クラスターのスケーリング
Zilliz Cloud では、クエリ CU はインデックスの提供と検索リクエストの処理に使用されるハードウェアリソースのセットです。クエリ CU は、クエリサービスを実行する完全に管理された物理ノードと考えることができます。レプリカ は、同じリソースとデータを含むクラスターレベルのコピーです。クエリ CU は主にクラスター容量とコンピューティングリソースを決定し、レプリカはクエリ提供のための追加の並列性を提供します。
この記事で説明するスケーリングオプションは、サービングクラスターにのみ適用されます。
オンデマンドクラスターは自動的にスケールします — リクエストが到着すると起動し、アイドル時にはゼロにスケールバックされ、手動での介入は不要です。
Query CU vs Replica
ワークロードが増加し、より多くのデータが書き込まれるにつれて、サービングクラスターは最終的に容量とパフォーマンスの限界に達する可能性があります。これを事前に管理するために、メトリクスページで Query CU容量 と Query CU計算 を監視し、限界に達する前にスケールすることができます。
クエリ CU をスケールするかレプリカをスケールするかの選択は、目的によって異なります。経験則として:
-
1 - 8 クエリ CU のサービングクラスターの場合、クエリ CU を直接スケールできます。
-
8 クエリ CU を超えるサービングクラスターの場合、ニーズに応じてクエリ CU またはレプリカをスケールできます。
より多くの容量のためにクエリ CU をスケール
容量関連の制限に達している場合、またはデータとワークロードの継続的な成長が予想される場合は、クエリ CU をスケールします。
典型的なシグナルとシナリオには以下が含まれます:
-
読み取りは成功するが、書き込み操作が失敗する。これは、サービングクラスターが容量上限またはその近くにあることを示していることが多い。
-
大規模なデータセットを扱っている、またはより多くのコレクションが必要である。
-
CPU またはメモリ使用率が高い。
詳細については、クエリ CU のスケール を参照してください。
より高いスループットまたは可用性のためにレプリカをスケール
サービングクラスターがデータを保持できるが、クエリスループット(QPS)のボトルネックが見られる、またはより良い可用性が必要な場合にレプリカをスケールします。
典型的なシグナルとシナリオには以下が含まれます:
-
小規模から中規模のデータセットだが、QPS のボトルネックが発生する。
-
クエリ負荷を複数の同一コピーに分散してスループットを向上させたい。
-
可用性を改善したい。
詳細については、レプリカのスケール を参照してください。
スケーリングオプション
Zilliz Cloud は、サービングクラスターリソースをスケールする複数の方法を提供します。ワークロードパターンに応じて、即座に、スケジュールに従って、または自動的にスケールできます。
手動スケーリング
ワークロードを明確に理解し、変更が必要な時期を予測できる場合に、手動でリソースを調整します。
-
クエリ CU: 容量を拡張するために増加させ、需要が低下したときにコストを削減するために減少させます。
-
レプリカ: クエリスループットと可用性を向上させるために増加させ、需要が低下したときに減少させます。
スケジュールされたスケーリング
