疎ベクトル
疎ベクトルは、情報検索および自然言語処理において、表層レベルの用語マッチングを捉える重要な手法です。密ベクトルはセマンティック理解に優れていますが、疎ベクトルは特別な用語やテキスト識別子を検索する際に、より予測可能なマッチング結果を提供することが多いです。
概要
疎ベクトルは、ほとんどの要素がゼロで、少数の次元のみが非ゼロの値を持つ特殊な高次元ベクトルです。以下の図に示すように、密ベクトルは通常、各位置に値を持つ連続した配列として表現されます(例:[0.3, 0.8, 0.2, 0.3, 0.1])。対照的に、疎ベクトルは非ゼロ要素とその次元のインデックスのみを格納し、多くの場合 { index: value} のキー・バリューペアとして表現されます(例:[{2: 0.2}, ..., {9997: 0.5}, {9999: 0.7}])。
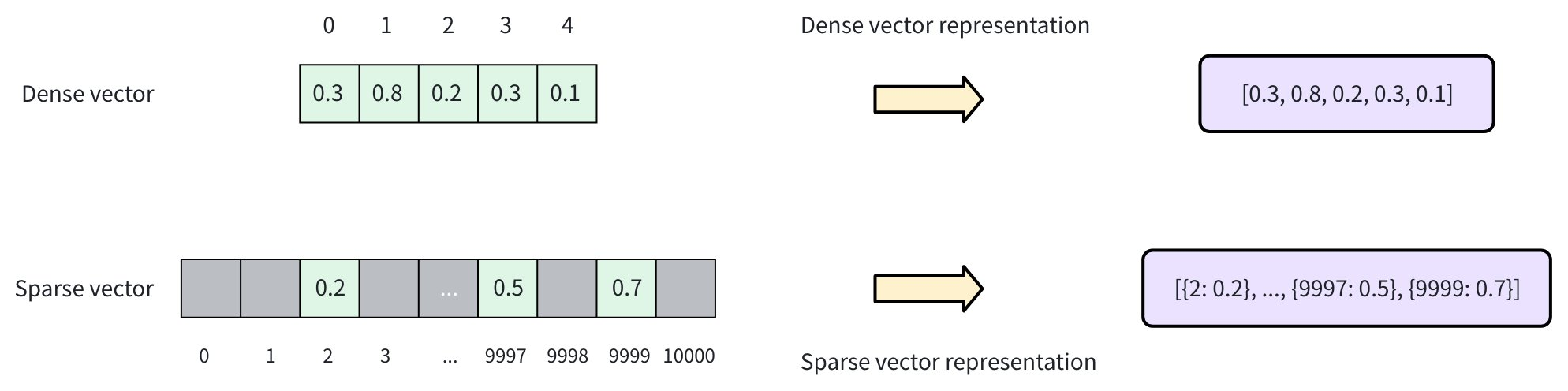
トークン化とスコアリングにより、文書は単語の袋ベクトルとして表現できます。ここで各次元は語彙内の特定の単語に対応します。文書内に存在する単語のみが非ゼロの値を持ち、疎ベクトル表現が作成されます。疎ベクトルは2つのアプローチで生成できます:
-
従来の統計手法、例えば TF-IDF(Term Frequency-Inverse Document Frequency)や BM25(Best Matching 25)は、コーパス全体での単語の頻度と重要度に基づいて重みを割り当てます。これらの方法は、各次元(トークンを表す)のスコアとして単純な統計量を計算します。Zilliz Cloud は BM25 方式の組み込み 全文検索 を提供しており、テキストを自動的に疎ベクトルに変換し、手動での前処理を不要にします。このアプローチは、精度と完全一致が重要なキーワードベースの検索に最適です。詳細については、全文検索 を参照してください。
-
ニューラル疎埋め込みモデル は、大規模データセットでの学習により疎表現を生成する学習済み手法です。これらは通常、Transformer アーキテクチャを持つ深層学習モデルであり、セマンティックコンテキストに基づいて単語を拡張・重み付けできます。Zilliz Cloud は SPLADE などのモデルから外部生成されたスパース埋め込みもサポートしています。詳細については、Embeddings を参照してください。
疎ベクトルと元のテキストは、Zilliz Cloud に効率的な検索のために格納できます。以下の図は、全体的なプロセスの概要を示しています。
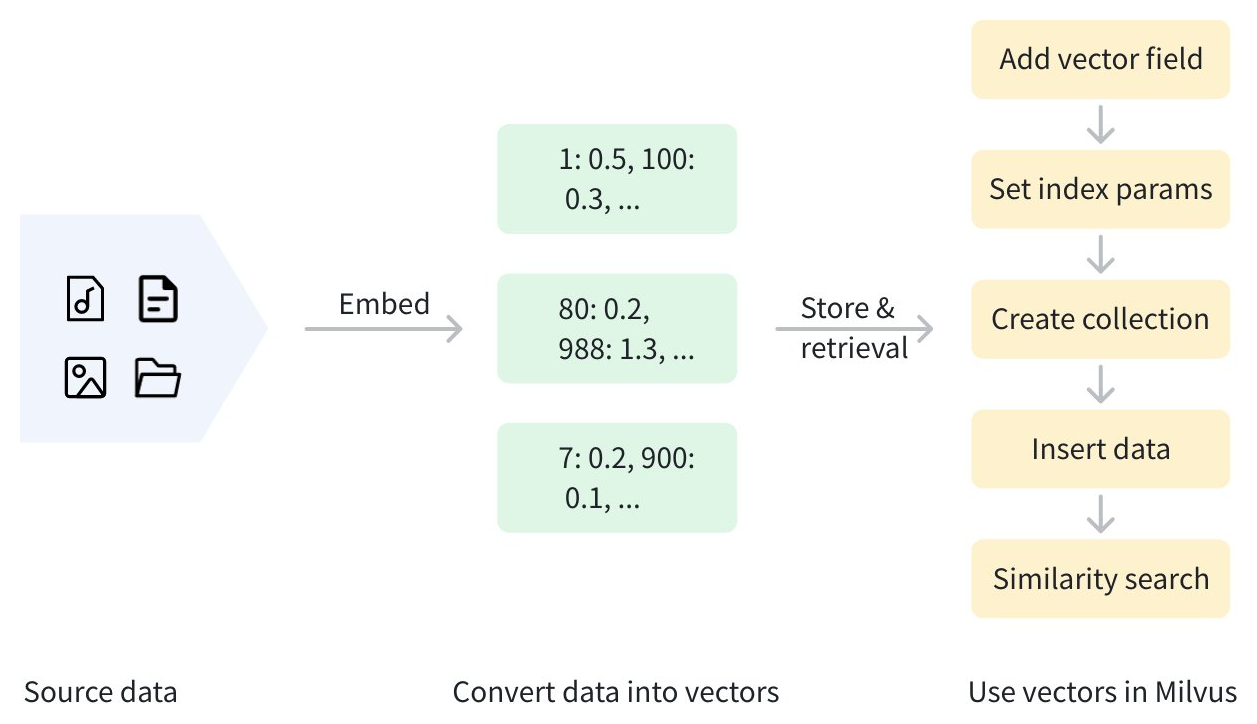
疎ベクトルに加えて、Zilliz Cloud は密ベクトルとバイナリベクトルもサポートしています。密ベクトルは深いセマンティック関係の捉え方に最適であり、バイナリベクトルは高速な類似性比較やコンテンツの重複排除などのシナリオで優れています。詳細については、Dense Vector および Binary Vector を参照してください。
データ形式
以下のセクションでは、SPLADE などの学習済み疎埋め込みモデルからのベクトルの格納方法を示します。密ベクトルベースのセマンティック検索を補完するものをお探しの場合、シンプルさのため SPLADE よりも BM25 を使用した 全文検索 を推奨します。品質評価を実施し、SPLADE の使用を決定した場合は、SPLADE で疎ベクトルを生成する方法について Embeddings を参照してください。
Zilliz Cloud は、以下の形式で疎ベクトル入力をサポートしています:
-
辞書のリスト(
{dimension_index: value, ...}の形式でフォーマット)# Represent each sparse vector using a dictionarysparse_vectors = [{27: 0.5, 100: 0.3, 5369: 0.6} , {100: 0.1, 3: 0.8}] -
