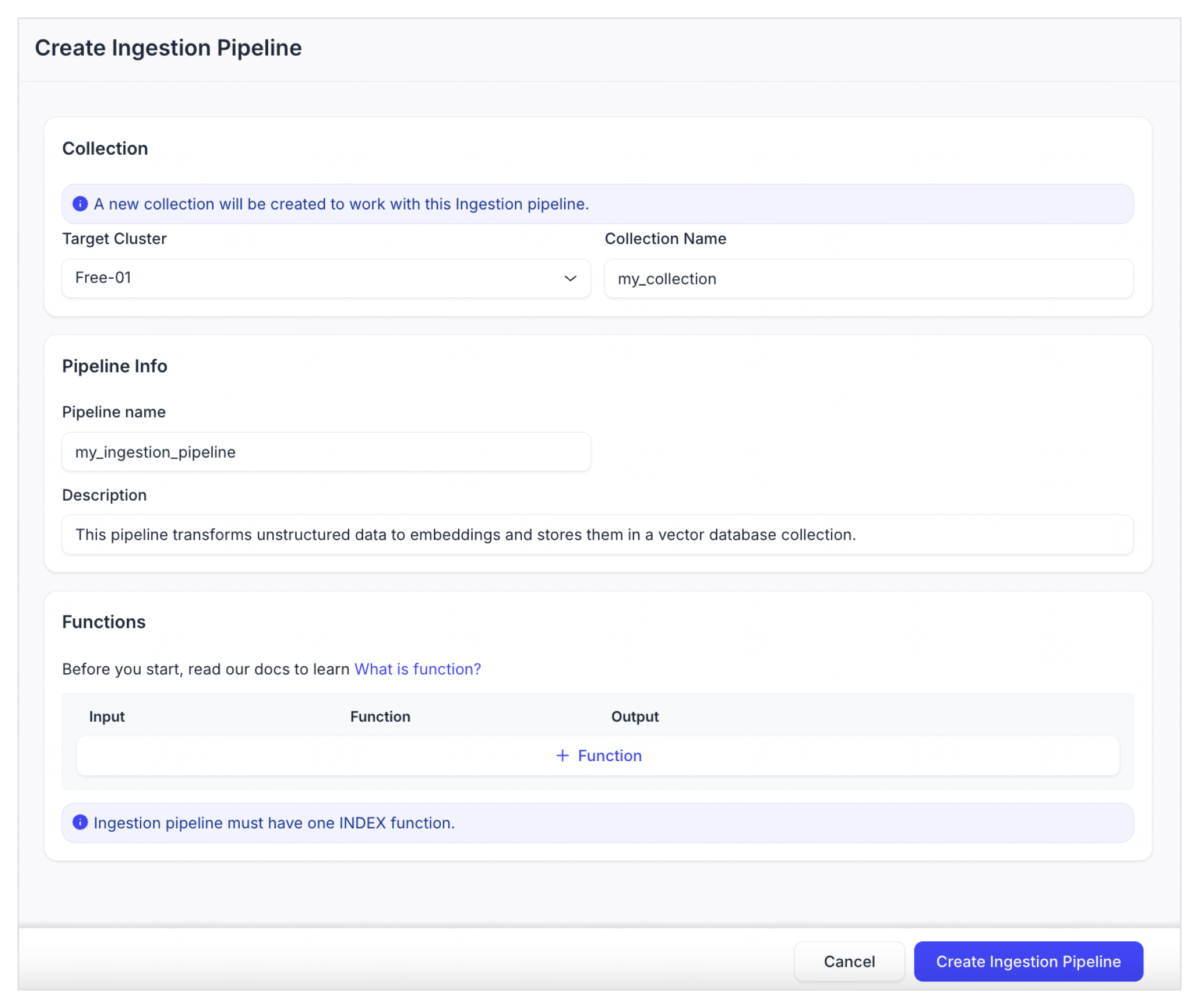
作成するIngestionパイプラインを構成します。
パラメータ
説明する
ターゲットクラスタ
このIngestionパイプラインを使用して新しいコレクションが自動的に作成されるクラスタです。現時点では、GCP us-west 1にデプロイされたクラスタのみとなります。
コレクション名
自動作成されたコレクションの名前。
パイプライン名
新しいIngestionパイプラインの名前です。小文字、数字、アンダースコアのみを含める必要があります。
説明(オプション)
新しいIngestionパイプラインの説明。
-
IngestionパイプラインにINDEX関数を追加するには、+Functionをクリックします。各Ingestionパイプラインに対して、正確に1つのINDEX関数を追加できます。
-
関数名を入力します。
-
関数タイプとしてINDEX_DOCを選択してください。INDEX_DOC関数は、オブジェクトストレージ(事前署名URLとして)またはローカルアップロードから文書ファイルをチャンクに分割し、チャンクのベクトル埋め込みを生成できます。
-
ベクトル埋め込みを生成するために使用する埋め込みモデルを選択してください。異なるドキュメント言語には異なる埋め込みモデルがあります。現在、英語には5つのモデルがあります:zilliz/bge-base-en-v 1.5、voyageai/voyage-2、voyageai/voyage-code-2、openai/text-embedding-3-small、およびopenai/text-embedding-3-large。中国語には、zilliz/bge-base-zh-v 1.5のみが利用可能です。以下の図は、各埋め込みモデルを簡単に紹介しています。
埋め込みモデル
説明する
zilliz/bge-based-en-v 1.5-ダウンロード
BAAIによってリリースされたこの最先端のオープンソースモデルは、Zilliz Cloudにホストされ、ベクトルデータベースと共有されており、高品質で最高のネットワークレイテンシを提供しています。
Voyage AIによってホストされています。この汎用モデルは、説明的なテキストとコードを含む技術文書の取得に優れています。軽量版はvoyage-lite-02-instructMTEBリーダーボードでトップにランクされています。このモデルは、
言語が英語の場合にのみ利用可能です。Voyage AIがホストしています。このモデルはソフトウェアコードに最適化されており、ソフトウェアドキュメントとソースコードを取得するための優れた品質を提供します。このモデルは、
言語が英語の場合にのみ利用可能です。Voyage AIによってホストされています。これはVoyage AIからの最も強力な汎用埋め込みモデルです。16 kのコンテキスト長(voyage-2の4倍)をサポートし、技術的および長いコンテキスト文書を含むさまざまなタイプのテキストに優れています。このモデルは、
言語が英語の場合にのみ利用可能です。Open AIによってホストされています。この非常に効率的な埋め込みモデルは、先行モデルよりも強力なパフォーマンスを持ちtext-embedding-ada-002推論コストと品質をバランスさせています。このモデルは、
言語が英語の場合にのみ利用可能です。Open AIがホストしています。これはOpen AIの最高のパフォーマンスモデルです。text-embedding-ada-002と比較して、MTEBスコアは61.0%から64.6%に増加しました。このモデルは、
言語が英語の場合にのみ利用可能です。zilliz/bge-base-zh-v 1.5-ダウンロード
BAAIによってリリースされたこの最先端のオープンソースモデルは、Zilliz Cloudにホストされ、ベクトルデータベースと共同配置されており、高品質で最高のネットワークレイテンシを提供します。これは、
言語が中国語の場合のデフォルトの埋め込みモデルです。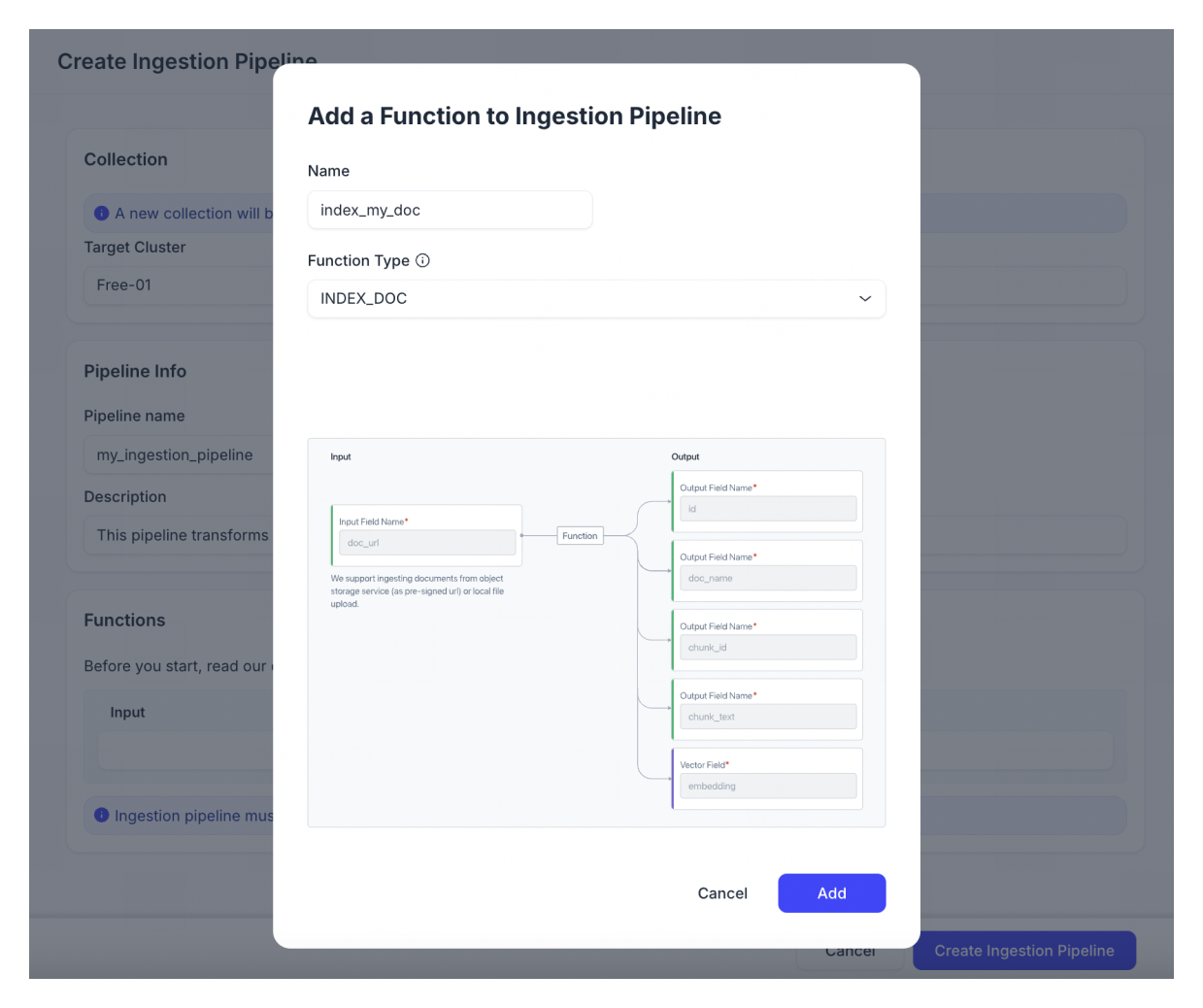
-
[追加]をクリックして関数を保存します。
-
-
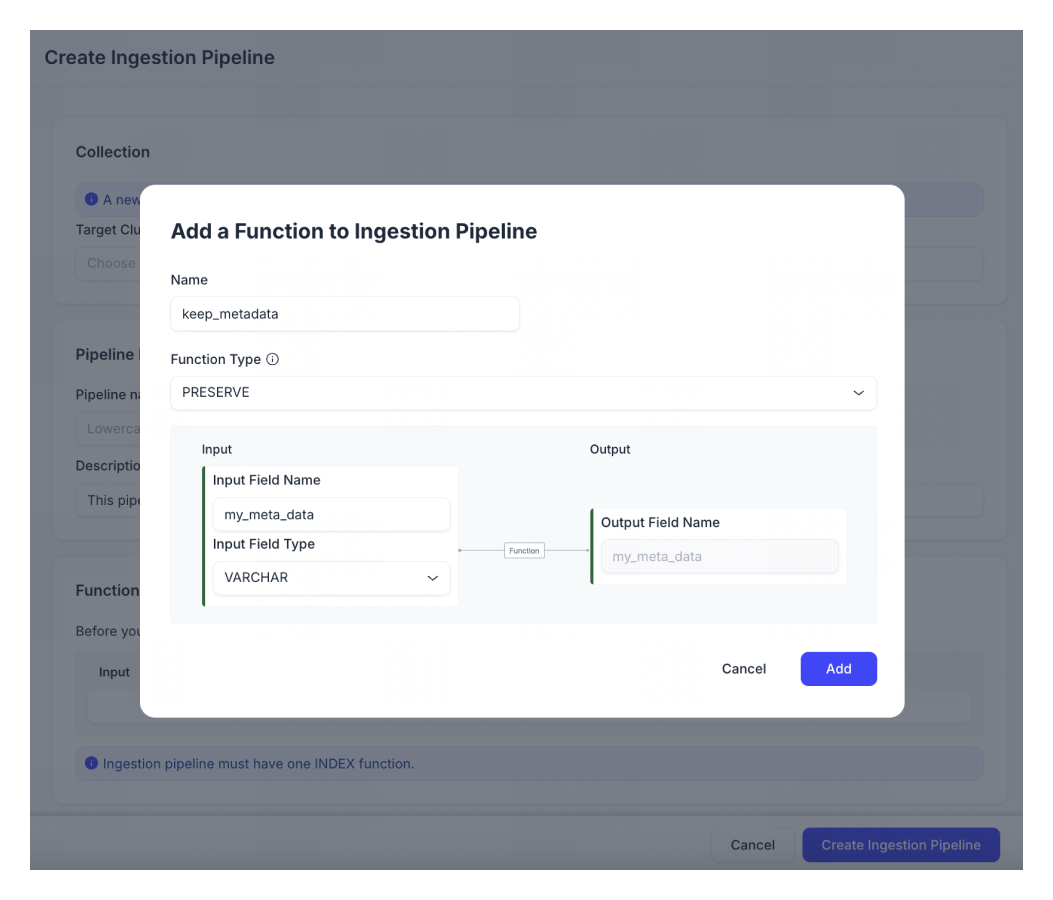
(オプション)ドキュメントのメタデータを保存する必要がある場合は、別のPRESERVE関数を追加してください。PRESERVE関数は、データの取り込みとともに、コレクションに追加のスカラーフィールドを追加します。
📘ノート各Ingestionパイプラインについて、最大50個のPRESERVE関数を追加できます。
-
[+Function]をクリックします。
-
関数名を入力します。
-
入力フィールドの名前と種類を設定します。サポートされている入力フィールドの種類は、Bool、Int 8、Int 16、Int 32、Int 64、Float、Double、VarCharです。
📘ノート現在、出力フィールド名は入力フィールド名と同じでなければなりません。入力フィールド名は、Ingestionパイプラインを実行する際に使用されるフィールド名を定義します。出力フィールド名は、保存された値が保持されるベクトルコレクションスキーマ内のフィールド名を定義します。
VarCharフィールドの場合、値は最大4,000文字の英数字の文字列である必要があります。
スカラーフィールドに日時を格納する場合は、年データにはInt 16データ型、タイムスタンプにはInt 32データ型を使用することをお勧めします。
-
[追加]をクリックして関数を保存します。
-
-
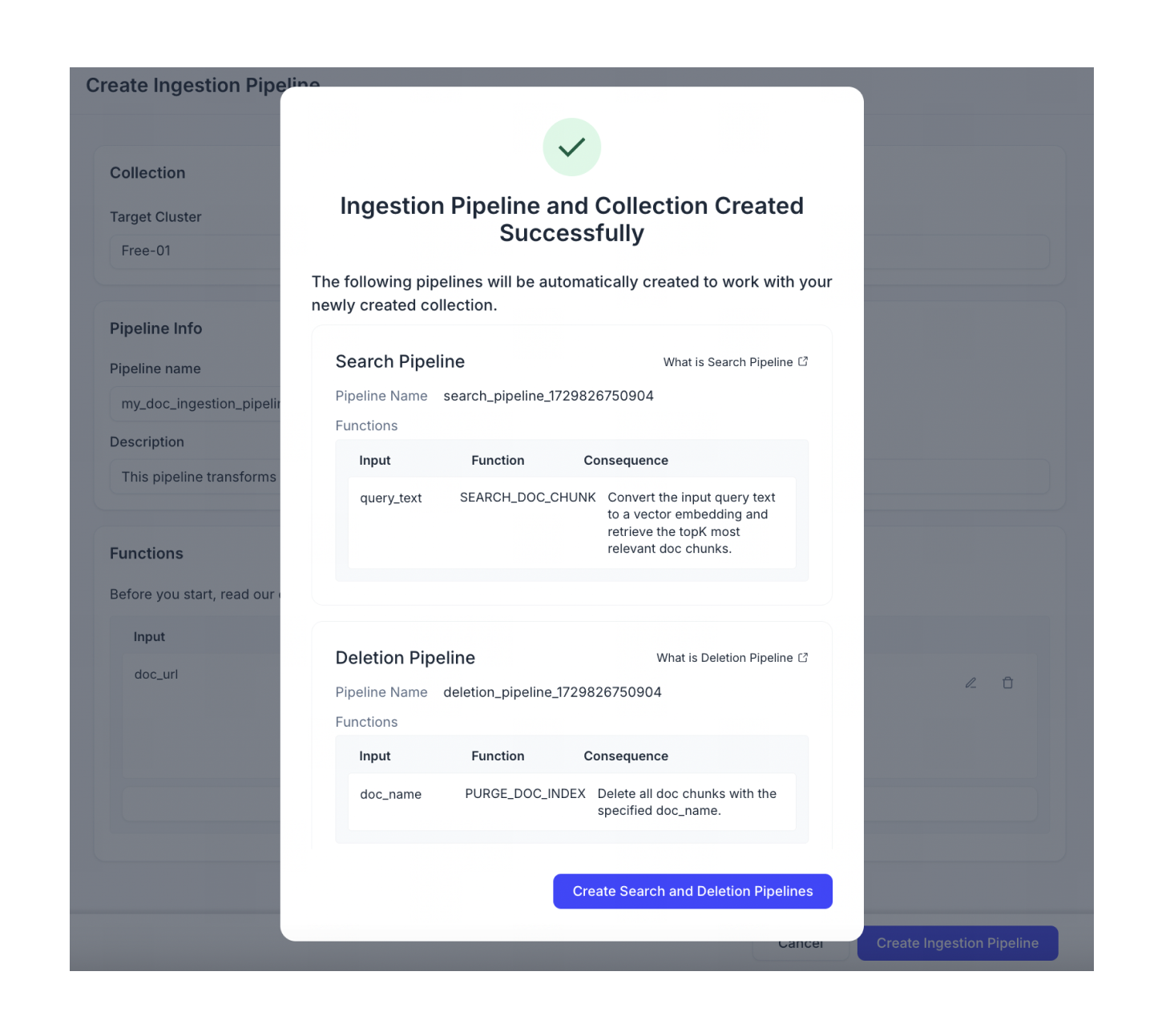
[Ingestion Pipelineを作成]をクリックします。
-
作成したばかりのIngestionパイプラインと互換性があるように自動構成された検索パイプラインと削除パイプラインの作成を続けます。
 📘ノート
📘ノートデフォルトでは、自動設定された検索パイプラインでreranker機能は無効になっています。rerankerを有効にする必要がある場合は、手動で新しい検索パイプラインを作成してください。
次の例では、という名前のIngestionパイプラインを作成しますmy_doc_ingestion_パイプライン、INDEX_DOC関数とPRESERVE関数を追加します。
curl --request POST \
--header "Content-Type: application/json" \
--header "Authorization: Bearer ${YOUR_API_KEY}" \
--url "https://controller.api.{cloud-region}.zillizcloud.com/v1/pipelines" \
-d '{
"projectId": "proj-xxxx",
"name": "my_doc_ingestion_pipeline",
"description": "A pipeline that splits a doc file into chunks and generates embeddings. It also stores the publish_year with each chunk.",
"type": "INGESTION",
"functions": [
{
"name": "index_my_doc",
"action": "INDEX_DOC",
"language": "ENGLISH",
"chunkSize": 500,
"embedding": "zilliz/bge-base-en-v1.5",
"splitBy": ["\n\n", "\n", " ", ""]
},
{
"name": "keep_doc_info",
"action": "PRESERVE",
"inputField": "publish_year",
"outputField": "publish_year",
"fieldType": "Int16"
}
],
"clusterId": "inxx-xxxxxxxxxxxxxxx",
"collectionName": "my_collection"
}'
上記のコードのパラメータは次のように説明されています
-
YOUR_API_KEY: APIリクエストの認証に使用される資格情報。APIキーの表示方法については、こちらをご覧ください。 -
cloud-region:クラスターが存在するクラウドリージョンのID。現在、gcp-us-west 1のみがサポートされています。 -
lusterId:パイプラインを作成するクラスタのIDです。現在、GCP上のus-west 1にデプロイされたクラスタのみを選択できます。CLUSTER_IDの確認方法については、How can I find my CLUSTER_ID?を参照してください。 -
projectId:パイプラインを作成するプロジェクトのID。詳しくはプロジェクトIDの取得方法をご覧ください。 -
lectionName:作成するインジェストパイプラインで自動的に生成されるコレクションの名前です。また、既存のコレクションを指定することもできます。 -
