バイナリベクトル
バイナリベクトルは、従来の高次元浮動小数点ベクトルを0と1のみを含むバイナリベクトルに変換する特殊なデータ表現形式です。この変換により、ベクトルのサイズが圧縮されるだけでなく、ストレージおよび計算コストが削減されながら、セマンティック情報が保持されます。非重要な特徴の精度が必須でない場合、バイナリベクトルは元の浮動小数点ベクトルの大部分の完全性と有用性を効果的に維持できます。
バイナリベクトルは、計算効率とストレージの最適化が重要な状況で特に、幅広い応用分野を持っています。検索エンジンや推薦システムなどの大規模AIシステムでは、大量のデータのリアルタイム処理が鍵となります。ベクトルのサイズを削減することで、バイナリベクトルは精度を大幅に犠牲にすることなく、レイテンシと計算コストの削減に貢献します。さらに、バイナリベクトルは、メモリと処理能力が限られたモバイルデバイスや組み込みシステムなど、リソースが制約された環境でも有用です。バイナリベクトルを使用することで、これらの制約された環境で複雑なAI機能を高いパフォーマンスを維持しながら実装できます。
概要
バイナリベクトルは、画像、テキスト、音声などの複雑なオブジェクトを固定長のバイナリ値にエンコードする方法です。Zilliz Cloud クラスタでは、バイナリベクトルは通常、ビット配列またはバイト配列として表現されます。例えば、8次元のバイナリベクトルは [1, 0, 1, 1, 0, 0, 1, 0] のように表現できます。
以下の図は、バイナリベクトルがテキストコンテンツ内のキーワードの存在をどのように表現するかを示しています。この例では、2つの異なるテキスト(テキスト1 と テキスト2)を表現するために10次元のバイナリベクトルが使用されており、各次元は語彙内の単語に対応しています。1はテキスト内にその単語が存在することを示し、0は存在しないことを示します。
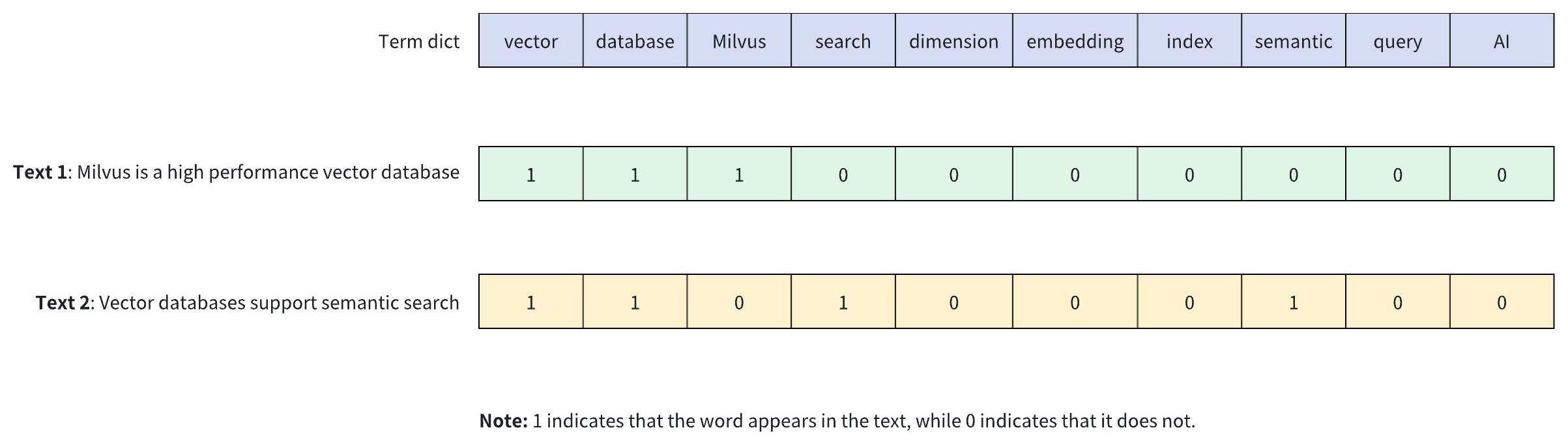
バイナリベクトルには以下の特徴があります。
-
効率的なストレージ: 各次元は1ビットのストレージのみを必要とし、ストレージスペースを大幅に削減します。
-
高速な計算: ベクトル間の類似度は、XORなどのビット演算を使用して高速に計算できます。
-
固定長: 元のテキストの長さに関係なく、ベクトルの長さは一定であり、インデックス作成と検索が容易になります。
-
シンプルで直感的: キーワードの存在を直接的に反映し、特定の専門的な検索タスクに適しています。
バイナリベクトルは、さまざまな方法で生成できます。テキスト処理では、事前定義された語彙を使用して、単語の存在に基づいて対応するビットを設定できます。画像処理では、pHash などの知覚ハッシュアルゴリズムを使用して画像のバイナリ特徴を生成できます。機械学習アプリケーションでは、モデルの出力を二値化してバイナリベクトル表現を取得できます。
