テキストデータAbout to Deprecate
Zilliz CloudのWeb UIは、パイプラインを作成、実行、管理するためのシンプルで直感的な方法を提供し、RESTful APIはWeb UIに比べてより柔軟性とカスタマイズ性を提供します。
このガイドでは、テキストパイプラインの作成、埋め込みテキストデータの意味検索の実行、パイプラインが不要になった場合の削除に必要な手順を説明します。
Zilliz Cloud Pipelinesは、2025年第2四半期の終わりまでに廃止され、「Data In, Data Out」という新しい機能に置き換えられます。これにより、MilvusとZilliz Cloudの両方で埋め込み生成が効率化されます。2024年12月24日現在、新規ユーザー登録は受け付けられていません。現在のユーザーは、日没日まで月額20ドルの無料手当内でサービスを継続して利用できますが、SLAは提供されていません。モデルプロバイダーまたはオープンソースモデルの埋め込みAPIを使用してベクトル埋め込みを生成することを検討してください。
前提条件と制限
-
Google Cloud Platform(GCP)上のus-west 1にデプロイされたクラスタを作成していることを確認してください。
-
一つのプロジェクトでは、同じタイプのパイプラインを最大100個まで作成できます。詳細については、Zillizクラウドの制限を参照してください。
テキストデータを取り込む
データを取り込むには、まず取り込みパイプラインを作成してから実行する必要があります。
テキスト取り込みパイプラインの作成
- Cloud Console
- Bash
-
プロジェクトに移動します。
-
ナビゲーションパネルからパイプラインをクリックします。次に、概要タブに切り替えて、パイプラインをクリックします。パイプラインを作成するには、+パイプラインをクリックしてください。
-
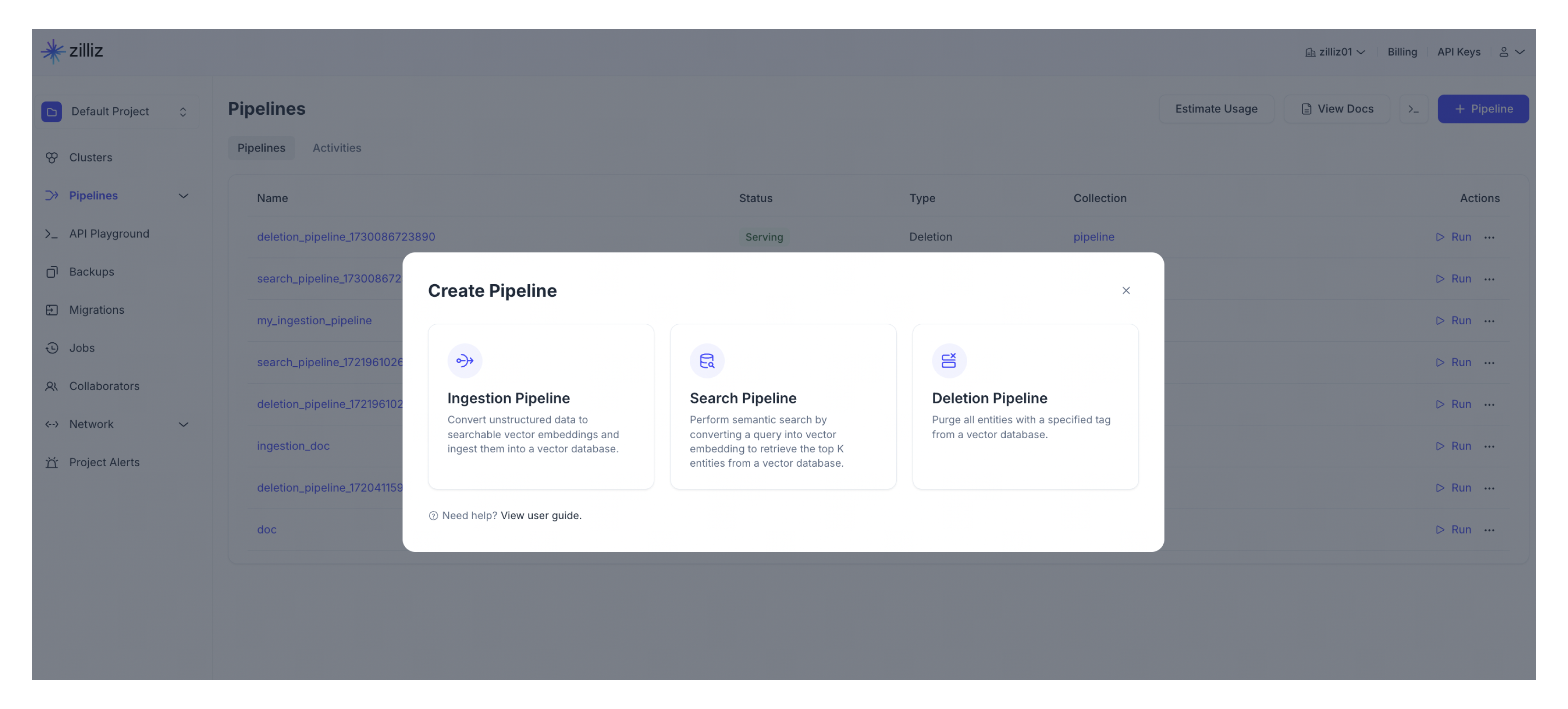
作成するパイプラインの種類を選択します。[+パイプライン]ボタンをクリックします。Ingestion Pipeline列。
-
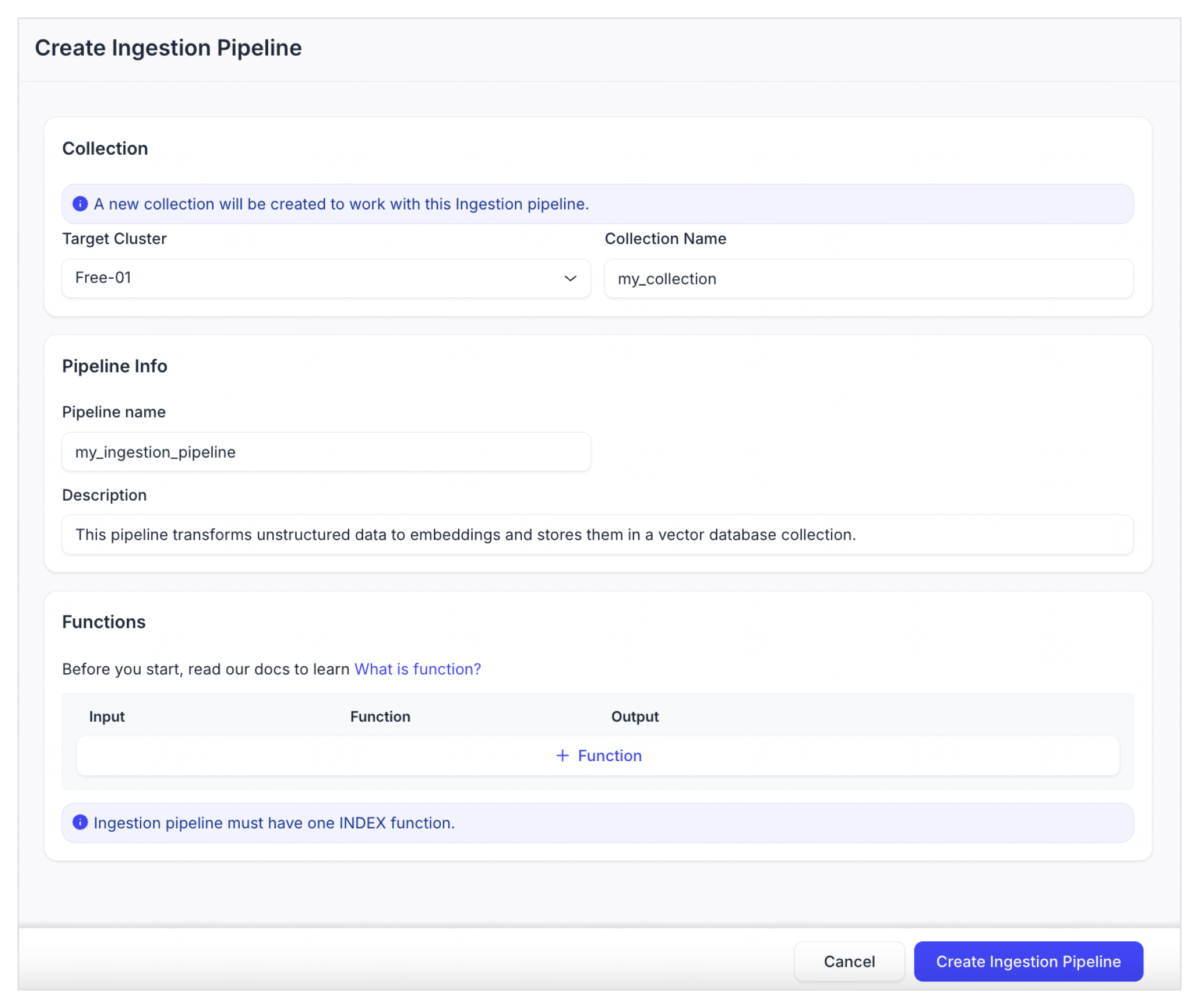
作成するIngestionパイプラインを構成します。
パラメータ
説明する
ターゲットクラスタ
このIngestionパイプラインを使用して新しいコレクションが自動的に作成されるクラスタです。現時点では、GCP us-west 1にデプロイされたクラスタのみとなります。
コレクション名
自動作成されたコレクションの名前。
パイプライン名
新しいIngestionパイプラインの名前です。小文字、数字、アンダースコアのみを含める必要があります。
説明(オプション)
新しいIngestionパイプラインの説明。
-
IngestionパイプラインにINDEX関数を追加するには、+Functionをクリックします。各Ingestionパイプラインに対して、正確に1つのINDEX関数を追加できます。
-
関数名を入力します。
-
関数タイプとしてINDEX_TEXTを選択します。INDEX_TEXT関数は、提供されたすべてのテキスト入力に対してベクトル埋め込みを生成できます。
-
ベクトル埋め込みを生成するために使用する埋め込みモデルを選択します。異なるテキスト言語には異なる埋め込みモデルがあります。現在、英語には5つの利用可能なモデルがあります:zilliz/bge-base-en-v 1.5、voyageai/voyage-2、voyageai/voyage-code-2、openai/text-embedding-3-small、およびopenai/text-embedding-3-large。中国語には、zilliz/bge-base-zh-v 1.5のみが利用可能です。以下の表は、各埋め込みモデルを簡単に紹介しています。
埋め込みモデル
説明する
zilliz/bge-based-en-v 1.5-ダウンロード
BAAIによってリリースされたこの最先端のオープンソースモデルは、Zilliz Cloudにホストされ、ベクトルデータベースと共有されており、高品質で最高のネットワークレイテンシを提供しています。
Voyage AIによってホストされています。この汎用モデルは、説明的なテキストとコードを含む技術文書の取得に優れています。軽量版はvoyage-lite-02-instructMTEBリーダーボードでトップにランクされています。このモデルは、
言語が英語の場合にのみ利用可能です。Voyage AIがホストしています。このモデルはソフトウェアコードに最適化されており、ソフトウェアドキュメントとソースコードを取得するための優れた品質を提供します。このモデルは、
言語が英語の場合にのみ利用可能です。Voyage AIによってホストされています。これはVoyage AIからの最も強力な汎用埋め込みモデルです。16 kのコンテキスト長(voyage-2の4倍)をサポートし、技術的および長いコンテキスト文書を含むさまざまなタイプのテキストに優れています。このモデルは、
言語が英語の場合にのみ利用可能です。Open AIによってホストされています。この非常に効率的な埋め込みモデルは、先行モデルよりも強力なパフォーマンスを持ちtext-embedding-ada-002推論コストと品質をバランスさせています。このモデルは、
言語が英語の場合にのみ利用可能です。Open AIがホストしています。これはOpen AIの最高のパフォーマンスモデルです。text-embedding-ada-002と比較して、MTEBスコアは61.0%から64.6%に増加しました。このモデルは、
言語が英語の場合にのみ利用可能です。zilliz/bge-base-zh-v 1.5-ダウンロード
BAAIによってリリースされたこの最先端のオープンソースモデルは、Zilliz Cloudにホストされ、ベクトルデータベースと共同配置されており、高品質で最高のネットワークレイテンシを提供します。これは、
言語が中国語の場合のデフォルトの埋め込みモデルです。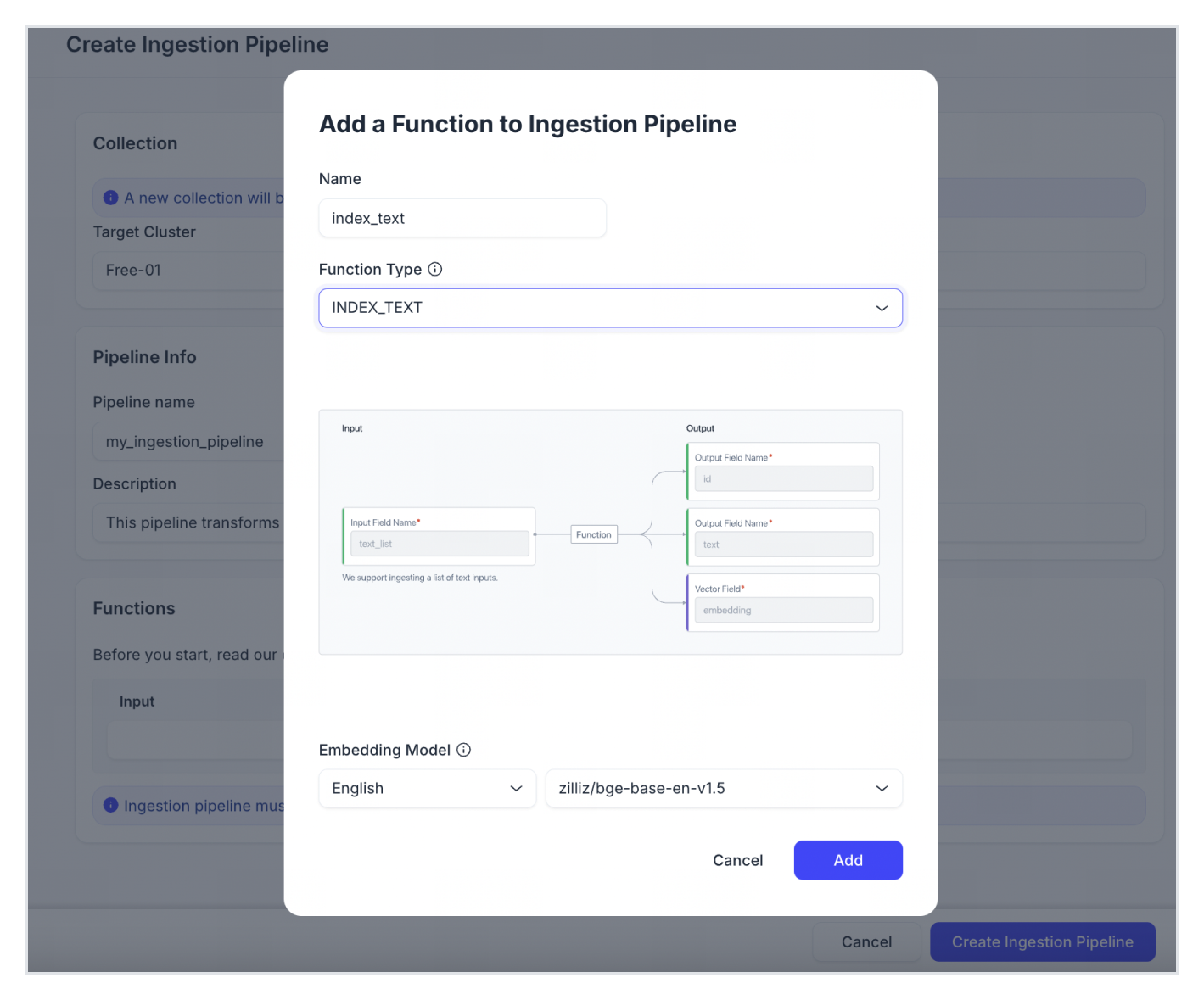
-
[追加]をクリックして関数を保存します。
-
-
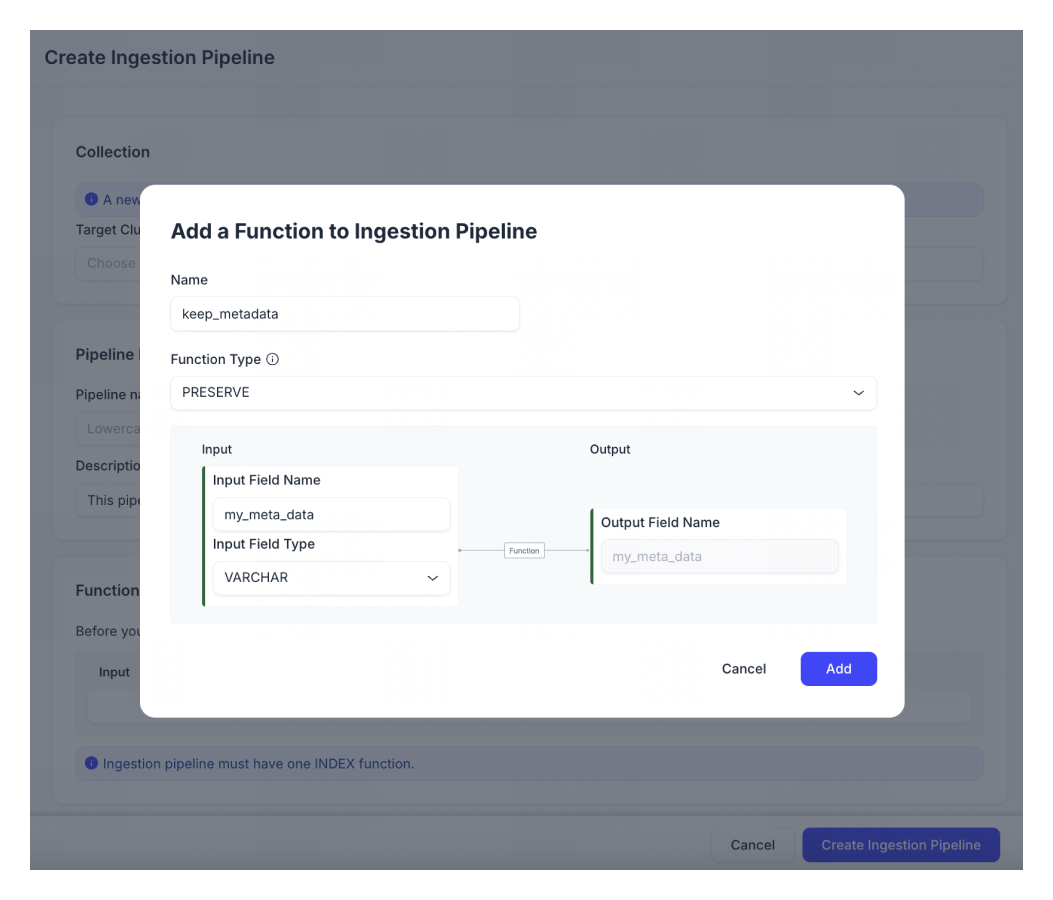
(オプション)テキストのメタデータを保持する必要がある場合は、別のPRESERVE関数を追加してください。PRESERVE関数は、データ取り込みとともにコレクションにスカラーフィールドを追加します。
📘ノート各Ingestionパイプラインについて、最大50個のPRESERVE関数を追加できます。