name:作成するパイプラインの名前。パイプライン名は3~64文字の文字列で、英数字とアンダースコアのみを含めることができます。 -
description(オプション):作成するパイプラインの説明。 -
type:作成するパイプラインの種類。現在利用可能なパイプラインの種類には、INGESTION、SEARCH、DELETIONがあります。 -
functions:パイプラインに追加する関数。Ingestionパイプラインには、1つのINDEX関数と最大50個のPRESERVE関数しか持てません。-
name:関数の名前です。関数名は3~64文字の文字列で、英数字とアンダースコアのみを含めることができます。 -
action:追加する関数の種類。現在利用可能なオプションには、INDEX_DOC、INDEX_TEXT、INDEX_IMAGE、PRESERVEがあります。 -
language:取り込むドキュメントの言語を指定します。使用可能な値はENGLISHとCHINESEです。(このパラメータはINDEX_DOC関数でのみ使用されます。) -
埋め込み:ドキュメントのベクトル埋め込みを生成するために使用する埋め込みモデルです。利用可能なオプションは以下の通りです。(このパラメータはIn dex関数でのみ使用されます。)埋め込みモデル
説明する
zilliz/bge-based-en-v 1.5-ダウンロード
BAAIによってリリースされたこの最先端のオープンソースモデルは、Zilliz Cloudにホストされ、ベクトルデータベースと共有されており、高品質で最高のネットワークレイテンシを提供しています。
Voyage AIによってホストされています。この汎用モデルは、説明的なテキストとコードを含む技術文書の取得に優れています。軽量版はvoyage-lite-02-instructMTEBリーダーボードでトップにランクされています。このモデルは、
言語が英語の場合にのみ利用可能です。Voyage AIがホストしています。このモデルはソフトウェアコードに最適化されており、ソフトウェアドキュメントとソースコードを取得するための優れた品質を提供します。このモデルは、
言語が英語の場合にのみ利用可能です。Voyage AIによってホストされています。これはVoyage AIからの最も強力な汎用埋め込みモデルです。16 kのコンテキスト長(voyage-2の4倍)をサポートし、技術的および長いコンテキスト文書を含むさまざまなタイプのテキストに優れています。このモデルは、
言語が英語の場合にのみ利用可能です。Open AIによってホストされています。この非常に効率的な埋め込みモデルは、先行モデルよりも強力なパフォーマンスを持ちtext-embedding-ada-002推論コストと品質をバランスさせています。このモデルは、
言語が英語の場合にのみ利用可能です。Open AIがホストしています。これはOpen AIの最高のパフォーマンスモデルです。text-embedding-ada-002と比較して、MTEBスコアは61.0%から64.6%に増加しました。このモデルは、
言語が英語の場合にのみ利用可能です。zilliz/bge-base-zh-v 1.5-ダウンロード
BAAIによってリリースされたこの最先端のオープンソースモデルは、Zilliz Cloudにホストされ、ベクトルデータベースと共同配置されており、高品質で最高のネットワークレイテンシを提供します。これは、
言語が中国語の場合のデフォルトの埋め込みモデルです。 -
chunkSize(オプション): INDEX_DOC関数は、各ドキュメントをより小さなチャンクに分割します。デフォルトでは、各チャンクには500トークン以下しか含まれませんが、カスタムチャンキング戦略に合わせて体格を調整できます。各埋め込みモデルでサポートされるチャンク体格範囲の詳細については、Zillizクラウドの制限を参照してください。さらに、マークダウンまたはHTMLファイルの場合、この関数は最初にヘッダーでドキュメントを分割し、次に指定されたチャンク体格に基づいてさらに大きなセクションで分割します。(このパラメータは
INDEX_DOC関数でのみ使用されます。) -
splitBy(オプション):分割子を使用して、区切り文字のリストに基づいてドキュメントを分割し、チャンクが定義されたチャンク体格以下になるようにします。デフォルトでは、Zilliz Cloud Pipelinesは["\n\n","\n","""]を区切り文字として使用します。(このパラメータはINDEX_DOC関数でのみ使用されます。)
-
-
input tField:inputフィールドの名前です。値はカスタマイズできますが、output tFieldと同じにしてください。(このパラメータはPRESERVE関数でのみ使用されます。) -
outputField:コレクションスキーマで使用される出力フィールドの名前。現在、出力フィールドの名前は入力フィールドの名前と同じでなければなりません。(このパラメータはPRESERVE関数でのみ使用されます。) -
fieldType:入力フィールドと出力フィールドのデータ型です。使用可能な値は、Bool、Int 8、Int 16、Int 32、Int 64、Float、Double、およびVarCharです。(このパラメータはPRESERVE関数でのみ使用されます。)📘ノートスカラーフィールドに日時を格納する場合は、年データにはInt 16データ型、タイムスタンプにはInt 32データ型を使用することをお勧めします。
VarCharフィールド
型の場合、このフィールドのデータのmax_lengthは4,000を超えることはできません。
以下は出力例です。
{
"code": 200,
"data": {
"pipelineId": "pipe-xxxx",
"name": "my_doc_ingestion_pipeline",
"type": "INGESTION",
"createTimestamp": 1721187300000,
"description": "A pipeline that splits a doc file into chunks and generates embeddings. It also stores the publish_year with each chunk.",
"status": "SERVING",
"totalUsage": {
"embedding": 0
},
"functions": [
{
"action": "INDEX_DOC",
"name": "index_my_doc",
"inputField": "doc_url",
"language": "ENGLISH",
"chunkSize": 500,
"embedding": "zilliz/bge-base-en-v1.5",
"splitBy": ["\n\n", "\n", " ", ""]
},
{
"action": "PRESERVE",
"name": "keep_doc_info",
"inputField": "publish_year",
"outputField": "publish_year",
"fieldType": "Int16"
}
],
"clusterId": "in03-***************",
"collectionName": "my_collection"
}
}
技術的な制限により、総使用データが数時間遅れる可能性があります。
Ingestionパイプラインが作成されると、my_collectionという名前のコレクションが自動的に作成されます。
このコレクションには、自動的に生成されるIDフィールド1つ、INDEX_DOC関数の出力フィールド4つ、およびPRESERVE関数ごとの出力フィールド1つの6つのフィールドが含まれています。コレクションのスキーマは以下の通りです。
id (データ型: Int 64) | ドキュメント名 (データ型: VarChar) | チャンクID (データ型: Int 64) | チャンクテキスト (データ型: VarChar) | 埋め込み (データ型: FLOAT_VECTOR) | パブリッシュ年 (データ型: Int 16) |
|---|
文書取り込みパイプラインの実行
- Cloud Console
- Bash
-
インジェスチョンパイプラインの横にある「▶︎」ボタンをクリックしてください。または、プレイグラウンドタブをクリックすることもできます。
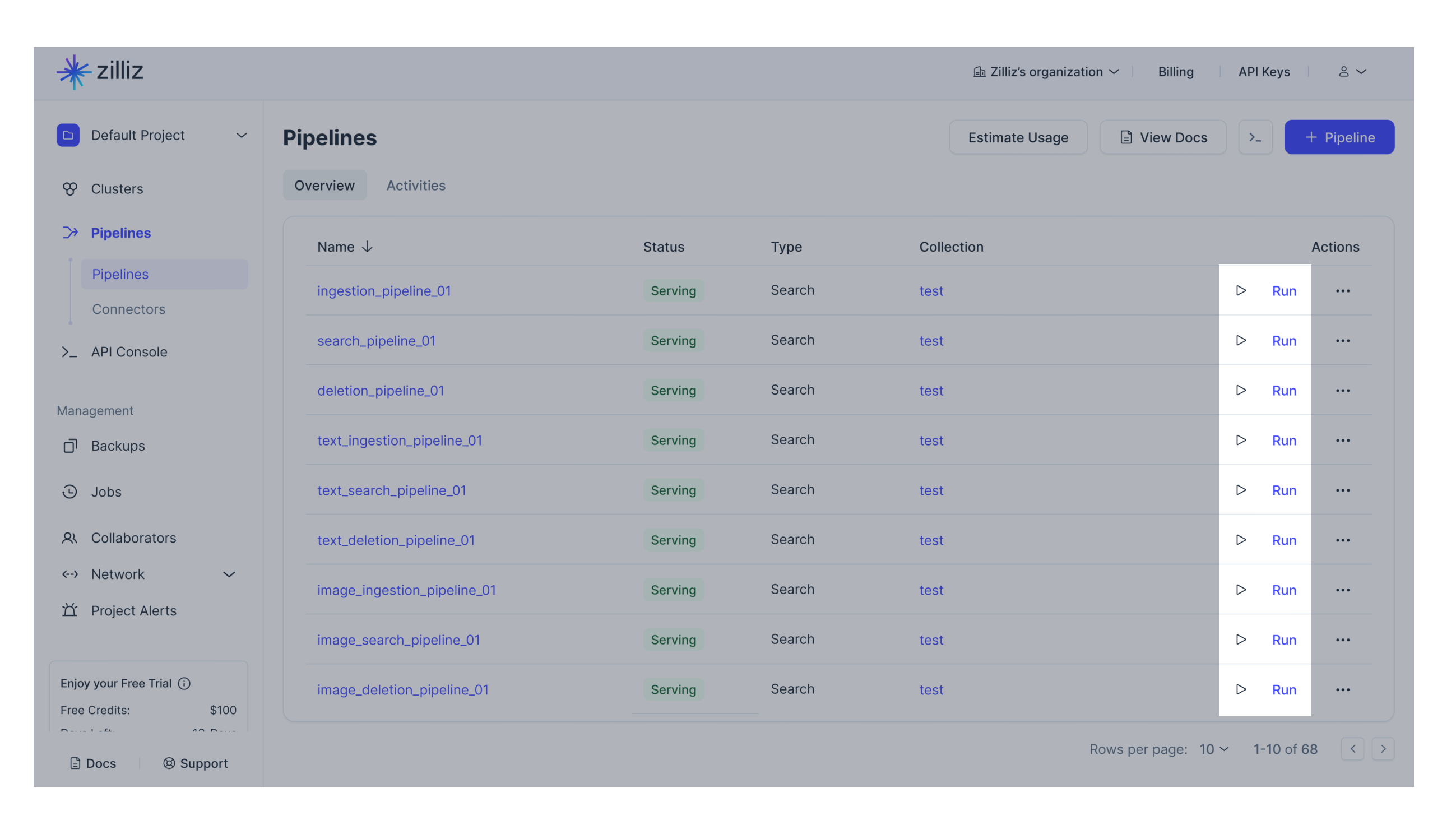
-
ファイルを取り込みます。Zilliz Cloudには、データを取り込む2つの方法があります。
- オブジェクトストレージにファイルを取り込む必要がある場合は、コードのS 3事前署名URLまたはGCS署名URLを
doc_urlフィールドに直接入力できます。
- ローカルファイルをアップロードする場合は、Attach Fileをクリックします。ダイアログポップアップで、ローカルファイルをアップロードします。ファイルのサイズは10 MB以下である必要があります。サポートされるファイル形式は、
