パーティションキーの使用
パーティションキーは、コレクションの名前空間として機能することで、論理的なデータ分離を実現する検索最適化ソリューションです。特定のスカラーフィールド(テナントIDやプロジェクト名など)をパーティションキーとして指定することで、単一のコレクション内でデータを異なる名前空間に効果的に分割できます。これにより、フィルタリング条件を介して特定の名前空間に検索リクエストを絞り込むことができ、検索範囲を大幅に縮小して全体的な効率を向上させることができます。この記事では、この名前空間ベースの最適化を実装する方法と、パーティションキーを使用する際の考慮事項について説明します。
概要
Zilliz Cloud では、パーティションを使用してデータの分離を実装し、検索範囲を特定のパーティションに制限することで検索パフォーマンスを向上させることができます。パーティションを手動で管理することを選択した場合、コレクション内に最大1,024個のパーティションを作成でき、特定のルールに基づいてこれらのパーティションにエンティティを挿入することで、特定の数のパーティション内で検索を制限することで検索範囲を絞り込むことができます。
Zilliz Cloud は、コレクション内に作成できるパーティション数の制限を克服するために、データ分離でパーティションを再利用できるパーティションキーを導入しています。コレクションを作成する際に、スカラーフィールドをパーティションキーとして使用できます。コレクションの準備が整うと、Zilliz Cloud はコレクション内に指定された数のパーティションを作成します。エンティティの挿入を受け取ると、Zilliz Cloud はエンティティのパーティションキー値を使用してハッシュ値を計算し、ハッシュ値とコレクションの partitions_num プロパティに基づいてモジュロ演算を実行してターゲットパーティションIDを取得し、エンティティをターゲットパーティションに保存します。
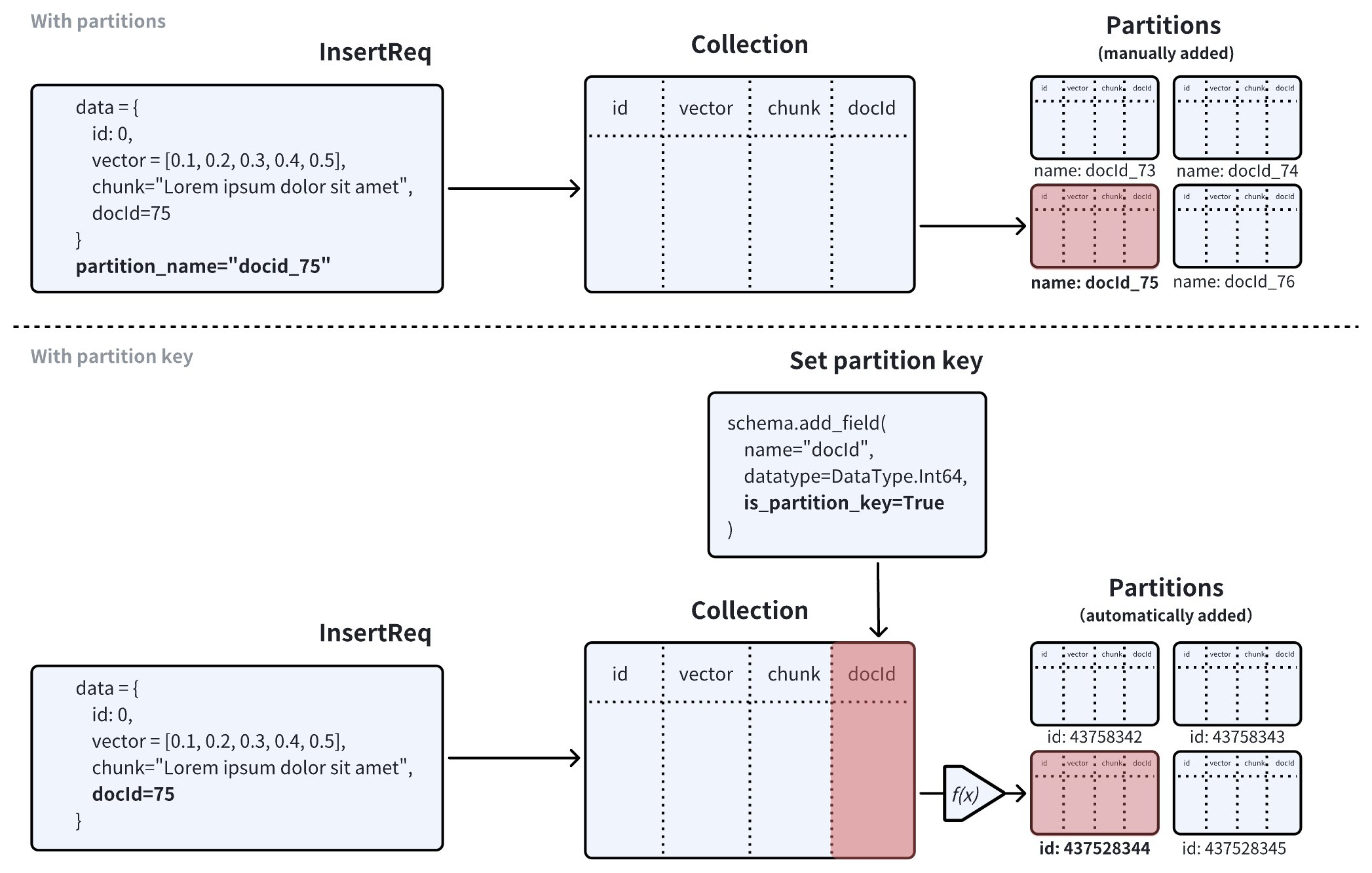
次の図は、パーティションキー機能の有無に関わらず、Zilliz Cloud がコレクション内の検索リクエストをどのように処理するかを示しています。
-
パーティションキーが無効な場合、Zilliz Cloud はコレクション内でクエリベクトルと最も類似したエンティティを検索します。どのパーティションに最も関連性の高い結果が含まれているかを知っていれば、検索範囲を絞り込むことができます。
-