-
[+Function]をクリックします。
-
関数名を入力します。
-
入力フィールドの名前と種類を設定します。サポートされている入力フィールドの種類は、Bool、Int 8、Int 16、Int 32、Int 64、Float、Double、VarCharです。
📘ノート現在、出力フィールド名は入力フィールド名と同じでなければなりません。入力フィールド名は、Ingestionパイプラインを実行する際に使用されるフィールド名を定義します。出力フィールド名は、保存された値が保持されるベクトルコレクションスキーマ内のフィールド名を定義します。
VarCharフィールドの場合、値は最大4,000文字の英数字の文字列である必要があります。
スカラーフィールドに日時を格納する場合は、年データにはInt 16データ型、タイムスタンプにはInt 32データ型を使用することをお勧めします。
-
[追加]をクリックして関数を保存します。
-
-
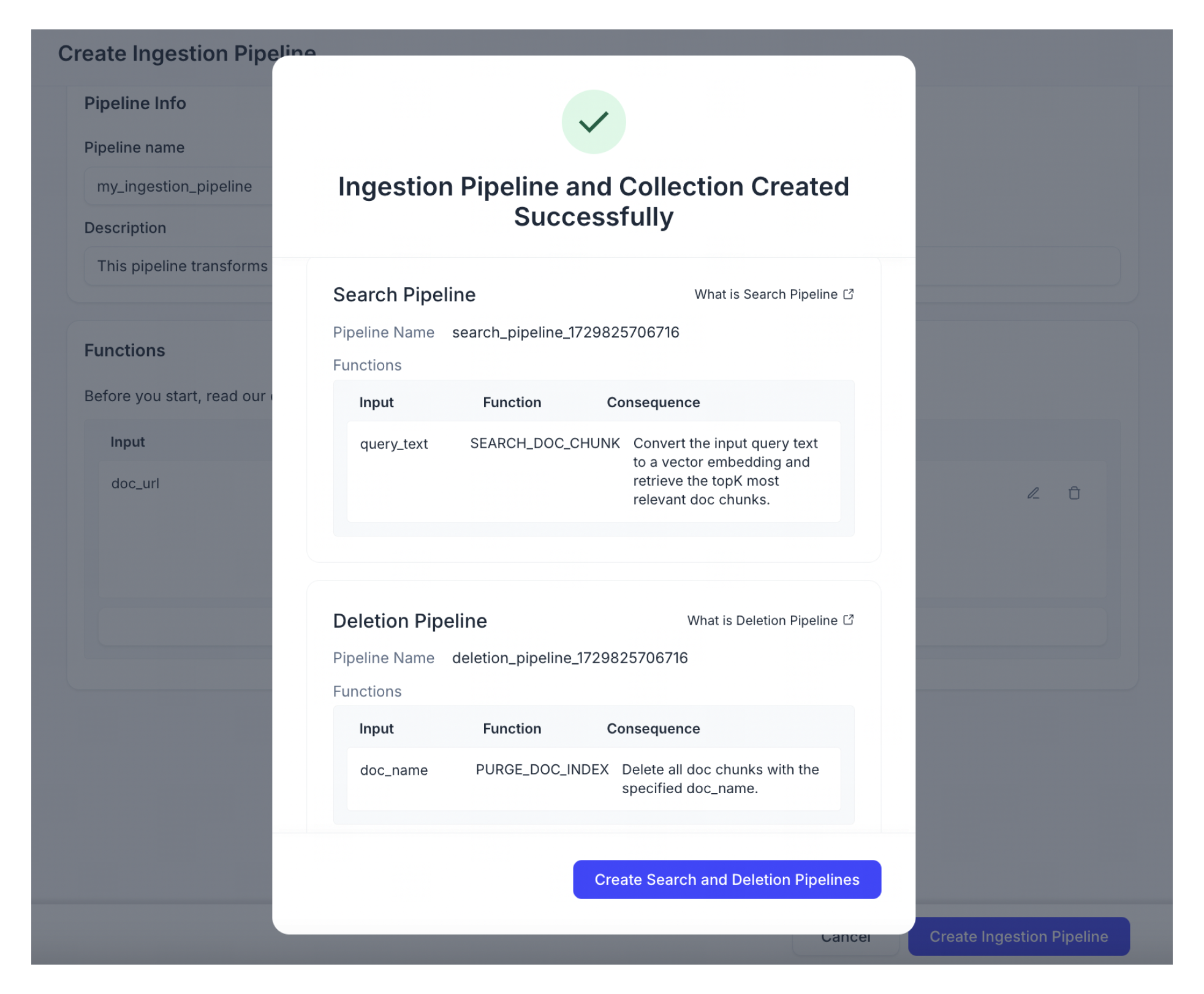
[Ingestion Pipelineを作成]をクリックします。
-
作成したばかりのIngestionパイプラインと互換性があるように自動構成された検索パイプラインと削除パイプラインの作成を続けます。
 📘ノート
📘ノートデフォルトでは、自動設定された検索パイプラインでreranker機能は無効になっています。rerankerを有効にする必要がある場合は、手動で新しい検索パイプラインを作成してください。
次の例では、という名前のIngestionパイプラインを作成しますmy_text_ingestion_パイプライン、INDEX_TEXT関数とPRESERVE関数を追加します。
curl --request POST \
--header "Content-Type: application/json" \
--header "Authorization: Bearer ${YOUR_API_KEY}" \
--url "https://controller.api.{cloud-region}.zillizcloud.com/v1/pipelines" \
-d '{
"name": "my_text_ingestion_pipeline",
"clusterId": "inxx-xxxxxxxxxxxxxxx",
"projectId": "proj-xxxx",
"collectionName": "my_collection",
"description": "A pipeline that generates text embeddings and stores additional fields.",
"type": "INGESTION",
"functions": [
{
"name": "index_my_text",
"action": "INDEX_TEXT",
"language": "ENGLISH",
"embedding": "zilliz/bge-base-en-v1.5"
},
{
"name": "keep_text_info",
"action": "PRESERVE",
"inputField": "source",
"outputField": "source",
"fieldType": "VarChar"
}
]
}'
上記のコードのパラメータは次のように説明されています
-
YOUR_API_KEY: APIリクエストの認証に使用される資格情報。APIキーの表示方法については、こちらをご覧ください。 -
cloud-region:クラスターが存在するクラウドリージョンのID。現在、gcp-us-west 1のみがサポートされています。 -
lusterId:パイプラインを作成するクラスタのIDです。現在、GCP上のus-west 1にデプロイされたクラスタのみを選択できます。CLUSTER_IDの確認方法については、How can I find my CLUSTER_ID?を参照してください。 -
projectId:パイプラインを作成するプロジェクトのID。詳しくはプロジェクトIDの取得方法をご覧ください。 -
lectionName:作成するインジェストパイプラインで自動的に生成されるコレクションの名前です。また、既存のコレクションを指定することもできます。 -
name:作成するパイプラインの名前。パイプライン名は3~64文字の文字列で、英数字とアンダースコアのみを含めることができます。 -
description(オプション):作成するパイプラインの説明。 -
type:作成するパイプラインの種類。現在利用可能なパイプラインの種類には、INGESTION、SEARCH、DELETIONがあります。 -
functions:パイプラインに追加する関数。Ingestionパイプラインには、1つのINDEX関数と最大50個のPRESERVE関数しか持てません。-
name:関数の名前です。関数名は3~64文字の文字列で、英数字とアンダースコアのみを含めることができます。 -
action:追加する関数の種類。現在利用可能なオプションには、INDEX_DOC、INDEX_TEXT、INDEX_IMAGE、PRESERVEがあります。 -
language:取り込むテキストの言語。使用可能な値はENGLISHとCHINESEです。(このパラメータはINDEX_TEXTとINDEX_DOC_CHUNK関数でのみ使用されます。) -
埋め込み:テキストのベクトル埋め込みを生成するために使用する埋め込みモデルです。利用可能なオプションは以下の通りです。(このパラメータはIn dex関数でのみ使用されます。)埋め込みモデル
説明する
zilliz/bge-based-en-v 1.5-ダウンロード
BAAIによってリリースされたこの最先端のオープンソースモデルは、Zilliz Cloudにホストされ、ベクトルデータベースと共有されており、高品質で最高のネットワークレイテンシを提供しています。
Voyage AIによってホストされています。この汎用モデルは、説明的なテキストとコードを含む技術文書の取得に優れています。軽量版はvoyage-lite-02-instructMTEBリーダーボードでトップにランクされています。このモデルは、
言語が英語の場合にのみ利用可能です。Voyage AIがホストしています。このモデルはプログラミングコードに最適化されており、検索コードブロックに優れた品質を提供します。このモデルは、
