RerankerAbout to Deprecate
情報検索において、リランカーは初期検索の結果を再配置します。ベクトル近似最近傍探索(ANN)検索のみを使用する場合と比較して、リランカーを追加することで、ドキュメントとクエリの意味的関連性をよりよく判断できるため、検索品質を向上させることができます。リランカーを使用することで、RAGアプリケーションで生成された回答の精度を向上させることもできます。これは、より少ないが高品質のドキュメントが文脈に置かれるためです。リランカーは計算量が多く、コストが高く、クエリのレイテンシが長くなる可能性があることに注意してください。
Zilliz Cloud Pipelinesは、2025年第2四半期の終わりまでに廃止され、「Data In, Data Out」という新しい機能に置き換えられます。これにより、MilvusとZilliz Cloudの両方で埋め込み生成が効率化されます。2024年12月24日現在、新規ユーザー登録は受け付けられていません。現在のユーザーは、日没日まで月額20ドルの無料手当内でサービスを継続して利用できますが、SLAは提供されていません。モデルプロバイダーまたはオープンソースモデルの埋め込みAPIを使用してベクトル埋め込みを生成することを検討してください。
リランカーとは何ですか?
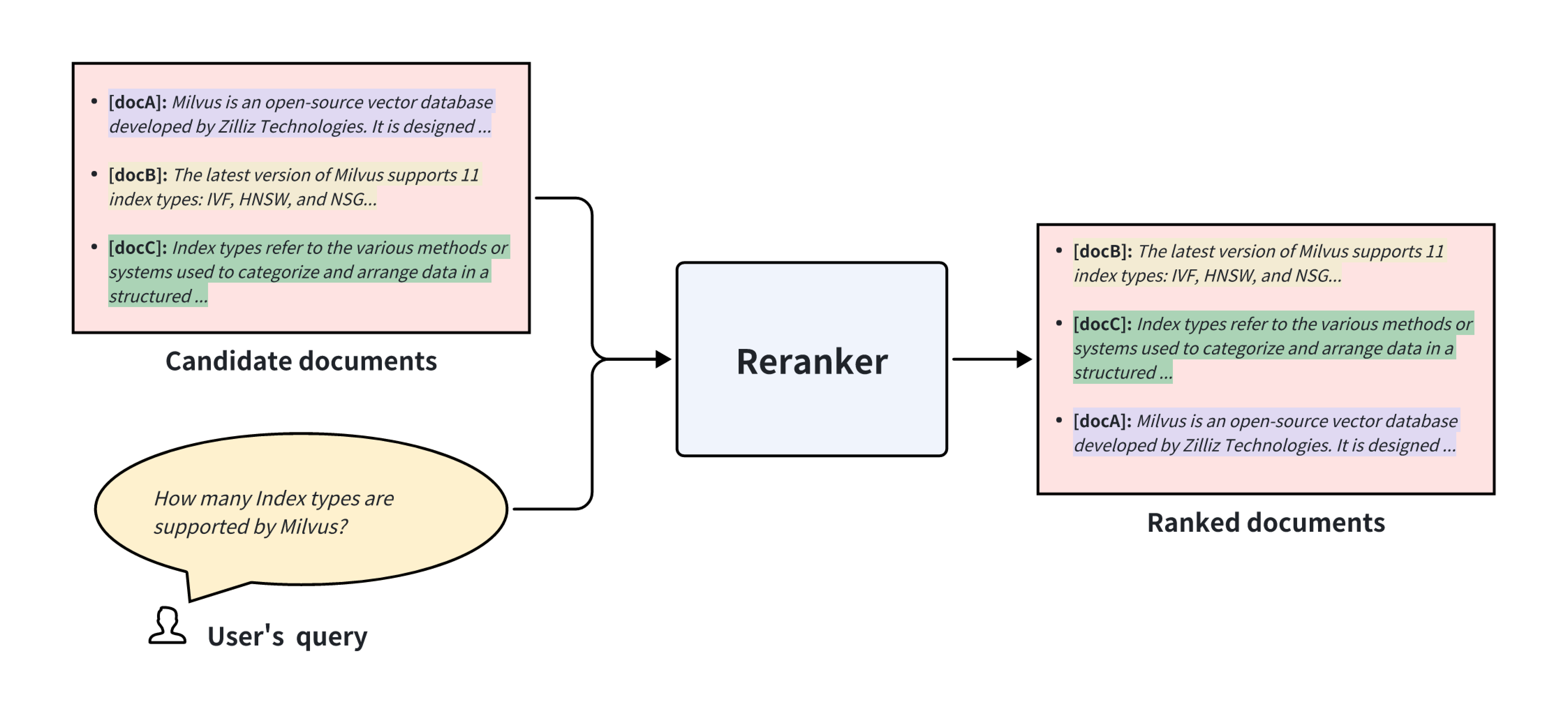
Rerankerは通常、クエリテキストと特定のドキュメントの意味的関連性をスコアリングするためにトレーニングされた機械学習モデルです。Web検索やレコメンデーションシステムなどのプロダクションレベルの情報検索システムは、通常、初期検索と再ランキングの2つの段階で構成されています。初期検索フェーズでは、しばしばベクトル近似最近傍探索(ANN)検索を利用して、膨大なデータセットを効率的に選別し、何百万もの候補者からトップ20アイテムを取得するなど、関連情報を特定します。