スイッチオーバーとフェイルオーバー
Zilliz Cloud グローバルクラスターは、どのリージョンがプライマリークラスターをホストするかを変更する2つの操作をサポートしています。
-
スイッチオーバー: 計画的な、データ損失ゼロの操作で、同期済みのセカンダリークラスターをプライマリーに昇格させます。
-
フェイルオーバー: プライマリーリージョンで障害が発生した後、セカンダリークラスターをプライマリーに昇格させる緊急復旧操作です。
このページでは、それぞれの操作をいつ使用するか、どのように実行するか、および実行中と実行後に何が起こるかを説明します。
この機能は、ビジネスクリティカルプロジェクトのDedicatedクラスターでのみ利用可能です。
概要
スイッチオーバーとフェイルオーバーの比較
以下の表は、2つの操作を比較しています。
スイッチオーバー | フェイルオーバー | |
|---|---|---|
使用するタイミング | 計画的な操作:リージョンのローテーション、コンプライアンス要件、データレジデンシーの変更。 | プライマリーリージョンでの予期しない障害または停止。 |
トリガー | すべてのプライマリーおよびセカンダリークラスターが実行中の場合に手動で開始。 | プライマリークラスターが異常になった場合に復旧アクションとして手動で開始 |
データ損失(RPO) | 0 — データ損失なし。完全なデータ同期後にのみ昇格が行われます。 | フェイルオーバー時の同期遅延と同等。 |
ダウンタイム(RTO) | ほぼゼロ。グローバルエンドポイントが自動的に再ルーティングします。 | 通常は数分程度。 |
前提条件 |
|
|
古いプライマリークラスターの処理 | セカンダリークラスターに降格されます。 | 破棄され、ごみ箱に移動されます。新しいセカンダリーが自動的に作成されます。 |
アプリケーションの変更 | グローバルエンドポイントを使用している場合はなし。ルーティングは自動的に更新されます。詳細については、グローバルクラスターへの接続を参照してください。 | グローバルエンドポイントを使用している場合はなし。ルーティングは自動的に更新されます。詳細については、グローバルクラスターへの接続を参照してください。 |
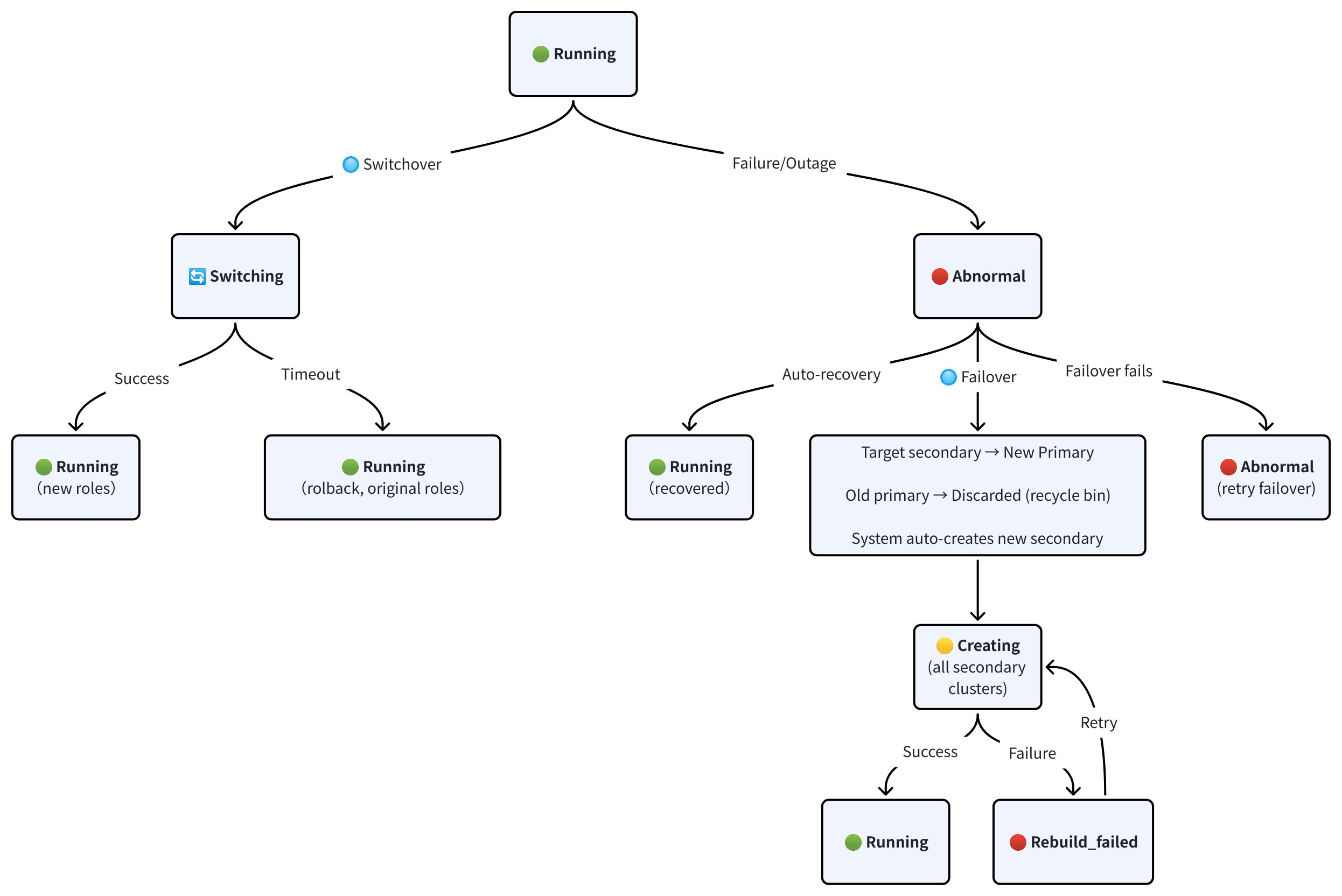
クラスターステータスの遷移
以下の図は、スイッチオーバー、フェイルオーバー、および自動復旧操作中のクラスターステータスの変化を示しています。
-
スイッチオーバー:
-
スイッチオーバーでは、ターゲットのセカンダリーが現在のプライマリーと同期する間、クラスターのステータスが RUNNING から SWITCHING に遷移します。同期が完了すると、ターゲットのセカンダリーが新しいプライマリーに昇格し、元のプライマリーはセカンダリーに降格されます。両方のクラスターは新しい役割で RUNNING に戻ります。
-
同期がタイムアウト期間内に完了しない場合、スイッチオーバーはロールバックされます。両方のクラスターは元の役割を保持したまま RUNNING に戻ります。
-
-
フェイルオーバー:
-