言語が英語の場合にのみ利用可能です。Voyage AIによってホストされています。これはVoyage AIからの最も強力な汎用埋め込みモデルです。16 kのコンテキスト長(voyage-2の4倍)をサポートし、技術的および長いコンテキスト文書を含むさまざまなタイプのテキストに優れています。このモデルは、
言語が英語の場合にのみ利用可能です。Open AIによってホストされています。この非常に効率的な埋め込みモデルは、先行モデルよりも強力なパフォーマンスを持ちtext-embedding-ada-002推論コストと品質をバランスさせています。このモデルは、
言語が英語の場合にのみ利用可能です。Open AIがホストしています。これはOpen AIの最高のパフォーマンスモデルです。text-embedding-ada-002と比較して、MTEBスコアは61.0%から64.6%に増加しました。このモデルは、
言語が英語の場合にのみ利用可能です。zilliz/bge-base-zh-v 1.5-ダウンロード
BAAIによってリリースされたこの最先端のオープンソースモデルは、Zilliz Cloudにホストされ、ベクトルデータベースと共同配置されており、高品質で最高のネットワークレイテンシを提供します。これは、
言語が中国語の場合のデフォルトの埋め込みモデルです。
-
-
input tField:inputフィールドの名前です。値はカスタマイズできますが、output tFieldと同じにしてください。(このパラメータはPRESERVE関数でのみ使用されます。) -
outputField:コレクションスキーマで使用される出力フィールドの名前。現在、出力フィールドの名前は入力フィールドの名前と同じでなければなりません。(このパラメータはPRESERVE関数でのみ使用されます。) -
fieldType:入力フィールドと出力フィールドのデータ型です。使用可能な値は、Bool、Int 8、Int 16、Int 32、Int 64、Float、Double、およびVarCharです。(このパラメータはPRESERVE関数でのみ使用されます。)📘ノートスカラーフィールドに日時を格納する場合は、年データにはInt 16データ型、タイムスタンプにはInt 32データ型を使用することをお勧めします。
VarCharフィールド
型の場合、このフィールドのデータのmax_lengthは4,000を超えることはできません。
以下は出力例です。
{
"code": 200,
"data": {
"pipelineId": "pipe-xxx",
"name": "my_text_ingestion_pipeline",
"type": "INGESTION",
"createTimestamp": 1721187300000,
"description": "A pipeline that generates text embeddings and stores additional fields.",
"status": "SERVING",
"totalUsage": {
"embedding": 0
},
"functions": [
{
"name": "index_my_text",
"action": "INDEX_TEXT",
"inputFields": ["text_list"],
"language": "ENGLISH",
"embedding": "zilliz/bge-base-en-v1.5"
},
{
"name": "keep_text_info",
"action": "PRESERVE",
"inputField": "source",
"outputField": "source",
"fieldType": "VarChar"
}
],
"clusterId": "inxx-xxxx",
"collectionName": "my_collection"
}
}
技術的な制限により、総使用データが数時間遅れる可能性があります。
クラスタに存在しない場合、my_collectionという名前のコレクションが自動的に作成されます。しかし、存在する場合、Zililz Cloud Pipelinesはコレクションスキーマがパイプラインで定義されたスキーマと一致しているかどうかをチェックします。
このコレクションには、INDEX_TEXT関数の出力フィールドが3つ、PRESERVE関数ごとに1つの出力フィールドが含まれています。コレクションのスキーマは以下の通りです。
id (データ型: Int 64) | テキスト (データ型: VarChar) | 埋め込み (データ型: FLOAT_VECTOR) | ソース (データ型: VarChar) |
|---|
テキスト取り込みパイプラインを実行する
- Cloud Console
- Bash
-
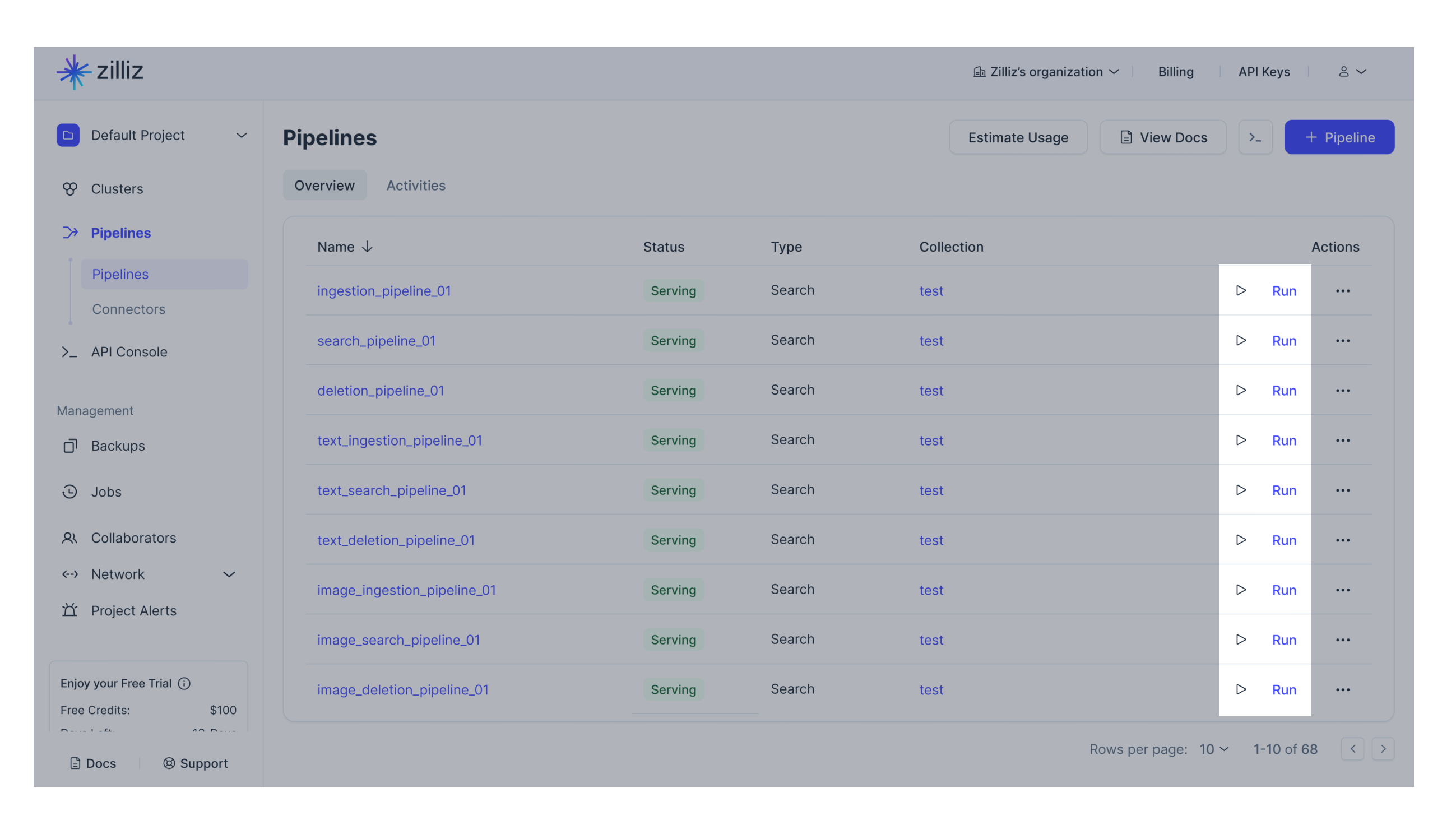
Ingestionパイプラインの横にある「▶︎」ボタンをクリックしてください。
-
text_listフィールドに取り込む必要のあるテキストまたは
テキストリストを入力します。PRESERVE関数を追加した場合は、定義済みの保存フィールドにも値を入力します。[実行]をクリックします。 -
結果を確認してください。
-
再度実行する他のテキストを入力します。
次の例では、Ingestionパイプラインmy_text_ingestion_Pipelineを実行します。sourceは、保持する必要のあるメタデータフィールドです。
curl --request POST \
--header "Content-Type: application/json" \
--header "Authorization: Bearer ${YOUR_API_KEY}" \
--url "https://controller.api.{cloud-region}.zillizcloud.com/v1/pipelines/${YOUR_PIPELINE_ID}/run" \
-d '{
"data": {
"text_list": [
"Zilliz Cloud is a fully managed vector database and data services, empowering you to unlock the full potential of unstructured data for your AI applications.",
"It can store, index, and manage massive embedding vectors generated by deep neural networks and other machine learning (ML) models."