スパース行列(
scipy.sparse** クラスを使用)**from scipy.sparse import csr_matrix# First vector: indices [27, 100, 5369] with values [0.5, 0.3, 0.6]# Second vector: indices [3, 100] with values [0.8, 0.1]indices = [[27, 100, 5369], [3, 100]]values = [[0.5, 0.3, 0.6], [0.8, 0.1]]sparse_vectors = [csr_matrix((vals, ([0]*len(idx), idx)), shape=(1, 5369+1)) for idx, vals in zip(indices, values)] -
タプルのイテラブルのリスト(例:
[(dimension_index, value)])# Represent each sparse vector using a list of iterables (e.g. tuples)sparse_vector = [[(27, 0.5), (100, 0.3), (5369, 0.6)],[(100, 0.1), (3, 0.8)]]
コレクションスキーマの定義
コレクションを作成する前に、フィールドを定義し、オプションでテキストフィールドを対応する疎ベクトル表現に変換する関数を指定するコレクションスキーマを定義する必要があります。
フィールドの追加
Zilliz Cloud クラスターで疎ベクトルを使用するには、以下のフィールドを含むスキーマでコレクションを作成する必要があります。
-
疎ベクトルを格納するために予約された
SPARSE_FLOAT_VECTORフィールド。これはVARCHARフィールドから自動生成されるか、または入力データ内で直接提供されます。 -
通常、疎ベクトルが表す元のテキストもコレクション内に格納されます。元のテキストを格納するには
VARCHARフィールドを使用できます。
- Python
- Java
- NodeJS
- Go
- cURL
from pymilvus import MilvusClient, DataType
client = MilvusClient(uri="YOUR_CLUSTER_ENDPOINT")
schema = client.create_schema(
auto_id=True,
enable_dynamic_fields=True,
)
schema.add_field(field_name="pk", datatype=DataType.VARCHAR, is_primary=True, max_length=100)
schema.add_field(field_name="sparse_vector", datatype=DataType.SPARSE_FLOAT_VECTOR)
schema.add_field(field_name="text", datatype=DataType.VARCHAR, max_length=65535, enable_analyzer=True)
import io.milvus.v2.client.ConnectConfig;
import io.milvus.v2.client.MilvusClientV2;
import io.milvus.v2.common.DataType;
import io.milvus.v2.service.collection.request.AddFieldReq;
import io.milvus.v2.service.collection.request.CreateCollectionReq;
MilvusClientV2 client = new MilvusClientV2(ConnectConfig.builder()