バイナリベクトル化後、データは Zilliz Cloud クラスタに保存され、管理およびベクトル検索が行われます。以下の図は基本的なプロセスを示しています。
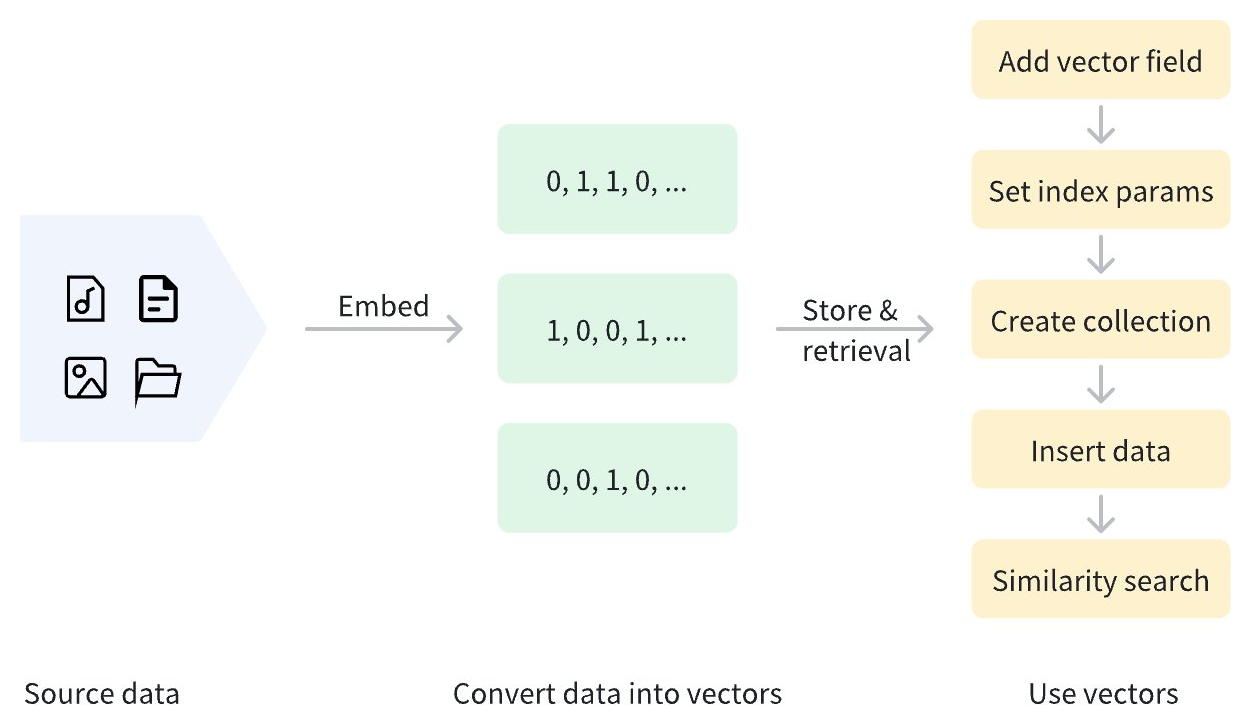
バイナリベクトルは特定のシナリオで優れていますが、表現能力には限界があり、複雑なセマンティック関係を捉えることが困難です。そのため、実際のシナリオでは、バイナリベクトルは効率と表現力のバランスを取るために、他のベクトルタイプと併用されることが多いです。詳細については、Dense Vector および Sparse Vector を参照してください。
バイナリベクトルの使用
ベクトルフィールドの追加
Zilliz Cloud クラスタでバイナリベクトルを使用するには、コレクションの作成時にバイナリベクトルを保存するためのベクトルフィールドを定義する必要があります。このプロセスには以下が含まれます。
-
datatypeをサポートされているバイナリベクトルデータタイプ、すなわちBINARY_VECTORに設定します。 -
dimパラメータを使用してベクトルの次元を指定します。バイナリベクトルは挿入時にバイト配列に変換する必要があるため、dimは8の倍数である必要があることに注意してください。8つのブール値(0または1)が1バイトにパックされます。例えば、dim=128の場合、挿入には16バイトの配列が必要です。
- Python
- Java
- NodeJS
- Go
- cURL
from pymilvus import MilvusClient, DataType
client = MilvusClient(uri="YOUR_CLUSTER_ENDPOINT")
schema = client.create_schema(
auto_id=True,
enable_dynamic_fields=True,
)
schema.add_field(field_name="pk", datatype=DataType.VARCHAR, is_primary=True, max_length=100)
schema.add_field(field_name="binary_vector", datatype=DataType.BINARY_VECTOR, dim=128)
import io.milvus.v2.client.ConnectConfig;
import io.milvus.v2.client.MilvusClientV2;
import io.milvus.v2.common.DataType;
import io.milvus.v2.service.collection.request.AddFieldReq;
import io.milvus.v2.service.collection.request.CreateCollectionReq;