. txt、.pdf、.md、.html、.epub、.csv、.document、.docx、.xls、.xlsx、.ppt、.pptxです。アップロードが成功したら、Attach<--atag--28/>をクリックします。このIngestionパイプラインに保存機能を追加した場合は、「data」フィールドを設定してください。
- オブジェクトストレージにファイルを取り込む必要がある場合は、コードのS 3事前署名URLまたはGCS署名URLを
-
結果を確認してください。
-
ドキュメントを削除して再度実行します。
オブジェクトストレージからのファイルでインジェストパイプラインを実行するか、ローカルファイルで実行することができます。
オブジェクトストレージ内のファイルを使用してインジェストパイプラインを実行します
-
パイプラインを実行する前に、ドキュメントをAWS S 3またはGoogle Cloud Storage(GCS)にアップロードしてください。サポートされているファイルタイプには、
. txt、.pdf、.md、.html、.epub、.csv、.文書、.docx、.xls、.xlsx、.ppt、.pptxがあります。 -
ドキュメントをアップロードしたら、S 3事前署名URLまたはGCS署名URLを取得してください。
-
コマンドを実行します。次の例では、Ingestionパイプライン
my_doc_ingestion_Pipelineを実行します。published_yearは、保持したいメタデータフィールドです。curl --request POST \
--header "Content-Type: application/json" \
--header "Authorization: Bearer ${YOUR_API_KEY}" \
--url "https://controller.api.{cloud-region}.zillizcloud.com/v1/pipelines/${YOUR_PIPELINE_ID}/run" \
-d '{
"data": {
"doc_url": "https://storage.googleapis.com/example-bucket/zilliz_concept_doc.md?X-Goog-Algorithm=GOOG4-RSA-SHA256&X-Goog-Credential=example%40example-project.iam.gserviceaccount.com%2F20181026%2Fus-central1%2Fstorage%2Fgoog4_request&X-Goog-Date=20181026T181309Z&X-Goog-Expires=900&X-Goog-SignedHeaders=host&X-Goog-Signature=247a2aa45f169edf4d187d54e7cc46e4731b1e6273242c4f4c39a1d2507a0e58706e25e3a85a7dbb891d62afa8496def8e260c1db863d9ace85ff0a184b894b117fe46d1225c82f2aa19efd52cf21d3e2022b3b868dcc1aca2741951ed5bf3bb25a34f5e9316a2841e8ff4c530b22ceaa1c5ce09c7cbb5732631510c20580e61723f5594de3aea497f195456a2ff2bdd0d13bad47289d8611b6f9cfeef0c46c91a455b94e90a66924f722292d21e24d31dcfb38ce0c0f353ffa5a9756fc2a9f2b40bc2113206a81e324fc4fd6823a29163fa845c8ae7eca1fcf6e5bb48b3200983c56c5ca81fffb151cca7402beddfc4a76b133447032ea7abedc098d2eb14a7",
"publish_year": 2023
}
}'上記のコードのパラメータは次のように説明されています
-
YOUR_API_KEY: APIリクエストの認証に使用される資格情報。APIキーの表示方法については、こちらをご覧ください。 -
cloud-region:クラスターが存在するクラウドリージョンのID。現在、gcp-us-west 1のみがサポートされています。 -
doc_url:オブジェクトストレージに保存されているドキュメントのURLです。エンコードされていないか、UTF-8でエンコードされたURLを使用してください。URLが少なくとも1時間有効であることを確認してください。 -
{YOUR_PRESERVED_FIELD}(オプション):保存するメタデータフィールド。入力フィールド名は、Ingestionパイプラインを作成し、PRESERVE関数を追加したときに定義したものと一致する必要があります。このフィールドの値は、定義済みのフィールドタイプに従う必要があります。
以下は回答例です。
{
"code": 200,
"data": {
"doc_name": "zilliz_concept_doc.md",
"usage": {
"embedding": 1241
},
"num_chunks": 3
}📘ノート出力の
doc_nameフィールドは重要な役割を果たします。同一のドキュメントに異なるdoc_name値が割り当てられている場合、それらは別々のエンティティとして取り込まれます。これは、同じコンテンツがデータベースに2回保存される可能性があることを意味します。 -
ローカルファイルを使用してインジェスチョンパイプラインを実行する
ローカルファイルを取り込むには、以下のコマンドを実行してください。
curl --request POST \
--header "Content-Type: multipart/form-data" \
--header "Authorization: Bearer ${YOUR_API_KEY}" \
--url "https://controller.api.{cloud-region}.zillizcloud.com/v1/pipelines/${YOUR_PIPELINE_ID}/run_ingestion_with_file" \
--form 'data={"year": 2023}' \
--form 'file=@path/to/local/file.ext'
上記のコードのパラメータは次のように説明されています
-
YOUR_API_KEY: APIリクエストの認証に使用される資格情報。APIキーの表示方法については、こちらをご覧ください。 -
cloud-region:クラスターが存在するクラウドリージョンのID。現在、gcp-us-west 1のみがサポートされています。 -
YOUR_PIPELINE_ID:実行するインジェストパイプラインのID。 -
ファイル:ローカルファイルへのパスです。サポートされているファイルタイプは、. txt、.pdf、.md、.html、.epub、.csv、.文書、.docx、.xls、.xlsx、.ppt、.pptxです。 -
data(オプション):保持するメタデータフィールド。入力フィールド名は、Ingestionパイプラインを作成し、PRESERVE関数を追加したときに定義したものと一致する必要があります。このフィールドの値は、定義済みのフィールドタイプに従う必要があります。
以下は回答例です。
{
"code": 200,
"data": {
"doc_name": "zilliz_concept_doc.md",
"usage": {
"embedding": 1241
},
"num_chunks": 3
}
技術的な制限により、使用データが数時間遅れる可能性があります。
文書データを検索する
任意のデータを検索するには、まず検索パイプラインを作成してから実行する必要があります。IngestionおよびDeletionパイプラインとは異なり、検索パイプラインを作成する場合、クラスタとコレクションはパイプラインレベルではなく関数レベルで定義されます。これは、Zilliz Cloudが複数のコレクションから同時に検索できるためです。
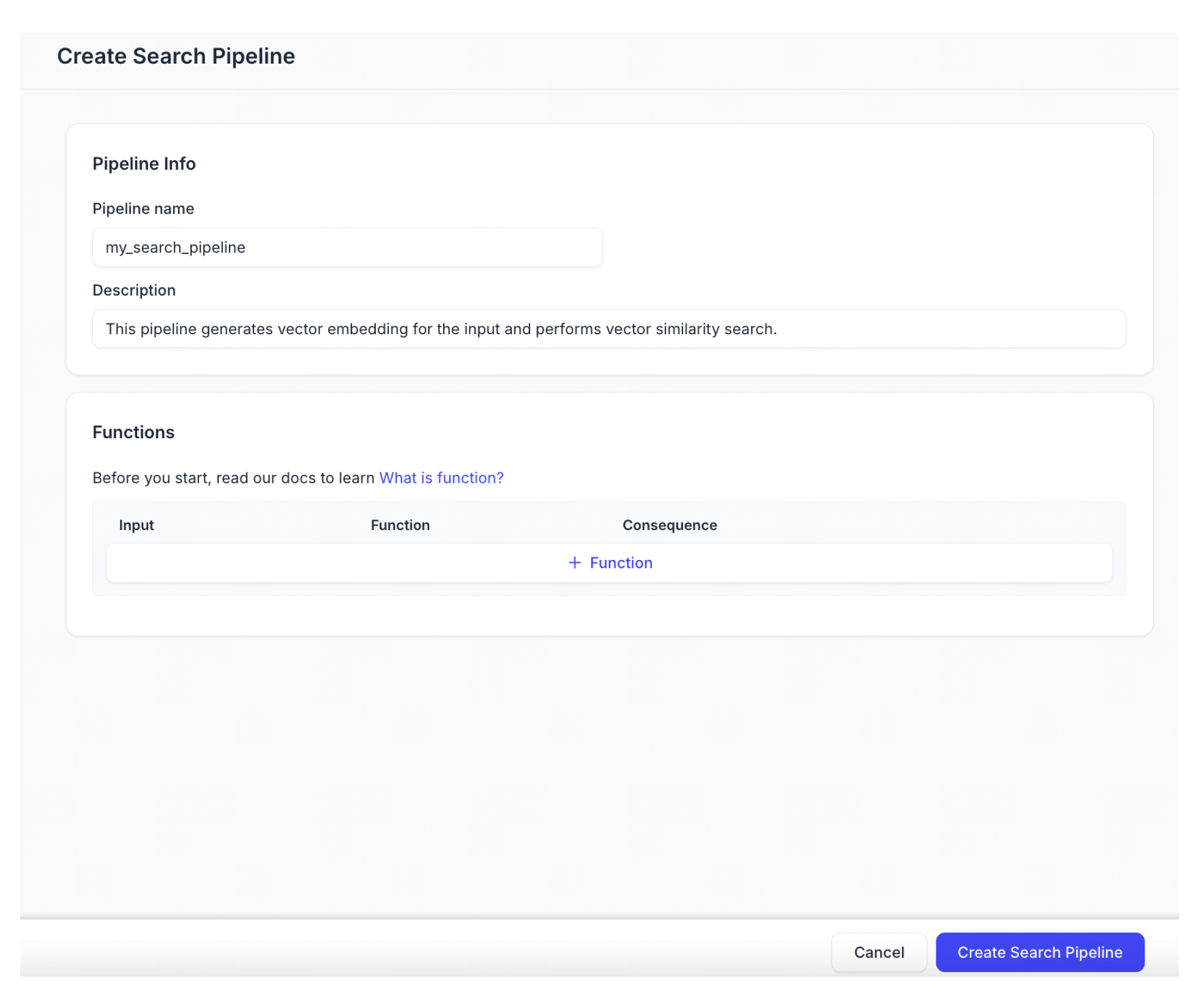
文書検索パイプラインの作成
- Cloud Console
- Bash
-
プロジェクトに移動します。
-
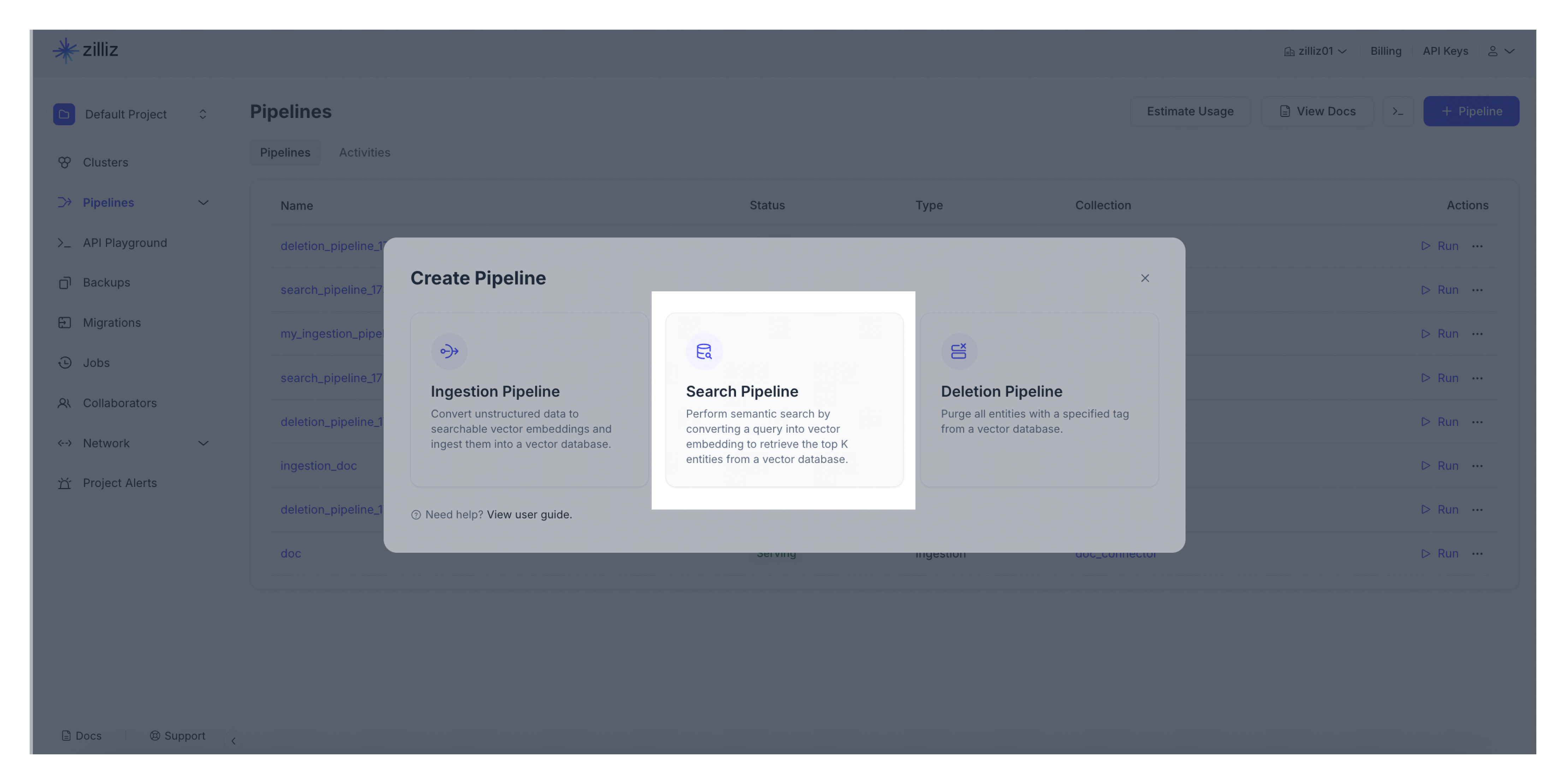
ナビゲーションパネルからパイプラインをクリックします。次に、概要タブに切り替えて、パイプラインをクリックします。パイプラインを作成するには、+パイプラインをクリックしてください。
-
作成するパイプラインの種類を選択してください。「+パイプライン」ボタンを検索パイプライン欄でクリックしてください。
-
作成したい検索パイプラインを構成します。
パラメータ
説明する
パイプライン名
新しい検索パイプラインの名前です。小文字、数字、アンダースコアのみを含める必要があります。
説明(オプション)
新しい検索パイプラインの説明。
-
「+Function」をクリックして、検索パイプラインに関数を追加します。正確に1つの関数を追加できます。