.uri("YOUR_CLUSTER_ENDPOINT")
.build());
CreateCollectionReq.CollectionSchema schema = client.createSchema();
schema.setEnableDynamicField(true);
schema.addField(AddFieldReq.builder()
.fieldName("pk")
.dataType(DataType.VarChar)
.isPrimaryKey(true)
.autoID(true)
.maxLength(100)
.build());
schema.addField(AddFieldReq.builder()
.fieldName("sparse_vector")
.dataType(DataType.SparseFloatVector)
.build());
schema.addField(AddFieldReq.builder()
.fieldName("text")
.dataType(DataType.VarChar)
.maxLength(65535)
.enableAnalyzer(true)
.build());
import { DataType } from "@zilliz/milvus2-sdk-node";
const schema = [
{
name: "metadata",
data_type: DataType.JSON,
},
{
name: "pk",
data_type: DataType.Int64,
is_primary_key: true,
},
{
name: "sparse_vector",
data_type: DataType.SparseFloatVector,
},
{
name: "text",
data_type: "VarChar",
enable_analyzer: true,
enable_match: true,
max_length: 65535,
},
];
import (
"context"
"fmt"
"github.com/milvus-io/milvus/client/v2/column"
"github.com/milvus-io/milvus/client/v2/entity"
"github.com/milvus-io/milvus/client/v2/index"
"github.com/milvus-io/milvus/client/v2/milvusclient"
)
ctx, cancel := context.WithCancel(context.Background())
defer cancel()
milvusAddr := "YOUR_CLUSTER_ENDPOINT"
client, err := milvusclient.New(ctx, &milvusclient.ClientConfig{
Address: milvusAddr,
})
if err != nil {
fmt.Println(err.Error())
// handle error
}
defer client.Close(ctx)
schema := entity.NewSchema()
schema.WithField(entity.NewField().
WithName("pk").
WithDataType(entity.FieldTypeVarChar).
WithIsAutoID(true).
WithIsPrimaryKey(true).
WithMaxLength(100),
).WithField(entity.NewField().
WithName("sparse_vector").
WithDataType(entity.FieldTypeSparseVector),
).WithField(entity.NewField().
WithName("text").