ワークロードに繰り返しパターンがある場合(例:平日のピークと週末のトラフ)、スケジュールされたスケーリングを使用します。一般的なユースケースには、営業時間中のトラフィックスパイクと予測可能なバッチ/クエリウィンドウが含まれます。
スケジュールされたスケーリングについて、Zilliz Cloud は 2 つのモードを提供します:
-
基本モード: スケジュールを定義するためのシンプルなセレクター
-
詳細モード: より柔軟性を得るために Unix cron 式 を使用します。
動的スケーリング
予測不可能なワークロードに対して動的スケーリングを有効にします。Zilliz Cloud は、リアルタイムメトリクスに基づいて、ユーザー定義の最小-最大範囲内でリソースを自動的に調整します。
-
クエリ CU: CU容量 メトリクス値に基づいて自動スケールします。
-
レプリカ: CU計算 メトリクス値に基づいて自動スケールします。
スケーリング中の課金
Dedicated クラスタでは、スケーリングによって課金が即座に変更されることはありません。スケーリングジョブ中、Zilliz Cloud は以前の構成に基づいてクラスタに課金し続けます。新しいクエリ CU またはレプリカ構成は、スケーリングジョブが正常に完了した後にのみ課金に使用されます。
詳細については、Dedicated クラスタのコスト を参照してください。
よくある質問
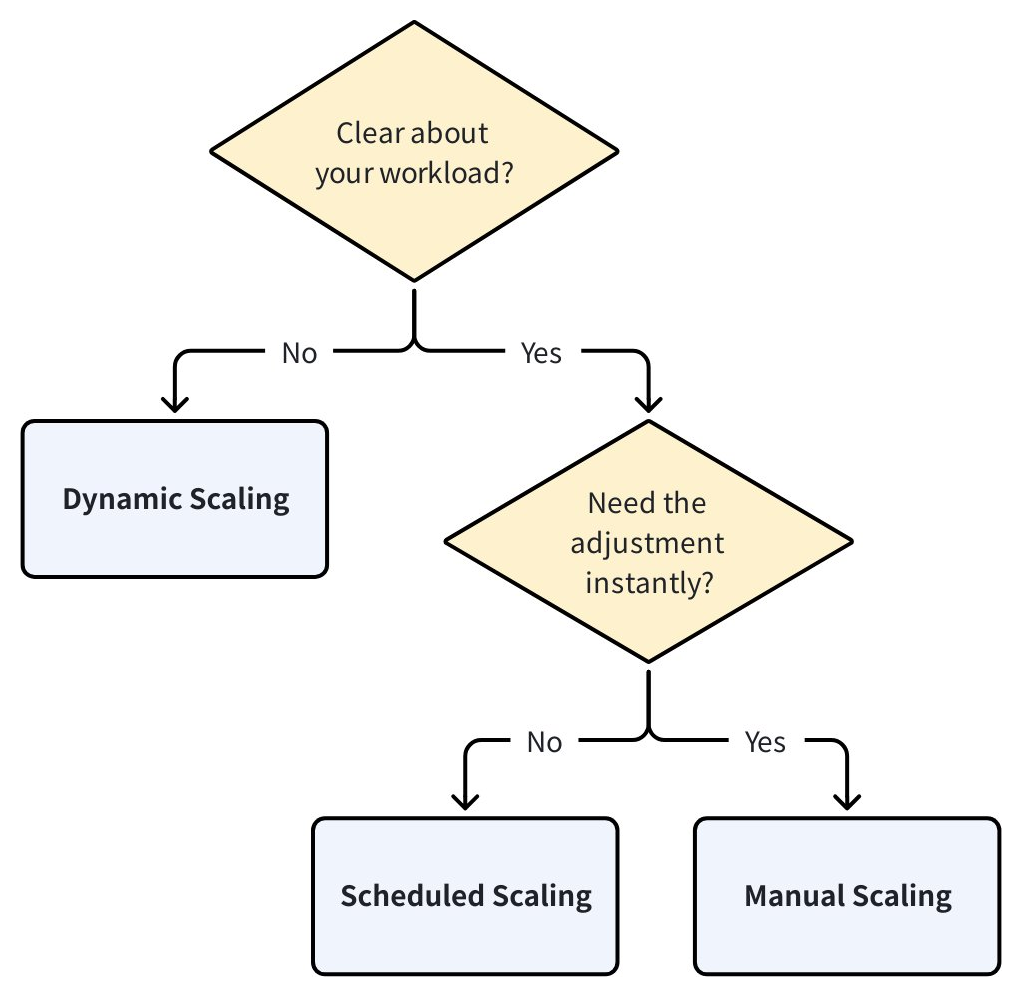
どのスケーリングオプションを選択すべきですか?
ニーズに適したスケーリング方法を選択するためのクイックヒントは以下の通りです:
-
ワークロードパターンを非常に明確に理解している場合 — 一貫した毎日のピークや計画されたバッチインポートジョブなど — 手動スケーリングとスケジュールされたスケーリングが適切なオプションです。クエリ CU を即座に調整する必要がある場合は、手動スケーリングを選択してください。特定の将来の時刻に繰り返し調整を行いたい場合は、スケジュールされたスケーリングを選択してください。
-
ワークロードが予測不可能で、1日や1週間を通じて変動する場合は、動的スケーリングを推奨します。定義した範囲内でサービングクラスターサイズを自動的に調整し、パフォーマンスを維持しながらコストを最適化するのに役立ちます。
いつレプリカをスケールし、いつクエリ CU をスケールすべきですか?
以下を推奨します:
-
レプリカ数を増やす場合:
-
高い QPS(1秒あたりのクエリ数)と高い可用性を処理する必要がある。
-
ワークロードに多くの同時検索またはクエリリクエストが含まれる。スループットを向上させる必要がある。
ヒント: 各レプリカはクエリ CU リソースの独立したコピーであり、クエリのサブセットを処理します。
-
-
クエリ CU を増やす場合:
-
大規模なデータセットを扱っている、またはより多くのコレクションが必要である。
-
CPU またはメモリ使用率が高い。
ヒント: CU サイズを増やすと、各クエリノードにより多くのコンピューティングリソースと容量が提供されます。
-
-
提案: 1 - 8 CU のサービングクラスターの場合、クエリ CU を直接スケールできます。8 CU を超えるサービングクラスターの場合は、レプリカを増やしてください。
Zilliz Cloud でスケーリングはどのように機能しますか?