-
関数名を入力します。
-
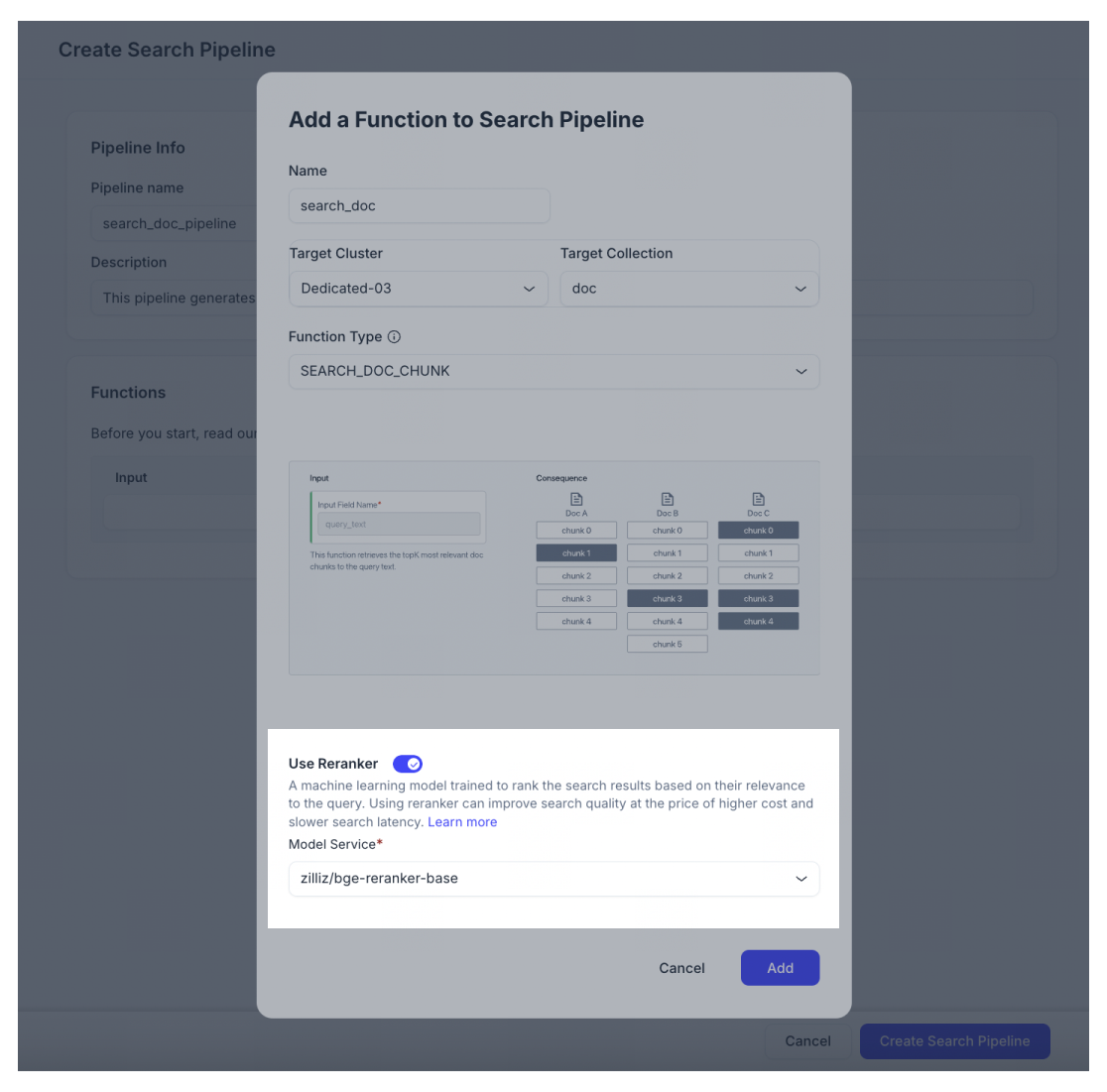
「Target Cluster」と「Target collection」を選択します。Target Clusterは、**us-west 1 on Google Cloud Platform(GCP)**にデプロイされたクラスタである必要があります。また、Target CollectionはIngestionパイプラインによって作成されている必要があります。そうでない場合、Searchパイプラインは互換性がありません。
-
Function TypeとしてSEARCH_DOC_CHUNKを選択してください。Function TypeとしてSEARCH_DOC_CHUNK関数を使用すると、入力クエリテキストをベクトル埋め込みに変換し、最も関連性の高い文書チャンクを取得できます。
-
(オプション)rerankerを有効にすると、クエリとの関連性に基づいて検索結果をランク付けして検索品質を向上させることができます。ただし、rerankerを有効にすると、コストと検索レイテンシが高くなることに注意してください。デフォルトでは、この機能は無効になっています。有効にすると、再ランキングに使用するモデルサービスを選択できます。現在、zilliz/bge-reranker-baseのみが利用可能です。
リランカーモデルサービス
説明する
zilliz/bge-reranker-base-ダウンロード
オープンソースのクロスエンコーダアーキテクチャの再ランクモデルはBAAIによって公開されています。このモデルはZilliz Cloudにホストされています。
-
[追加]をクリックして関数を保存します。
-
-
[検索パイプラインを作成]をクリックします。
次の例では、my_text_search_パイプラインという名前の検索パイプラインを作成し、SEARCH_DOC_CHUNK関数を追加します。
curl --request POST \
--header "Content-Type: application/json" \
--header "Authorization: Bearer ${YOUR_API_KEY}" \
--url "https://controller.api.{cloud-region}.zillizcloud.com/v1/pipelines" \
-d '{
"projectId": "proj-xxxx",
"name": "my_text_search_pipeline",
"description": "A pipeline that receives text and search for semantically similar doc chunks",
"type": "SEARCH",
"functions": [
{
"name": "search_chunk_text_and_title",
"action": "SEARCH_DOC_CHUNK",
"clusterId": "inxx-xxxxxxxxxxxxxxx",
"collectionName": "my_collection",
"embedding": "zilliz/bge-base-en-v1.5",
"reranker": "zilliz/bge-reranker-base"
}
]
}'
上記のコードのパラメータは次のように説明されています
-
YOUR_API_KEY: APIリクエストの認証に使用される資格情報。APIキーの表示方法については、こちらをご覧ください。 -
cloud-region:クラスターが存在するクラウドリージョンのID。現在、gcp-us-west 1のみがサポートされています。 -
projectId:パイプラインを作成するプロジェクトのID。詳しくはプロジェクトIDの取得方法をご覧ください。 -
name:作成するパイプラインの名前。パイプライン名は3~64文字の文字列で、英数字とアンダースコアのみを含めることができます。 -
description(オプション):作成するパイプラインの説明。 -
type:作成するパイプラインの種類。現在利用可能なパイプラインの種類には、INGESTION、SEARCH、DELETIONがあります。 -
functions:パイプラインに追加する関数。Searchパイプラインには1つの関数しか持てません。-
name:関数の名前です。関数名は3~64文字の文字列で、英数字とアンダースコアのみを含めることができます。 -
action:追加する関数の種類。現在利用可能なオプションは、SEARCH_DOC_CHUNK、SEARCH_TEXT、SEARCH_IMAGE_BY_IMAGE、SEARCH_IMAGE_BY_TEXTです。 -
lusterId:パイプラインを作成するクラスタのIDです。現在、GCP us-west 1にデプロイされたクラスタのみを選択できます。詳しくはHow can I find my CLUSTER_ID? -
collectionName:パイプラインを作成するコレクションの名前。 -
埋め込み:ベクトル検索中に使用される埋め込みモデル。モデルは、互換性のあるコレクションで選択されたものと一致する必要があります。 -
reranker(オプション):検索結果の品質を向上させるために、一連の候補出力を並べ替えたりランク付けしたりするためのオプションのパラメータです。rerankerが必要ない場合は、このパラメータを省略できます。現在、パラメータ値としてzilliz/bge-reranker-baseのみが利用可能です。
-
以下は出力例です。
{
"code": 200,
"data": {
"pipelineId": "pipe-84e6d9dba930e035150972",
"name": "my_text_search_pipeline",
"type": "SEARCH",
"createTimestamp": 1721187655000,
"description": "A pipeline that receives text and search for semantically similar doc chunks",
"status": "SERVING",
"totalUsage": {
"embedding": 0,
"rerank": 0
},
"functions":
{
"action": "SEARCH_DOC_CHUNK",
"name": "search_chunk_text_and_title",
"inputField": "query_text",
"clusterId": "in03-***************",
"collectionName": "my_collection",
"embedding": "zilliz/bge-base-en-v1.5",
"reranker": "zilliz/bge-reranker-base"
}
}
}
技術的な制限により、総使用データが数時間遅れる可能性があります。
文書検索パイプラインの実行
- Cloud Console
- Bash
-
検索パイプラインの横にある「▶︎」ボタンをクリックしてください。または、プレイグラウンドタブをクリックすることもできます。
-
必要なパラメータを設定します。[実行]をクリックします。
-
結果を確認してください。
-
パイプラインを再実行する新しいクエリテキストを入力します。
以下の例では、my_text_search_Pipelineという名前の検索パイプラインを実行しています。クエリテキストは「8つ以上のCUを持つクラスタは何個のコレクションを保持できますか?」です。
curl --request POST \
--header "Content-Type: application/json" \
--header "Authorization: Bearer ${YOUR_API_KEY}" \
--url "https://controller.api.{cloud-region}.zillizcloud.com/v1/pipelines/${YOUR_PIPELINE_ID}/run" \
-d '{
"data": {
"query_text": "How many collections can a cluster with more than 8 CUs hold?"
},
"params":{
"limit": 1,
"offset": 0,
"outputFields": [ "chunk_id", "doc_name" ],
"filter": "id >= 0",
}
}'
上記のコードのパラメータは次のように説明されています
-
YOUR_API_KEY: APIリクエストの認証に使用される資格情報。APIキーの表示方法については、こちらをご覧ください。 -
cloud-region:クラスターが存在するクラウドリージョンのID。現在、gcp-us-west 1のみがサポートされています。 -
query_text:このフィールドの値にクエリしたいテキスト文字列を入力してください。 -