WithDataType(entity.FieldTypeVarChar).
WithEnableAnalyzer(true).
WithMaxLength(65535),
)
export primaryField='{
"fieldName": "pk",
"dataType": "VarChar",
"isPrimary": true,
"elementTypeParams": {
"max_length": 100
}
}'
export vectorField='{
"fieldName": "sparse_vector",
"dataType": "SparseFloatVector"
}'
export textField='{
"fieldName": "text",
"dataType": "VarChar",
"elementTypeParams": {
"max_length": 65535,
"enable_analyzer": true
}
}'
export schema="{
\"autoID\": true,
\"fields\": [
$primaryField,
$vectorField,
$textField
]
}"
この例では、3つのフィールドが追加されています。
-
pk: このフィールドは、最大長100バイトで自動生成されるVARCHARデータ型を使用して主キーを格納します。 -
sparse_vector: このフィールドは、SPARSE_FLOAT_VECTORデータ型を使用して疎ベクトルを格納します。 -
text: このフィールドは、最大長65535バイトのVARCHARデータ型を使用してテキスト文字列を格納します。
データ挿入時に指定されたテキストフィールドから疎ベクトルの埋め込みを または Zilliz Cloud に生成させるには、関数を使用する追加のステップが必要です。詳細については、全文検索 を参照してください。
インデックスパラメータの設定
疎ベクトルのインデックス作成プロセスは、密ベクトル の場合と似ていますが、指定するインデックスタイプ(index_type)、距離メトリック(metric_type)、およびインデックスパラメータ(params)が異なります。
- Python
- Java
- NodeJS
- Go
- cURL
index_params = client.prepare_index_params()
index_params.add_index(
field_name="sparse_vector",
index_name="sparse_auto_index",
index_type="AUTOINDEX",
metric_type="IP"
)
import io.milvus.v2.common.IndexParam;
import java.util.*;
List<IndexParam> indexes = new ArrayList<>();
indexes.add(IndexParam.builder()
.fieldName("sparse_vector")
.indexName("sparse_auto_index")
.indexType(IndexParam.IndexType.AUTOINDEX)
.metricType(IndexParam.MetricType.IP)
.build());
const indexParams = await client.createIndex({
field_name: 'sparse_vector',
metric_type: MetricType.IP,
index_name: 'sparse_auto_index',
index_type: IndexType.AUTOINDEX,
});
idx := index.NewSparseInvertedIndex(entity.IP, 0.2)
indexOption := milvusclient.NewCreateIndexOption("my_collection", "sparse_vector", idx)
export indexParams='[
{
"fieldName": "sparse_vector",
"metricType": "IP",
"indexName": "sparse_auto_index",
"indexType": "AUTOINDEX"
}
]'
この例では、SPARSE_INVERTED_INDEX インデックスタイプと IP メトリックを使用しています。詳細については、以下のリソースを参照してください。
Create Collection
疎ベクトルとインデックスの設定が完了したら、疎ベクトルを含むコレクションを作成できます。以下の例では、create_collection メソッドを使用して my_collection という名前のコレクションを作成しています。
- Python
- Java
- NodeJS
- Go
- cURL
client.create_collection(
collection_name="my_collection",
schema=schema,
index_params=index_params
)
CreateCollectionReq requestCreate = CreateCollectionReq.builder()
.collectionName("my_collection")
.collectionSchema(schema)
.indexParams(indexes)
.build();
client.createCollection(requestCreate);
import { MilvusClient } from "@zilliz/milvus2-sdk-node";
await client.createCollection({
collection_name: 'my_collection',
schema: schema,
index_params: indexParams
});
err = client.CreateCollection(ctx,
milvusclient.NewCreateCollectionOption("my_collection", schema).