],
"source": "Zilliz official website"
}
}'
上記のコードのパラメータは次のように説明されています
-
YOUR_API_KEY: APIリクエストの認証に使用される資格情報。APIキーの表示方法については、こちらをご覧ください。 -
cloud-region:クラスターが存在するクラウドリージョンのID。現在、gcp-us-west 1のみがサポートされています。 -
text_list:取り込むテキストまたはテキストリスト。 -
source(オプション):保存するメタデータフィールド。入力フィールド名は、Ingestionパイプラインを作成し、PRESERVE関数を追加したときに定義したものと一致する必要があります。このフィールドの値は、定義済みのフィールドタイプに従う必要があります。
以下は回答例です。
{
"code": 200,
"data": {
"num_entities": 2,
"usage": {
"embedding": 63
},
"ids": [
450524927755105948,
450524927755105949
]
}
}
テキストデータを検索する
任意のデータを検索するには、まず検索パイプラインを作成してから実行する必要があります。IngestionおよびDeletionパイプラインとは異なり、検索パイプラインを作成する場合、クラスタとコレクションはパイプラインレベルではなく関数レベルで定義されます。これは、Zilliz Cloudが複数のコレクションから同時に検索できるためです。
テキスト検索パイプラインの作成
- Cloud Console
- Bash
-
プロジェクトに移動します。
-
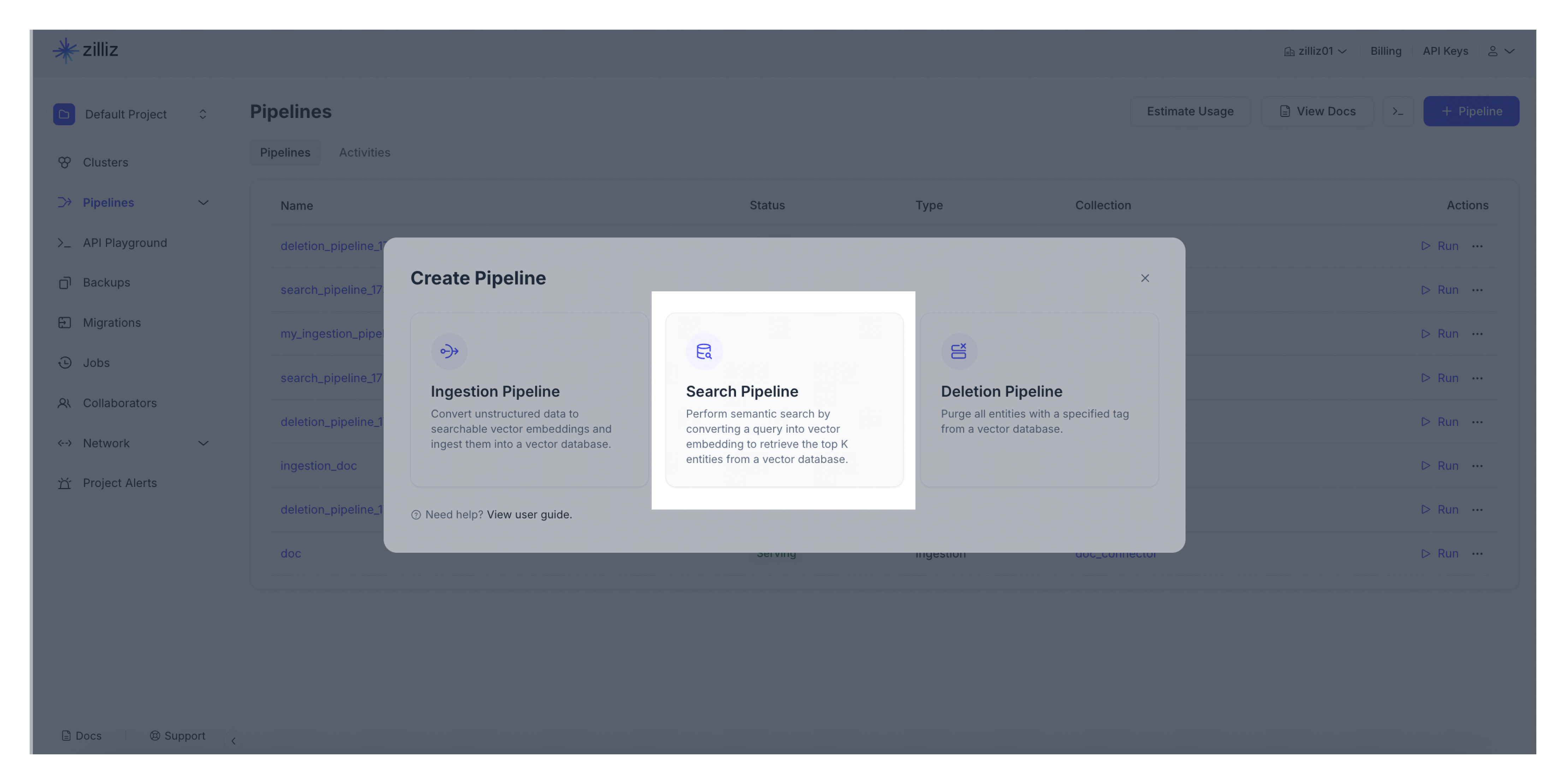
ナビゲーションパネルからパイプラインをクリックします。次に、概要タブに切り替えて、パイプラインをクリックします。パイプラインを作成するには、+パイプラインをクリックしてください。
-
作成するパイプラインの種類を選択してください。「+パイプライン」ボタンを検索パイプライン欄でクリックしてください。
-
作成したい検索パイプラインを構成します。
パラメータ
説明する
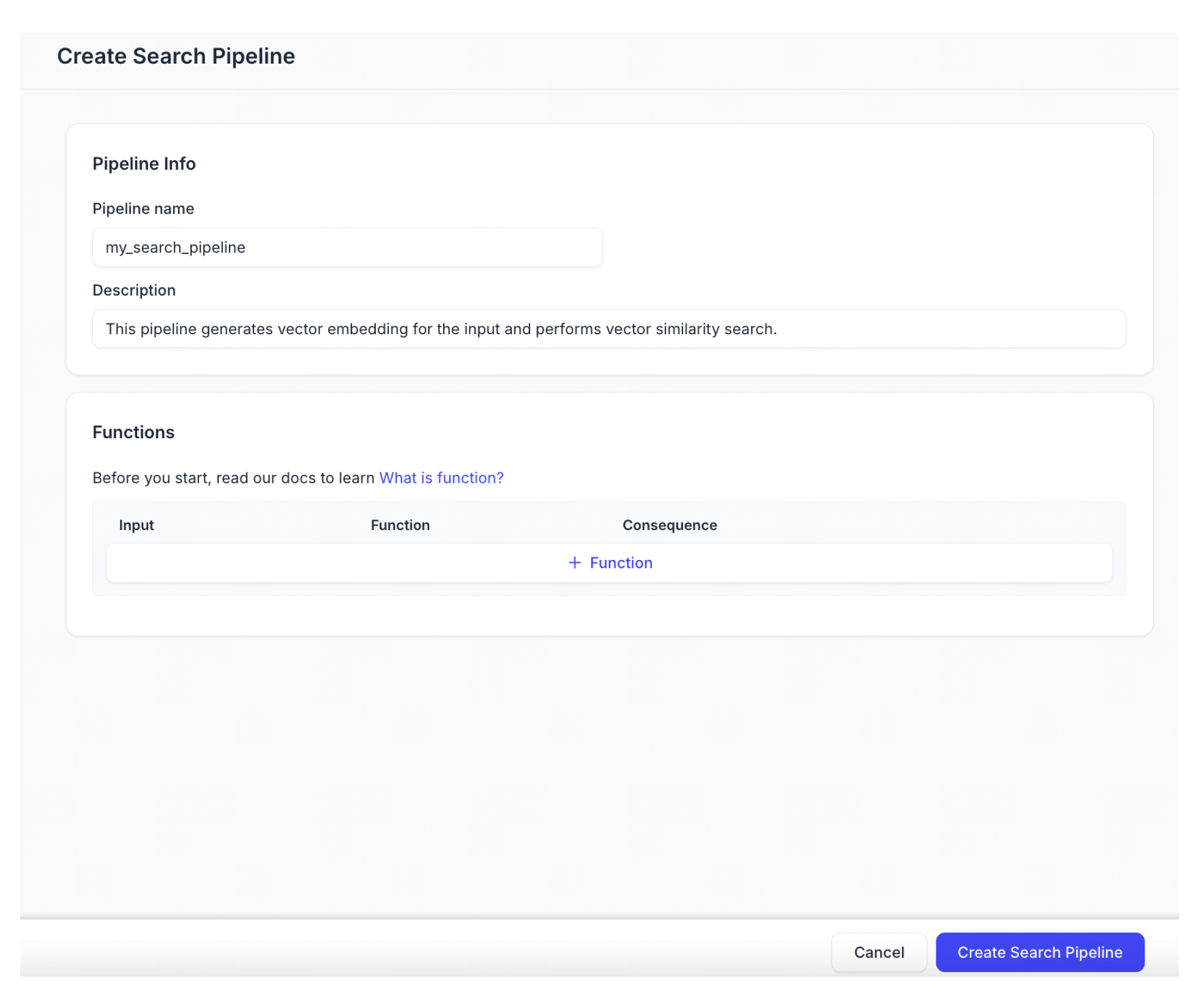
パイプライン名
新しい検索パイプラインの名前です。小文字、数字、アンダースコアのみを含める必要があります。
説明(オプション)
新しい検索パイプラインの説明。
-
「+Function」をクリックして、検索パイプラインに関数を追加します。正確に1つの関数を追加できます。
-
関数名を入力します。
-
「Target Cluster」と「Target collection」を選択します。Target Clusterは、**us-west 1 on Google Cloud Platform(GCP)**にデプロイされたクラスタである必要があります。また、Target CollectionはIngestionパイプラインによって作成されている必要があります。そうでない場合、Searchパイプラインは互換性がありません。
-
[SEARCH_TEXT]を関数タイプとして選択します。SEARCH_TEXT関数は、クエリテキストをベクトル埋め込みに変換し、最も関連性の高いテキストエンティティを取得できます。
-
(オプション)rerankerを有効にすると、クエリとの関連性に基づいて検索結果をランク付けして検索品質を向上させることができます。ただし、rerankerを有効にすると、コストと検索レイテンシが高くなることに注意してください。デフォルトでは、この機能は無効になっています。有効にすると、再ランキングに使用するモデルサービスを選択できます。現在、zilliz/bge-reranker-baseのみが利用可能です。
リランカーモデルサービス
説明する
zilliz/bge-reranker-base-ダウンロード
オープンソースのクロスエンコーダアーキテクチャの再ランクモデルはBAAIによって公開されています。このモデルはZilliz Cloudにホストされています。
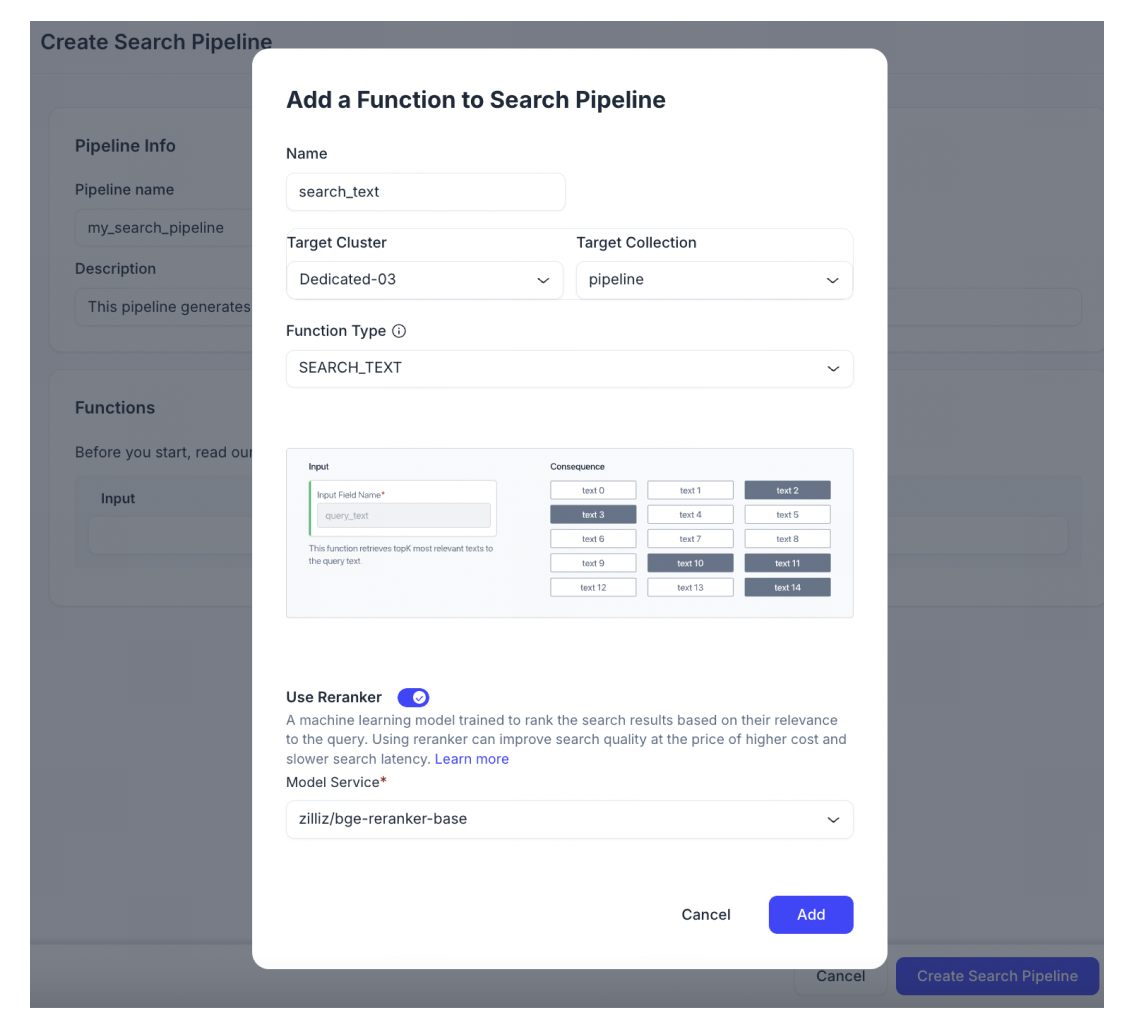
-
[追加]をクリックして関数を保存します。
-
-
[検索パイプラインを作成]をクリックします。
次の例では、my_text_search_Pipelineという名前の検索パイプラインを作成し、SEARCH_TEXT関数を追加します。
curl --request POST \
--header "Content-Type: application/json" \
--header "Authorization: Bearer ${YOUR_API_KEY}" \
--url "https://controller.api.{cloud-region}.zillizcloud.com/v1/pipelines" \
-d '{
"projectId": "proj-xxxx",
"name": "my_text_search_pipeline",
"description": "A pipeline that receives text and search for semantically similar texts",
"type": "SEARCH",
"functions": [
{
"name": "search_text",
"action": "SEARCH_TEXT",
"clusterId": "inxx-xxxxxxxxxxxxxxx",
"collectionName": "my_collection",
"embedding": "zilliz/bge-base-en-v1.5",
"reranker": "zilliz/bge-reranker-base"
}
]
}'
上記のコードのパラメータは次のように説明されています
-
YOUR_API_KEY: APIリクエストの認証に使用される資格情報。APIキーの表示方法については、こちらをご覧ください。 -
cloud-region:クラスターが存在するクラウドリージョンのID。現在、gcp-us-west 1のみがサポートされています。 -
projectId:パイプラインを作成するプロジェクトのID。詳しくはプロジェクトIDの取得方法をご覧ください。 -