パーティションキーが有効な場合、Zilliz Cloud は検索フィルターで指定されたパーティションキー値に基づいて検索範囲を決定し、一致するパーティション内のエンティティのみをスキャンします。
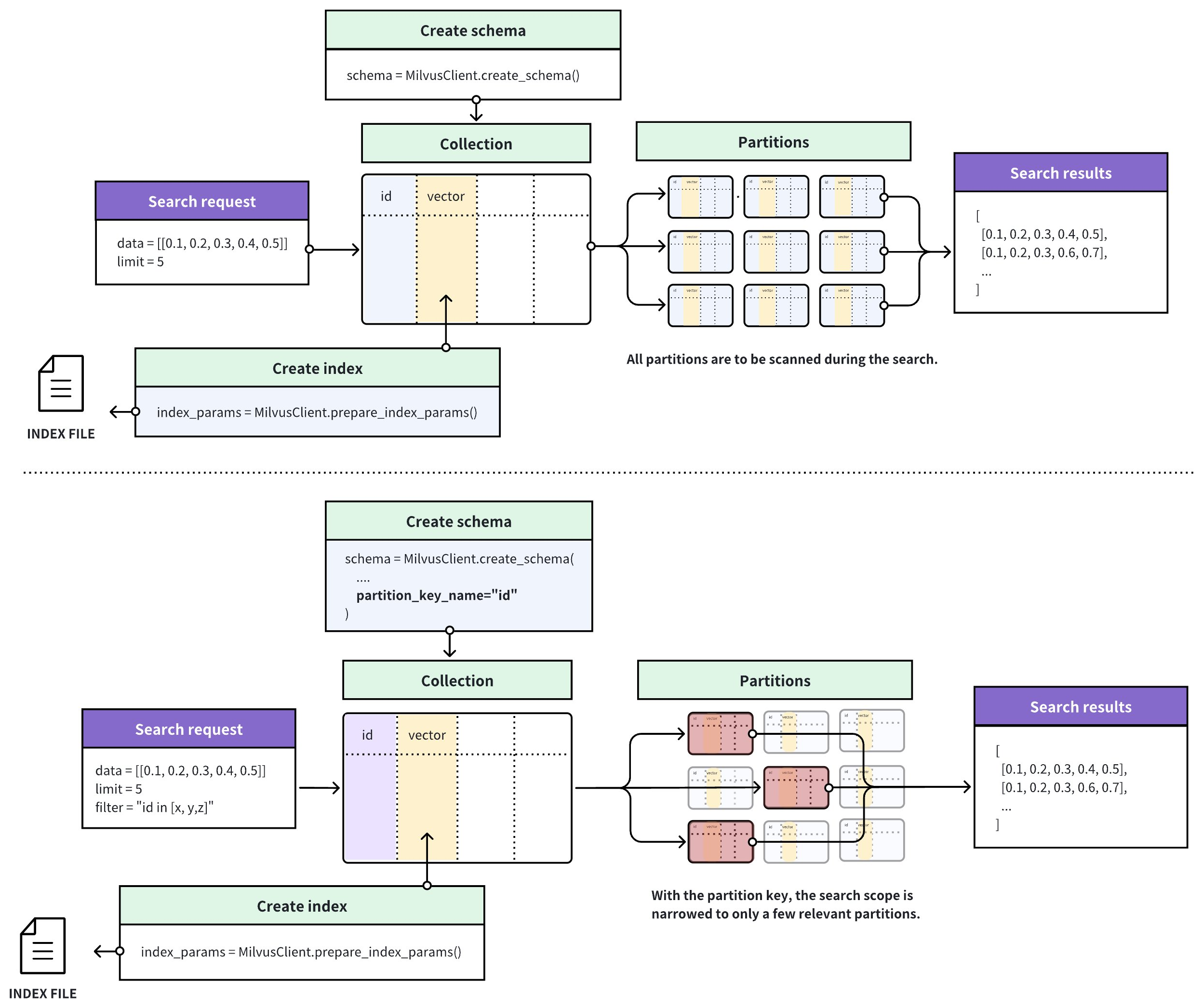
パーティションキーの使用
パーティションキーを使用するには、以下が必要です。
-
作成するパーティション数の設定(オプション)、および
パーティションキーの設定
スカラーフィールドをパーティションキーとして指定するには、スカラーフィールドを追加する際に、その is_partition_key 属性を true に設定する必要があります。
スカラーフィールドをパーティションキーとして設定する場合、フィールド値は空またはnullにできません。
- Python
- Java
- Go
- NodeJS
- cURL
from pymilvus import (
MilvusClient, DataType
)
client = MilvusClient(
uri="YOUR_CLUSTER_ENDPOINT",
token="YOUR_CLUSTER_TOKEN"
)
schema = client.create_schema()
schema.add_field(field_name="id",
datatype=DataType.INT64,
is_primary=True)
schema.add_field(field_name="vector",
datatype=DataType.FLOAT_VECTOR,
dim=5)
# Add the partition key
schema.add_field(
field_name="my_varchar",
datatype=DataType.VARCHAR,
max_length=512,
is_partition_key=True,
)
import io.milvus.v2.client.ConnectConfig;
import io.milvus.v2.client.MilvusClientV2;
import io.milvus.v2.common.DataType;
import io.milvus.v2.service.collection.request.AddFieldReq;
import io.milvus.v2.service.collection.request.CreateCollectionReq;
MilvusClientV2 client = new MilvusClientV2(ConnectConfig.builder()