この初期セットが取得されると、Rerankerはクエリテキストへの関連性に基づいてランキングをさらに洗練させます。再ランク付けされたリストのトップ5など、より小さなセットを使用して、元の順序に基づいて最初の5つを選択するよりも、より良い品質を提供します。
RAGアプリケーションでrerankerを使用する
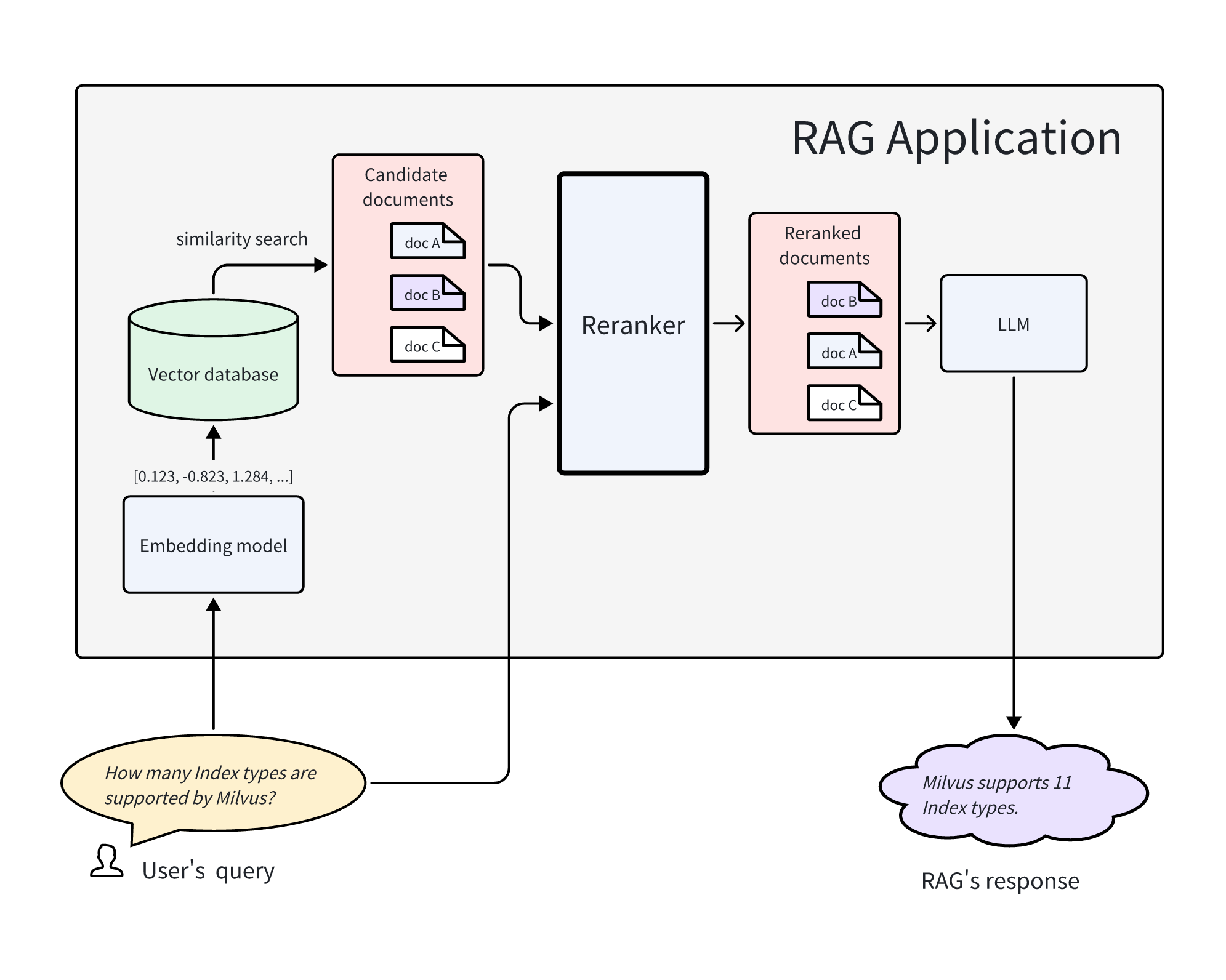
RAGアプリケーションは2つのフェーズで構成されています。検索フェーズは知識ベースから関連情報を取得する責任があり、生成フェーズはLLMを使用して取得された知識を要約し、推論します。検索フェーズでLLMに提供される文脈の関連性は、最終的な回答品質にとって重要です。Rerankerは、RAGアプリケーションの回答品質を向上させるための効果的なツールです。
以下の図は、RAGパイプライン内のリランカの位置を示しています。
いつrerankerを使うべきか
近似最近傍法(ANN)ベクトル検索だけでの初期検索は非常に効率的で、しばしば満足のいく結果をもたらします。多くのシナリオでは、再ランキングの二次段階が必須とは見なされない場合があります。高品質基準を持つアプリケーションでは、再ランク付けを使用することで精度を向上させることができますが、計算量が増加し、検索時間が長くなります。通常、再ランク付けモデルを統合すると、topK選択や再ランク付けモデル体格などの要因に応じて、検索クエリに100 msから数秒のレイテンシが追加されます。初期検索で不正確または関係のないドキュメントが得られた場合、再ランク付けを使用して効果的にフィルタリングし、最終的に生成される応答の品質を向上させます。
ユースケースでリランカーが必要と判断された場合は、検索パイプラインで有効にできます。