name:作成するパイプラインの名前。パイプライン名は3~64文字の文字列で、英数字とアンダースコアのみを含めることができます。 -
description(オプション):作成するパイプラインの説明。 -
type:作成するパイプラインの種類。現在利用可能なパイプラインの種類には、INGESTION、SEARCH、DELETIONがあります。 -
functions:パイプラインに追加する関数。Searchパイプラインには1つの関数しか持てません。-
name:関数の名前です。関数名は3~64文字の文字列で、英数字とアンダースコアのみを含めることができます。 -
action:追加する関数の種類。現在利用可能なオプションは、SEARCH_DOC_CHUNK、SEARCH_TEXT、SEARCH_IMAGE_BY_IMAGE、SEARCH_IMAGE_BY_TEXTです。 -
lusterId:パイプラインを作成するクラスタのIDです。現在、GCP上のus-west 1にデプロイされたクラスタのみを選択できます。CLUSTER_IDの確認方法については、How can I find my CLUSTER_ID?を参照してください。 -
collectionName:パイプラインを作成するコレクションの名前。 -
埋め込み:ベクトル検索中に使用される埋め込みモデル。モデルは、互換性のあるコレクションで選択されたものと一致する必要があります。 -
reranker(オプション):検索結果の品質を向上させるために、一連の候補出力を並べ替えたりランク付けしたりするためのオプションのパラメータです。rerankerが必要ない場合は、このパラメータを省略できます。現在、パラメータ値としてzilliz/bge-reranker-baseのみが利用可能です。
-
以下は出力例です。
{
"code": 200,
"data": {
"pipelineId": "pipe-xxxx",
"name": "my_text_search_pipeline",
"type": "SEARCH",
"createTimestamp": 1721187655000,
"description": "A pipeline that receives text and search for semantically similar texts",
"status": "SERVING",
"totalUsage": {
"embedding": 0,
"rerank": 0
},
"functions": [
{
"name": "search_text",
"action": "SEARCH_TEXT",
"inputFields": [
"query_text"
],
"clusterId": "inxx-xxxx",
"collectionName": "my_collection",
"reranker": "zilliz/bge-reranker-base",
"embedding": "zilliz/bge-base-en-v1.5"
}
]
}
}
技術的な制限により、総使用データが数時間遅れる可能性があります。
テキスト検索パイプラインの実行
- Cloud Console
- Bash
-
検索パイプラインの横にある「▶︎」ボタンをクリックしてください。または、プレイグラウンドタブをクリックすることもできます。
-
クエリテキストを入力します。[実行]をクリックします。
-
結果を確認してください。
-
パイプラインを再実行する新しいクエリテキストを入力します。
以下の例では、my_text_search_パイプラインという名前の検索パイプラインを実行しています。クエリテキストは「Zilliz Cloudとは何ですか?」です。
curl --request POST \
--header "Content-Type: application/json" \
--header "Authorization: Bearer ${YOUR_API_KEY}" \
--url "https://controller.api.{cloud-region}.zillizcloud.com/v1/pipelines/${YOUR_PIPELINE_ID}/run" \
-d '{
"data": {
"query_text": "What is Zilliz Cloud?"
},
"params":{
"limit": 1,
"offset": 0,
"outputFields": [],
"filter": "id >= 0"
}
}'
上記のコードのパラメータは次のように説明されています
-
YOUR_API_KEY: APIリクエストの認証に使用される資格情報。APIキーの表示方法については、こちらをご覧ください。 -
cloud-region:クラスターが存在するクラウドリージョンのID。現在、gcp-us-west 1のみがサポートされています。 -
query_text:セマンティック検索を実行するために使用されるクエリテキスト。 -
params:設定する検索パラメータ。-
limit:返すエンティティの最大数。値は1から500までの整数である必要があります。この値とoffsetの値の合計は1024になる必要があります。 -
オフセット:検索結果でスキップするエンティティの数。この値と
limitの合計は大なり1024ではありません。最大値は1024です。 -
outputFields:検索結果とともに返されるフィールドの配列です。デフォルトでは、id(エンティティID)、distance、textが検索結果に返されます。返された結果に他の出力フィールドが必要な場合は、このパラメータを設定できます。 -
フィルター:検索に一致するものを見つけるために使用されるブール式のフィルター
-
以下は回答例です。
{
"code": 200,
"data": {
"result": [
{
"id": 450524927755105948,
"distance": 0.9997715353965759,
"text": "Zilliz Cloud is a fully managed vector database and data services, empowering you to unlock the full potential of unstructured data for your AI applications."