.uri("YOUR_CLUSTER_ENDPOINT")
.token("YOUR_CLUSTER_TOKEN")
.build());
// Create schema
CreateCollectionReq.CollectionSchema schema = client.createSchema();
schema.addField(AddFieldReq.builder()
.fieldName("id")
.dataType(DataType.Int64)
.isPrimaryKey(true)
.build());
schema.addField(AddFieldReq.builder()
.fieldName("vector")
.dataType(DataType.FloatVector)
.dimension(5)
.build());
// Add the partition key
schema.addField(AddFieldReq.builder()
.fieldName("my_varchar")
.dataType(DataType.VarChar)
.maxLength(512)
.isPartitionKey(true)
.build());
import (
"context"
"fmt"
"github.com/milvus-io/milvus/client/v2/column"
"github.com/milvus-io/milvus/client/v2/entity"
"github.com/milvus-io/milvus/client/v2/index"
"github.com/milvus-io/milvus/client/v2/milvusclient"
)
ctx, cancel := context.WithCancel(context.Background())
defer cancel()
milvusAddr := "YOUR_CLUSTER_ENDPOINT"
client, err := milvusclient.New(ctx, &milvusclient.ClientConfig{
Address: milvusAddr,
})
if err != nil {
fmt.Println(err.Error())
// handle error
}
defer client.Close(ctx)
schema := entity.NewSchema().WithDynamicFieldEnabled(false)
schema.WithField(entity.NewField().