params:設定する検索パラメータ。-
limit:返すエンティティの最大数。値は1から500までの整数である必要があります。この値とoffsetの値の合計は1024になる必要があります。 -
オフセット:検索結果でスキップするエンティティの数。この値と
limitの合計は大なり1024ではありません。最大値は1024です。 -
outputFields:検索結果とともに返されるフィールドの配列です。デフォルトでは、id(エンティティID)、distance、chunk_textが検索結果に返されます。返される結果に他の出力フィールドが必要な場合は、このパラメータを設定できます。 -
フィルター:検索に一致するものを見つけるために使用されるブール式のフィルター
-
以下は回答例です。
{
"code": 200,
"data": {
"result": [
{
"id": 450524927755105957,
"distance": 0.99967360496521,
"chunk_id": 0,
"doc_name": "zilliz_concept_doc.md",
"chunk_text": "# Cluster, Collection & Entities\nA Zilliz Cloud cluster is a managed Milvus instance associated with certain computing resources. You can create collections in the cluster and insert entities into them. In comparison to a relational database, a collection in a cluster is similar to a table in the database, and an entity in a collection is similar to a record in the table.\\\n\\\n# Cluster, Collection & Entities\n## Cluster\nWhen creating a cluster on Zilliz Cloud, you must specify the type of CU associated with the cluster. There are three types of CUs available: performance-optimized and capacity-optimized. You can learn how to choose among these types in [Select the Right CU](https://zilliverse.feishu.cn/wiki/UgqvwKh2QiKE1kkYNLJcaHt0nkg). \nAfter determining the CU type, you must also specify its size. Note that the number of collections a cluster can hold varies based on its CU size. A cluster with less than 8 CUs can hold no more than 32 collections, while a cluster with more than 8 CUs can hold as many as 256 collections. \nAll collections in a cluster share the CUs associated with the cluster. To save CUs, you can unload some collections. When a collection is unloaded, its data is moved to disk storage and its CUs are freed up for use by other collections. You can load the collection back into memory when you need to query it. Keep in mind that loading a collection requires some time, so you should only do so when necessary.\\\n\\\n# Cluster, Collection & Entities\n## Collection\nA collection collects data in a two-dimensional table with a fixed number of columns and a variable number of rows. In the table, each column corresponds to a field, and each row represents an entity. \nThe following figure shows a sample collection that comprises six entities and eight fields."
},
{
"id": 450524927755105959,
"distance": 0.07810573279857635,
"chunk_id": 2,
"doc_name": "zilliz_concept_doc.md",
"chunk_text": "# Cluster, Collection & Entities\n## Collection\n### Index\nUnlike Milvus instances, Zilliz Cloud clusters only support the **AUTOINDEX** algorithm for indexing. This algorithm is optimized for the three types of computing units (CUs) supported by Zilliz Cloud. For more information, see [AUTOINDEX Explained](https://zilliverse.feishu.cn/wiki/EA2twSf5oiERMDkriKScU9GInc4).\\\n\\\n# Cluster, Collection & Entities\n## Entities\nEntities in a collection are data records sharing the same set of fields, like a book in a library or a gene in a genome. As to an entity, the data stored in each field forms the entity. \nBy specifying a query vector, search metrics, and optional filtering conditions, you can conduct vector searches among the entities in a collection. For example, if you search with the keyword \"Interesting Python demo\", any article whose title implies such semantic meaning will be returned as a relevant result. During this process, the search is actually conducted on the vector field **title_vector** to retrieve the top K nearest results. For details on vector searches, see [Search and Query](https://zilliverse.feishu.cn/wiki/YfMEwLHzeisARCk4VZ3cVhJmnjd). \nYou can add as many entities to a collection as you want. However, the size that an entity takes grows along with the increase of the dimensions of the vectors in the entity, reversely affecting the performance of searches within the collection. Therefore, plan your collection wisely on Zilliz Cloud by referring to [Schema Explained](https://zilliverse.feishu.cn/wiki/Vs4YwNnvzitoQ8kunlGcWMJInbf)."