MilvusClientV2 client = new MilvusClientV2(ConnectConfig.builder()
.uri("YOUR_CLUSTER_ENDPOINT")
.build());
CreateCollectionReq.CollectionSchema schema = client.createSchema();
schema.setEnableDynamicField(true);
schema.addField(AddFieldReq.builder()
.fieldName("pk")
.dataType(DataType.VarChar)
.isPrimaryKey(true)
.autoID(true)
.maxLength(100)
.build());
schema.addField(AddFieldReq.builder()
.fieldName("binary_vector")
.dataType(DataType.BinaryVector)
.dimension(128)
.build());
import { DataType } from "@zilliz/milvus2-sdk-node";
schema.push({
name: "binary vector",
data_type: DataType.BinaryVector,
dim: 128,
});
import (
"context"
"fmt"
"github.com/milvus-io/milvus/client/v2/column"
"github.com/milvus-io/milvus/client/v2/entity"
"github.com/milvus-io/milvus/client/v2/index"
"github.com/milvus-io/milvus/client/v2/milvusclient"
)
ctx, cancel := context.WithCancel(context.Background())
defer cancel()
milvusAddr := "YOUR_CLUSTER_ENDPOINT"
client, err := milvusclient.New(ctx, &milvusclient.ClientConfig{
Address: milvusAddr,
})
if err != nil {
fmt.Println(err.Error())
// handle error
}
defer client.Close(ctx)
schema := entity.NewSchema()
schema.WithField(entity.NewField().
WithName("pk").
WithDataType(entity.FieldTypeVarChar).
WithIsAutoID(true).
WithIsPrimaryKey(true).