WithName("id").
WithDataType(entity.FieldTypeInt64).
WithIsPrimaryKey(true),
).WithField(entity.NewField().
WithName("my_varchar").
WithDataType(entity.FieldTypeVarChar).
WithIsPartitionKey(true).
WithMaxLength(512),
).WithField(entity.NewField().
WithName("vector").
WithDataType(entity.FieldTypeFloatVector).
WithDim(5),
)
import { MilvusClient, DataType } from "@zilliz/milvus2-sdk-node";
const address = "YOUR_CLUSTER_ENDPOINT";
const token = "YOUR_CLUSTER_TOKEN";
const client = new MilvusClient({address, token});
// 3. Create a collection in customized setup mode
// 3.1 Define fields
const fields = [
{
name: 'id',
data_type: DataType.Int64,
is_primary_key: true,
},
{
name: 'vector',
data_type: DataType.FloatVector,
dim: 5,
},
{
name: 'my_varchar',
data_type: DataType.VarChar,
max_length: 512,
is_partition_key: true,
},
];
export schema='{
"autoId": true,
"enabledDynamicField": false,
"fields": [
{
"fieldName": "id",
"dataType": "Int64",
"isPrimary": true
},
{
"fieldName": "vector",
"dataType": "FloatVector",
"elementTypeParams": {
"dim": "5"
}
},
{
"fieldName": "my_varchar",
"dataType": "VarChar",
"isPartitionKey": true,
"elementTypeParams": {
"max_length": 512
}
}
]
}'
Set Partition Numbers
コレクション内のスカラー フィールドをパーティションキーとして指定すると、Zilliz Cloud はそのコレクション内に自動的に 16 個のパーティションを作成します。エンティティを受信すると、Zilliz Cloud はそのエンティティのパーティションキー値に基づいてパーティションを選び、そのパーティション内にエンティティを格納します。この結果、一部またはすべてのパーティションが異なるパーティションキー値を持つエンティティを保持することになります。
コレクション作成時にパーティション数を自分で決定することもできます。ただし、これはスカラー フィールドがパーティションキーとして指定されている場合にのみ有効です。
- Python
- Java
- Go
- NodeJS
- cURL
client.create_collection(
collection_name="my_collection",
schema=schema,
num_partitions=128
)
import io.milvus.v2.service.collection.request.CreateCollectionReq;
CreateCollectionReq createCollectionReq = CreateCollectionReq.builder()
.collectionName("my_collection")
.collectionSchema(schema)
.numPartitions(128)
.build();
client.createCollection(createCollectionReq);
err = client.CreateCollection(ctx,
milvusclient.NewCreateCollectionOption("my_collection", schema).
