Welcome to Zilliz Cloud Docs!
Zilliz Cloud provides a fully managed Milvus service, simplifying the deployment and scaling of vector search applications with security in mind, eliminating the need to construct and maintain complex infrastructure. Learn more.
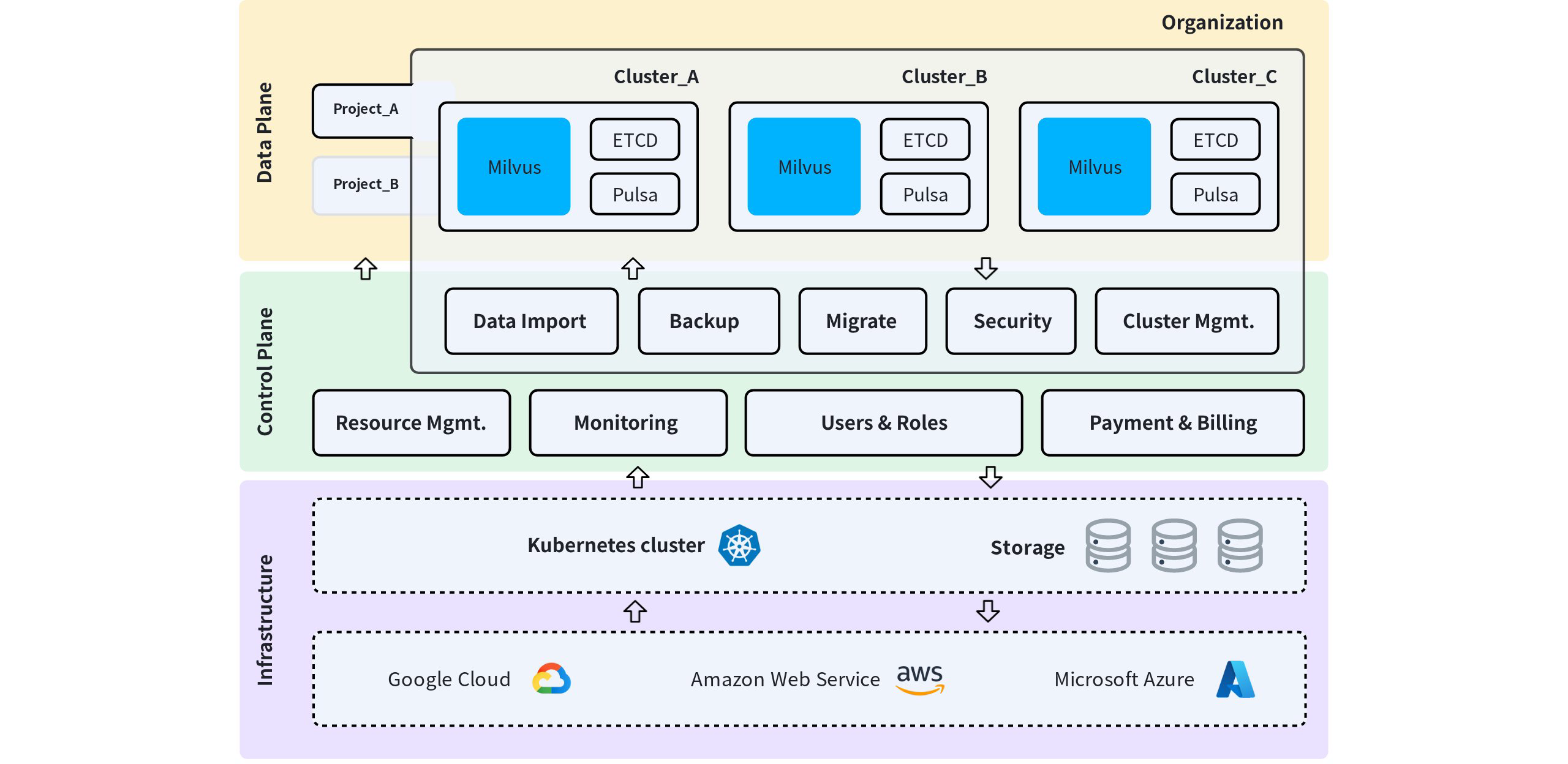
You can create clusters in the following plans:
Work with Your Data in Zilliz Cloud
- Bring Your Own Vectors
- Migrate From Other Data Infra
- Backup & Restore
Create and connect to your cluster.
Create a cluster with your desired compute and storage resources and then connect to it.
Create a collection.
A collection is a two-dimensional table with fixed columns and variable rows. Create a collection to work with your data.
Import data.
Import data from a local file or an object storage bucket.
Conduct a vector similarity search.
A basic vector similarity search helps you find the most similar results.
Go Further with Zilliz Cloud
Monitoring & Alerts
Monitor your clusters and get alerts on time.
Access Control
Secure your data with fine-grained access control.
Private Networking
Connect your clusters to your private network.
Billing
Pay only for what you use, with no upfront costs.
Integrations
Integrate with your existing tools and workflows.