WithMaxLength(100),
).WithField(entity.NewField().
WithName("binary_vector").
WithDataType(entity.FieldTypeBinaryVector).
WithDim(128),
)
export primaryField='{
"fieldName": "pk",
"dataType": "VarChar",
"isPrimary": true,
"elementTypeParams": {
"max_length": 100
}
}'
export vectorField='{
"fieldName": "binary_vector",
"dataType": "BinaryVector",
"elementTypeParams": {
"dim": 128
}
}'
export schema="{
\"autoID\": true,
\"fields\": [
$primaryField,
$vectorField
],
\"enableDynamicField\": true
}"
この例では、バイナリベクトルを格納するための binary_vector という名前のベクトルフィールドが追加されています。このフィールドのデータ型は BINARY_VECTOR で、次元数は 128 です。
ベクトルフィールドのインデックスパラメータを設定する
検索を高速化するには、バイナリベクトルフィールドに対してインデックスを作成する必要があります。インデックス作成により、大規模なベクトルデータの検索効率を大幅に向上させることができます。
- Python
- Java
- NodeJS
- Go
- cURL
index_params = client.prepare_index_params()
index_params.add_index(
field_name="binary_vector",
index_name="binary_vector_index",
index_type="AUTOINDEX",
metric_type="HAMMING"
)
import io.milvus.v2.common.IndexParam;
import java.util.*;
List<IndexParam> indexParams = new ArrayList<>();
Map<String,Object> extraParams = new HashMap<>();
indexParams.add(IndexParam.builder()
.fieldName("binary_vector")
.indexType(IndexParam.IndexType.AUTOINDEX)
.metricType(IndexParam.MetricType.HAMMING)
.build());
import { MetricType, IndexType } from "@zilliz/milvus2-sdk-node";
const indexParams = {
indexName: "binary_vector_index",
field_name: "binary_vector",
metric_type: MetricType.HAMMING,
index_type: IndexType.AUTOINDEX
};
idx := index.NewAutoIndex(entity.HAMMING)
indexOption := milvusclient.NewCreateIndexOption("my_collection", "binary_vector", idx)
export indexParams='[
{
"fieldName": "binary_vector",
"metricType": "HAMMING",
"indexName": "binary_vector_index",
"indexType": "AUTOINDEX"
}
]'
上記の例では、binary_vector フィールドに対して binary_vector_index という名前のインデックスが作成されています。インデックスタイプには AUTOINDEX を使用し、metric_type は HAMMING に設定されており、類似度測定にハミング距離が使用されることを示しています。
さらに、Zilliz Cloud ではバイナリベクトルに対して他の類似度メトリクスもサポートしています。詳細については、メトリックタイプ を参照してください。
コレクションの作成
バイナリベクトルとインデックスの設定が完了したら、バイナリベクトルを含むコレクションを作成します。以下の例では、create_collection メソッドを使用して my_collection という名前のコレクションを作成しています。
- Python
- Java
- NodeJS
- Go
- cURL
client.create_collection(
collection_name="my_collection",
schema=schema,
index_params=index_params
)
import io.milvus.v2.service.collection.request.CreateCollectionReq;
CreateCollectionReq requestCreate = CreateCollectionReq.builder()
.collectionName("my_collection")
.collectionSchema(schema)
.indexParams(indexParams)
.build();
client.createCollection(requestCreate);
import { MilvusClient } from "@zilliz/milvus2-sdk-node";
await client.createCollection({
collection_name: 'my_collection',
schema: schema,
index_params: indexParams
});
err = client.CreateCollection(ctx,
milvusclient.NewCreateCollectionOption("my_collection", schema).