WithNumPartitions(128))
if err != nil {
fmt.Println(err.Error())
// handle error
}
await client.create_collection({
collection_name: "my_collection",
schema: schema,
num_partitions: 128
})
export params='{
"partitionsNum": 128
}'
export CLUSTER_ENDPOINT="YOUR_CLUSTER_ENDPOINT"
export TOKEN="YOUR_CLUSTER_TOKEN"
curl --request POST \
--url "${CLUSTER_ENDPOINT}/v2/vectordb/collections/create" \
--header "Authorization: Bearer ${TOKEN}" \
--header "Content-Type: application/json" \
-d "{
\"collectionName\": \"my_collection\",
\"schema\": $schema,
\"params\": $params
}"
フィルタリング条件の作成
パーティションキー機能が有効化されたコレクションでANN検索を実行する際には、検索リクエストにパーティションキーを含むフィルタリング式を指定する必要があります。このフィルタリング式では、パーティションキーの値を特定の範囲内に限定することで、Zilliz Cloudが対応するパーティション内でのみ検索を実行します。
削除操作を実行する際には、単一のパーティションキーを指定するフィルター式を含めることを推奨します。これにより、削除操作が特定のパーティションに限定され、コンパクション時のライトアンプリフィケーションが軽減され、コンパクションおよびインデックス作成のためのリソースを節約できます。
以下の例では、特定のパーティションキー値および複数のパーティションキー値に基づくフィルタリングを示しています。
- Python
- Java
- Go
- NodeJS
- cURL
# Filter based on a single partition key value, or
filter='partition_key == "x" && <other conditions>'
# Filter based on multiple partition key values
filter='partition_key in ["x", "y", "z"] && <other conditions>'
// Filter based on a single partition key value, or
String filter = "partition_key == 'x' && <other conditions>";
// Filter based on multiple partition key values
String filter = "partition_key in ['x', 'y', 'z'] && <other conditions>";
// Filter based on a single partition key value, or
filter = "partition_key == 'x' && <other conditions>"
// Filter based on multiple partition key values
filter = "partition_key in ['x', 'y', 'z'] && <other conditions>"
// Filter based on a single partition key value, or
const filter = 'partition_key == "x" && <other conditions>'
// Filter based on multiple partition key values
const filter = 'partition_key in ["x", "y", "z"] && <other conditions>'
# Filter based on a single partition key value, or
export filter='partition_key == "x" && <other conditions>'
# Filter based on multiple partition key values
export filter='partition_key in ["x", "y", "z"] && <other conditions>'