WithIndexOptions(indexOption))
if err != nil {
fmt.Println(err.Error())
// handle error
}
curl --request POST \
--url "${CLUSTER_ENDPOINT}/v2/vectordb/collections/create" \
--header "Authorization: Bearer ${TOKEN}" \
--header "Content-Type: application/json" \
-d "{
\"collectionName\": \"my_collection\",
\"schema\": $schema,
\"indexParams\": $indexParams
}"
Insert data
コレクション作成時に定義されたすべてのフィールドに対してデータを提供する必要があります。ただし、自動生成されるフィールド(auto_id が有効になっている主キーなど)は除きます。組み込みのBM25関数を使用して疎ベクトルを自動生成している場合は、データ挿入時に疎ベクトルフィールドも省略する必要があります。
- Python
- Java
- NodeJS
- Go
- cURL
data = [
{
"text": "information retrieval is a field of study.",
"sparse_vector": {1: 0.5, 100: 0.3, 500: 0.8}
},
{
"text": "information retrieval focuses on finding relevant information in large datasets.",
"sparse_vector": {10: 0.1, 200: 0.7, 1000: 0.9}
}
]
client.insert(
collection_name="my_collection",
data=data
)
import com.google.gson.Gson;
import com.google.gson.JsonObject;
import io.milvus.v2.service.vector.request.InsertReq;
import io.milvus.v2.service.vector.response.InsertResp;
import java.util.ArrayList;
import java.util.List;
import java.util.SortedMap;
import java.util.TreeMap;
Gson gson = new Gson();
List<JsonObject> rows = new ArrayList<>();
{
JsonObject row = new JsonObject();
row.addProperty("text", "information retrieval is a field of study.");
SortedMap<Long, Float> sparse = new TreeMap<>();
sparse.put(1L, 0.5f);
sparse.put(100L, 0.3f);
sparse.put(500L, 0.8f);
row.add("sparse_vector", gson.toJsonTree(sparse));
rows.add(row);
}
{
JsonObject row = new JsonObject();
row.addProperty("text", "information retrieval focuses on finding relevant information in large datasets.");
SortedMap<Long, Float> sparse = new TreeMap<>();
sparse.put(10L, 0.1f);
sparse.put(200L, 0.7f);
sparse.put(1000L, 0.9f);
row.add("sparse_vector", gson.toJsonTree(sparse));
rows.add(row);
}
InsertResp insertResp = client.insert(InsertReq.builder()
.collectionName("my_collection")
.data(rows)
.build());
const data = [
{
text: 'information retrieval is a field of study.',
sparse_vector: {1: 0.5, 100: 0.3, 500: 0.8}
{
text: 'information retrieval focuses on finding relevant information in large datasets.',
sparse_vector: {10: 0.1, 200: 0.7, 1000: 0.9}
},
];
client.insert({
collection_name: "my_collection",
data: data
});
texts := []string{
"information retrieval is a field of study.",
"information retrieval focuses on finding relevant information in large datasets.",
}
textColumn := entity.NewColumnVarChar("text", texts)
// Prepare sparse vectors
sparseVectors := make([]entity.SparseEmbedding, 0, 2)
sparseVector1, _ := entity.NewSliceSparseEmbedding([]uint32{1, 100, 500}, []float32{0.5, 0.3, 0.8})
sparseVectors = append(sparseVectors, sparseVector1)
sparseVector2, _ := entity.NewSliceSparseEmbedding([]uint32{10, 200, 1000}, []float32{0.1, 0.7, 0.9})
sparseVectors = append(sparseVectors, sparseVector2)
sparseVectorColumn := entity.NewColumnSparseVectors("sparse_vector", sparseVectors)
_, err = client.Insert(ctx, milvusclient.NewColumnBasedInsertOption("my_collection").
WithColumns(
sparseVectorColumn,
textColumn
))
if err != nil {
fmt.Println(err.Error())
// handle err
}
curl --request POST \
--url "${CLUSTER_ENDPOINT}/v2/vectordb/entities/insert" \
--header "Authorization: Bearer ${TOKEN}" \
--header "Content-Type: application/json" \
-d '{
"data": [
{
"text": "information retrieval is a field of study.",
"sparse_vector": {"1": 0.5, "100": 0.3, "500": 0.8}
},
{
"text": "information retrieval focuses on finding relevant information in large datasets.",
"sparse_vector": {"10": 0.1, "200": 0.7, "1000": 0.9}
}
],
"collectionName": "my_collection"
}'
類似性検索の実行
疎ベクトルを使用して類似性検索を実行するには、クエリデータと検索パラメータの両方を準備します。
- Python
- Java
- Go
- NodeJS
- cURL
# Prepare search parameters
search_params = {
"params": {"drop_ratio_search": 0.2}, # A tunable drop ratio parameter with a valid range between 0 and 1
}
# Query with sparse vector
query_data = [{1: 0.2, 50: 0.4, 1000: 0.7}]
import io.milvus.v2.service.vector.request.data.EmbeddedText;
import io.milvus.v2.service.vector.request.data.SparseFloatVec;
// Prepare search parameters
Map<String,Object> searchParams = new HashMap<>();
searchParams.put("drop_ratio_search", 0.2);
// Query with the sparse vector
SortedMap<Long, Float> sparse = new TreeMap<>();
sparse.put(1L, 0.2f);
sparse.put(50L, 0.4f);
sparse.put(1000L, 0.7f);
SparseFloatVec queryData = new SparseFloatVec(sparse);
// Prepare search parameters
annSearchParams := index.NewCustomAnnParam()
annSearchParams.WithExtraParam("drop_ratio_search", 0.2)
// Query with the sparse vector
queryData, _ := entity.NewSliceSparseEmbedding([]uint32{1, 50, 1000}, []float32{0.2, 0.4, 0.7})
// Prepare search parameters
const searchParams = {drop_ratio_search: 0.2}
// Query with the sparse vector
const queryData = [{1: 0.2, 50: 0.4, 1000: 0.7}]
# Prepare search parameters
export queryData='["What is information retrieval?"]'