},
{
"id": 450524927755105958,
"distance": 0.046239592134952545,
"chunk_id": 1,
"doc_name": "zilliz_concept_doc.md",
"chunk_text": "# Cluster, Collection & Entities\n## Collection\n### Fields\nIn most cases, people describe an object in terms of its attributes, including size, weight, position, etc. These attributes of the object are similar to the fields in a collection. \nAmong all the fields in a collection, the primary key is one of the most special, because the values stored in this field are unique throughout the entire collection. Each primary key maps to a different record in the collection. \nIn the collection shown in Figure 1, the **id** field is the primary key. The first ID **0** maps to the article titled *The Mortality Rate of Coronavirus is Not Important*, and will not be used in any other records in this collection.\\\n\\\n# Cluster, Collection & Entities\n## Collection\n### Schema\nFields have their own properties, such as data types and related constraints for storing data in the field, like vector dimensions and distance metrics. By defining fields and their order, you will get a skeletal data structure termed schema, which shapes a collection in a way that resembles constructing the structure of a data table. \nFor your reference, Zilliz Cloud supports the following field data types: \n- Boolean value (BOOLEAN)\n- 8-byte floating-point (DOUBLE)\n- 4-byte floating-point (FLOAT)\n- Float vector (FLOAT_VECTOR)\n- 8-bit integer (INT8)\n- 32-bit integer (INT32)\n- 64-bit integer (INT64)\n- Variable character (VARCHAR)\n- [JSON](https://zilliverse.feishu.cn/wiki/H04VwNGoaimjcLkxoH4cs5TQnNd) \nZilliz Cloud provides three types of CUs, each of which have its own application scenarios, and they are also the factor that impacts search performance. \n> 📘 Notes\n>\n> **FLOAT_VECTOR** is the only data type that supports vector embeddings in Zilliz Cloud clusters."
}
],
"usage": {
"embedding": 24,
"rerank": 1437
}
}
}
文書データの削除
データを削除するには、まず削除パイプラインを作成してから実行する必要があります。
まず、Ingestionパイプラインを作成する必要があります。Ingestionパイプラインの作成に成功したら、検索パイプラインと削除パイプラインを作成して、新しく作成したIngestionパイプラインを操作できます。
文書削除パイプラインの作成
- Cloud Console
- Bash
-
プロジェクトに移動します。
-
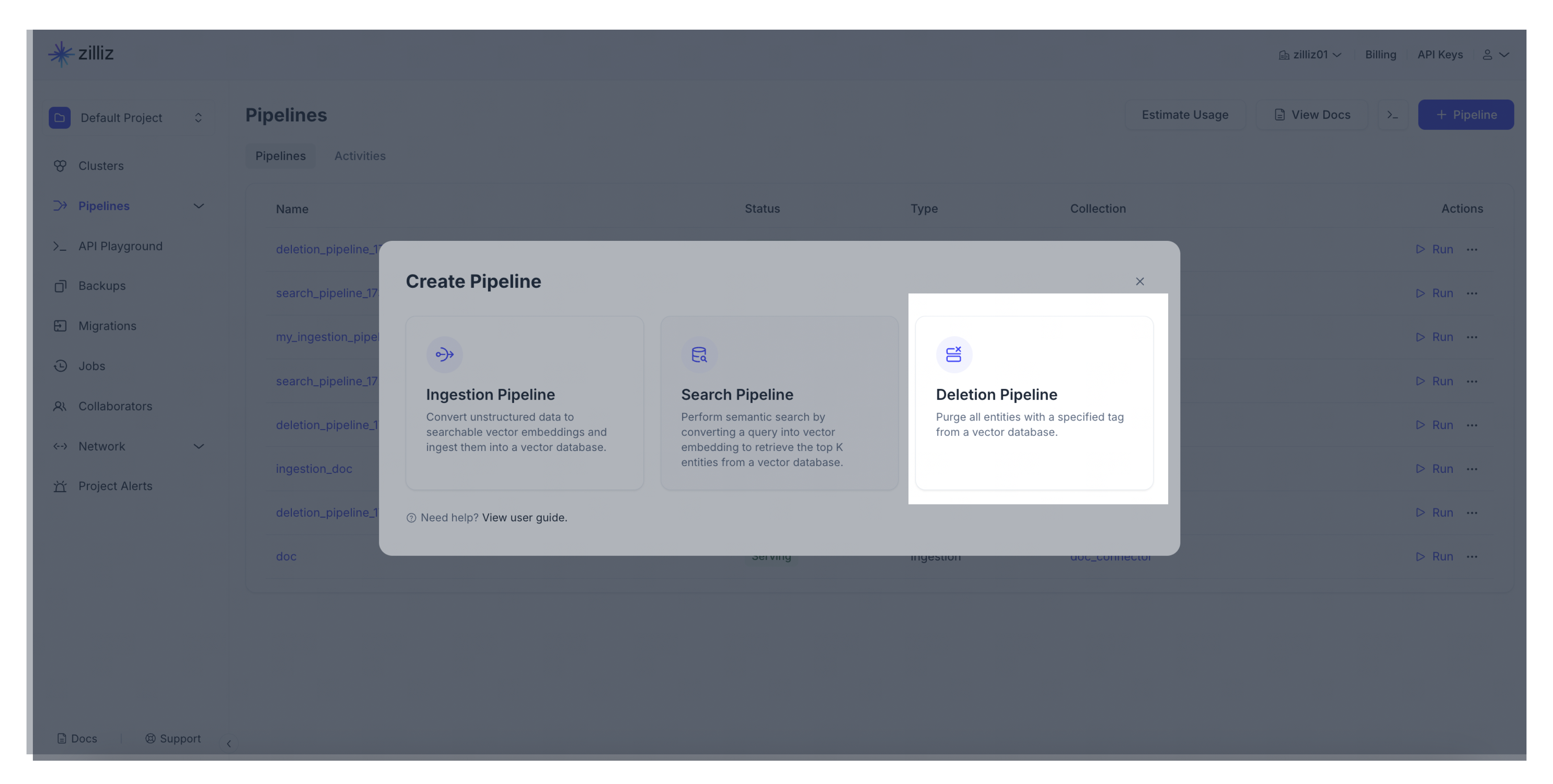
ナビゲーションパネルからパイプラインをクリックします。次に、概要タブに切り替えて、パイプラインをクリックします。パイプラインを作成するには、+パイプラインをクリックしてください。
-
作成するパイプラインの種類を選択してください。「+パイプライン」ボタンを削除パイプライン欄でクリックしてください。
-
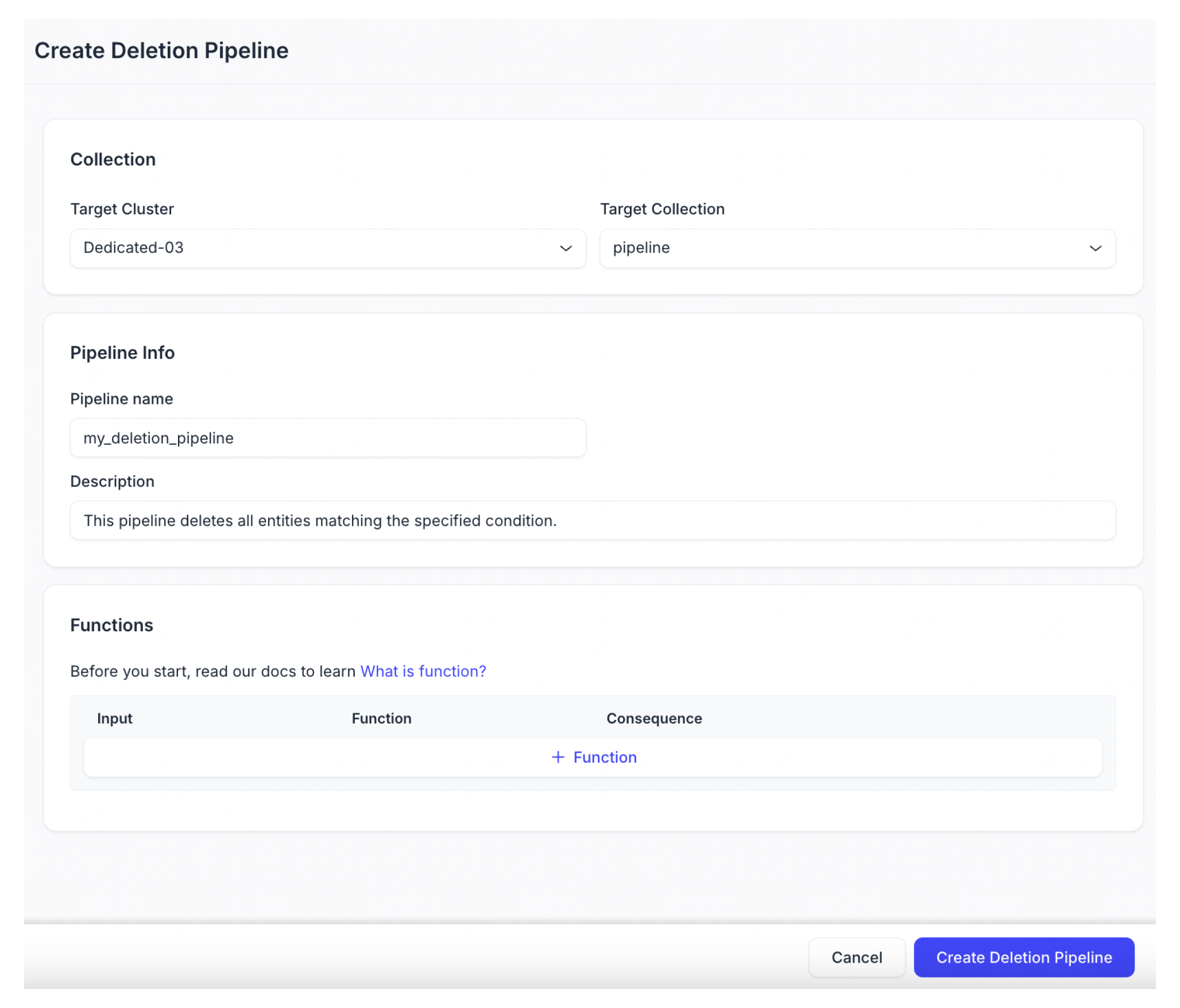
作成する削除パイプラインを構成します。
パラメータ
説明する
パイプライン名
新しい削除パイプラインの名前です。小文字、数字、アンダースコアのみを含める必要があります。
説明(オプション)
新しいDeletionパイプラインの説明。
-
「+Function」をクリックして、削除パイプラインに関数を追加します。1つの関数だけを追加できます。
-
関数名を入力します。
-
「PURGE_DOC_INDEX」または「PURGE_BY_EXPRESSION」を関数型として選択します。PURGE_DOC_INDEX関数は、指定されたdoc_nameを持つすべての文書チャンクを削除できます。PURGE_BY_EXPRESSION関数は、指定されたフィルタ式に一致するすべてのエンティティを削除できます。
-
[追加]をクリックして関数を保存します。
-
-
[削除パイプラインを作成]をクリックします。
以下の例では、my_doc_delete_Pipelineという名前のDeletionパイプラインを作成し、PURGE_DOC_INDEX関数を追加しています。
curl --request POST \
--header "Content-Type: application/json" \
--header "Authorization: Bearer ${YOUR_API_KEY}" \
--url "https://controller.api.{cloud-region}.zillizcloud.com/v1/pipelines" \
-d '{
"projectId": "proj-xxxx",
"name": "my_doc_deletion_pipeline",
"description": "A pipeline that deletes all info associated with a doc",
"type": "DELETION",
"functions": [
{
"name": "purge_chunks_by_doc_name",
"action": "PURGE_DOC_INDEX"
}
],
"clusterId": "inxx-xxxxxxxxxxxxxxx",
"collectionName": "my_collection"