partition_key は、パーティションキーとして指定されたフィールドの名前に置き換える必要があります。
パーティションキー分離の使用
マルチテナンシーのシナリオでは、テナントIDに関連するスカラーフィールドをパーティションキーとして指定し、このスカラーフィールドの特定の値に基づいてフィルタを作成できます。このようなシナリオでの検索パフォーマンスをさらに向上させるため、Zilliz Cloud はパーティションキー分離機能を導入しています。
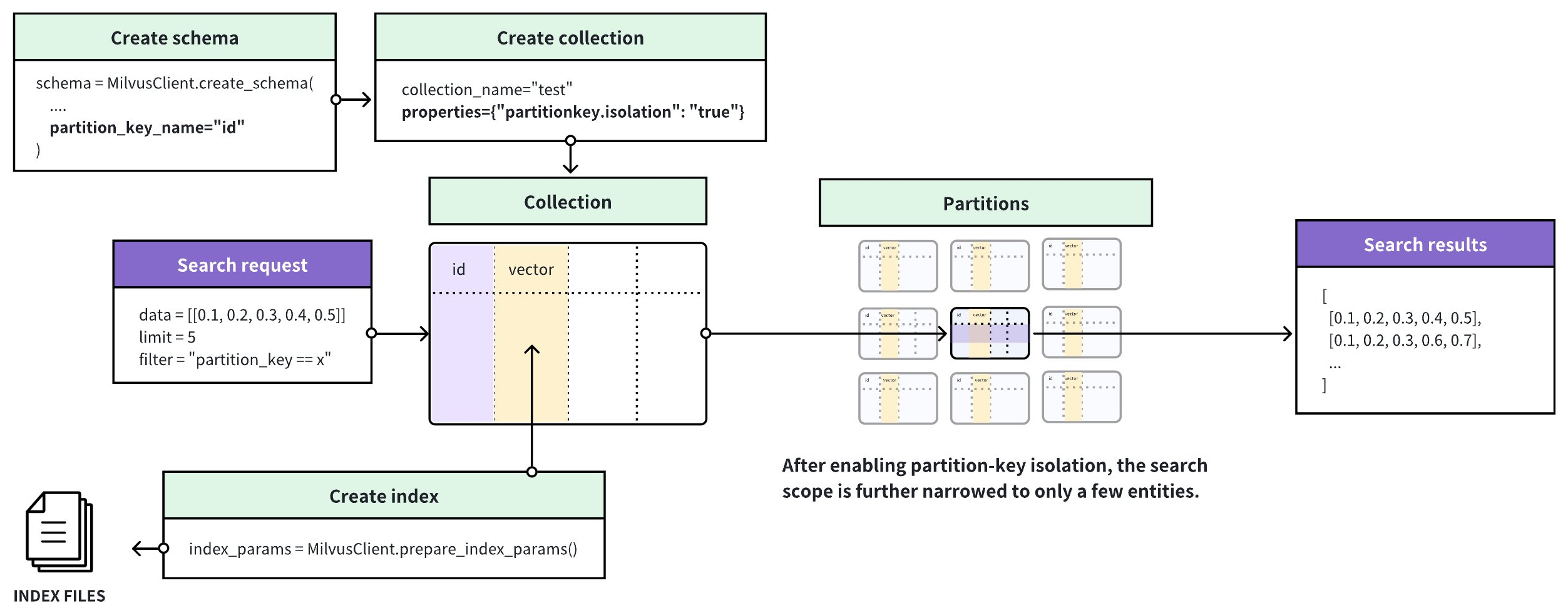
上図に示すように、Zilliz Cloud はパーティションキーの値に基づいてエンティティをグループ化し、これらの各グループに対して個別のインデックスを作成します。検索リクエストを受信すると、Zilliz Cloud はフィルタ条件で指定されたパーティションキーの値に基づいてインデックスを特定し、検索範囲をそのインデックスに含まれるエンティティ内に制限します。これにより、検索時に無関係なエンティティをスキャンすることを回避し、検索パフォーマンスを大幅に向上させます。
パーティションキー分離を有効にすると、パーティションキーに基づくフィルタに特定の値を1つだけ含める必要があります。これにより、Zilliz Cloud は一致するインデックスに含まれるエンティティ内に検索範囲を制限できます。
パーティションキー分離の有効化
以下のコード例は、パーティションキー分離を有効にする方法を示しています。
- Python
- Java
- Go
- NodeJS
- cURL
client.create_collection(
collection_name="my_collection",
schema=schema,
properties={"partitionkey.isolation": True}
)
import io.milvus.v2.service.collection.request.CreateCollectionReq;
Map<String, String> properties = new HashMap<>();
properties.put("partitionkey.isolation", "true");
CreateCollectionReq createCollectionReq = CreateCollectionReq.builder()
.collectionName("my_collection")
.collectionSchema(schema)
.properties(properties)
.build();
client.createCollection(createCollectionReq);
err = client.CreateCollection(ctx,
milvusclient.NewCreateCollectionOption("my_collection", schema).
WithProperty("partitionkey.isolation", true))
if err != nil {
fmt.Println(err.Error())
// handle error
}
res = await client.alterCollection({
collection_name: "my_collection",
properties: {
"partitionkey.isolation": true
}
})
export params='{
"partitionKeyIsolation": true
}'
export CLUSTER_ENDPOINT="YOUR_CLUSTER_ENDPOINT"
export TOKEN="YOUR_CLUSTER_TOKEN"
curl --request POST \
--url "${CLUSTER_ENDPOINT}/v2/vectordb/collections/create" \
--header "Authorization: Bearer ${TOKEN}" \
--header "Content-Type: application/json" \
-d "{
\"collectionName\": \"my_collection\",
\"schema\": $schema,
\"params\": $params
}"
パーティションキー分離を有効にした後も、パーティション数の設定 で説明されているように、パーティションキーとパーティション数を設定できます。パーティションキーに基づくフィルターには、1 つの特定のパーティションキー値のみを含める必要があることに注意してください。