}
],
"usage": {
"embedding": 17,
"rerank": 43
}
}
}
テキストデータを削除
データを削除するには、まず削除パイプラインを作成してから実行する必要があります。
テキスト削除パイプラインの作成
- Cloud Console
- Bash
-
プロジェクトに移動します。
-
ナビゲーションパネルからパイプラインをクリックします。次に、概要タブに切り替えて、パイプラインをクリックします。パイプラインを作成するには、+パイプラインをクリックしてください。
-
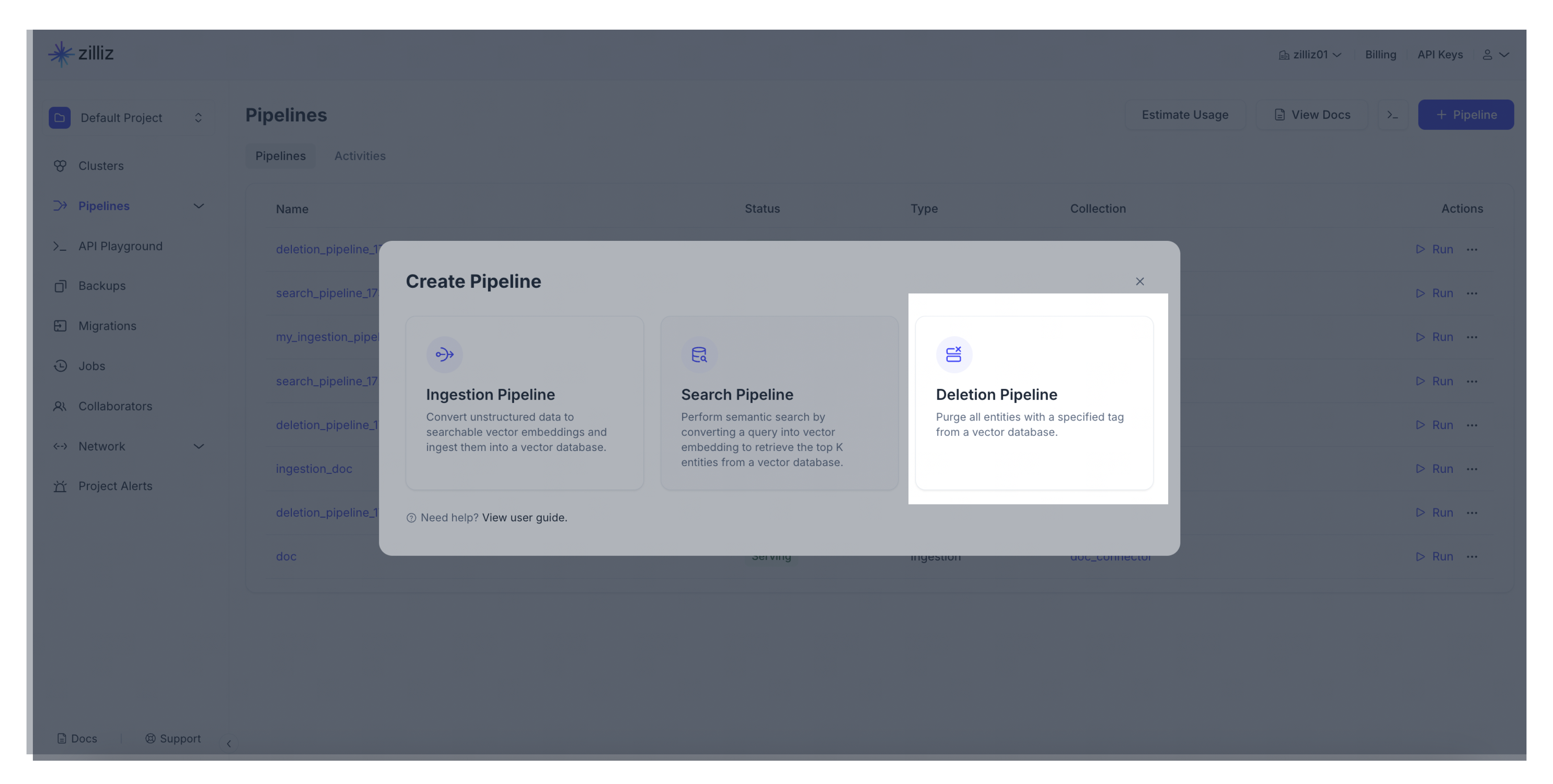
作成するパイプラインの種類を選択してください。「+パイプライン」ボタンを削除パイプライン欄でクリックしてください。
-
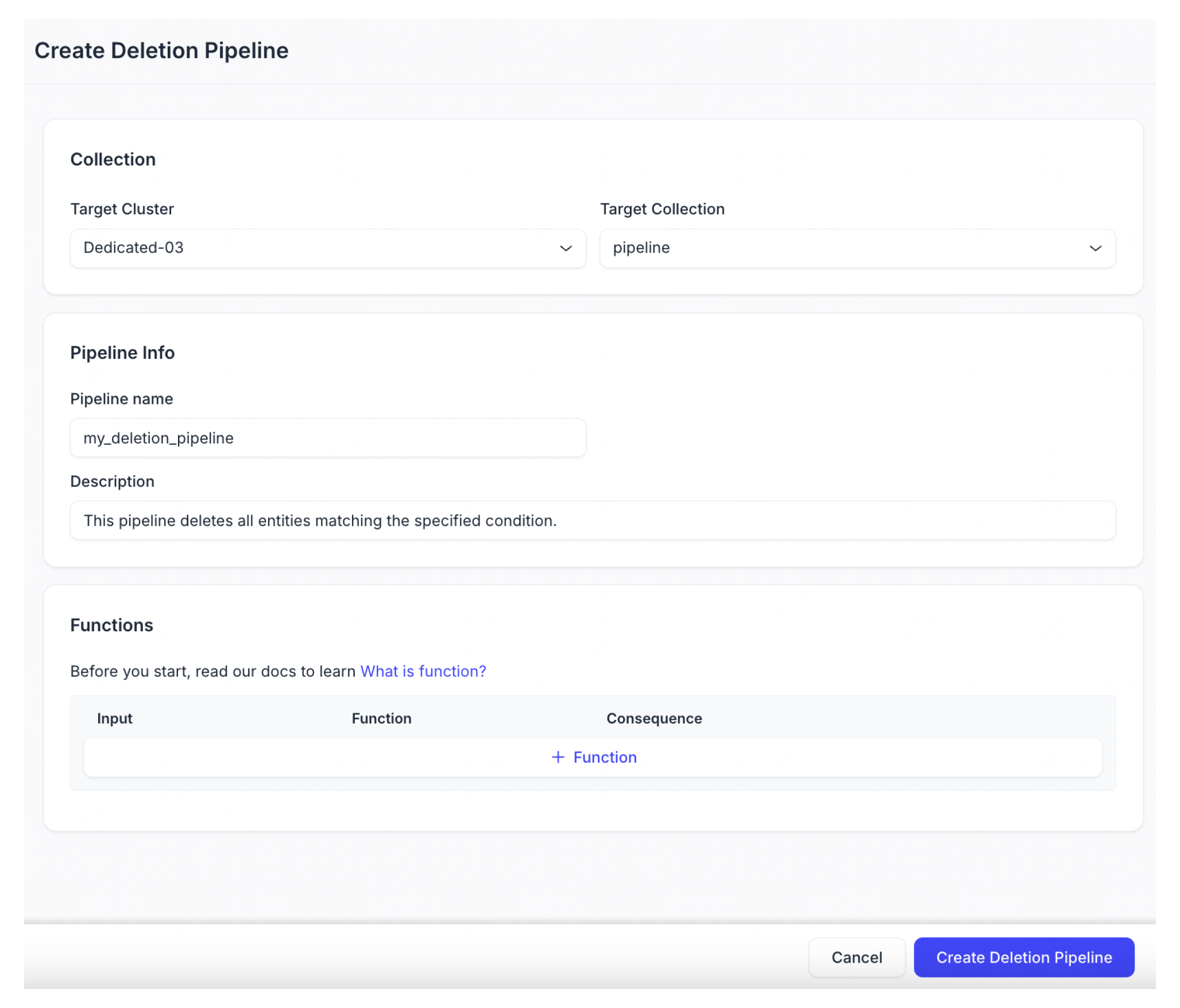
作成する削除パイプラインを構成します。
パラメータ
説明する
パイプライン名
新しい削除パイプラインの名前です。小文字、数字、アンダースコアのみを含める必要があります。
説明(オプション)
新しいDeletionパイプラインの説明。
-
「+Function」をクリックして、削除パイプラインに関数を追加します。1つの関数だけを追加できます。
-
関数名を入力します。
-
「PURGE_TEXT_INDEX」または「PURGE_BY_EXPRESSION」を関数タイプとして選択します。PURGE_TEXT_INDEX関数は、指定されたidを持つすべてのテキストエンティティを削除できます。PURGE_BY_EXPRESSION関数は、指定されたフィルタ式に一致するすべてのテキストエンティティを削除できます。
-
[追加]をクリックして関数を保存します。
-
-
[削除パイプラインを作成]をクリックします。
以下の例では、my_text_delete_Pipelineという名前の削除パイプラインを作成し、PURGE_BY_EXPRESSION関数を追加しています。
curl --request POST \
--header "Content-Type: application/json" \
--header "Authorization: Bearer ${YOUR_API_KEY}" \
--url "https://controller.api.{cloud-region}.zillizcloud.com/v1/pipelines" \
-d '{
"projectId": "proj-xxxx",
"name": "my_text_deletion_pipeline",
"description": "A pipeline that deletes entities by expression",
"type": "DELETION",
"functions": [
{
"name": "purge_data_by_expression",
"action": "PURGE_BY_EXPRESSION"
}
],
"clusterId": "inxx-xxxxxxxxxxxxxxx",
"collectionName": "my_collection"
}'
上記のコードのパラメータは次のように説明されています
-
YOUR_API_KEY: APIリクエストの認証に使用される資格情報。APIキーの表示方法については、こちらをご覧ください。 -
cloud-region:クラスターが存在するクラウドリージョンのID。現在、gcp-us-west 1のみがサポートされています。 -
projectId:パイプラインを作成するプロジェクトのID。詳しくはプロジェクトIDの取得方法をご覧ください。 -
name:作成するパイプラインの名前。パイプライン名は3~64文字の文字列で、英数字とアンダースコアのみを含めることができます。 -
description(オプション):作成するパイプラインの説明。 -
type:作成するパイプラインの種類。現在利用可能なパイプラインの種類には、INGESTION、SEARCH、DELETIONがあります。 -
functions:パイプラインに追加する関数。Deletionパイプラインには1つの関数しか持てません。-
name:関数の名前です。関数名は3~64文字の文字列で、英数字とアンダースコアのみを含めることができます。 -
アクション:追加する関数の種類。利用可能なオプションには、PURGE_DOC_INDEX、PURGE_TEXT_INDEX、PURGE_BY_EXPRESSION、PURGE_IMAGE_INDEXがあります。
-
-
lusterId:パイプラインを作成するクラスタのIDです。現在、GCP us-west 1にデプロイされたクラスタのみを選択できます。詳しくはHow can I find my CLUSTER_ID? -
collectionName:パイプラインを作成するコレクションの名前。
以下は出力例です。
{
"code": 200,
"data": {
"pipelineId": "pipe-xxxx",
"name": "my_text_deletion_pipeline",
"type": "DELETION",
"createTimestamp": 1721187655000,
"description": "A pipeline that deletes entities by expression",
"status": "SERVING",
"functions": [
{
"action": "PURGE_BY_EXPRESSION",
"name": "purge_data_by_expression",
"inputFields": ["expression"]
}
],
"clusterId": "in03-***************",
"collectionName": "my_collection"
}
}
テキスト削除パイプラインを実行
- Cloud Console
- Bash
-