WithIndexOptions(indexOption))
if err != nil {
fmt.Println(err.Error())
// handle error
}
curl --request POST \
--url "${CLUSTER_ENDPOINT}/v2/vectordb/collections/create" \
--header "Authorization: Bearer ${TOKEN}" \
--header "Content-Type: application/json" \
-d "{
\"collectionName\": \"my_collection\",
\"schema\": $schema,
\"indexParams\": $indexParams
}"
データの挿入
コレクションを作成した後、insert メソッドを使用してバイナリベクトルを含むデータを追加します。バイナリベクトルはバイト配列の形式で提供する必要があり、各バイトは8つのブール値を表します。
たとえば、128次元のバイナリベクトルの場合、16バイトの配列が必要です(128ビット ÷ 8ビット/バイト = 16バイト)。以下にデータ挿入の例を示します:
- Python
- Java
- NodeJS
- Go
- cURL
def convert_bool_list_to_bytes(bool_list):
if len(bool_list) % 8 != 0:
raise ValueError("The length of a boolean list must be a multiple of 8")
byte_array = bytearray(len(bool_list) // 8)
for i, bit in enumerate(bool_list):
if bit == 1:
index = i // 8
shift = i % 8
byte_array[index] |= (1 << shift)
return bytes(byte_array)
bool_vectors = [
[1, 0, 0, 1, 1, 0, 1, 1, 0, 1, 0, 1, 0, 1, 0, 0] + [0] * 112,
[0, 1, 0, 1, 0, 1, 0, 0, 1, 1, 0, 0, 1, 1, 0, 1] + [0] * 112,
]
data = [{"binary_vector": convert_bool_list_to_bytes(bool_vector)} for bool_vector in bool_vectors]
client.insert(
collection_name="my_collection",
data=data
)
import com.google.gson.Gson;
import com.google.gson.JsonObject;
import io.milvus.v2.service.vector.request.InsertReq;
import io.milvus.v2.service.vector.response.InsertResp;
private static byte[] convertBoolArrayToBytes(boolean[] booleanArray) {
byte[] byteArray = new byte[booleanArray.length / Byte.SIZE];
for (int i = 0; i < booleanArray.length; i++) {
if (booleanArray[i]) {
int index = i / Byte.SIZE;
int shift = i % Byte.SIZE;
byteArray[index] |= (byte) (1 << shift);
}
}
return byteArray;
}
List<JsonObject> rows = new ArrayList<>();
Gson gson = new Gson();
{
boolean[] boolArray = {true, false, false, true, true, false, true, true, false, true, false, false, true, true, false, true};
JsonObject row = new JsonObject();
row.add("binary_vector", gson.toJsonTree(convertBoolArrayToBytes(boolArray)));
rows.add(row);
}
{
boolean[] boolArray = {false, true, false, true, false, true, false, false, true, true, false, false, true, true, false, true};
JsonObject row = new JsonObject();
row.add("binary_vector", gson.toJsonTree(convertBoolArrayToBytes(boolArray)));
rows.add(row);
}
InsertResp insertR = client.insert(InsertReq.builder()
.collectionName("my_collection")
.data(rows)
.build());
const data = [
{ binary_vector: [1, 0, 0, 1, 1, 0, 1, 1, 0, 1, 0, 0, 1, 1, 0, 1] },
{ binary_vector: [1, 0, 0, 1, 1, 0, 1, 1, 0, 1, 0, 0, 1, 1, 0, 1] },
];
client.insert({
collection_name: "my_collection",
data: data,
});
_, err = client.Insert(ctx, milvusclient.NewColumnBasedInsertOption("my_collection").