プライマリークラスターが障害または停止により ABNORMAL ステータスになった場合、フェイルオーバーをトリガーできます。ターゲットのセカンダリーが新しいプライマリーに昇格し、古いプライマリーは破棄されてごみ箱に移動されます。
-
フェイルオーバーが完了すると、Zilliz Cloud は完全なトポロジーを復元するために新しいセカンダリークラスターを自動的に作成します。新しいセカンダリーと残りのすべてのセカンダリークラスターは CREATING ステータスで開始し、プロビジョニングとデータ同期が完了すると RUNNING に遷移します。作成に失敗した場合、クラスターは REBUILD_FAILED ステータスになります。再構築を再試行するか、お問い合わせください。
-
フェイルオーバー自体が失敗した場合、クラスターは ABNORMAL ステータスのままになります。フェイルオーバーを再試行するか、お問い合わせください。
-
-
自動復旧:
プライマリークラスターの問題が自己解決した場合、クラスターは ABNORMAL から RUNNING に手動介入なしで遷移します。この場合、フェイルオーバーは不要です。
スイッチオーバーの実行
計画的なリージョンローテーションの場合、スイッチオーバーを実行してセカンダリークラスターをプライマリーの役割に昇格させることができます。
開始前
-
グローバルクラスター内のすべてのクラスターが RUNNING ステータスである必要があります。
-
同期遅延は30秒以下である必要があります。このしきい値を超えると、スイッチオーバーは拒否されます。遅延は グローバルトポロジー タブで確認してください。
-
Query CU または Replica の スケーリング 操作が進行中でないこと。
手順
以下のデモは、スイッチオーバーの実行方法を示しています。
グローバルクラスター ページに移動します。
スイッチオーバー or フェイルオーバー をクリックします。
昇格させるターゲットのセカンダリークラスターを選択します。
スイッチオーバー を選択します。
ダイアログで操作を確認します。
スイッチオーバーを開始すると、Zilliz Cloud はターゲットのセカンダリーが現在のプライマリーと完全に同期するのを待ってから、新しいプライマリーに昇格させます。
スイッチオーバー後
-
元のプライマリーはセカンダリークラスターになり、新しいプライマリーからのレプリケートデータの受信を開始します。
-
グローバルエンドポイントのルーティングは自動的に更新され、書き込みを新しいプライマリーに向けます。
-
新しい グローバルトポロジー ビューを確認できます。すべてのクラスターは RUNNING ステータスに戻るはずです。
-
新しいプライマリークラスターでバックアップポリシーを再構成してください。バックアップポリシーは自動的に新しいプライマリーに転送されません。
フェイルオーバーの実行
プライマリーリージョンで停止が発生し、プライマリークラスターが ABNORMAL ステータスの場合にフェイルオーバーを使用します。
フェイルオーバーは緊急操作です。スイッチオーバーとは異なり、完全なデータ同期を待ちません。プライマリーでコミットされたが、ターゲットのセカンダリーにまだレプリケートされていない書き込みは失われます。データ損失の量は、フェイルオーバー時の同期遅延と同等です。