}'
上記のコードのパラメータは次のように説明されています
-
YOUR_API_KEY: APIリクエストの認証に使用される資格情報。APIキーの表示方法については、こちらをご覧ください。 -
cloud-region:クラスターが存在するクラウドリージョンのID。現在、gcp-us-west 1のみがサポートされています。 -
projectId:パイプラインを作成するプロジェクトのID。詳しくはプロジェクトIDの取得方法をご覧ください。 -
name:作成するパイプラインの名前。パイプライン名は3~64文字の文字列で、英数字とアンダースコアのみを含めることができます。 -
description(オプション):作成するパイプラインの説明 -
type:作成するパイプラインの種類。現在利用可能なパイプラインの種類には、INGESTION、SEARCH、DELETIONがあります。 -
functions:パイプラインに追加する関数。Deletionパイプラインには1つの関数しか持てません。-
name:関数の名前です。関数名は3~64文字の文字列で、英数字とアンダースコアのみを含めることができます。 -
アクション:追加する関数の種類。利用可能なオプションには、PURGE_DOC_INDEX、PURGE_TEXT_INDEX、PURGE_BY_EXPRESSION、PURGE_IMAGE_INDEXがあります。
-
-
lusterId:パイプラインを作成するクラスタのIDです。現在、GCP us-west 1にデプロイされたクラスタのみを選択できます。詳しくはHow can I find my CLUSTER_ID? -
collectionName:パイプラインを作成するコレクションの名前。
以下は出力例です。
{
"code": 200,
"data": {
"pipelineId": "pipe-ab2874d8138c8554375bb0",
"name": "my_doc_deletion_pipeline",
"type": "DELETION",
"createTimestamp": 1721187655000,
"description": "A pipeline that deletes all info associated with a doc",
"status": "SERVING",
"functions": [
{
"action": "PURGE_DOC_INDEX",
"name": "purge_chunks_by_doc_name",
"inputField": "doc_name"
}
],
"clusterId": "in03-***************",
"collectionName": "my_collection"
}
}
文書削除パイプラインの実行
- Cloud Console
- Bash
-
削除パイプラインの横にある「▶︎」ボタンをクリックしてください。または、プレイグラウンドタブをクリックすることもできます。
-
[
doc_name]フィールドに削除するドキュメントの名前を入力します。[実行]をクリックします。 -
結果を確認してください。
次の例では、my_doc_deletion_Pipelineという名前のDeletionパイプラインを実行します。
curl --request POST \
--header "Content-Type: application/json" \
--header "Authorization: Bearer ${YOUR_API_KEY}" \
--url "https://controller.api.{cloud-region}.zillizcloud.com/v1/pipelines/${YOUR_PIPELINE_ID}/run" \
-d '{
"data": {
"doc_name": "zilliz_concept_doc.md",
}
}'
上記のコードのパラメータは次のように説明されています
-
YOUR_API_KEY: APIリクエストの認証に使用される資格情報。APIキーの表示方法については、こちらをご覧ください。 -
cloud-region:クラスターが存在するクラウドリージョンのID。現在、gcp-us-west 1のみがサポートされています。 -
doc_name:削除するドキュメントの名前。指定したdoc_nameを持つドキュメントが存在する場合、そのドキュメント内のすべてのチャンクが削除されます。doc_nameを持つドキュメントが存在しない場合でも、リクエストは実行できますが、出力のnum_deleted_chunksの値は0になります。
以下は回答例です。
{
"code": 200,
"data": {
"num_deleted_chunks": 567
}
}
パイプラインの管理
以下は、前述の手順で作成されたパイプラインを管理する関連する操作です。
ビューパイプライン
- Cloud Console
- Bash
左ナビゲーションのパイプラインをクリックします。パイプラインタブを選択します。利用可能なすべてのパイプラインが表示されます。
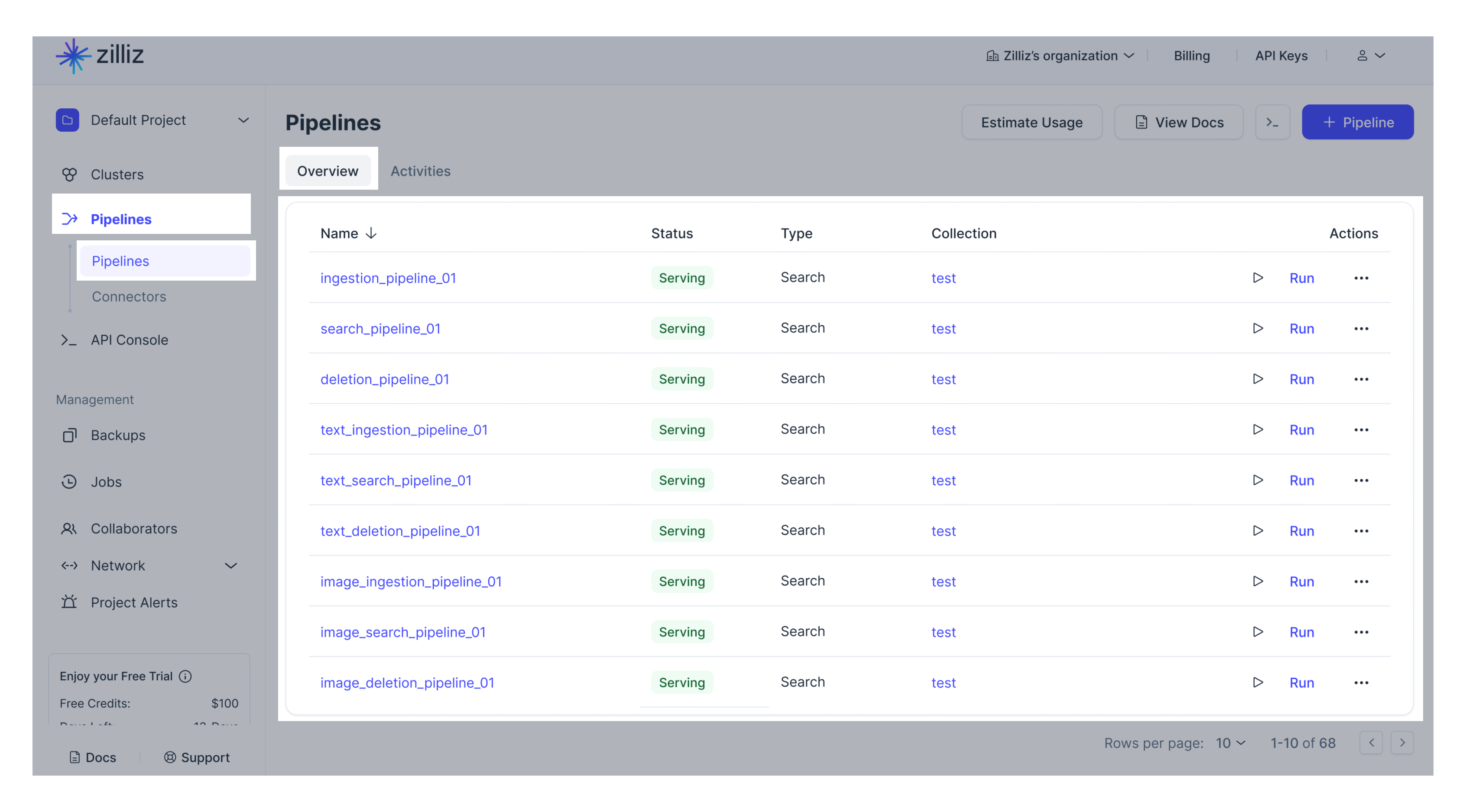
特定のパイプラインをクリックすると、基本情報、合計使用量、機能、関連コネクタなどの詳細情報が表示されます。
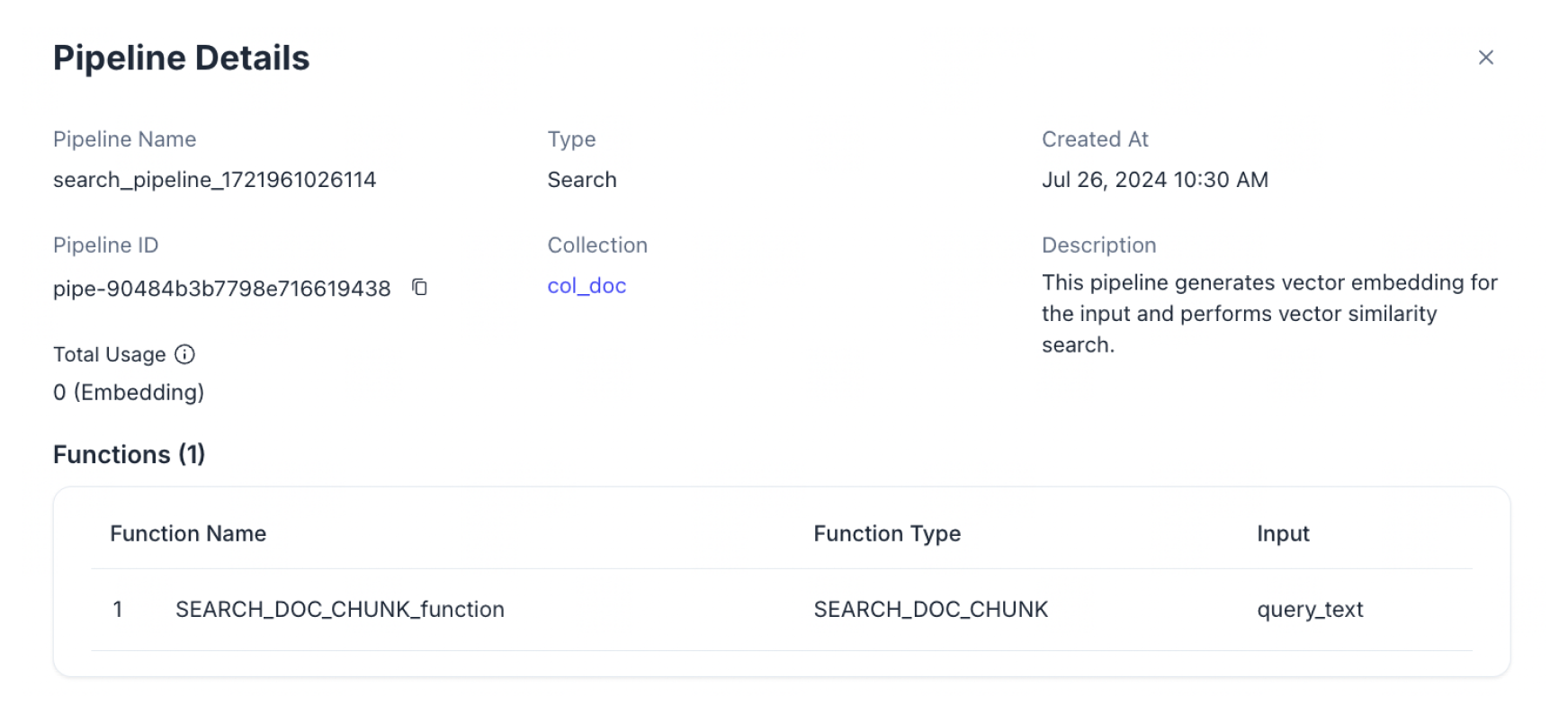
技術的な制限により、総使用データが数時間遅れる可能性があります。
Web UIでパイプラインのアクティビティを確認することもできます。
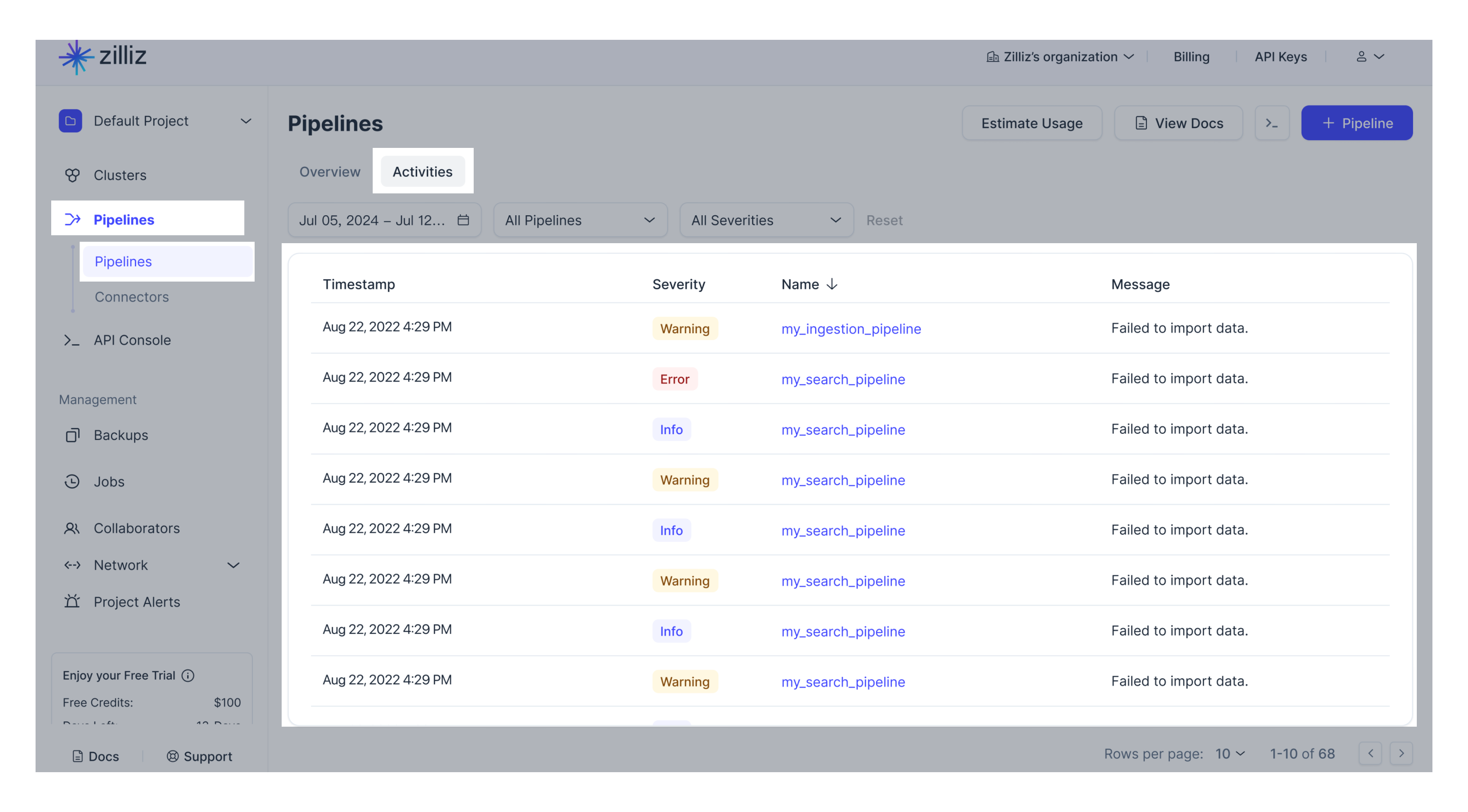
APIを呼び出して、既存のすべてのパイプラインを一覧表示したり、特定のパイプラインの詳細を表示したりできます。
-
既存のパイプラインをすべて表示する
以下の例に従い、projectIdを指定してくださ
い。プロジェクトIDの取得方法については、こちらをご覧ください。curl --request GET \
--header "Content-Type: application/json" \
--header "Authorization: Bearer ${YOUR_API_KEY}" \
--url "https://controller.api.{cloud-region}.zillizcloud.com/v1/pipelines?projectId=proj-xxxx"以下は出力例です。
{
"code": 200,
"data": [
{
"pipelineId": "pipe-xxxx",
"name": "my_text_ingestion_pipeline",
"type": "INGESTION",
"createTimestamp": 1721187655000,
"clusterId": "in03-***************",
"collectionName": "my_collection"
"description": "A pipeline that generates text embeddings and stores additional fields.",
"status": "SERVING",
"totalUsage": {
"embedding": 0
},
"functions": [
{
"action": "INDEX_TEXT",
"name": "index_my_text",
"inputFields": ["text_list"],
"language": "ENGLISH",
"embedding": "zilliz/bge-base-en-v1.5"
},
{
"action": "PRESERVE",