WithBinaryVectorColumn("binary_vector", 128, [][]byte{
{0b10011011, 0b01010100, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0},
{0b10011011, 0b01010101, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0},
}))
if err != nil {
fmt.Println(err.Error())
// handle err
}
curl --request POST \
--url "${CLUSTER_ENDPOINT}/v2/vectordb/entities/insert" \
--header "Authorization: Bearer ${TOKEN}" \
--header "Content-Type: application/json" \
-d "{
\"data\": $data,
\"collectionName\": \"my_collection\"
}"
類似性検索を実行する
類似性検索は Zilliz Cloud クラスターの中核機能の一つであり、ベクトル間の距離に基づいてクエリベクトルに最も類似したデータを高速に検索できます。バイナリベクトルを使用して類似性検索を実行するには、クエリベクトルと検索パラメータを準備し、search メソッドを呼び出します。
検索操作時には、バイナリベクトルもバイト配列の形式で提供する必要があります。クエリベクトルの次元数が dim 定義時に指定した次元数と一致していること、および8つのブール値ごとに1バイトに変換されていることを確認してください。
- Python
- Java
- NodeJS
- Go
- cURL
search_params = {
"params": {"nprobe": 10}
}
query_bool_list = [1, 0, 0, 1, 1, 0, 1, 1, 0, 1, 0, 1, 0, 1, 0, 0] + [0] * 112
query_vector = convert_bool_list_to_bytes(query_bool_list)
res = client.search(
collection_name="my_collection",
data=[query_vector],
anns_field="binary_vector",
search_params=search_params,
limit=5,
output_fields=["pk"]
)
print(res)
# Output
# data: ["[{'id': '453718927992172268', 'distance': 10.0, 'entity': {'pk': '453718927992172268'}}]"]
import io.milvus.v2.service.vector.request.SearchReq;
import io.milvus.v2.service.vector.request.data.BinaryVec;
import io.milvus.v2.service.vector.response.SearchResp;
Map<String,Object> searchParams = new HashMap<>();
searchParams.put("nprobe",10);
boolean[] boolArray = {true, false, false, true, true, false, true, true, false, true, false, false, true, true, false, true};
BinaryVec queryVector = new BinaryVec(convertBoolArrayToBytes(boolArray));
SearchResp searchR = client.search(SearchReq.builder()
.collectionName("my_collection")
.data(Collections.singletonList(queryVector))
.annsField("binary_vector")
.searchParams(searchParams)
.topK(5)
.outputFields(Collections.singletonList("pk"))
.build());
System.out.println(searchR.getSearchResults());
// Output
//
// [[SearchResp.SearchResult(entity={pk=453444327741536775}, score=0.0, id=453444327741536775), SearchResp.SearchResult(entity={pk=453444327741536776}, score=7.0, id=453444327741536776)]]
query_vector = [1,0,1,0,1,1,1,1,1,1,1,1];
client.search({
collection_name: 'my_collection',
data: query_vector,
limit: 5,
output_fields: ['pk'],
params: {
nprobe: 10
}
});
queryVector := []byte{0b10011011, 0b01010100, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0}
annSearchParams := index.NewCustomAnnParam()
annSearchParams.WithExtraParam("nprobe", 10)
resultSets, err := client.Search(ctx, milvusclient.NewSearchOption(
"my_collection", // collectionName
5, // limit
[]entity.Vector{entity.BinaryVector(queryVector)},
).WithANNSField("binary_vector").
WithOutputFields("pk").
WithAnnParam(annSearchParams))
if err != nil {
fmt.Println(err.Error())
// handle err
}
for _, resultSet := range resultSets {
fmt.Println("IDs: ", resultSet.IDs.FieldData().GetScalars())
fmt.Println("Scores: ", resultSet.Scores)
fmt.Println("Pks: ", resultSet.GetColumn("pk").FieldData().GetScalars())
}
export searchParams='{
"params":{"nprobe":10}
}'
curl --request POST \
--url "${CLUSTER_ENDPOINT}/v2/vectordb/entities/search" \
--header "Authorization: Bearer ${TOKEN}" \
--header "Content-Type: application/json" \
-d "{
\"collectionName\": \"my_collection\",
\"data\": $data,
\"annsField\": \"binary_vector\",
\"limit\": 5,
\"searchParams\":$searchParams,
\"outputFields\": [\"pk\"]
}"
類似性検索パラメータの詳細については、基本的な ANN 検索 を参照してください。