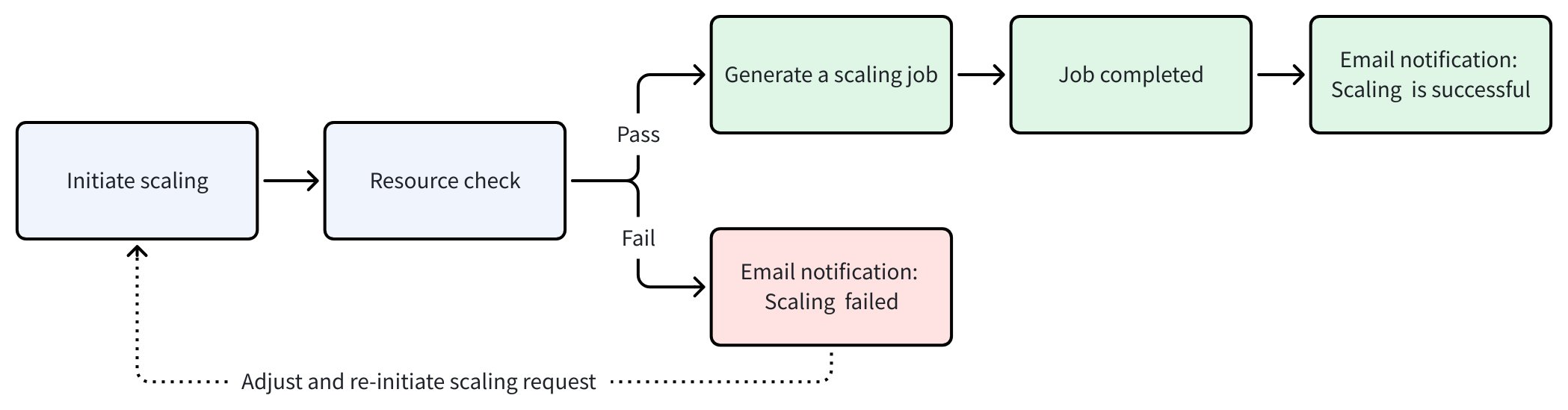
以下の図は、Zilliz Cloud でのスケーリング操作のワークフローを示しています。
-
スケーリングの開始: Web コンソールまたは RESTful API を介してスケーリングリクエストを送信できます。
-
リソースチェック: Zilliz Cloud は、スケーリングリクエストを以下の要件に対して検証します。
-
Enterprise プロジェクト: クエリ CU × レプリカ ≤ 10,240
-
Standard プロジェクト: クエリ CU ≤ 32
-
レプリカ > 1 の場合、サービングクラスターは 12 クエリ CU 未満にスケールダウンできません。
-
現在のデータ量 < 新しい CU サイズの CU 容量の 80%。
-
現在のコレクションとパーティションの数 < 新しい CU サイズで許可されるコレクションとパーティションの最大数。
-
スケーリングに問題がある場合は、サポートにお問い合わせください。
-
-
スケーリングジョブの生成: リソースチェックが通過すると、Zilliz Cloud はスケーリングジョブを作成します。ジョブページで進捗を追跡できます。この間、サービングクラスターのステータスは変更中に変わり、サスペンド、マイグレート、ドロップなどのクラスター操作は利用できません。
-
ジョブが完了しました: ジョブが完了すると、スケーリングは成功し、サービングクラスターのステータスは実行中に戻ります。リソース調整を確認するメールも受信します。
Dedicated クラスタをスケーリングする場合、スケーリング中は古い構成と新しい構成のどちらに基づいて課金されますか?
スケーリング中は、以前の構成に基づいて課金されます。新しい構成は、スケーリングジョブが正常に完了した後にのみ課金に使用されます。
クエリCUをスケーリング [READ MORE]
ワークロードの増加やデータの書き込み量が多くなると、サービングクラスターが容量上限に達する可能性があります。このような場合、読み取り操作は引き続き機能しますが、新しい書き込み操作が失敗する可能性があります。
レプリカをスケーリング [READ MORE]
Zilliz Cloud はクラスターレベルのレプリケーションをサポートしています。各レプリカはクラスター内のリソースとデータの完全なコピーです。レプリカを使用することで、クエリのスループットと可用性を向上させることができます。
Cron 式 [READ MORE]
Cron 式は、特定の時刻にスケーリングタスクを実行するためのスケジュールを定義します。