削除パイプラインの横にある「▶︎」ボタンをクリックしてください。または、プレイグラウンドタブをクリックすることもできます。
-
フィルタ式を入力します。[実行]をクリックします。
-
結果を確認してください。
次の例では、my_text_deletion_Pipelineという名前のDeletionパイプラインを実行します。
curl --request POST \
--header "Content-Type: application/json" \
--header "Authorization: Bearer ${YOUR_API_KEY}" \
--url "https://controller.api.{cloud-region}.zillizcloud.com/v1/pipelines/${YOUR_PIPELINE_ID}/run" \
-d '{
"data": {
"expression": "id in [1, 2, 3]"
}
}'
上記のコードのパラメータは次のように説明されています
-
YOUR_API_KEY: APIリクエストの認証に使用される資格情報。APIキーの表示方法については、こちらをご覧ください。 -
cloud-region:クラスターが存在するクラウドリージョンのID。現在、gcp-us-west 1のみがサポートされています。 -
expression:削除する必要のあるエンティティをフィルタリングするために使用されるブール式。ブール式の書き方の詳細については、フィルタリングを参照してください。
以下は回答例です。
{
"code": 200,
"data": {
"num_deleted_entities": 3
}
}
パイプラインの管理
以下は、前述の手順で作成されたパイプラインを管理する関連する操作です。
ビューパイプライン
- Cloud Console
- Bash
左ナビゲーションのパイプラインをクリックします。パイプラインタブを選択します。利用可能なすべてのパイプラインが表示されます。
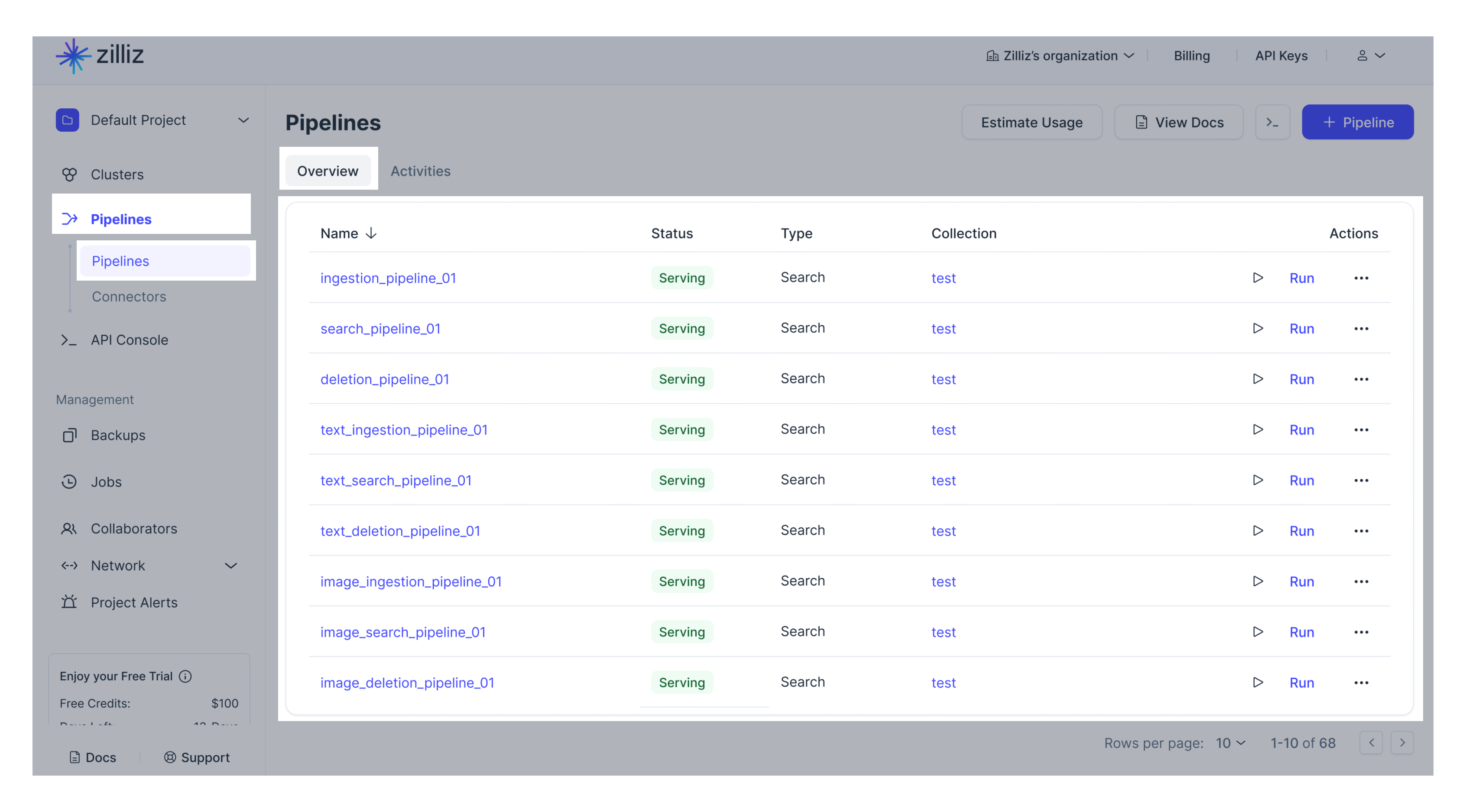
特定のパイプラインをクリックすると、基本情報、合計使用量、機能、関連コネクタなどの詳細情報が表示されます。
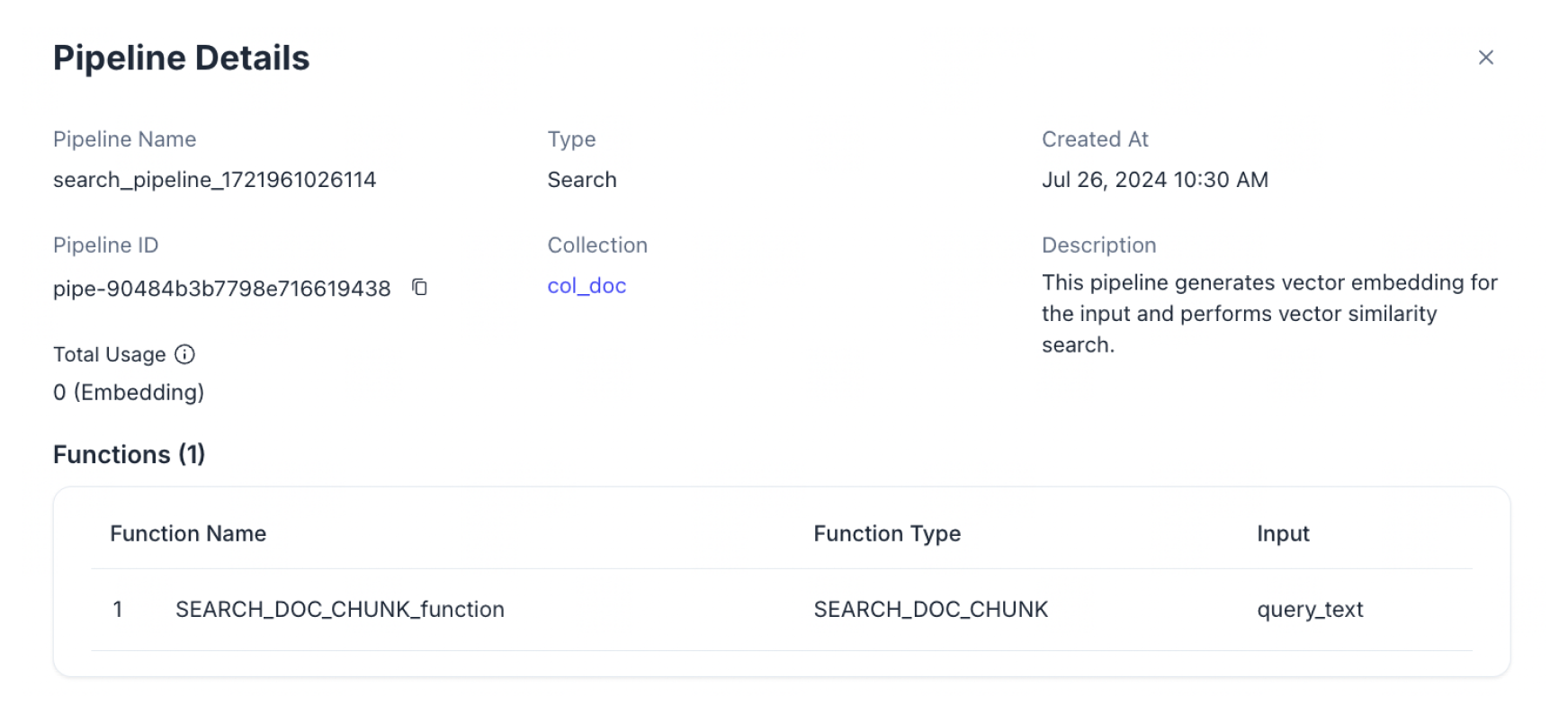
技術的な制限により、総使用データが数時間遅れる可能性があります。
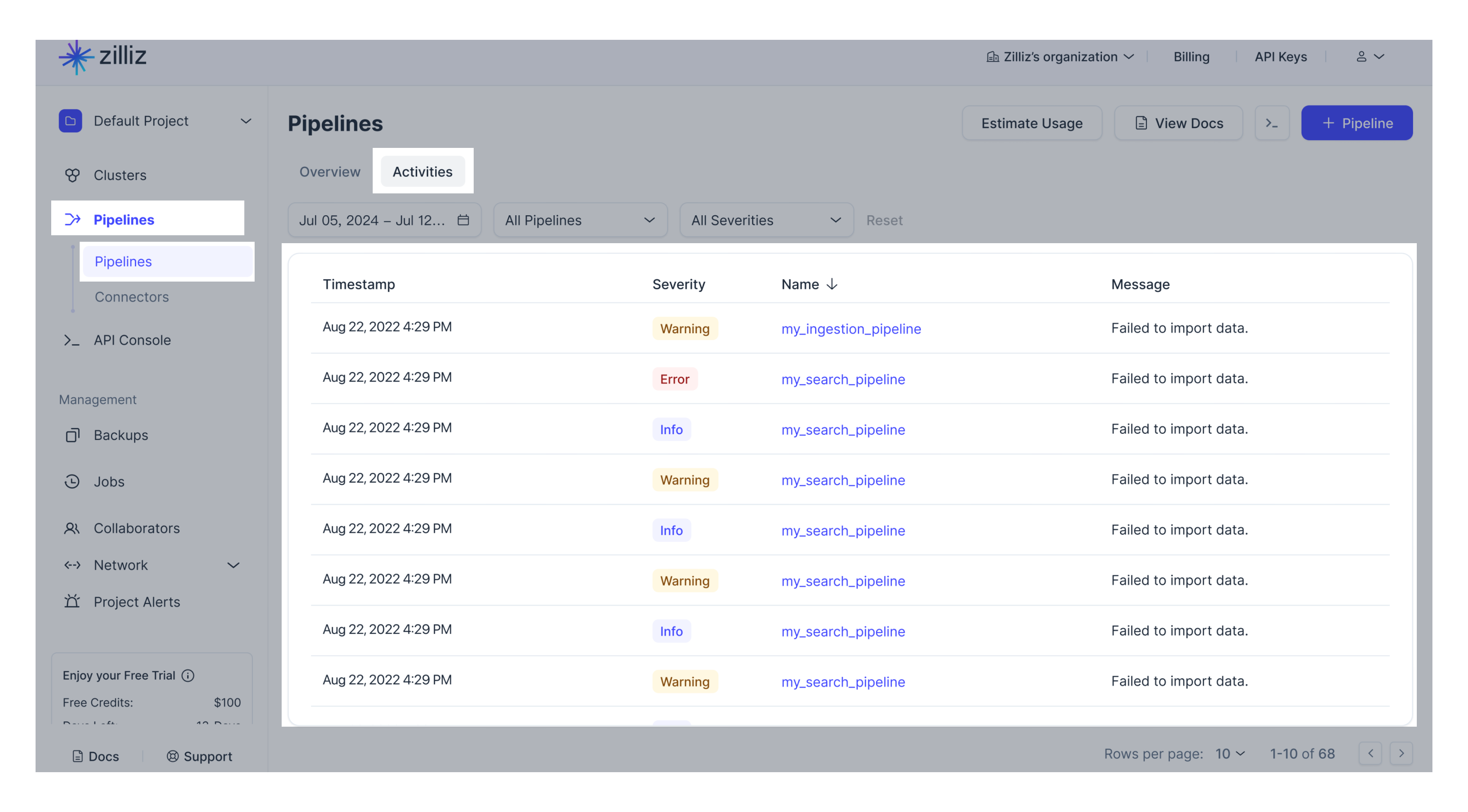
Web UIでパイプラインのアクティビティを確認することもできます。
APIを呼び出して、既存のすべてのパイプラインを一覧表示したり、特定のパイプラインの詳細を表示したりできます。
-
既存のパイプラインをすべて表示する
以下の例に従い、projectIdを指定してくださ
い。プロジェクトIDの取得方法については、こちらをご覧ください。curl --request GET \
--header "Content-Type: application/json" \
--header "Authorization: Bearer ${YOUR_API_KEY}" \
--url "https://controller.api.{cloud-region}.zillizcloud.com/v1/pipelines?projectId=proj-xxxx"以下は出力例です。
{
"code": 200,
"data": [
{
"pipelineId": "pipe-xxxx",
"name": "my_text_ingestion_pipeline",
"type": "INGESTION",
"createTimestamp": 1721187655000,
"clusterId": "in03-***************",
"collectionName": "my_collection"
"description": "A pipeline that generates text embeddings and stores additional fields.",
"status": "SERVING",
"totalUsage": {
"embedding": 0
},
"functions": [
{
"action": "INDEX_TEXT",
"name": "index_my_text",
"inputFields": ["text_list"],
"language": "ENGLISH",
"embedding": "zilliz/bge-base-en-v1.5"
},
{
"action": "PRESERVE",
"name": "keep_text_info",
"inputField": "source",
"outputField": "source",
"fieldType": "VarChar"
}
]
},
{
"pipelineId": "pipe-xxxx",
"name": "my_text_search_pipeline",
"type": "SEARCH",
"createTimestamp": 1721187655000,
"description": "A pipeline that receives text and search for semantically similar texts",
"status": "SERVING",
"totalUsage": {
"embedding": 0,
"rerank": 0
},
"functions":
{
"action": "SEARCH_TEXT",
"name": "search_text",
"inputFields": "query_text",
"clusterId": "in03-***************",
"collectionName": "my_collection",
"embedding": "zilliz/bge-base-en-v1.5",
"reranker": "zilliz/bge-reranker-base"