開始前
-
プライマリークラスターが到達不能で ABNORMAL ステータスであることを確認します。
-
どのセカンダリークラスターを昇格させるかを特定します。複数のセカンダリーが利用可能な場合は、同期遅延が最も小さいもの(プライマリーの最新の状態に最も近いもの)を選択します。
手順
以下のデモは、フェイルオーバーの実行方法を示しています。
グローバルクラスター ページに移動します。
スイッチオーバー or フェイルオーバー をクリックします。
昇格させるターゲットのセカンダリークラスターを選択します。
フェイルオーバー を選択します。
ダイアログで操作を確認します。
フェイルオーバーが失敗した場合、クラスターは ABNORMAL ステータスのままになります。フェイルオーバー操作を再試行するか、サポートチケットを作成できます。
フェイルオーバー後
-
元のプライマリーは破棄され、ごみ箱に移動されます。グローバルトポロジー ビューには表示されなくなります。
-
完全なグローバルトポロジーを復元するために、新しいセカンダリークラスターが自動的に作成されます。新しいセカンダリーのプロビジョニング中は、グローバルトポロジーからは非表示になります。代わりに、グローバルクラスターページにバナーが表示されます:"A new secondary cluster will be created and become available shortly."
-
残りのセカンダリークラスターも、再構築のために CREATING ステータスに遷移し、再構築が完了すると RUNNING になります。
-
グローバルエンドポイントは、書き込みを新しいプライマリーに向けるように更新されます。
-
新しいプライマリークラスターでバックアップポリシーを再構成してください。バックアップポリシーは自動的に新しいプライマリーに転送されません。
ルーティング動作
以下の表は、各操作中および完了後のグローバルエンドポイントとパブリックエンドポイントの動作をまとめたものです。
エンドポイントの種類 | スイッチオーバー中 | フェイルオーバー中 | 完了後 |
|---|---|---|---|
グローバルエンドポイント |
|
|
|
パブリックエンドポイント |
|
|
|
進行中のタスクへの影響
以下の表は、スイッチオーバーとフェイルオーバー中の進行中のタスクの処理方法をまとめたものです。
タスク | スイッチオーバー中 | フェイルオーバー中 |
|---|---|---|
バックアップ | タスクが失敗します。スイッチオーバー完了後、新しいプライマリーで自動的に再試行されます。 | タスクが失敗します。フェイルオーバー完了後、新しいプライマリーで自動的に再試行されます。 |
Query CU スケーリング | スケーリングが進行中の間、スイッチオーバーはブロックされます。 | タスクが失敗します。フェイルオーバー完了後に再試行されます。 |
Replica スケーリング | スケーリングが進行中の間、スイッチオーバーはブロックされます。 | タスクが失敗します。フェイルオーバー完了後に再試行されます。 |