"name": "keep_text_info",
"inputField": "source",
"outputField": "source",
"fieldType": "VarChar"
}
]
},
{
"pipelineId": "pipe-xxxx",
"name": "my_text_search_pipeline",
"type": "SEARCH",
"createTimestamp": 1721187655000,
"description": "A pipeline that receives text and search for semantically similar texts",
"status": "SERVING",
"totalUsage": {
"embedding": 0,
"rerank": 0
},
"functions":
{
"action": "SEARCH_TEXT",
"name": "search_text",
"inputFields": "query_text",
"clusterId": "in03-***************",
"collectionName": "my_collection",
"embedding": "zilliz/bge-base-en-v1.5",
"reranker": "zilliz/bge-reranker-base"
}
},
{
"pipelineId": "pipe-xxxx",
"name": "my_text_deletion_pipeline",
"type": "DELETION",
"createTimestamp": 1721187655000,
"description": "A pipeline that deletes entities by expression",
"status": "SERVING",
"functions":
{
"action": "PURGE_BY_EXPRESSION",
"name": "purge_data_by_expression",
"inputFields": ["expression"]
},
"clusterId": "in03-***************",
"collectionName": "my_collection"
}
]
}📘ノート技術的な制限により、総使用データが数時間遅れる可能性があります。
-
特定のパイプラインの詳細を表示する
パイプラインの詳細を表示するには、以下の例に従ってください。
curl --request GET \
--header "Content-Type: application/json" \
--header "Authorization: Bearer ${YOUR_API_KEY}" \
--url "https://controller.api.{cloud-region}.zillizcloud.com/v1/pipelines/${YOUR_PIPELINE_ID}"以下は出力例です。
{
"code": 200,
"data": {
"pipelineId": "pipe-xxx",
"name": "my_text_ingestion_pipeline",
"type": "INGESTION",
"createTimestamp": 1721187300000,
"description": "A pipeline that generates text embeddings and stores additional fields.",
"status": "SERVING",
"totalUsage": {
"embedding": 0
},
"functions": [
{
"name": "index_my_text",
"action": "INDEX_TEXT",
"inputFields": ["text_list"],
"language": "ENGLISH",
"embedding": "zilliz/bge-base-en-v1.5"
},
{
"name": "keep_text_info",
"action": "PRESERVE",
"inputField": "source",
"outputField": "source",
"fieldType": "VarChar"
}
],
"clusterId": "inxx-xxxx",
"collectionName": "my_collection"
}
}📘ノート技術的な制限により、総使用データが数時間遅れる可能性があります。
パイプラインを削除
パイプラインが不要になった場合は、削除できます。パイプラインを削除しても、データを取り込んだ自動作成コレクションは削除されません。
ドロップしたパイプラインは回復できません。行動には注意してください。
Dropping a data-ingestion pipeline does not affect the collection created along with the pipeline. Your data is safe.
- Cloud Console
- Bash
To drop a pipeline on the web UI, click the ... button under the Actions column. Then click Drop.
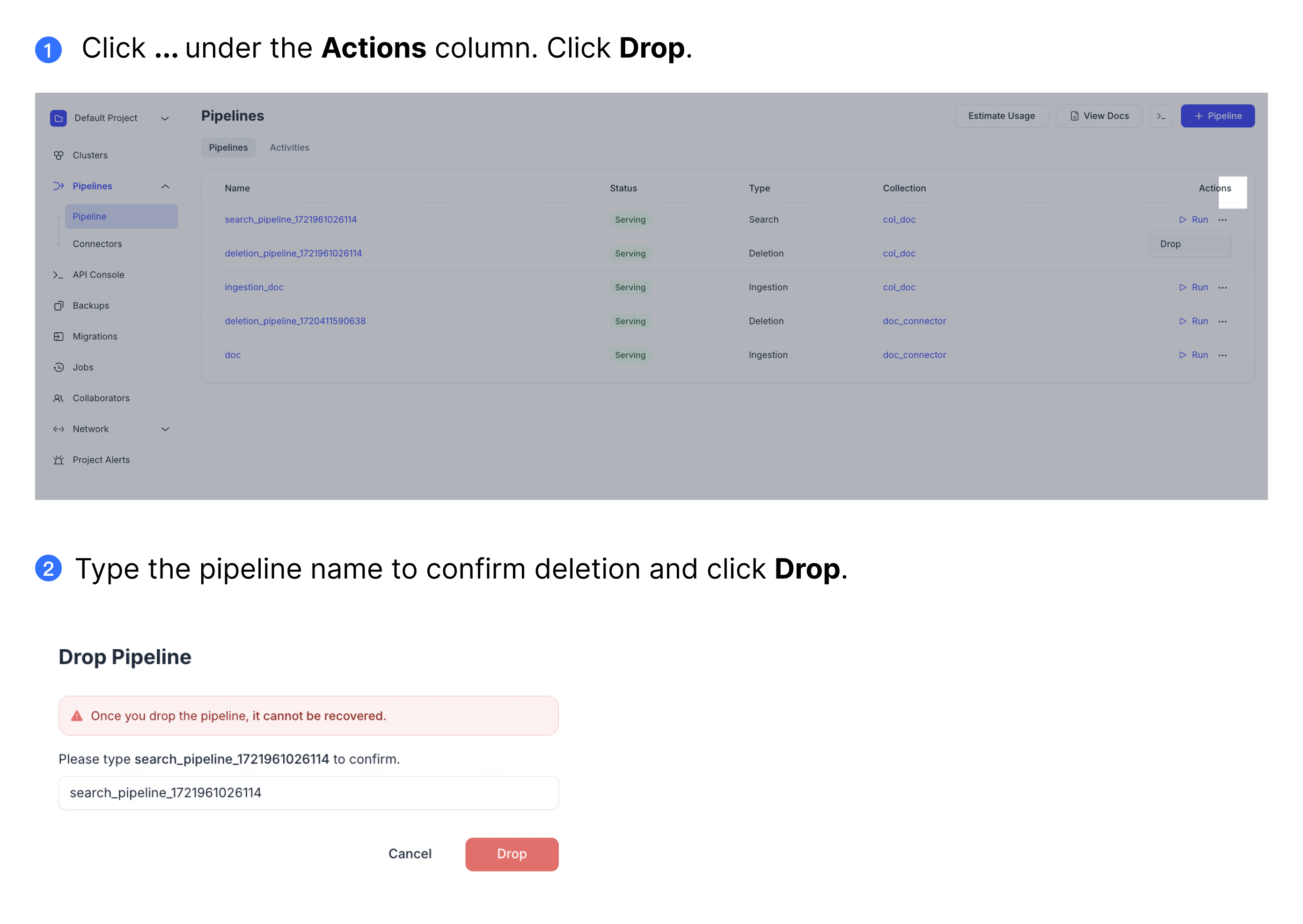
Follow the example below to drop a pipeline.
curl --request GET \
--header "Content-Type: application/json" \
--header "Authorization: Bearer ${YOUR_API_KEY}" \
--url "https://controller.api.{cloud-region}.zillizcloud.com/v1/pipelines/${YOUR_PIPELINE_ID}"
The following is an example output.
{
"code": 200,
"data": {
"pipelineId": "pipe-xxx",
"name": "my_text_ingestion_pipeline",
"type": "INGESTION",
"createTimestamp": 1721187300000,
"description": "A pipeline that generates text embeddings and stores additional fields.",
"status": "SERVING",
"totalUsage": {
"embedding": 0
},
"functions": [
{
"name": "index_my_text",
"action": "INDEX_TEXT",
"inputFields": ["text_list"],
"language": "ENGLISH",
"embedding": "zilliz/bge-base-en-v1.5"
},
{
"name": "keep_text_info",
"action": "PRESERVE",
"inputField": "source",
"outputField": "source",
"fieldType": "VarChar"
}
],
"clusterId": "inxx-xxxx",
"collectionName": "my_collection"
}
}
The total usage data could delay by a few hours due to technical limitation.