}
},
{
"pipelineId": "pipe-xxxx",
"name": "my_text_deletion_pipeline",
"type": "DELETION",
"createTimestamp": 1721187655000,
"description": "A pipeline that deletes entities by expression",
"status": "SERVING",
"functions":
{
"action": "PURGE_BY_EXPRESSION",
"name": "purge_data_by_expression",
"inputFields": ["expression"]
},
"clusterId": "in03-***************",
"collectionName": "my_collection"
}
]
}📘ノート技術的な制限により、総使用データが数時間遅れる可能性があります。
-
特定のパイプラインの詳細を表示する
パイプラインの詳細を表示するには、以下の例に従ってください。
curl --request GET \
--header "Content-Type: application/json" \
--header "Authorization: Bearer ${YOUR_API_KEY}" \
--url "https://controller.api.{cloud-region}.zillizcloud.com/v1/pipelines/${YOUR_PIPELINE_ID}"以下は出力例です。
{
"code": 200,
"data": {
"pipelineId": "pipe-xxx",
"name": "my_text_ingestion_pipeline",
"type": "INGESTION",
"createTimestamp": 1721187300000,
"description": "A pipeline that generates text embeddings and stores additional fields.",
"status": "SERVING",
"totalUsage": {
"embedding": 0
},
"functions": [
{
"name": "index_my_text",
"action": "INDEX_TEXT",
"inputFields": ["text_list"],
"language": "ENGLISH",
"embedding": "zilliz/bge-base-en-v1.5"
},
{
"name": "keep_text_info",
"action": "PRESERVE",
"inputField": "source",
"outputField": "source",
"fieldType": "VarChar"
}
],
"clusterId": "inxx-xxxx",
"collectionName": "my_collection"
}
}📘ノート技術的な制限により、総使用データが数時間遅れる可能性があります。
パイプラインを削除
パイプラインが不要になった場合は、削除できます。パイプラインを削除しても、データを取り込んだ自動作成コレクションは削除されません。
ドロップしたパイプラインは回復できません。行動には注意してください。
データ取り込みパイプラインを削除しても、パイプラインと一緒に作成されたコレクションには影響しません。データは安全です。
- Cloud Console
- Bash
Web UIにパイプラインをドロップするには、をクリックします**。。。**「アクション」列の下にあるボタンをクリックします。次に、「ドロップ」をクリックします。
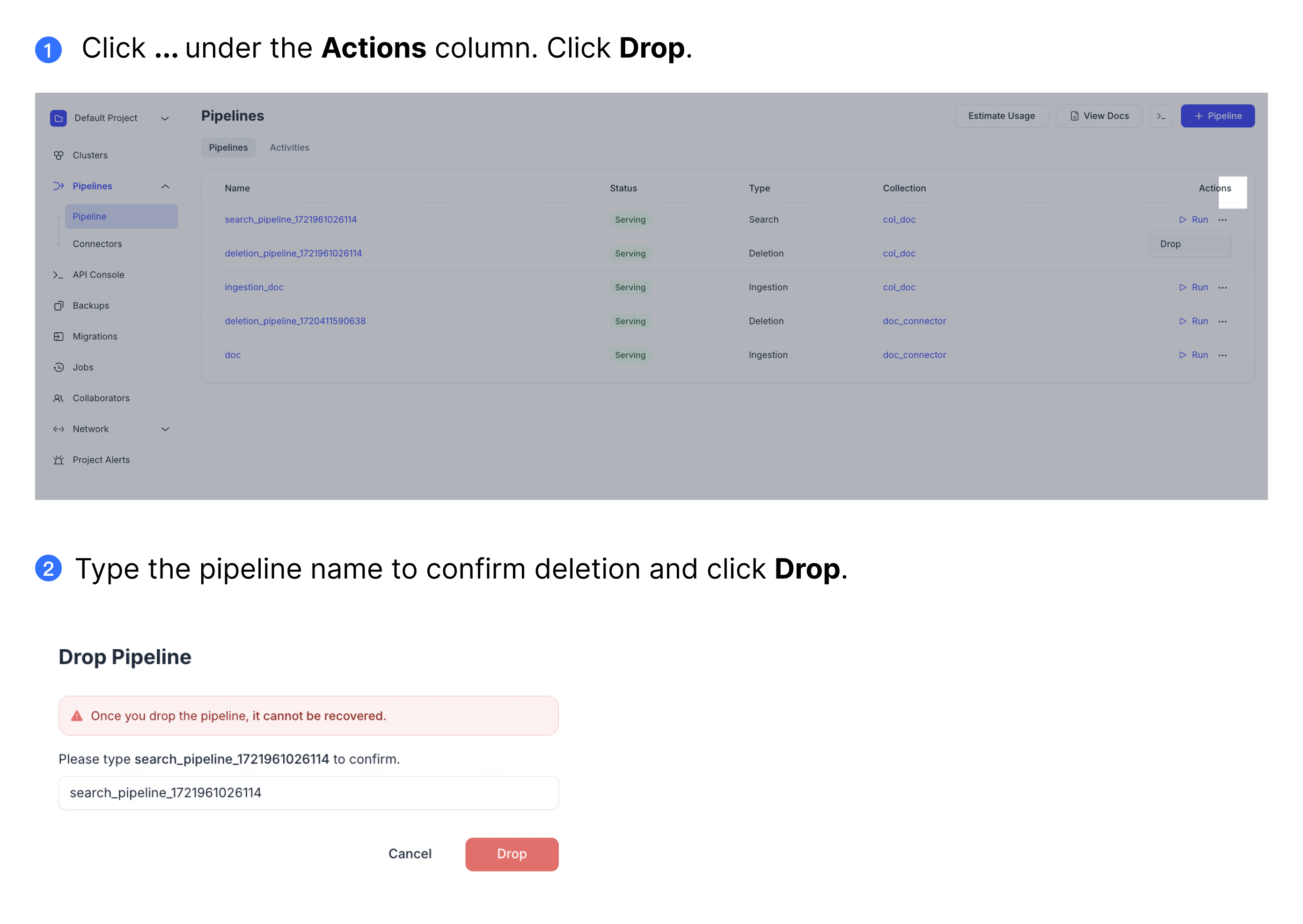
以下の例に従って、パイプラインを削除してください。
curl --request GET \
--header "Content-Type: application/json" \
--header "Authorization: Bearer ${YOUR_API_KEY}" \
--url "https://controller.api.{cloud-region}.zillizcloud.com/v1/pipelines/${YOUR_PIPELINE_ID}"
以下は出力例です。
{
"code": 200,
"data": {
"pipelineId": "pipe-xxx",
"name": "my_text_ingestion_pipeline",
"type": "INGESTION",
"createTimestamp": 1721187300000,
"description": "A pipeline that generates text embeddings and stores additional fields.",
"status": "SERVING",
"totalUsage": {
"embedding": 0
},
"functions": [
{
"name": "index_my_text",
"action": "INDEX_TEXT",
"inputFields": ["text_list"],
"language": "ENGLISH",
"embedding": "zilliz/bge-base-en-v1.5"
},
{
"name": "keep_text_info",
"action": "PRESERVE",
"inputField": "source",
"outputField": "source",
"fieldType": "VarChar"
}
],
"clusterId": "inxx-xxxx",
"collectionName": "my_collection"
}
}
技術的な制限により、総使用データが数時間遅れる可能性があります。