# Query with the sparse vector
export queryData='[{1: 0.2, 50: 0.4, 1000: 0.7}]'
次に、search メソッドを使用して類似性検索を実行します:
- Python
- Java
- NodeJS
- Go
- cURL
res = client.search(
collection_name="my_collection",
data=query_data,
limit=3,
output_fields=["pk"],
search_params=search_params,
consistency_level="Strong"
)
print(res)
# Output
# data: ["[{'id': '453718927992172266', 'distance': 0.6299999952316284, 'entity': {'pk': '453718927992172266'}}, {'id': '453718927992172265', 'distance': 0.10000000149011612, 'entity': {'pk': '453718927992172265'}}]"]
import io.milvus.v2.service.vector.request.SearchReq;
import io.milvus.v2.service.vector.response.SearchResp;
SparseFloatVec queryVector = new SparseFloatVec(sparse);
SearchResp searchR = client.search(SearchReq.builder()
.collectionName("my_collection")
.data(Collections.singletonList(queryData))
.annsField("sparse_vector")
.searchParams(searchParams)
.consistencyLevel(ConsistencyLevel.STRONG)
.topK(3)
.outputFields(Collections.singletonList("pk"))
.build());
System.out.println(searchR.getSearchResults());
// Output
//
// [[SearchResp.SearchResult(entity={pk=457270974427187729}, score=0.63, id=457270974427187729), SearchResp.SearchResult(entity={pk=457270974427187728}, score=0.1, id=457270974427187728)]]
await client.search({
collection_name: 'my_collection',
data: queryData,
limit: 3,
output_fields: ['pk'],
params: searchParams,
consistency_level: "Strong"
});
resultSets, err := client.Search(ctx, milvusclient.NewSearchOption(
"my_collection",
3, // limit
[]entity.Vector{queryData},
).WithANNSField("sparse_vector").
WithOutputFields("pk").
WithAnnParam(annSearchParams))
if err != nil {
fmt.Println(err.Error())
// handle err
}
for _, resultSet := range resultSets {
fmt.Println("IDs: ", resultSet.IDs.FieldData().GetScalars())
fmt.Println("Scores: ", resultSet.Scores)
fmt.Println("Pks: ", resultSet.GetColumn("pk").FieldData().GetScalars())
}
// Results:
// IDs: string_data:{data:"457270974427187705" data:"457270974427187704"}
// Scores: [0.63 0.1]
// Pks: string_data:{data:"457270974427187705" data:"457270974427187704"}
export params='{
"consistencyLevel": "Strong"
}'
curl --request POST \
--url "${CLUSTER_ENDPOINT}/v2/vectordb/entities/search" \
--header "Authorization: Bearer ${TOKEN}" \
--header "Content-Type: application/json" \
-d '{
"collectionName": "my_collection",
"data": $queryData,
"annsField": "sparse_vector",
"limit": 3,
"searchParams": $searchParams,
"outputFields": ["pk"],
"params": $params
}'
## {"code":0,"cost":0,"data":[{"distance":0.63,"id":"453577185629572535","pk":"453577185629572535"},{"distance":0.1,"id":"453577185629572534","pk":"453577185629572534"}]}
類似性検索パラメータの詳細については、基本的なベクトル検索 を参照してください。